当前位置:网站首页>70000 words of detailed explanation of the whole process of pad openvino [CPU] - from environment configuration to model deployment
70000 words of detailed explanation of the whole process of pad openvino [CPU] - from environment configuration to model deployment
2022-07-04 05:49:00 【Yida gum】
70000 words in detail paddle-openVINO【CPU】- From the environment configuration - The whole process of model deployment
In this article you will be exposed to :paddle-openvino frame 、 The two Linux、windows Multiple configurations 、 Use LabelMe Yes paddle Annotation, transformation and division of data 、 Image classification / object detection / Instance segmentation / Data format of semantic segmentation 、 model training 、 Training parameter adjustment 、 Model preservation 、 The model of compression ( Crop quantification ) Export with model (ONNX2).
You will be exposed to 6 A real project :paddle( Portrait segmentation - RGB Remote sensing image segmentation - Multi channel remote sensing image segmentation - Parcel change detection ) and paddle with openvino(paddleyolo、paddleyolo3、paddleOCR )
During this period, more than 100 official technical documents were referred 、 Learn from it intel Excellent engineer Zhang Jing 、 Xu Yuwen 、 Peng Jiali 、 Jia Zhigang 、 Zhuang Jian 、 Yang Yicheng 、raymondlo、 Wu Zhuo and other eight engineers , Bi ran, the engineer of Baidu PaddlePaddle 、 Sun Gaofeng 、 Zhou Xiangyang 、 Some materials of Liu Weiwei and a large number of paddle Official open source literature
Catalog
- 70000 words in detail paddle-openVINO【CPU】- From the environment configuration - The whole process of model deployment
- Three pictures make it clear openVINO- Flying propeller
- Paddlepaddle-PaddleX-openVINO Installation and environment deployment
- PaddleX Introduce
- Take vegetable classification as an example PaddleX Develop the whole process
- 1、 install paddle paddle
- 2.win/Mac/linux/anaconda/pip/pycocotools
- install paddleX
- pip install
- Anaconda install
- Windows System
- Linux/Mac System
- 3、openVINO The installation is suitable for the relevant environment
- Windows install openVINO
- Installation steps
- The first 1 Step : Install external software dependencies
- The first 2 Step : install OpenVINOTM Intel distribution of toolkit core components
- The first 3 Step : Configuration environment
- The first 4 Step : Configure the model optimizer
- window- paddle- openVINO Hook up
- Step1: download PaddleX Forecast code
- Step2 Software dependency
- Step3: Use Visual Studio 2019 Compile directly CMake
- Step4: forecast
- Linux install openVINO
- The first 1 Step : install OpenVINOTM Intel distribution of toolkit core components
- The first 2 Step : Install external software dependencies
- The first 3 Step : Configuration environment
- The first 4 Step : Configure the model optimizer
- Predictive deployment testing
- Step1 download PaddleX Forecast code
- Step2 Software dependency
- Step3: compile
- Step4: forecast
- OpenVINO Deployment FAQs
- paddlepaddle Training for
- paddle Model training and parameter adjustment
- Model compression optimization
- Deployment model export
- Example demonstration of propeller
- Portrait segmentation model
- Pre training model and test data
- Pre training model
- About the prediction sawtooth problem
- Test data
- Quickly experience video streaming portrait segmentation
- Pre dependence
- Video stream portrait segmentation assisted by optical flow tracking
- Portrait background replacement
- Model Fine-tune
- Pre dependence
- model training
- assessment
- forecast
- Model export
- RGB Remote sensing image segmentation
- Multi channel remote sensing image segmentation
- Parcel change detection
- OpenVINO Model transformation
- paddle- openVINO Deployment instance
- openvino-yolo
- openvino-PaddleOCR
- Handwriting recognition ancient poetry
- adopt OpenVINO function Paddle Detection
- Loading pictures
- Yes PaddleDetection After processing the reasoning result of
- stay openvino Identification of flying slurry running on
- The pretreatment is delivered to Paddle Recognized images
- Load the Network
- Begin to recognize ancient poetry
- Visual detection and recognition results
Why choose paddle+openVINO?
Paddlepaddle It is a deep learning framework launched by Baidu in China ,Openvino Intel is based on X86 A deployment scheme proposed by the chip of architecture .
The main problem that the propeller solves is AI Developers' huge demand for computing resources , Flying oars provide an online cloud platform , You can use their computer card equipment to train and evaluate the model .
and openVINO Solve the problem that there is no graphics card or insufficient computing power on the host AI The developer's question .
The combination of the two parts , Greatly reduced AI The threshold of developers' demand for computing resources , So as to achieve lower cost AI application development . Models trained with oars cannot be deployed directly to openVINO On , But through two transformations . Model derivation of the propeller ONNX Model , Then transform this model into IR Model , Can be realized in openVINO Deployment on .
Hui He TF、pytorch、caffe Conflict ?
This part is not only conflict free , It also helps to understand these three frameworks . The framework of the flying oar has many grammars that are very similar to the three , And it's simple , Easy to use . It can help you understand some more complex architectures in the algorithm on the propeller . The second is that these three can also be in openVINO The upper part
Three pictures make it clear openVINO- Flying propeller
These three are from making Hackathon Three during the training intel Engineer pengjiali 、 Yang Yicheng 、raymondlo Information , Three diagrams can explain this process clearly .
1、openVINO Deployment process

Now this model mainly consists of structure 、 Optimize 、 Deploy Tools to achieve incremental learning , Retrain the model based on the data we developers need , It can meet our requirements for accuracy and industrial efficiency . It can take advantage of existing open model zoo Help our developers , It can also be based on mainstream TF、pytorch、PP Model transformation .
modeloptimizer and inference engine
In the optimization stage of the model, we use two core components ,modeloptimizer and inference engine. The former mainly plays a role of transferring and optimizing the third-party model , Turn it into OPENVINO Supported by the IR(intermediate representation.bin .xml) Model middle expression .inference engine Will read these IR Model expressions , And put it into the corresponding hardware , Optimize it at the bottom , And operator merging and model simplification . Deployment belongs to the third stage , In the build .
post-training optimization tool &deep learning workbench
such as post-training optimization tool Mainly for some specific scenarios of the model , Do some quantification and tailoring of the model .deep learning workbench It is mainly based on a visual web Some accuracy of the interface adjustment model , As well as an input and output result of each class of it for a tuning .
deep learning streaming
Besides , It also integrates a large number of third-party tools . for instance deep learning streaming Such a tool , Help developers go right decode and encode Do streaming processing .openCL Accelerate the pre-processing and post-processing of the model, as well as some optimization acceleration and corresponding development .
There are also some finished scripts that can be used to compare the accuracy and performance of the application model , And related performance optimization .
model server
Then the final model deployment , It is deployed in the form of server model server Upper , As long as through the request The output result of this model can be accurately obtained by calling the output result of this model in the form of interface .( This is just a mention , It is recommended that you use Baidu's public cloud server )
development manager
For some specific scenarios of this edge calculation , Also provided development manager. Through this tool, developers can tailor deployment packages for industrial fields . Because in some scenes , Our developers may only need cpu, There is no need for other warehouses of the original factory at the bottom , Then we can eliminate these libraries during deployment , Minimize the whole deployment package .
Finally, the whole software is also supported in X86 Build the deployment of all hardware products .
2、paddlepaddle+OpenVINO
Propeller and openVINO Nesting between the two , In fact, it is the same as the above process , We use paddle Model , Then our propeller model is converted into IR Model , Or you can directly deploy part of the propeller model to the hardware , Thus, the whole process deployment and development are realized .
openVINO Software architecture

front end
openVINO The software architecture can be divided into two parts: the front end and the back end , The corresponding code is ours read_network Function interface and load_network These two function interfaces . The main function of the front end is through our read_network Interface to read and parse the third-party model , Then through some of our general 、 The way to optimize , Some of the models layer Make some optimizations . These optimizations are generic , For example, based on, for example, some layer A layer fusion is performed on some sparse graphs of , In other words, some operators in the system may not be needed in the reasoning process , We will eliminate this useless operator for him . Then transform the transformed model into ours CNNnetwork, That is, the function of the front end .
There are three main methods to build the front-end code .
First of all, it can be based on our parameter interface as shown on the left side of the figure below , To manually determine the topology and corresponding parameters of a model , And turn it into CNNnetwork In the form of .
Secondly, it also passed modeloptimizer To transform a third-party model , formation IR The middle expression of the model , And pass IR Read and parse the model , Directly into this CNNnetwork.
The third and most challenging , adopt paddle reader The component directly reads and loads the propeller model . adopt paddle converter This constructs a one-to-one mapping to the corresponding operator , Support the front end , In the end, I will directly paddle Load in CNNnetwork The Internet .
Back end
adopt load_network This function interface specifies which hardware platform the model will run on .load_network This function interface will load the optimized CNNnetwork, And push it to the designated hardware platform for a front-end reasoning . In this process, we will do some customized optimization for different hardware platforms , For example, we will use memory rearrangement or some parallel reasoning , To achieve some deep optimization , Ensure that the best reasoning efficiency can be achieved on the specified platform . Through this interface, you can also make some customized optimization settings . For example, we can specify to run on multiple hardware platforms on this interface , In this way, it can support multiple data streams . At the same time, it can also realize such a pattern as heterogeneous reasoning , You can generate multiple reasoning requests at the same time , Then these reasoning situations are equally distributed to different computing units , Give multiple tasks such a reasoning at the same time , Improve the throughput of the whole network .
There are three main difficulties
1、 The first part is the configuration of different environments , Now it is mainly WINDOWS Systems and Linux System configuration , Apple system can also be used .
2、 The second part is the mastery, derivation and transformation of the propeller training model .
3、 The third part is how to transform the exported model into IR Model and deploy to openVINO On .
(PS: If you have mastered the application , You can try to do the operator transformation of different models , This is a very low-level and also a challenge to train people's basic skills , for instance PP-OPENVINO Transformation of operators, etc )
The difficulties and key points of the whole process are composed of these three parts , Let's solve these three problems at once .
Paddlepaddle-PaddleX-openVINO Installation and environment deployment
First, let's briefly introduce the structure of the propeller , This reference Baidu official product “ Deep learning zero basic time ” A picture in a book , Speak very clearly . Scholars in different fields can find corresponding systems , But here are the two core parts , One is paddle, One is paddleX, The former is the core framework , Use this core framework to use other frameworks , and paddleX It is a full process tool for development , Used to develop your own AI Model .

PaddleX Introduce
Here, please refer to the official technical document of Baidu PaddlePaddle Click to learn more
PaddleX The visualization client is based on PaddleX Developed visual deep learning model training suite , Currently, it supports image classification in the field of training vision 、 object detection 、 Instance segmentation and semantic segmentation , It also supports model clipping 、 Model quantization compresses the model in two ways .
PaddleX All model training in can be summarized as follows 3 A step
Definition : The process 、 Data sets and models , You can get one AI Model 
The following is a simple code to show a development process , But it is not recommended that friends try , Because at this time, my friend's computer has not been installed paddlepaddle, But it can help you understand this process .
Take vegetable classification as an example PaddleX Develop the whole process
- install PaddleX
Installation related issues will be discussed in detail next .
pip install paddlex -i https://mirror.baidu.com/pypi/simple
- Prepare the vegetable classification data set
wget https://bj.bcebos.com/paddlex/datasets/vegetables_cls.tar.gz
tar xzvf vegetables_cls.tar.gz
- Define training / Verify the image processing flow transforms
Because data enhancement operation is added during training , Therefore, in the process of training and verification , The data processing flow of the model needs to be defined separately . As shown below , Code in train_transforms Added RandomCrop and RandomHorizontalFlip Two ways of data enhancement , For more methods, please refer to the official data enhancement document .
from paddlex.cls import transforms
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224),
transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=256),
transforms.CenterCrop(crop_size=224),
transforms.Normalize()
])
- Definition dataset Load image classification dataset
Define datasets ,pdx.datasets.ImageNet Means read ImageNet Classified dataset in format
train_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/train_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/val_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=eval_transforms)
- Use MobileNetV3_small_ssld The model starts training
Here we use Baidu based distillation method MobileNetV3 Pre training model , Model structure and MobileNetV3 Agreement , But more accurate .PaddleX Built in 20 Multiple classification models
num_classes = len(train_dataset.labels)
model = pdx.cls.MobileNetV3_small_ssld(num_classes=num_classes)
model.train(num_epochs=20,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4, 6, 8],
save_dir='output/mobilenetv3_small_ssld',
use_vdl=True)
- The training process uses VisualDL Check the changes of training indicators
During training , The indicators of the model in the training set and verification set will be output to the command terminal in the form of standard output stream . When the user sets use_vdl=True when , You can also use VisualDL Format the index to save_dir In the catalog vdl_log Folder , Run the following command at the terminal to start visualdl And view the changes of visual indicators .
visualdl --logdir output/mobilenetv3_small_ssld --port 8001
After the service starts , Open via browser https://0.0.0.0:8001 or https://localhost:8001 that will do .
- Load training saved model predictions
The model is in the training process , The model will be saved once every certain number of rounds , The best round evaluated on the validation set will be saved in save_dir In the catalog best_model Folder . The model can be loaded in the following way , To make predictions .
import paddlex as pdx
model = pdx.load_model('output/mobilenetv3_small_ssld/best_model')
result = model.predict('vegetables_cls/bocai/100.jpg')
print("Predict Result: ", result)
The prediction results are output as follows ,
Predict Result: Predict Result: [{'score': 0.9999393, 'category': 'bocai', 'category_id': 0}]
So now , You have finished once AI The development of the model , Even the most complicated industrial engineering , It is the refinement of these three steps .
Just now we mentioned , Want to use paddle X Users' computers must have paddlepaddle Environment (paddlepaddle-gpu or paddlepaddle( Version greater than or equal to 1.8.1), Next, let me talk about different environments paddle Installation .
1、 install paddle paddle
First of all, the computer environment of each user is not necessarily the same , So Baidu official provides the following page guidance , Open the link below , Choose the computer environment you belong to , You can get relevant installation instructions , Generally, the installation can be completed in more than ten minutes .
Here is the official guidance .
https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/macos-pip.html
2.win/Mac/linux/anaconda/pip/pycocotools
install paddleX
pip install
Here is Windows Installation command
pip install paddlex -i https://mirror.baidu.com/pypi/simple
Anaconda install
Anaconda It's an open source Python Release version , It contains conda、Python etc. 180 Multiple science packs and their dependencies . Use Anaconda You can create multiple independent Python Environmental Science , Avoid user's Python The environment installs too many different version dependencies, resulting in conflicts .
Code installation
git clone https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
git checkout release/1.3
python setup.py install
pycocotools Installation problems
PaddleX rely on pycocotools package , If installed pycocotools Failure , It can be installed as follows pycocotools
Windows System
Windows Installation may prompt Microsoft Visual C++ 14.0 is required, This will cause installation errors , This is the time to download VC build tools Perform the following installation pip command
Download link
https://go.microsoft.com/fwlink/?LinkId=691126
Be careful : After the installation , You need to reopen the new terminal command window
pip install cython
pip install git+https://gitee.com/jiangjiajun/philferriere-cocoapi.git#subdirectory=PythonAPI
Linux/Mac System
Linux/Mac Under the system , Use it directly pip Install the following two dependencies
pip install cython
pip install pycocotools
Next Previous
3、openVINO The installation is suitable for the relevant environment
If using window The partners of the operating system can refer to a blog written before when they encounter difficulties , There are screenshots of each step .
Blog links
But here because of the need to adapt to the propeller , So the downloaded version has some specific requirements . It is recommended to use OpenVINO 2020.4 And 2021.1 edition
Be careful :
because PaddleX The segmentation model uses ReSize-11 Op,OpenVINO 2021.1 Version starts to support Resize-11 ,CPU Please be sure to download OpenVINO 2021.1+ edition
because VPU stay OpenVINO 2021.1 The classification model converted under version will appear Range layer Not supported ,VPU Please be sure to download OpenVINO 2020.4 edition
You can see the major software and hardware equipment pairs openVINO Support for 
Windows install openVINO
Let's first talk about some environments to be installed
What's the problem? If you still don't understand it after reading it , You can see the official technical documents
https://docs.openvino.ai/latest/openvino_docs_install_guides_installing_openvino_windows.html
precondition
Visual Studio 2019
OpenVINO 2020.4 perhaps 2021.1+
CMake 3.0+
python3.6+
Let me remind you again :CPU Next use OpenVINO 2021.1+ edition ;VPU Please use the OpenVINO 2020.4 edition
Installation steps
1、 Install external software dependencies
2、 install OpenVINOTM Intel distribution of Toolkit
3、 Configuration environment
4、 Configure the model optimizer
The first 1 Step : Install external software dependencies
1、Microsoft Visual Studio* 2019 with MSBuild
https://visualstudio.microsoft.com/vs/older-downloads/#visual-studio-2019-and-other-products
2、CMake 3.14 or higher 64-bit
https://cmake.org/download/
3、Python - 64-bit
https://www.python.org/downloads/windows/

The first 2 Step : install OpenVINOTM Intel distribution of toolkit core components
1、 Apply to from Windows Of OpenVINOTM Intel distribution of toolkit download OpenVINOTM Intel distribution of toolkit files . Select apply to from the drop-down menu Windows Of OpenVINOTM Intel distribution of Toolkit .
2、 go to “Downloads” Folder , Double click in
w_openvino_toolkit_p_.exe, Open a window , Allows you to choose the installation directory and components .

3、 Follow the instructions on the screen . Pay attention to the following information , In case you have to complete other steps :

4、 By default ,IntelDistribution of OpenVINO Install to the following directory , Elsewhere in the document it is called <INSTALL_DIR>: C:\Program Files (x86)\Intel\ openvino_. For the sake of simplicity , Also created a shortcut to the latest installation :C:\Program Files (x86)\Intel\ openvino_2021.
5、 Optional : You can choose customization to change the installation directory or the components to be installed .
single click “ complete ” To close the installation wizard .
single click “ complete ” To close the installation wizard , A new browser window will open , It contains the document you are reading ( In case you don't install ), Then jump to the section containing the subsequent installation steps .
The core components are now installed . Continue to the next section to install additional dependencies .
The first 3 Step : Configuration environment

Multiple environment variables must be updated , Then you can compile and run OpenVINOTM Applications . Open Command Prompt , And then run setupvars.bat Batch file to temporarily set environment variables :
C:\ Program files (x86)\Intel\openvino_2021\bin\setupvars.bat
Be careful : It is not recommended to run the configuration command Windows PowerShell, Use the command prompt instead (cmd), Here I tried , Only use terminals , Not advice .
Suggest : When closing the command prompt window ,OpenVINO Toolkit environment variables will be deleted . As an option , You can set environment variables permanently manually .
The first 4 Step : Configure the model optimizer
Model Optimizer Is based on Python Command line tools for , Used to learn from popular deep learning frameworks ( Such as Caffe、TensorFlow*、Apache MXNet*、ONNX and Kaldi) Import a well-trained model .
The model optimizer is OpenVINO Kit key components released by Intel . Perform inference on the model (ONNX and nGraph Except for models ) You need to run the model through the model optimizer . When transforming the pre trained model through the model optimizer , The output is the intermediate representation of the network (IR). The middle representation is a pair of files that describe the whole model :
.xml: Describe network topology
.bin: Contains weight and offset binary data
1、 Enter cmd Open Command Prompt , Then press Enter key . Enter the command... In the open window :
2、 Go to the model optimizer prerequisites directory .
cd C:\Program Files (x86)\Intel\openvino_2021\deployment_tools\model_optimizer\install_prerequisites
3、 Run this batch file to configure Caffe、TensorFlow 2.x、MXNet、Kaldi* and ONNX Model optimizer :
install_prerequisites.bat
Be careful : installed OpenVINO After that, you need to add OpenVINO Directory to system environment variable , Otherwise, when running the program, it will appear that it cannot be found dll The situation of . To install OpenVINO Time doesn't change OpenVINO The case of installation directory is an example ,
The process is as follows
My computer -> attribute -> Advanced system setup -> environment variable
Find... In the system variable Path( If not , Create your own ), And double-click edit
newly build , Separately OpenVINO Fill in the following path and save :
C:\Program File (x86)\IntelSWTools\openvino\inference_engine\bin\intel64\Release
C:\Program File (x86)\IntelSWTools\openvino\inference_engine\external\tbb\bin
C:\Program File (x86)\IntelSWTools\openvino\deployment_tools\ngraph\lib
Please ensure that the above basic software has been installed in the system , And configure the corresponding environment , All the following examples take the working directory as D:\projects demonstration .
window- paddle- openVINO Hook up
Use here c++ How to predict deployment
Step1: download PaddleX Forecast code
open win Terminal , In D Download the prediction code
d:
mkdir projects
cd projects
git clone https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
git checkout release/1.3
explain : among C++ The prediction code is PaddleX\deploy\openvino Catalog , This directory does not depend on any PaddleX Other directories .
Step2 Software dependency
It provides a precompiled Library of dependent software :
Download the opencv After that, you need to configure environment variables , The flow is as follows - My computer -> attribute -> Advanced system setup -> environment variable - Find... In the system variable Path( If not , Create your own ), And double-click edit - newly build , take opencv Fill in the path and save , Such as D:\projects\opencv\build\x64\vc14\bin
Step3: Use Visual Studio 2019 Compile directly CMake
open Visual Studio 2019 Community, Click continue without code
Click on : file -> open ->CMake choice C++ The path where the prediction code is located ( for example D:\projects\PaddleX\deploy\openvino), And open CMakeList.txt
Click on : project ->CMake Set up
Click Browse , Set the compilation options and specify OpenVINO、Gflags、NGRAPH、OPENCV The path of

After setting up , Click save and generate CMake Cache to load variables . 5. Click generation -> Generate all
Step4: forecast
Above Visual Studio 2019 The compiled executable file is in out\build\x64-Release Under the table of contents , open cmd, And switch to that directory :
D:
cd D:\projects\PaddleX\deploy\openvino\out\build\x64-Release
After successful compilation , Picture prediction demo The entry procedure of is detector.exe,classifier.exe,segmenter.exe, Users can choose according to their own model type , The main command parameters are described as follows :
test :
stay CPU Do the classification task of a single picture to predict the test picture /path/to/test_img.jpeg
Directly input the downlink code at the terminal to see whether the prediction can succeed
./classifier.exe --model_dir=/path/to/openvino_model --image=/path/to/test_img.jpeg --cfg_file=/path/to/PadlleX_model.yml
If it works , Congratulations, you can be in window The system uses both .
Linux install openVINO
If you still don't understand something after reading it , You can directly look at the official technical documents .
https://docs.openvino.ai/latest/openvino_docs_install_guides_installing_openvino_linux.html
Next up Linux Installation steps of , Relatively speaking, it is windows It's easy :
1、 install OpenVINOTM Intel distribution of Toolkit
2、 Install external software dependencies
3、 Configuration environment
4、 Configure the model optimizer
The first 1 Step : install OpenVINOTM Intel distribution of toolkit core components
Apply to from Linux Of OpenVINOTM Intel distribution of toolkit *OpenVINOTM tool kit Download Intel distribution of package files . Select apply to from the drop-down menu Linux Package's OpenVINOTM Intel distribution of Toolkit .
1、 Open the command prompt terminal window . Use keyboard shortcuts :Ctrl+Alt+T
2、 Change the directory to your download Linux* Of package files OpenVINO Intel distribution of toolkit .
3、 If you download the package file to the current user's Downloads Catalog :
cd ~/ download /
By default , The file is saved as l_openvino_toolkit_p_.tgz, for example l_openvino_toolkit_p_2021.4.689.tgz.
4、 decompression .tgz file :
tar -xvzf l_openvino_toolkit_p_<version>.tgz
5、 go to l_openvino_toolkit_p_ Catalog :
cd l_openvino_toolkit_p_< edition >
6、 Choose the installation option , And run the relevant script as the root , To use the graphical user interface (GUI) Installation wizard or command line instructions (CLI).GUI Provide screenshots ,CLI No screenshots . The following information also applies to CLI, It is very helpful for installation , You can see the same choices and tasks .
Options 1:GUI Installation wizard :
sudo ./install_GUI.sh
Options 2: Command line description :
Sudo ./install.sh
Options 3: Command line mute description :
sudo sed -i's/decline/accept/g' silent.cfg
sudo ./install.sh -s silent.cfg
7、 Pay attention to the following information , In case you have to complete other steps , See if there is a lack of environment :
For root or administrator :/opt/intel/openvino_/
For ordinary users :/home//intel/openvino_/
For the sake of simplicity , Also created symbolic links for the latest installation :/opt/intel/openvino_2021/ or /home//intel/openvino_2021/
8、“ complete ” The screen indicates that the core components have been installed :
single click “ complete ” After closing the installation wizard , This document will be used to open a new browser window . It jumps to the section containing the subsequent installation steps .
By default ,OpenVINOTM The Intel distribution of is installed in the following directory :
The first 2 Step : Install external software dependencies
If you will OpenVINOTM Install the Intel distribution of to a non default directory , Please put /opt/intel Replace with the directory where the software is installed .
These dependencies are necessary for the following conditions :
Intel optimized OpenCV Library build
Deep learning reasoning engine
Deep learning model optimizer tools
1、 go to install_dependencies Catalog :
cd /opt/intel/openvino_2021/install_dependencies
2、 Run scripts to download and install external software dependencies :
sudo -E ./install_openvino_dependencies.sh
After installing the dependencies , Continue to the next section to set environment variables .
The first 3 Step : Configuration environment
Multiple environment variables must be updated , Then you can compile and run OpenVINOTM Applications . Use vi( as follows ) Or the preferred editor sets the following persistent environment variables :
1、 stay /home/ Open in .bashrc file :
vi ~/.bashrc
2、 Press i Key to switch to insert mode .
3、 Add the following line to the end of the file :
source /opt/intel/openvino_2021/bin/setupvars.sh
4、 Save and close file : Press Esc Key and type :wq.
5、 To verify changes , Please open a new terminal . You will see [setupvars.sh] OpenVINO Environment initialized .
source /opt/intel/openvino_2021/bin/setupvars.sh
Set the environment variable . Next , The model optimizer will be configured .
The first 4 Step : Configure the model optimizer
because CentOS Informal support TensorFlow frame , Therefore, you cannot configure and run on this operating system TensorFlow Model optimizer .
*
Model Optimizer Is based on Python Command line tools for , Used to learn from popular deep learning frameworks ( Such as Caffe、TensorFlow、Apache MXNet、ONNX and Kaldi) Import a well-trained model .
The model optimizer is OpenVINO Kit key components released by Intel . Perform inference on the model (ONNX and nGraph Except for models ) You need to run the model through the model optimizer . When the pre training model is run through the model optimizer , The output is the intermediate representation of the network (IR). The middle representation is a pair of files that describe the whole model :
.xml: Describe network topology
.bin: Contains weight and offset binary data
1、 Go to the model optimizer prerequisites directory :
cd /opt/intel/openvino_2021/deployment_tools/model_optimizer/install_prerequisites
2、 Run the script as Caffe、TensorFlow 2.x、MXNet、Kaldi and ONNX Configure the model optimizer :
sudo ./install_prerequisites.sh
If it's already installed paddle and openVINO after , And configure the corresponding environment , All the examples below are based on the working directory /root/projects/ demonstration .
Predictive deployment testing
The document provides c++ How to predict deployment , If you need to python Please refer to python Forecast deployment
Step1 download PaddleX Forecast code
mkdir -p /root/projects
cd /root/projects
git clone https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
git checkout release/1.3
explain : among C++ The prediction code is PaddleX/deploy/openvino Catalog , This directory does not depend on any PaddleX Other directories .
Step2 Software dependency
Step3 The compilation script in will install the precompiled package of the third-party dependent software with one click , Users do not need to download or compile these dependent software separately .
Step3: compile
compile cmake Command on scripts/build.sh in , If in raspberry pie (Raspbian OS) Please modify ARCH Parameters x86 by armv7, If you compile the third-party dependent software by yourself, please follow Step1 Modify the main parameters according to the actual situation of the compiled software , The main contents are as follows :
#openvino The path of the precompiled Library
OPENVINO_DIR=$INTEL_OPENVINO_DIR/inference_engine
#gflags The path of the precompiled Library
GFLAGS_DIR=$(pwd)/deps/gflags
#ngraph lib The path of the precompiled Library
NGRAPH_LIB=$INTEL_OPENVINO_DIR/deployment_tools/ngraph/lib
#opencv The path of the precompiled Library
OPENCV_DIR=$(pwd)/deps/opencv/
#cpu framework (x86 or armv7)
ARCH=x86
perform build Script :
sh ./scripts/build.sh
Step4: forecast
You can run the following example
linux The system is in CPU Do the classification task of a single picture to predict the test picture /path/to/test_img.jpeg
./build/classifier --model_dir=/path/to/openvino_model --image=/path/to/test_img.jpeg --cfg_file=/path/to/PadlleX_model.yml
After successful compilation , The prediction executable program of classification task is classifier, The prediction executable program of the detection task is detector, The prediction executable program of segmentation task is segmenter, The main command parameters are described as follows :
Start training
Save the code locally and run ( The code download link is located in the table above ), The code will automatically download training data and start training . If saved as deeplabv3p_mobilenetv2_x0.25.py, Execute the following commands to start training :
python deeplabv3p_mobilenetv2_x0.25.py
OpenVINO Deployment FAQs
In the process of converting the model ”ModuleNotFoundError: No module named ‘mo’”
reason : This problem is mainly due to the installation OpenVINO Not initialized after OpenVINO Environmental solutions : find OpenVINO Initialize the environment script , This problem can be solved after running
Linux System initialization OpenVINO Environmental Science
1)root User installation , With OpenVINO 2021.1 Version as an example , Run the following command to initialize
source /opt/intel/openvino_2021/bin/setupvars.sh
2) Not root User installation , With OpenVINO 2021.1 edition 、 The user is called paddlex For example , Run the following command to initialize
source /home/paddlex/intel/openvino_2021/bin/setupvar.sh
Window System initialization OpenVINO Environmental Science
With OpenVINO 2021.1 Version as an example , Execute the following command to initialize OpenVINO Environmental Science
cd C:\Program Files (x86)\Intel\openvino_2021\bin\
setupvars.bat
paddlepaddle Training for
Data preparation ( Data tagging 、 transformation 、 Divide )
Use Labelme mark
The website links :
https://paddlex.readthedocs.io/zh_CN/release-1.3/data/annotation/labelme.html
LabelMe Installation and startup of
LabelMe Installation and startup of
LabelMe It can be used for marking target detection 、 Instance segmentation 、 Semantic segmentation dataset , Is an open source annotation tool .
- install Anaconda
Recommended Anaconda install python rely on , Experienced developers can skip this step . install Anaconda You can refer to the documentation .
In the installation Anaconda, And create the environment , Then proceed to the next step
- install LabelMe
Get into Python After environment , Execute the following command
conda activate my_paddlex
conda install pyqt
pip install labelme
- start-up LabelMe
Enter the installation LabelMe Of Python Environmental Science , Execute the following command to start LabelMe
conda activate my_paddlex
labelme
Image classification
Image classification and annotation is the most basic , The simplest annotation task , Users only need to put pictures belonging to the same category in the same folder , For example, the directory structure shown below ,
MyDataset/ # Image classification dataset root directory
|--dog/ # All pictures in the current folder belong to dog Category
| |--d1.jpg
| |--d2.jpg
| |--...
| |--...
|
|--...
|
|--snake/ # All pictures in the current folder belong to snake Category
| |--s1.jpg
| |--s2.jpg
| |--...
| |--...
Data partitioning
When training the model , We need to divide the training set , Validation set and test set , Therefore, it is necessary to divide the above data , Use it directly paddlex Command to randomly divide the data set into 70% Training set ,20% Validation set and 10% Test set
paddlex --split_dataset --format ImageNet --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
Divided data sets are generated additionally labels.txt, train_list.txt, val_list.txt, test_list.txt Four files , Then you can train directly .
object detection
It is recommended to use LabelMe Dimensioning tools , If not previously installed , that LabelMe For installation, please refer to LabelMe Installation and startup
The website links :
https://paddlex.readthedocs.io/zh_CN/release-1.3/data/annotation/labelme.html
Be careful :LabelMe Do not appear Chinese characters in the following path and file name !
preparation
1、 Store the collected images in JPEGImages Under the folder , For example, stored in D:\MyDataset\JPEGImages
2、 Create a folder corresponding to the image folder Annotations, For storing annotations json file , Such as D:MyDataset\Annotations
3、 open LabelMe, Click on ”Open Dir“ Button , Select the folder where the image to be marked is located and open , be ”File List“ The dialog box will display the absolute path corresponding to all images , Then you can start traversing each image , Carry out marking work
Target box label
1、 Open the rectangle dimension tool ( Right-click menu ->Create Rectangle), The details are shown in the following figure 
2、 Use drag to identify the target object , And write the corresponding... In the pop-up dialog box label( When label Click when it already exists , Please note here label Do not use Chinese ), The details are shown in the following figure , When the box is marked incorrectly , Click... On the left “Edit Polygons” Then click the label box , Modify by dragging , You can also click “Delete Polygon” To delete .
3、 Click the right side. ”Save“, Save the dimension results to the folder created in Annotations Directory
format conversion
LabelMe The marked data needs to be converted into PascalVOC or MSCOCO Format , Can be used for target detection task training , establish D:\dataset_voc Catalog , stay python Installation in the environment paddlex after , Use the following command
paddlex --data_conversion --source labelme --to PascalVOC \
--pics D:\MyDataset\JPEGImages \
--annotations D:\MyDataset\Annotations \
--save_dir D:\dataset_voc
Data set partitioning
After converting the data , For training , You also need to divide the data into training sets 、 Validation set and test set , Also installing paddlex after , Use the following command to divide the data into 70% Training set ,20% Validation set and 10% Test set of
paddlex --split_dataset --format VOC --dataset_dir D:\MyDataset --val_value 0.2 --test_value 0.1
Execute the above command line , Will be in D:\MyDataset Lower generation labels.txt, train_list.txt, val_list.txt and test_list.txt, Store category information separately , List of training samples , Verify sample list , List of test samples
Instance segmentation
preparation
1、 Store the collected images in JPEGImages Under the folder , For example, stored in D:\MyDataset\JPEGImages
2、 Create a folder corresponding to the image folder Annotations, For storing annotations json file , Such as D:MyDataset\Annotations
3、 open LabelMe, Click on ”Open Dir“ Button , Select the folder where the image to be marked is located and open , be ”File List“ The dialog box will display the absolute path corresponding to all images , Then you can start traversing each image , Carry out marking work
Target edge annotation
1、 Open the polygon annotation tool ( Right-click menu ->Create Polygon) Circle the outline of the target by punctuation , And write the corresponding... In the pop-up dialog box label( When label Click when it already exists , Please note here label Do not use Chinese ), The details are as follows , When the box is marked incorrectly , Click... On the left “Edit Polygons” Then click the label box , Modify by dragging , You can also click “Delete Polygon” To delete . 
2、 Click the right side. ”Save“, Save the dimension results to the folder created in Annotations Directory
format conversion
LabelMe The marked data needs to be converted into MSCOCO Format , Can be used for instance segmentation task training , Create a save Directory D:\dataset_seg, stay python Installation in the environment paddlex after , Use the following command
paddlex --data_conversion --source labelme --to MSCOCO \
--pics D:\MyDataset\JPEGImages \
--annotations D:\MyDataset\Annotations \
--save_dir D:\dataset_coco
Data set partitioning
After converting the data , For training , You also need to divide the data into training sets 、 Validation set and test set , Also installing paddlex after , Use the following command to divide the data into 70% Training set ,20% Validation set and 10% Test set of
paddlex --split_dataset --format COCO --dataset_dir D:\MyDataset --val_value 0.2 --test_value 0.1
Execute the above command line , Will be in D:\MyDataset Lower generation train.json, val.json, test.json, Store training sample information separately , Verify sample information , Test sample information
Semantic segmentation
preparation
1、 Store the collected images in JPEGImages Under the folder , For example, stored in D:\MyDataset\JPEGImages
2、 Create a folder corresponding to the image folder Annotations, For storing annotations json file , Such as D:MyDataset\Annotations
3、 open LabelMe, Click on ”Open Dir“ Button , Select the folder where the image to be marked is located and open , be ”File List“ The dialog box will display the absolute path corresponding to all images , Then you can start traversing each image , Carry out marking work
Target edge annotation
1、 Open the polygon annotation tool ( Right-click menu ->Create Polygon) Circle the outline of the target by punctuation , And write the corresponding... In the pop-up dialog box label( When label Click when it already exists , Please note here label Do not use Chinese ), The details are as follows , When the box is marked incorrectly , Click... On the left “Edit Polygons” Then click the label box , Modify by dragging , You can also click “Delete Polygon” To delete .
2、 Click the right side. ”Save“, Save the dimension results to the folder created in Annotations Directory
format conversion
LabelMe The marked data needs to be converted into SEG Format , Can be used for the training of semantic segmentation tasks , Create a save Directory D:\dataset_seg, stay python Installation in the environment paddlex after , Use the following command
paddlex --data_conversion --source labelme --to SEG \
--pics D:\MyDataset\JPEGImages \
--annotations D:\MyDataset\Annotations \
--save_dir D:\dataset_seg
Data set partitioning
After converting the data , For training , You also need to divide the data into training sets 、 Validation set and test set , Also installing paddlex after , Use the following command to divide the data into 70% Training set ,20% Validation set and 10% Test set of
paddlex --split_dataset --format SEG --dataset_dir D:\MyDataset --val_value 0.2 --test_value 0.1
Execute the above command line , Will be in D:\MyDataset Lower generation train_list.txt, val_list.txt, test_list.txt, Store training sample information separately , Verify sample information , Test sample information
data format
Image classification ImageNet
Folder data structure
stay PaddleX in , Image classification support ImageNet Dataset format . Dataset catalog data_dir There are multiple folders under , The images in each folder belong to the same category , The name of a folder is called a class alias ( Be careful not to include Chinese in the path , Space ). The following is an example structure
MyDataset/ # Image classification dataset root directory
|--dog/ # All pictures in the current folder belong to dog Category
| |--d1.jpg
| |--d2.jpg
| |--...
| |--...
|
|--...
|
|--snake/ # All pictures in the current folder belong to snake Category
| |--s1.jpg
| |--s2.jpg
| |--...
| |--...
Divide the training set and the verification set
For training , We need to be in MyDataset Prepare under the directory train_list.txt, val_list.txt and labels.txt Three files , Respectively used to represent the training set list , Validation set list and category label list . Click to download the image classification sample data set
notes : You can also use PaddleX Bring their own tools , Randomly divide the data set , After the data set is organized according to the above format , Use the following commands to quickly complete the random division of data sets , among val_value Represents the proportion of the validation set ,test_value Represents the scale of the test set ( It can be for 0), The remaining proportion is used for the training set .
paddlex --split_dataset --format ImageNet --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
labels.txt
labels.txt Used to list all categories , The line number corresponding to the category represents the category in the model training process id( Line number from 0 Start counting ), for example labels.txt For
dog
cat
snake
That is, there are 3 Categories , Respectively dog,cat and snake, In model training dog Corresponding category id by 0, cat Corresponding 1, And so on
train_list.txt
train_list.txt List a collection of pictures for training , Its corresponding category id, Examples are as follows
dog/d1.jpg 0
dog/d2.jpg 0
cat/c1.jpg 1
... ...
snake/s1.jpg 2
The first column is relative MyDataset Relative path of , The second column is the category of the corresponding category of the picture id
val_list.txt
val_list List the image integration used for verification , Its corresponding category id, Format and train_list.txt Agreement
PaddleX Dataset loading
The sample code is as follows ,
import paddlex as pdx
from paddlex.cls import transforms
train_transforms = transforms.Compose([
transforms.RandomCrop(crop_size=224), transforms.RandomHorizontalFlip(),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByShort(short_size=256),
transforms.CenterCrop(crop_size=224), transforms.Normalize()
])
train_dataset = pdx.datasets.ImageNet(
data_dir='./MyDataset',
file_list='./MyDataset/train_list.txt',
label_list='./MyDataset/labels.txt',
transforms=train_transforms)
eval_dataset = pdx.datasets.ImageNet(
data_dir='./MyDataset',
file_list='./MyDataset/eval_list.txt',
label_list='./MyDataset/labels.txt',
transforms=eval_transforms)
Next Previous
object detection PascalVOC
Dataset folder structure
stay PaddleX in , Target detection support PascalVOC Dataset format . It is recommended that users organize data sets as follows , The original drawings are all placed in the same directory , Such as JPEGImages, The same name of the dimension xml All files are placed in the same directory , Such as Annotations, Examples are as follows
MyDataset/ # Target detection dataset root directory
|--JPEGImages/ # The directory where the original drawing file is located
| |--1.jpg
| |--2.jpg
| |--...
| |--...
|
|--Annotations/ # Mark the directory where the file is located
| |--1.xml
| |--2.xml
| |--...
| |--...
Divide the training set and the verification set
For training , We need to be in MyDataset Prepare under the directory train_list.txt, val_list.txt and labels.txt Three files , Respectively used to represent the training set list , Validation set list and category label list . Click to download the sample data set of target detection
notes : You can also use PaddleX Bring their own tools , Randomly divide the data set , After the data set is organized according to the above format , Use the following commands to quickly complete the random division of data sets , among val_value Represents the proportion of the validation set ,test_value Represents the scale of the test set ( It can be for 0), The remaining proportion is used for the training set .
paddlex --split_dataset --format VOC --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
labels.txt
labels.txt Used to list all categories , The line number corresponding to the category represents the category in the model training process id( Line number from 0 Start counting ), for example labels.txt For
dog
cat
snake
Indicates that there are 3 Target categories , Respectively dog,cat and snake, In model training dog Corresponding category id by 0, cat Corresponding 1, And so on
train_list.txt
train_list.txt List a collection of pictures for training , Its corresponding annotation file , Examples are as follows
JPEGImages/1.jpg Annotations/1.xml
JPEGImages/2.jpg Annotations/2.xml
... ...
The first column is opposite to the original MyDataset Relative path of , The second column is relative to the annotation file MyDataset Relative path of
val_list.txt
val_list List the image integration used for verification , Its corresponding annotation file , Format and val_list.txt Agreement
PaddleX Dataset loading
The sample code is as follows ,
import paddlex as pdx
from paddlex.det import transforms
train_transforms = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.Normalize(),
transforms.ResizeByShort(short_size=800, max_size=1333),
transforms.Padding(coarsest_stride=32)
])
eval_transforms = transforms.Compose([
transforms.Normalize(),
transforms.ResizeByShort(short_size=800, max_size=1333),
transforms.Padding(coarsest_stride=32),
])
train_dataset = pdx.datasets.VOCDetection(
data_dir='./MyDataset',
file_list='./MyDataset/train_list.txt',
label_list='./MyDataset/labels.txt',
transforms=train_transforms)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='./MyDataset',
file_list='./MyDataset/val_list.txt',
label_list='MyDataset/labels.txt',
transforms=eval_transforms)
Next Previous
Instance segmentation MSCOCO
Dataset folder structure
stay PaddleX in , Instance segmentation support MSCOCO Dataset format (MSCOCO The format can also be used for target detection ). It is recommended that users organize data sets as follows , The original drawings are all placed in the same directory , Such as JPEGImages, Mark the file ( Such as annotations.json) Put the JPEGImages Under the same level directory of the directory , The example structure is as follows
MyDataset/ # Instance partition dataset root directory
|--JPEGImages/ # The directory where the original drawing file is located
| |--1.jpg
| |--2.jpg
| |--...
| |--...
|
|--annotations.json # Mark the directory where the file is located
Divide the training set and the verification set
stay PaddleX in , In order to distinguish between training set and verification set , stay MyDataset At the same directory , Use different json Represents the division of data , for example train.json and val.json. Click to download the instance segmentation sample data set .
notes : You can also use PaddleX Bring their own tools , Randomly divide the data set , After the data set is organized according to the above format , Use the following commands to quickly complete the random division of data sets , among val_value Represents the proportion of the validation set ,test_value Represents the scale of the test set ( It can be for 0), The remaining proportion is used for the training set .
paddlex --split_dataset --format COCO --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
MSCOCO The data annotation file adopts json Format , User available Labelme, Wizard annotation assistant or EasyData And other annotation tools , See data annotation tool
PaddleX Load data set
The sample code is as follows ,
import paddlex as pdx
from paddlex.det import transforms
train_transforms = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.Normalize(),
transforms.ResizeByShort(short_size=800, max_size=1333),
transforms.Padding(coarsest_stride=32)
])
eval_transforms = transforms.Compose([
transforms.Normalize(),
transforms.ResizeByShort(short_size=800, max_size=1333),
transforms.Padding(coarsest_stride=32),
])
train_dataset = pdx.dataset.CocoDetection(
data_dir='./MyDataset/JPEGImages',
ann_file='./MyDataset/train.json',
transforms=train_transforms)
eval_dataset = pdx.dataset.CocoDetection(
data_dir='./MyDataset/JPEGImages',
ann_file='./MyDataset/val.json',
transforms=eval_transforms)
Next Previous
Semantic segmentation Seg
Dataset folder structure
stay PaddleX in , Mark the document as png file . It is recommended that users organize data sets as follows , The original drawings are all placed in the same directory , Such as JPEGImages, The same name of the dimension png All files are placed in the same directory , Such as Annotations, Examples are as follows
MyDataset/ # Semantic segmentation dataset root directory
|--JPEGImages/ # The directory where the original drawing file is located
| |--1.jpg
| |--2.jpg
| |--...
| |--...
|
|--Annotations/ # Mark the directory where the file is located
| |--1.png
| |--2.png
| |--...
| |--...
Semantic segmentation annotation image , Such as 1.png, Is a single channel image , Pixel annotation categories need to be from 0 Began to increase ( commonly 0 Express background background ), for example 0, 1, 2, 3 Express 4 Species category , The maximum number of annotation categories 255 Categories ( Where pixel value 255 Do not participate in training and evaluation ).
Divide the training set and the verification set
For training , We need to be in MyDataset Prepare under the directory train_list.txt, val_list.txt and labels.txt Three files , Respectively used to represent the training set list , Validation set list and category label list . Click to download the semantic segmentation sample data set
notes : You can also use PaddleX Bring their own tools , Randomly divide the data set , After the data set is organized according to the above format , Use the following commands to quickly complete the random division of data sets , among val_value Represents the proportion of the validation set ,test_value Represents the scale of the test set ( It can be for 0), The remaining proportion is used for the training set .
paddlex --split_dataset --format Seg --dataset_dir MyDataset --val_value 0.2 --test_value 0.1
labels.txt
labels.txt Used to list all categories , The line number corresponding to the category represents the category in the model training process id( Line number from 0 Start counting ), for example labels.txt For
background
human
car
Indicates that there are 3 Split categories , Respectively background,human and car, In model training background Corresponding category id by 0, human Corresponding 1, And so on , If you don't know the specific category label , But directly in labels.txt Write line by line 0,1,2… Sequence .
train_list.txt
train_list.txt List a collection of pictures for training , Its corresponding annotation file , Examples are as follows
JPEGImages/1.jpg Annotations/1.png
JPEGImages/2.jpg Annotations/2.png
... ...
The first column is opposite to the original MyDataset Relative path of , The second column is relative to the annotation file MyDataset Relative path of
val_list.txt
val_list List the image integration used for verification , Its corresponding annotation file , Format and val_list.txt Agreement
PaddleX Dataset loading
The sample code is as follows ,
import paddlex as pdx
from paddlex.seg import transforms
train_transforms = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ResizeRangeScaling(),
transforms.RandomPaddingCrop(crop_size=512),
transforms.Normalize()
])
eval_transforms = transforms.Compose([
transforms.ResizeByLong(long_size=512),
transforms.Padding(target_size=512),
transforms.Normalize()
])
train_dataset = pdx.datasets.SegDataset(
data_dir='./MyDataset',
file_list='./MyDataset/train_list.txt',
label_list='./MyDataset/labels.txt',
transforms=train_transforms)
eval_dataset = pdx.datasets.SegDataset(
data_dir='./MyDataset',
file_list='./MyDataset/val_list.txt',
label_list='MyDataset/labels.txt',
transforms=eval_transforms)
Plot detection ChangeDet
Dataset folder structure
stay PaddleX in , Mark the document as png file . It is recommended that users organize data sets as follows , The original geomorphic maps of the same plot in different periods are placed in the same directory , Such as JPEGImages, The same name of the dimension png All files are placed in the same directory , Such as Annotations, Examples are as follows
MyDataset/ # Semantic segmentation dataset root directory
|--JPEGImages/ # The directory where the original drawing file is located , It contains pictures of the same object in the early and late stages
| |--1_1.jpg
| |--1_2.jpg
| |--2_1.jpg
| |--2_2.jpg
| |--...
| |--...
|
|--Annotations/ # Mark the directory where the file is located
| |--1.png
| |--2.png
| |--...
| |--...
The original geomorphic map of the same plot in different periods , Such as 1_1.jpg and 1_2.jpg, It can be RGB Color images 、 grayscale 、 or tiff Format multi-channel image . Semantic segmentation annotation image , Such as 1.png, Is a single channel image , Pixel annotation categories need to be from 0 Began to increase ( commonly 0 Express background background ), for example 0, 1, 2, 3 Express 4 Species category , The maximum number of annotation categories 255 Categories ( Where pixel value 255 Do not participate in training and evaluation ).
Divide the training set and the verification set
For training , We need to be in MyDataset Prepare under the directory train_list.txt, val_list.txt and labels.txt Three files , Respectively used to represent the training set list , Validation set list and category label list .
labels.txt
labels.txt Used to list all categories , The line number corresponding to the category represents the category in the model training process id( Line number from 0 Start counting ), for example labels.txt For
unchanged
changed
Indicates that there are 2 Split categories , Respectively unchanged and changed, In model training unchanged Corresponding category id by 0, changed Corresponding 1, And so on , If you don't know the specific category label , But directly in labels.txt Write line by line 0,1,2… Sequence .
train_list.txt
train_list.txt List a collection of pictures for training , Its corresponding annotation file , Examples are as follows
JPEGImages/1_1.jpg JPEGImages/1_2.jpg Annotations/1.png
JPEGImages/2_1.jpg JPEGImages/2_2.jpg Annotations/2.png
... ...
The first column and the second column are opposite to the original MyDataset Relative path of , Corresponding to the geomorphic images of the same block in different periods , The third column is relative to the annotation file MyDataset Relative path of
val_list.txt
val_list List the image integration used for verification , Its corresponding annotation file , Format and val_list.txt Agreement
paddle Model training and parameter adjustment
model training
Image classification
PaddleX A total of 20+ Image classification model , It can meet the needs of developers in different scenarios .
-Top1 precision : Model in ImageNet Test accuracy on datasets
- Forecast speed : The prediction time of a single picture ( It does not include pretreatment and post-treatment )
-“-” Indicates that the index has not been updated 
Start training
Save the code locally and run ( The code download link is located in the table above ), The code will automatically download training data and start training . If saved as mobilenetv3_small_ssld.py, Execute the following commands to start training :
python mobilenetv3_small_ssld.py
object detection
PaddleX Currently provided FasterRCNN and YOLOv3 Two detection structures , Varied backbone Model , It can meet the needs of developers in different scenarios and performances .
-Box MMAP: Model in COCO Test accuracy on datasets
- Forecast speed : The prediction time of a single picture ( It does not include pretreatment and post-treatment )
-“-” Indicates that the index has not been updated

Start training
Save the code locally and run ( The code download link is located in the table above ), The code will automatically download training data and start training . If saved as yolov3_mobilenetv1.py, Execute the following commands to start training :
python yolov3_mobilenetv1.py
Instance segmentation
PaddleX Currently provided MaskRCNN Instance segmentation model structure , Varied backbone Model , It can meet the needs of developers in different scenarios and performances .
-Box MMAP/Seg MMAP: Model in COCO Test accuracy on datasets
- Forecast speed : The prediction time of a single picture ( It does not include pretreatment and post-treatment )
-“-” Indicates that the index has not been updated 
Start training
Save the code locally and run ( The code download link is located in the table above ), The code will automatically download training data and start training . If saved as mask_rcnn_r50_fpn.py, Execute the following commands to start training :
python mask_rcnn_r50_fpn.py
Semantic segmentation
PaddleX Currently provided DeepLabv3p、UNet、HRNet and FastSCNN Four semantic segmentation structures , Varied backbone Model , It can meet the needs of developers in different scenarios and performances .
-mIoU: Model in CityScape Test accuracy on datasets
- Forecast speed : The prediction time of a single picture ( It does not include pretreatment and post-treatment )
-“-” Indicates that the index has not been updated

Start training
Save the code locally and run ( The code download link is located in the table above ), The code will automatically download training data and start training . If saved as deeplabv3p_mobilenetv2_x0.25.py, Execute the following commands to start training :
python deeplabv3p_mobilenetv2_x0.25.py
Load model predictions
Image classification
Load model predictions
PaddleX have access to paddlex.load_model Interface loading model ( Including the model saved during the training , Exported deployment model , Quantitative model and tailored model ) To make predictions , meanwhile PaddleX A series of visualizer functions are also built in , Help users conveniently check the effect of the model .
Be careful : Use paddlex.load_model Interface loading is only used for model prediction , If you need to continue training based on this model , This model can be used as a pre training model for training , The specific method is in the training code , take train Function pretrain_weights The parameter is specified as the pre training model path .
Image classification
Click to download The model in the following example code
import paddlex as pdx
test_jpg = 'mobilenetv3_small_ssld_imagenet/test.jpg'
model = pdx.load_model('mobilenetv3_small_ssld_imagenet')
result = model.predict(test_jpg)
print("Predict Result: ", result)
The output is as follows :
Predict Result: [{'category_id': 549, 'category': 'envelope', 'score': 0.29062933}]
The test picture is as follows :
object detection
Click to download The model in the following example code
import paddlex as pdx
test_jpg = 'yolov3_mobilenetv1_coco/test.jpg'
model = pdx.load_model('yolov3_mobilenetv1_coco')
#predict The interface does not filter low confidence identification results , Users can press score Value to filter
result = model.predict(test_jpg)
# The visualization results are stored in ./visualized_test.jpg, See the picture below
pdx.det.visualize(test_jpg, result, threshold=0.3, save_dir='./')

Instance segmentation
Instance segmentation
Click to download The model in the following example code
import paddlex as pdx
test_jpg = 'mask_r50_fpn_coco/test.jpg'
model = pdx.load_model('mask_r50_fpn_coco')
# predict The interface does not filter low confidence identification results , Users can press score Value to filter
result = model.predict(test_jpg)
# The visualization results are stored in ./visualized_test.jpg, See the picture below
pdx.det.visualize(test_jpg, result, threshold=0.5, save_dir='./')

Semantic segmentation
Semantic segmentation
Click to download the model in the following example code
import paddlex as pdx
test_jpg = './deeplabv3p_mobilenetv2_voc/test.jpg'
model = pdx.load_model('./deeplabv3p_mobilenetv2_voc')
result = model.predict(test_jpg)
# The visualization results are stored in ./visualized_test.jpg, See the picture on the right ( The picture on the left is the original )
pdx.seg.visualize(test_jpg, result, weight=0.0, save_dir='./')
In the above example code , By calling paddlex.seg.visualize The prediction results of semantic segmentation can be visualized , The visualization results are saved in save_dir Next , See the picture below . among weight Parameters are used to adjust the weight when the prediction results and the original results are fused ,0.0 Only the prediction results are displayed mask Visualization ,1.0 Only show the original image visualization .
Training parameter adjustment
PaddleX In all training interfaces , The built-in parameters are based on the single GPU Card corresponding batch_size Better parameters under , Users train models on their own data , When it comes to parameter adjustment , If you don't have much experience in parameter tuning , You can refer to the following methods
1.num_epochs Adjustment of
num_epochs Is the total number of rounds of model training iterations ( The model passes all the samples of the training set once, which is one epoch), The user can set a larger value , According to the index performance of the model iteration process on the verification set , To judge whether the model converges , And then terminate the training in advance . You can also use train Interface early_stop Strategy , During the training process, the model will automatically judge whether the model converges and automatically stop .
2.batch_size and learning_rate
Batch Size Refers to the model in the training process , Forward calculation once ( It's a step) Number of samples used
If you use multi card training , batch_size Will be equally distributed to each card ( So we need to let batch size Divide the number of cards )
Batch Size With the machine's video memory / Memory is highly correlated ,batch_size The higher the , Consumed video memory / The higher the memory
PaddleX In all train The interface is configured with the default batch size( The default is for single GPU card ), If prompted during training GPU There is not enough video memory , Then lower it accordingly BatchSize, If so GPU Display memory high or use multiple GPU Card time , It can be raised accordingly BatchSize.
If users adjust batch size, Note that other parameters need to be adjusted accordingly , especially train The default in the interface is learning_rate value . If in YOLOv3 In the model , Default train_batch_size by 8,learning_rate by 0.000125, When the user puts the model in 2 When training on the card machine , Can be train_batch_size Adjusted for 16, So at the same time learning_rate It can also be adjusted to 0.000125 * 2 = 0.00025
3.warmup_steps and warmup_start_lr
In training the model , Generally, pre training model will be used , For example, the detection model is used in training backbone stay ImageNet Pre training weights on data sets . But because in self training , Own data and ImageNet There are big differences in data sets , At first, there may be problems in training due to the gradient , In this case, you can start training , Let the learning rate take a smaller value , Slowly increase to the set learning rate .warmup_steps and warmup_start_lr That's how it works , When the model starts training , The learning rate will increase from warmup_start_lr Start , stay warmup_steps individual batch After data iteration, it grows linearly to the set learning rate .
for example YOLOv3 Of train Interface , Default train_batch_size by 8,learning_rate by 0.000125, warmup_steps by 1000, warmup_start_lr by 0.0; Under this parameter configuration, it means , The model starts training , before 1000 individual step( Every step Use one batch The data of , namely 8 Samples ) Inside , The learning rate will increase from 0.0 Start linear growth to the set 0.000125.
4.lr_decay_epochs and lr_decay_gamma
lr_decay_epochs It is used to make the learning rate gradually decline in the later stage of model training , It's usually a list, Such as [6, 8, 10], Indicates that the learning rate is at 6 individual epoch Decay once , The first 8 individual epoch Decay again , The first 10 individual epoch Decay again . Each learning rate decays to the previous learning rate *lr_decay_gamma.
for example YOLOv3 Of train Interface , Default num_epochs by 270,learning_rate by 0.000125, lr_decay_epochs by [213, 240],lr_decay_gamma by 0.1; Under this parameter configuration, it means , The model starts training , before 213 individual epoch in , The learning rate used in training is 0.000125, In the 213 to 240 individual epoch Between , The learning rate used in training is 0.000125x0.1=0.0000125, stay 240 individual epoch after , The learning rate used is 0.000125x0.1x0.1=0.00000125
5. Constraints during parameter setting
According to the above parameters , It can be seen that the change of learning rate is divided into WarmUp Warm up phase and Decay Attenuation stage ,
Wamup Warm up phase : As the training iterations , The learning rate increases linearly from a lower value to a set value , With step In units of
Decay Attenuation stage : As the training iterations , The learning rate gradually declines , For example, each attenuation is the previous 0.1, With epoch In units of
step And epoch The relationship between :1 individual epoch By multiple step form , For example, the training samples are 800 Zhang image ,train_batch_size by 8, Then each epoch Use this completely 800 A picture teaches a model , And each epoch A total of 800//8 namely 100 individual step
stay PaddleX in , constraint warmup Must be in Decay It's over , Therefore, the parameter settings need to meet the following conditions
warmup_steps <= lr_decay_epochs[0] * num_steps_each_epoch
among num_steps_each_epoch The calculation method is as follows ,
num_steps_each_eposh = num_samples_in_train_dataset // train_batch_size
therefore , If you start training , Prompted warmup_steps should be less than… when , That means you need to adjust your parameters according to the above formula , You can adjust lr_decay_epochs Or is it warmup_steps.
6. How to use more GPU Card to train
stay import paddlex Pre configuration environment variables , The code is as follows
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # Use 0 Number GPU Card to train
# Be careful paddle or paddlex You need to set environment variables before import
import paddlex as pdx
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '' # Don't use GPU, Use CPU Training
import paddlex as pdx
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,3' # Also use section 0、1、3 Number GPU Card to train
import paddlex as pdx
Model preservation
The training process is saved
PaddleX During model training , according to train In the function interface save_interval_epoch Parameter setting , Save the model once every corresponding number of rounds , The model directory contains model.pdparams, model.yml Wait for the documents .
Models saved during training , Can be used as pretrain_weights Continuous training model , You can also use paddlex.load_model Prediction and evaluation of interface loading test model .
Deployment model export
The model saved in the training mentioned above , For deployment ( See PaddleX The multi terminal deployment chapter of the model in the document ), It needs to be exported to the deployed model format , The deployed model directory contains __model__,params__ and model.yml Three files .
The model is deployed in Python level , You can use... Based on a high-performance prediction library python Interface paddlex.deploy.Predictor, You can also use paddlex.load_model Interface .
【 summary 】 If the model directory contains model.pdparams, That means the model is saved during the training , Export is required during deployment ; The deployed model directory needs to contain __model,__params__ and model.yml Three files .
Model deployment file description
model: The network structure information of the model is saved
params: The parameter weights in the model network are saved
model.yml: stay PaddleX in , Preprocess the model , post-processing , And category related information are stored in this file
The model is exported as ONNX Model
PaddleX As an open source suite , Most of these models support exporting as ONNX agreement , Meet the diverse needs of developers .
It should be noted that ONNX There are multiple OpSet edition , The table below for PaddleX Each model supports exported ONNX Protocol version .
Model compression optimization
Model of the cutting
Model clipping can better meet the requirements of end-to-side 、 Performance requirements under the deployment scenario on the mobile terminal , It can effectively reduce the volume of the model , And the amount of calculation , Accelerate predictive performance .PaddleX Integrated PaddleSlim Sensitivity based channel clipping algorithm , Users can go to PaddleX Easy to use in the training code .
The tailoring process of the classification model is shown in this document , The code in the document and the tailoring code of more other models can be found in Github Medium tutorials/slim/prune Directory get .
Usage method
Model cutting is relatively better than our ordinary training of a model , There will be two more steps
1. Train a model in a normal way
2. Sensitivity analysis of the parameters of the model
3. According to the first 2 Sensitivity information obtained in step , Crop the model , And with the 1 Step trained model as pre training weight , Keep training
Specifically, we use image classification model MobileNetV2 For example , All the code in this example can be found in Github Of [tutorials/slim/prune/image_classification] gain .
First step Normal training model
In this step, normal code is used for model training , After getting this sample code , Execute the following command directly
python mobilenetv2_train.py
After training , We use output/mobilenetv2/best_model Saved models , Continue with the next steps
The second step Parameter sensitivity analysis
In this step , We need to load the model saved in the first step of training , And by constantly traversing the parameters , Analyze the accuracy loss on the validation data set after cutting each parameter , So as to judge the sensitivity of each parameter . The code of sensitivity analysis is very simple , Users can directly view params_analysis.py. Execute the following command at the command line terminal to start parameter analysis .
python params_analysis.py
In this step , We will be preserved mobilenetv2.sensi.data file , This file saves the sensitivity of each parameter in the model , In the subsequent tailoring training , According to the information saved in this file , Cut the parameters . meanwhile , We can also visually analyze this file , Judge eval_metric_loss The relationship between the size setting of the model and the clipping scale .(eval_metric_loss See Step 3 )
See slim_visualize.py, Execute the following command
python slim_visualize.py
The visualization results are as follows , The picture shows , When we will eval_metric_loss Set to 0.05 when , The model will be cut out 65%; take eval_metric_loss Set to 0.10, The model will be cut out 68.0%. So in actual use , We can meet our needs , To set up eval_metric_loss Control the cropping scale .
The third step Model cutting training
In the first two steps , We got the model preserved by normal training output/mobilenetv2/best_model And the parameter sensitivity information file obtained based on the saved model mobilenetv2.sensi.data, Next is the training of model cutting . The first step of the code of model tailoring training is basically the same , The only difference is in the last train Function , We changed it pretrain_weights,save_dir,sensitivities_file and eval_metric_loss Four parameters , As shown below
model.train(
num_epoch=10,
train_dataset=train_dataset,
train_batch_size=32,
eval_dataset=eval_dataset,
lr_decay_epochs=[4,6,8],
learning_rate=0.025,
pretrain_weights='output/mobilenetv2/best_model',
save_dir='output/mobilenetv2_prune',
sensitivities_file='./mobilenetv2.sensi.data',
eval_metric_loss=0.05,
use_vdl=True)
See for specific code tutorials/slim/prune/image_classification/mobilenetv2_prune_train.py, Execute the following command
python mobilenetv2_prune_train.py
Modified 4 The parameter functions are as follows
1、pretrain_weights: Pre training weights , In tailoring training , Designate it as the model path obtained in the first step of normal training
2、save_dir: During tailoring training , New path of model saving
3、sensitivities_file: In the second step, the sensitivity information file of each parameter is analyzed
4、
eval_metric_loss: It can be used to control the proportion of the model finally cut , See the visualization instructions in step 2
Cutting effect
On the dataset of this example , After cutting training , The effect comparison of the model is as follows , The prediction speed does not include image preprocessing and result post-processing . As you can see from the table , For the simple dataset in this example , Cut out the model 68% after , The accuracy of the model has not decreased , stay CPU It takes less time to predict a single picture 37%
Model quantification
Model quantization converts the calculation of the model from floating-point to integer , So as to accelerate the prediction and calculation speed of the model , In mobile terminal / Reduce the volume of the model on the edge device .
notes : The quantified model , adopt PaddleLite Convert to PaddleLite After the deployed model format , The volume of the model will be greatly compressed . If the quantified model is still in the format of local deployment of the server ( Documents including __model__ and __params__), Then the file size of the model cannot show parameter changes .
Usage method
PaddleX The quantification function has been used as an example of model Export API, The code is used as follows , This sample code and model data can be accessed through GitHub Code on the project tutorials/slim/quant/image_classification To obtain
import paddlex as pdx
model = pdx.load_model('mobilenetv2_vegetables')
# Load data sets for quantification
dataset = pdx.datasets.ImageNet(
data_dir='vegetables_cls',
file_list='vegetables_cls/train_list.txt',
label_list='vegetables_cls/labels.txt',
transforms=model.test_transforms)
# Start quantifying
pdx.slim.export_quant_model(model, dataset,
batch_size=4,
batch_num=5,
save_dir='./quant_mobilenet',
cache_dir='./tmp')
After getting this sample code , Execute the following commands to complete quantization and PaddleLite Model export of
# take mobilenetv2 Model quantification preservation
python mobilenetv2_quant.py
# Export the quantized model as PaddleLite Deployment format
python paddlelite_export.py
Quantify the effect
In this example , We can see the format of the server deployment model after the quantification of the model server_mobilenet and quant_mobilenet In both directories , The size of model parameters does not change . But in the use of PaddleLite After export ,mobilenetv2.nb and mobilenetv2_quant.nb The sizes are 8.8M, 2.7M, I'm going to compress it to the original 31%.
Deployment model export
When deploying the model on the server, you need to export the model saved in the training process as inference Format model , Derived inference The format model includes __model__、__params__ and model.yml Three files , Respectively represent the network structure of the model 、 Model weights and model configuration files ( Including data preprocessing parameters, etc ).
Check your model folder , If it's inside model.pdparams, model.pdmodel and model.yml3 When you create a file , Then you need to export the model according to the following process
After installation PaddleX after , Use the following command at the command line terminal to export the model . You can directly download the Xiaodu bear sorting model to test the process of this document xiaoduxiong_epoch_12.tar.gz.
paddlex --export_inference --model_dir=./xiaoduxiong_epoch_12 --save_dir=./inference_model

Use TensorRT When predicting , The input size of the model needs to be fixed , adopt –fixed_input_shape To set the input size [w,h].
Be careful :
1、 Please keep the fixed input size of the classification model consistent with the input size during training ;
2、 In the detection model YOLO Please save the series w And h Agreement , And for 32 Multiple size of ;3、RCNN Class has no such limitation , You can specify [w,h] when ,w and h Separated by commas , Spaces and other characters are not allowed .
4、 Need to pay attention to ,w,h The larger the setting , The time and memory required by the model in the prediction process / The higher the occupation of video memory ; Set too small , It will affect the accuracy of the model
paddlex --export_inference --model_dir=./xiaoduxiong_epoch_12 --save_dir=./inference_model --fixed_input_shape=[640,960]
Example demonstration of propeller
Portrait segmentation model
This tutorial is based on PaddleX The core segmentation model realizes portrait segmentation , Open the pre training model and test data 、 Support video streaming portrait segmentation 、 Provide models Fine-tune To Paddle Lite Mobile terminal and Nvidia Jeston Application guide for the whole process of embedded device deployment .
Pre training model and test data
Pre training model
This case opens two models trained on large-scale portrait data sets , To meet the needs of server-side scenarios and mobile side scenarios . Using these models, you can quickly experience video streaming portrait segmentation , It can also be deployed to mobile terminals or embedded devices for real-time portrait segmentation , It can also be used to complete the model Fine-tuning.

1、Checkpoint Parameter Is the model weight , be used for Fine-tuning scene , contain __params__ Model parameters and model.yaml Basic model configuration information .
2、Inference Model and Quant Inference Model Deploy models for forecasting , contain __model__ Calculation chart structure 、__params__ Model parameters and model.yaml Basic model configuration information .
among Inference Model For server CPU and GPU Forecast deployment ,Qunat 3、3、Inference Model For quantitative version , Suitable for passing through Paddle Lite Deploy end-to-end devices such as mobile terminals .
About the prediction sawtooth problem
After training the model , You may encounter predicted results 『 sawtooth 』 The problem of , The possible reason for this is that the model is in the prediction process , Experienced the process of zooming and zooming in the original image , The flow is as follows ,
Original drawing input -> Preprocessing transforms Zoom the image to the target size -> Paddle Model to predict -> The prediction result is enlarged to the size of the original image
For the problems caused by this reason , You can manually modify model.yml file , Adjust the target size in preprocessing to a higher level to optimize this problem , Such as portrait segmentation provided in this document server In the end model model.yml The contents of the document , modify target_size to 1024*1024( This will also bring more resources for model prediction , Prediction is slower )
Model: DeepLabv3p
Transforms:
- Resize:
interp: LINEAR
target_size:
- 512
- 512
It is amended as follows
Model: DeepLabv3p
Transforms:
- Resize:
interp: LINEAR
target_size:
- 1024
- 1024
The storage size and reasoning duration of the pre training model are as follows , The running environment of the mobile terminal model is cpu: Xiao dragon 855, Memory :6GB, Picture size :192*192
Execute the following script to download all the pre training models :
~ download PaddleX Source code :
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
~ The code to download the pre training model is located at PaddleX/examples/human_segmentation, Enter this directory :
cd PaddleX/examples/human_segmentation
~ Execute download
python pretrain_weights/download_pretrain_weights.py
Test data
supervise.ly Released the portrait segmentation data set Supervisely Persons, In this case, a small part of data is randomly selected and transformed into PaddleX Data format that can be loaded directly , Run the following code to download the data 、 And the portrait test video taken by the front camera of the mobile phone video_test.mp4.
The code to download the test data is located at PaddleX/xamples/human_segmentation, Enter the directory and perform the download :
python data/download_data.py
Quickly experience video streaming portrait segmentation
Pre dependence
PaddlePaddle >= 1.8.0
Python >= 3.5
PaddleX >= 1.0.0
For installation related problems, please refer to PaddleX install
download PaddleX Source code :
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
The execution files of video stream portrait segmentation and background replacement are located in PaddleX/examples/human_segmentation, Enter this directory :
cd PaddleX/examples/human_segmentation
Video stream portrait segmentation assisted by optical flow tracking
This case will DIS(Dense Inverse Search-basedmethod) The prediction results of optical flow tracking algorithm are consistent with PaddleX The segmentation results of , So as to improve the effect of video streaming portrait segmentation . Run the following code to experience , The following code is located in PaddleX/xamples/human_segmentation:
Real time segmentation processing through computer camera
python video_infer.py --model_dir pretrain_weights/humanseg_mobile_inference
Segment the offline portrait video
python video_infer.py --model_dir pretrain_weights/humanseg_mobile_inference --video_path data/video_test.mp4
The video segmentation results are as follows :
Portrait background replacement
This case also realizes the portrait background replacement function , Replace the background picture of the portrait according to the selected background , The background can be a picture , It can also be a video . The code of portrait background replacement is located in PaddleX/xamples/human_segmentation, Enter the directory and execute :
Real time background replacement processing through computer camera , adopt ’–background_video_path’ Pass in the background video
python bg_replace.py --model_dir pretrain_weights/humanseg_mobile_inference --background_image_path data/background.jpg
Background replacement for portrait video , adopt ’–background_video_path’ Pass in the background video
python bg_replace.py --model_dir pretrain_weights/humanseg_mobile_inference --video_path data/video_test.mp4 --background_image_path data/background.jpg
Replace the background of a single image
python bg_replace.py --model_dir pretrain_weights/humanseg_mobile_inference --image_path data/human_image.jpg --background_image_path data/background.jpg
The result of background replacement is as follows :

Be careful :
Video segmentation processing time takes a few minutes , Please be patient .
The model provided is applicable to the vertical screen shooting scene of the mobile camera , The widescreen effect will be slightly worse .
Model Fine-tune
Pre dependence
PaddlePaddle >= 1.8.0
Python >= 3.5
PaddleX >= 1.0.0
For installation related problems, please refer to PaddleX install
download PaddleX Source code :
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
Portrait segmentation training 、 assessment 、 forecast 、 Model export 、 The execution files of offline quantification are located in PaddleX/examples/human_segmentation, Enter this directory :
cd PaddleX/examples/human_segmentation
model training
Use the following command to train the model based on the pre training model , Please make sure to choose the model structure model_type And model parameters pretrain_weights matching . If the test data provided by this case is not required , Replaceable data 、 Select the appropriate model and adjust the training parameters .
# Appoint GPU Card number ( With 0 Take card no )
export CUDA_VISIBLE_DEVICES=0
# If not used GPU, Will CUDA_VISIBLE_DEVICES The specified value is empty
# export CUDA_VISIBLE_DEVICES=
python train.py --model_type HumanSegMobile \
--save_dir output/ \
--data_dir data/mini_supervisely \
--train_list data/mini_supervisely/train.txt \
--val_list data/mini_supervisely/val.txt \
--pretrain_weights pretrain_weights/humanseg_mobile_params \
--batch_size 8 \
--learning_rate 0.001 \
--num_epochs 10 \
--image_shape 192 192
The meaning of parameters is as follows :
–model_type: Model type , Options for :HumanSegServer and HumanSegMobile
–save_dir: Model save path
–data_dir: Dataset path
–train_list: Training set list path
–val_list: Verification set list path
–pretrain_weights: Pre training model path
–batch_size: Batch size
–learning_rate: Initial learning rate
–num_epochs: Number of training rounds
–image_shape: Network input image size (w, h)
More command line help can be viewed by running the following commands :
python train.py --help
Be careful : It can be replaced by –model_type Variables and corresponding –pretrain_weights Try different models quickly .
assessment
Use the following command to evaluate the accuracy of the model on the validation set :
python eval.py --model_dir output/best_model \
--data_dir data/mini_supervisely \
--val_list data/mini_supervisely/val.txt \
--image_shape 192 192
The meaning of parameters is as follows :
–model_dir: Model path
–data_dir: Dataset path
–val_list: Verification set list path
–image_shape: Network input image size (w, h)
forecast
Use the following command to predict the test set , The prediction visualization results are saved in ./output/result/ In the folder .
python infer.py --model_dir output/best_model \
--data_dir data/mini_supervisely \
--test_list data/mini_supervisely/test.txt \
--save_dir output/result \
--image_shape 192 192
The meaning of parameters is as follows :
–model_dir: Model path
–data_dir: Dataset path
–test_list: Test set list path
–image_shape: Network input image size (w, h)
Model export
The model deployed on the server needs to be exported as inference Format model , The exported model will include __model__、__params__ and model.yml Three article names , They are the network structure of the model , Model weights and model configuration files ( Including data preprocessing parameters and so on ). After installation PaddleX after , Use the following commands at the command line terminal to complete the model Export :
paddlex --export_inference --model_dir output/best_model \
--save_dir output/export
The meaning of parameters is as follows :
–model_dir: Model path
–save_dir: Export model save path
RGB Remote sensing image segmentation
This case is based on PaddleX Realize remote sensing image segmentation , Provide sliding window prediction , In order to avoid the occurrence of insufficient memory when directly predicting large-size pictures . Besides , The degree of overlap between sliding windows can be configured , So as to eliminate the crack feeling at the splicing of each window in the final prediction result .
Pre dependence
Paddle paddle >= 1.8.4
Python >= 3.5
PaddleX >= 1.1.4
For installation related problems, please refer to PaddleX install
download PaddleX Source code :
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
All scripts of this case are located in PaddleX/examples/remote_sensing/, Enter this directory :
cd PaddleX/examples/remote_sensing/
Data preparation
Use in this case 2015 CCF High definition remote sensing images provided by big data competition , contain 5 Marked with RGB Images , The maximum image size is 7969 × 7939、 The smallest is 4011 × 2470. The data set is marked with 5 Class object , They are the background ( Marked as 0)、 Vegetation ( Marked as 1)、 road ( Marked as 2)、 Architecture ( Marked as 3)、 Water ( Marked as 4).
This case will be before 4 Pictures are divided into training sets , The first 5 Picture as verification set . To increase the batch size during training , Take sliding window as (1024,1024)、 In steps of (512, 512) To the front 4 Image segmentation , Add the original 4 Large size picture , The training set consists of 688 A picture . Direct verification of large pictures during training will lead to insufficient video memory , To avoid such problems , For the validation set, the sliding window is (769, 769)、 In steps of (769,769) Right. 5 Image segmentation , obtain 40 Zhang Zi picture .
Run the following script , Download the original dataset , And complete data set segmentation :
python prepare_data.py
model training
Split model selection Backbone by MobileNetv3_large_ssld Of Deeplabv3 Model , The model has the advantages of high performance and high accuracy . Run the following script , Model training :
python train.py
You can also skip the model training steps , Download the pre training model directly for subsequent model prediction and evaluation :
wget https://bj.bcebos.com/paddlex/examples/remote_sensing/models/ccf_remote_model.tar.gz
tar -xvf ccf_remote_model.tar.gz
Model to predict
Direct prediction of large-size pictures will lead to insufficient video memory , To avoid such problems , This case provides a sliding window prediction interface , Support overlap and no overlap .
Non overlapping sliding window prediction
Slide on the input image with a fixed size window , Respectively predict the image under each window , Finally, the prediction results of each window are spliced into the prediction results of the input picture . Because the prediction effect of the edge part of each window will be worse than that of the middle part , Therefore, there may be obvious cracks at the splicing of each window .
The prediction method is API The interface is detailed in overlap_tile_predict, When using, you need to set parameters pad_size Set to [0, 0].
There are overlapping sliding window predictions
stay Unet In the paper , The author proposes a sliding window prediction strategy with overlap (Overlap-tile strategy) To eliminate the sense of cracks at the splice . When predicting each sliding window , It will expand a certain area around , Predict the expanded window , For example, the blue area in the figure below , When splicing, only the prediction results of the middle part of each window are taken , For example, the yellow area in the figure below . Window at the edge of the input image , The pixels under the expanded area are filled by mirroring the pixels at the edge .

Compared with non overlapping sliding window prediction , The overlapping sliding window prediction strategy will improve the model accuracy of this case miou from 80.58% Up to the 81.52%, And the crack sense in the prediction visualization results will be significantly eliminated , It can be seen that the effect comparison of the two prediction methods in the figure below .

Run the following script to predict using overlapping sliding windows :
python predict.py
Model to evaluate
In the process of training , every other 10 The number of iterations will evaluate the accuracy of the model in the validation set . Because the original large-size picture has been cut into small pieces in advance , At this time, it is equivalent to using the non overlapping large map to small map prediction , Optimal model accuracy miou by 80.58%. Run the following script , It will adopt the prediction method of cutting overlapping large graphs into small graphs , Re evaluate the model accuracy of the original large-scale image , here miou by 81.52%.
python eval.py
Multi channel remote sensing image segmentation
Remote sensing image segmentation is an important application scene in the field of image segmentation , It is widely used in land surveying and mapping 、 The environmental monitoring 、 Urban construction and other fields . The targets of remote sensing image segmentation are various , There are things like snow 、 Crops 、 road 、 Architecture 、 Water source and other ground objects , There are also aerial targets such as clouds .
This case is based on PaddleX Realize multi-channel remote sensing image segmentation , Covering data analysis 、 model training 、 Model prediction and other processes , It aims to help users solve the problem of multi-channel remote sensing image segmentation by using deep learning technology .
Pre dependence
Paddle paddle >= 1.8.4
Python >= 3.5
PaddleX >= 1.1.4
For installation related problems, please refer to PaddleX install
In addition, you need to install gdal, Use pip install gdal Possible error , Recommended conda Installation :
conda install gdal
download PaddleX Source code :
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
All scripts of this case are located in PaddleX/examples/channel_remote_sensing/, Enter this directory :
cd PaddleX/examples/channel_remote_sensing/
Data preparation
The formats of remote sensing images are various , Different sensors may produce different data formats .PaddleX Now compatible with the following 4 Picture reading in different formats :
tif
png
img
npy
The marking diagram must be single channel png Format image , The pixel value is the corresponding category , Pixel annotation categories need to be from 0 Began to increase . for example 0,1,2,3 Express 4 Species category ,255 Used to specify pixels that do not participate in training and evaluation , The maximum annotation category is 256 class .
Use in this case L8 SPARCS Open data sets for cloud and snow segmentation , The dataset contains 80 Zhang satellite image , cover 10 Band . The original annotation picture contains 7 Categories , Namely cloud, cloud shadow, shadow over water, snow/ice, water, land and flooded. because flooded and shadow over water2 The proportion of categories is only 1.8% and 0.24%, We will merge them ,flooded Classified as land,shadow over water Classified as shadow, The merged annotation contains 5 Categories .
The number 、 Category 、 Color table :


Execute the following command to download and decompress the data set after category merging :
mkdir dataset && cd dataset
wget https://paddleseg.bj.bcebos.com/dataset/remote_sensing_seg.zip
unzip remote_sensing_seg.zip
cd ..
among data The directory stores remote sensing images ,data_vis The directory stores color composite preview pictures ,mask Catalog storage annotation drawing .
Data analysis
Remote sensing images are often composed of many bands , The data distribution of different bands may be quite different , For example, the distribution of visible and thermal infrared bands is very different . In order to better understand the distribution of data to optimize the effect of model training , The data needs to be analyzed .
Statistical analysis of training set with reference to document data analysis , Determine the truncation range of image pixel values , And statistical mean and variance after truncation .
model training
In this case, we choose UNet Semantic segmentation model completes cloud and snow segmentation , Run the following steps to complete the model training , The optimal accuracy of the model miou by 78.38%.
Set up GPU Card number
export CUDA_VISIBLE_DEVICES=0
Run the following script to start training
python train.py --data_dir dataset/remote_sensing_seg \
--train_file_list dataset/remote_sensing_seg/train.txt \
--eval_file_list dataset/remote_sensing_seg/val.txt \
--label_list dataset/remote_sensing_seg/labels.txt \
--save_dir saved_model/remote_sensing_unet \
--num_classes 5 \
--channel 10 \
--lr 0.01 \
--clip_min_value 7172 6561 5777 5103 4291 4000 4000 4232 6934 7199 \
--clip_max_value 50000 50000 50000 50000 50000 40000 30000 18000 40000 36000 \
--mean 0.15163569 0.15142828 0.15574491 0.1716084 0.2799778 0.27652043 0.28195933 0.07853807 0.56333154 0.5477584 \
--std 0.09301891 0.09818967 0.09831126 0.1057784 0.10842132 0.11062996 0.12791838 0.02637859 0.0675052 0.06168227 \
--num_epochs 500 \
--train_batch_size 3
You can also skip the model training steps , Download the pre training model and directly predict the model :
wget https://bj.bcebos.com/paddlex/examples/multi-channel_remote_sensing/models/l8sparcs_remote_model.tar.gz
tar -xvf l8sparcs_remote_model.tar.gz
Model to predict
Run the following script , Predict the remote sensing image and visualize the prediction results , Correspondingly, the corresponding annotation file is also visualized , To compare the prediction effect .
export CUDA_VISIBLE_DEVICES=0
python predict.py
The visualization is as follows :
The number 、 Category 、 Color table :

Parcel change detection
This case is based on PaddleX Realize the detection of plot changes , Splice the early and late pictures of the same plot , Then input it to the semantic segmentation network to predict the changing region . In the training phase , Use random scaling dimensions 、 rotate 、 tailoring 、 Color space disturbance 、 Flip horizontal 、 Flip vertically a variety of data enhancement strategies . In the validation and prediction phase , Use sliding window prediction , In order to avoid the occurrence of insufficient memory when directly predicting large-size pictures .
Pre dependence
Paddle paddle >= 1.8.4
Python >= 3.5
PaddleX >= 1.2.2
For installation related problems, please refer to PaddleX install
download PaddleX Source code :
git clone https://github.com/PaddlePaddle/PaddleX
cd PaddleX
git checkout release/1.3
All scripts of this case are located in PaddleX/examples/change_detection/, Enter this directory :
cd PaddleX/examples/change_detection/
Data preparation
Use in this case Daifeng Peng Others are open Google Dataset, This data set covers some areas of Guangzhou in 2006 - 2019 Changes in houses and buildings during the year , Used to analyze the process of urbanization . Altogether 20 For HD pictures , The picture is red 、 green 、 Blue three bands , The spatial resolution is 0.55m, The size of the picture is 1006x1168 to 4936x5224 Unequal .
because Google Dataset It only indicates whether the building has changed , Therefore, this case is a two category change detection task , The number of categories can be modified according to actual needs, which can be extended to multi category change detection .
This case will 15 Pictures are divided into training sets ,5 Pictures are divided into verification sets . Because the picture size is too large , Direct training will lead to insufficient memory , So take sliding window as (1024,1024)、 In steps of (512, 512) Segment the training pictures , The training set after segmentation has 743 A picture . Take sliding window as (769, 769)、 In steps of (769,769) Segment the verification image , obtain 108 Zhang Zi picture , Used for verification during training .
Run the following script , Download the original dataset , And complete data set segmentation :
python prepare_data.py
The data after segmentation is shown as follows :

Be careful :
tiff Format picture PaddleX Unified use gdal Library to read ,gdal Installation can refer to gdal file . If the data is tiff Three channels of format RGB Images , If you don't want to install gdal, It needs to be converted to jpeg、bmp、png Format picture .
label Documents need to be single channel png Format picture , And label from 0 Start counting , mark 255 Indicates that this category does not participate in the calculation . For example, in this case ,0 Express unchanged class ,1 Express changed class .
model training
Because of the small amount of data , The selection of segmentation model takes into account both shallow detail information and deep semantic information UNet Model . Run the following script , Model training :
python train.py
Use in this case 0,1,2,3 Number GPU Card finish training , You can change the GPU Number of cards and train_batch_size Set the value of , Press train_batch_size Adjust the learning rate accordingly learning_rate, for example train_batch_size from 16 Reduce to 8 when ,learning_rate By 0.1 Reduce to 0.05. Besides , Corresponding to the optimal accuracy can be obtained on different data sets learning_rate It may be different , You can try to adjust .
You can also skip the model training steps , Download the pre training model directly for subsequent model evaluation and prediction :
wget https://bj.bcebos.com/paddlex/examples/change_detection/models/google_change_det_model.tar.gz
tar -xvf google_change_det_model.tar.gz
Model to evaluate
In the process of training , every other 10 The number of iterations will evaluate the accuracy of the model in the validation set . Because the original large-size picture has been cut into small pieces in advance , It is equivalent to using non overlapping sliding window prediction , Optimal model accuracy :

category They correspond to each other unchanged and changed Two types of .
Run the following script , The overlapping sliding window prediction method will be adopted , Re evaluate the model accuracy of the original large-scale image , At this time, the accuracy of the model is :

python eval.py
See API explain , Existing usage scenarios can be referred to RGB Remote sensing segmentation case . The evaluation script can be modified according to the actual video memory size tile_size,pad_size and batch_size.
Model to predict
Execute the following script , Use overlapping sliding prediction windows to predict the validation set . The evaluation script can be modified according to the actual video memory size tile_size,pad_size and batch_size.
python predict.py
The visualization results of prediction are shown in the figure below :
OpenVINO Model transformation
take Paddle The model is converted to OpenVINO Of Inference Engine
1、 Environment depends on
Paddle2ONNX 0.4
ONNX 1.6.0+
PaddleX 1.3+
OpenVINO 2020.4+
explain :PaddleX Please refer to PaddleX , OpenVINO Please refer to OpenVINO,ONNX Please install 1.6.0 Otherwise, there will be a model conversion error in the above version , Paddle2ONNX Please install 0.4 edition .
Be careful : install OpenVINO Please be sure to install the official website tutorial initialization OpenVINO Running environment , And install dependencies , Otherwise ”No module named mo” Other questions
Please ensure that the above basic software has been installed in the system , All the examples below are based on the working directory /root/projects/ demonstration .
2、 export inference Model
paddle Model transfer openvino You need to paddle The model is exported as inference Format model , The exported model will include __model__、__params__ and model.yml Three filenames , The export command is as follows
paddlex --export_inference --model_dir=/path/to/paddle_model --save_dir=./inference_model --fixed_input_shape=[w,h]
Be careful : It needs to be transferred OpenVINO Model time , export inference Please be sure to specify –fixed_input_shape Parameters to fix the input size of the model , And the input size of the model needs to be consistent with the training . PaddleX The client does not have a fixed input size when publishing the model , So for visual clients , Please find the directory where the task is located , From the inside output Folder found best_model Model catalog , Fix this directory with the above command shape Export it .
3、 export OpenVINO Model
mkdir -p /root/projects
cd /root/projects
git clone https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
git checkout release/1.3
cd deploy/openvino/python
python converter.py --model_dir /path/to/inference_model --save_dir /path/to/openvino_model --fixed_input_shape [w,h]
After successful conversion, it will be in save_dir The suffix appears under .xml、.bin、.mapping The three file conversion parameters are described below :

paddle- openVINO Deployment instance
openvino-yolo
Object detection sample code
This demo shows how to OpenVINO Up operation PaddlePaddle YoloV3 Detection algorithm .
First of all, if you want to have a deeper understanding of these , You can see the following three links .
YOLOV3Model Configuration( The model configuration ):
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.1/configs/yolov3
PPYOLO Annotation Data( data ):
https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.2/docs/tutorials/config_annotation/ppyolo_r50vd_dcn_1x_coco_annotation.md
PPYOLO Model Configuration:
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.1/configs/ppyolo
import os, sys, os.path
import numpy as np
import cv2
from openvino.inference_engine import IENetwork, IECore, ExecutableNetwork
from IPython import display
from PIL import Image, ImageDraw
import urllib, shutil, json
import yaml
from yaml.loader import SafeLoader
Download and export Baidu models - YOLOV3 and PPYOLO
This will take some time , Make sure to follow the official website read me The installation instructions in will PaddleDetection GitHub Installed in the openvino-paddlepaddle-demo Directory .
The following is the link to the official website
Reference on Baidu Model Exporting: https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.1/deploy/EXPORT_MODEL.md
#Get the YOLOV3
PADDLE_DET_PATH="../../PaddleDetection"
YML_CONFIG="configs/yolov3/yolov3_darknet53_270e_coco.yml"
PRETRAINED="yolov3_darknet53_270e_coco.pdparams"
OUTPUT_DIR="models"
if(not os.path.isfile("models/yolov3_darknet53_270e_coco/model.pdmodel")):
print("Download and Export Model... This may take a while...")
! python $PADDLE_DET_PATH/tools/export_model.py -c $PADDLE_DET_PATH/$YML_CONFIG -o use_gpu=false weights=https://paddledet.bj.bcebos.com/models/$PRETRAINED "TestReader.inputs_def.image_shape=[3,608,608]" --output_dir=$OUTPUT_DIR
else:
print("Model is already downloaded")
The results show that the model has been downloaded
Model is already downloaded
#Get the PPYOLO (experimental)
PADDLE_DET_PATH="../../PaddleDetection"
YML_CONFIG="configs/ppyolo/ppyolo_r50vd_dcn_1x_coco.yml"
PRETRAINED="ppyolo_r50vd_dcn_1x_coco.pdparams"
OUTPUT_DIR="models"
if(not os.path.isfile("models/ppyolo_r50vd_dcn_1x_coco/model.pdmodel")):
print("Download and Export Model... This may take a while...")
! python $PADDLE_DET_PATH/tools/export_model.py -c $PADDLE_DET_PATH/$YML_CONFIG -o use_gpu=false weights=https://paddledet.bj.bcebos.com/models/$PRETRAINED "TestReader.inputs_def.image_shape=[3,608,608]" --output_dir=$OUTPUT_DIR
else:
print("Model is already downloaded")
Model is already downloaded
#Helper functions
def image_preprocess(input_image, size):
img = cv2.resize(input_image, (size,size))
img = np.transpose(img, [2,0,1]) / 255
img = np.expand_dims(img, 0)
##NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
img_mean = np.array([0.485, 0.456,0.406]).reshape((3,1,1))
img_std = np.array([0.229, 0.224, 0.225]).reshape((3,1,1))
img -= img_mean
img /= img_std
return img.astype(np.float32)
def draw_box(img, results, label_text, scale_x, scale_y):
for i in range(len(results)):
#print(results[i])
bbox = results[i, 2:]
label_id = int(results[i, 0])
score = results[i, 1]
if(score>0.20):
xmin, ymin, xmax, ymax = [int(bbox[0]*scale_x), int(bbox[1]*scale_y),
int(bbox[2]*scale_x), int(bbox[3]*scale_y)]
cv2.rectangle(img,(xmin, ymin),(xmax, ymax),(0,255,0),3)
font = cv2.FONT_HERSHEY_SIMPLEX
label_text = label_list[label_id];
cv2.rectangle(img, (xmin, ymin), (xmax, ymin-70), (0,255,0), -1)
cv2.putText(img, "#"+label_text,(xmin,ymin-10), font, 1.2,(255,255,255), 2,cv2.LINE_AA)
cv2.putText(img, str(score),(xmin,ymin-40), font, 0.8,(255,255,255), 2,cv2.LINE_AA)
return img
Set up the model
You can switch between two different models - The default is PPYolo To compare the performance of the two models
#PPYolo3
#pdmodel_path = "models/yolov3_darknet53_270e_coco"
#PPYolo (experimental)
pdmodel_path = "models/ppyolo_r50vd_dcn_1x_coco"
pdmodel_file = pdmodel_path + "/model.pdmodel"
pdmodel_config = pdmodel_path + "/infer_cfg.yml"
device = 'CPU'
#load the data from config, and setup the parameters
label_list=[]
with open(pdmodel_config) as f:
data = yaml.load(f, Loader=SafeLoader)
label_list = data['label_list'];
take PaddlePaddle The pre training model is loaded into OpenVINO Inference engine (IE) in
ie = IECore()
net = ie.read_network(pdmodel_file)
net.reshape({'image': [1, 3, 608, 608], 'im_shape': [
1, 2], 'scale_factor': [1, 2]})
exec_net = ie.load_network(net, device)
assert isinstance(exec_net, ExecutableNetwork)
Load the image and run the reasoning step
input_image = cv2.imread("horse.jpg")
test_image = image_preprocess(input_image, 608)
test_im_shape = np.array([[608, 608]]).astype('float32')
test_scale_factor = np.array([[1, 2]]).astype('float32')
#print(test_image.shape)
inputs_dict = {'image': test_image, "im_shape": test_im_shape,
"scale_factor": test_scale_factor}
output = exec_net.infer(inputs_dict)
result_ie = list(output.values())
result_image = cv2.imread("horse.jpg")
scale_x = result_image.shape[1]/608*2
scale_y = result_image.shape[0]/608
result_image = draw_box(result_image, result_ie[0], label_list, scale_x, scale_y)
_,ret_array = cv2.imencode('.jpg', result_image)
i = display.Image(data=ret_array)
display.display(i)
cv2.imwrite("yolo-output.png",result_image)

Real time camera demo
The following example shows running on a camera YoloV3. This model is really more complex , Therefore, it can provide better mAP. Also consider other models , Such as mobilenet, If you want to balance performance and accuracy .
Source: https://github.com/PaddlePaddle/PaddleDetection
def YoloVideo(VideoIndex=0, scale=0.5):
#PPYolo3
pdmodel_path = "models/yolov3_darknet53_270e_coco"
pdmodel_file = pdmodel_path + "/model.pdmodel"
pdmodel_config = pdmodel_path + "/infer_cfg.yml"
device = 'CPU'
#load the data from config, and setup the parameters
label_list=[]
with open(pdmodel_config) as f:
data = yaml.load(f, Loader=SafeLoader)
label_list = data['label_list'];
ie = IECore()
net = ie.read_network(pdmodel_file)
net.reshape({'image': [1, 3, 608, 608], 'im_shape': [
1, 2], 'scale_factor': [1, 2]})
exec_net = ie.load_network(net, device)
assert isinstance(exec_net, ExecutableNetwork)
try:
cap = cv2.VideoCapture(VideoIndex)
except:
print("Cannot Open Device")
del exec_net
try:
ret, frame = cap.read()
while(ret==True):
# Capture frame-by-frame
ret, frame = cap.read()
if not ret:
# Release the Video Device if ret is false
cap.release()
# Message to be displayed after releasing the device
print ("Released Video Resource")
break
#frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
half_frame = cv2.resize(frame, (0, 0), fx = scale, fy = scale)
#Processing the Frame
test_image = image_preprocess(half_frame, 608)
test_im_shape = np.array([[608, 608]]).astype('float32')
test_scale_factor = np.array([[1, 2]]).astype('float32')
#print(test_image.shape)
inputs_dict = {'image': test_image, "im_shape": test_im_shape,
"scale_factor": test_scale_factor}
output = exec_net.infer(inputs_dict)
result_ie = list(output.values())
result_image = half_frame.copy()
#result_image = cv2.resize(result_image, (int(608*1.0),int(608*1.0)))
scale_x = result_image.shape[1]/608*2
scale_y = result_image.shape[0]/608
result_image = draw_box(result_image, result_ie[0], label_list, scale_x, scale_y)
#convert to jpg for performance results
_,ret_array = cv2.imencode('.jpg', result_image)
i = display.Image(data=ret_array)
display.display(i)
display.clear_output(wait=True)
except KeyboardInterrupt:
# Release the Video Device
cap.release()
# Message to be displayed after releasing the device
print("Released Video Resource from KeyboardInterrupt")
del exec_net
pass
function Webcam Feed
Please press the stop button , Terminate correctly .
YoloVideo(1, 0.75)
Released Video Resource from KeyboardInterrupt
openvino-PaddleOCR
Handwriting recognition ancient poetry
This demonstration is from Dr. Wu Zhuo (OpenVINO Edge AI Software evangelist - Intel)
An open source project of , How does it work OpenVINO Up operation PaddleOCR (Lite) Model . We can now go directly from mobilenetv3 Model reading without any conversion , Rather than mobilenetv3 The model is exported to ONNX, And then through OpenVINO The optimizer creates an intermediate representation (IR) Format .
If anything goes wrong , You can refer to here
adopt OpenVINO function Paddle Detection
import os, os.path
import sys
import json
import urllib.request
import cv2
import numpy as np
import paddle
import math
import time
from openvino.inference_engine import IENetwork, IECore, ExecutableNetwork
from IPython import display
from PIL import Image, ImageDraw
import copy
import logging
import imghdr
from shapely.geometry import Polygon
import pyclipper
from pre_post_processing import *
Loading pictures
def image_preprocess(input_image, size):
img = cv2.resize(input_image, (size,size))
img = np.transpose(img, [2,0,1]) / 255
img = np.expand_dims(img, 0)
##NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
img_mean = np.array([0.485, 0.456,0.406]).reshape((3,1,1))
img_std = np.array([0.229, 0.224, 0.225]).reshape((3,1,1))
img -= img_mean
img /= img_std
return img.astype(np.float32)
# Test images provided include 1 handwritten Chinese image and 1 printed Chinese image
image_file = "handwritten_simplified_chinese_test.jpg"
ii = cv2.imread(image_file)
test_image = image_preprocess(ii,640)
Load the Network
model_dir = "./inference/ch_ppocr_mobile_v2.0_det_infer"
model_file_path = model_dir + "/inference.pdmodel"
params_file_path = model_dir + "/inference.pdiparams"
# initialize inference engine
ie = IECore()
# initialize inference engine
net = ie.read_network(model_file_path)
# pdmodel might be dynamic shape, this will reshape based on the input
input_key = list(net.input_info.items())[0][0] # 'inputs'
net.reshape({input_key: test_image.shape})
exec_net = ie.load_network(net, 'CPU')
assert isinstance(exec_net, ExecutableNetwork)
#perform the inference step
det_start_time = time.time()
output = exec_net.infer({input_key: test_image})
det_stop_time = time.time()
result_ie = list(output.values())
det_infer_time = det_stop_time - det_start_time
Yes PaddleDetection After processing the reasoning result of
ori_im = ii.copy()
data = {'image': ii}
data_resize = DetResizeForTest(data)
data_norm = NormalizeImage(data_resize)
data_list = []
keep_keys = ['image', 'shape']
for key in keep_keys:
data_list.append(data[key])
img, shape_list = data_list
shape_list = np.expand_dims(shape_list, axis=0)
pred = result_ie[0]
if isinstance(pred, paddle.Tensor):
pred = pred.numpy()
pred = pred[:, 0, :, :]
segmentation = pred > 0.3
boxes_batch = []
for batch_index in range(pred.shape[0]):
src_h, src_w, ratio_h, ratio_w = shape_list[batch_index]
mask = segmentation[batch_index]
boxes, scores = boxes_from_bitmap(pred[batch_index], mask,src_w, src_h)
boxes_batch.append({'points': boxes})
post_result = boxes_batch
dt_boxes = post_result[0]['points']
dt_boxes = filter_tag_det_res(dt_boxes, ii.shape)
stay openvino Identification of flying slurry running on
# Processing detection results for Recognition
dt_boxes = sorted_boxes(dt_boxes)
img_crop_list = []
for bno in range(len(dt_boxes)):
tmp_box = copy.deepcopy(dt_boxes[bno])
img_crop = get_rotate_crop_image(ori_im, tmp_box)
img_crop_list.append(img_crop)
The pretreatment is delivered to Paddle Recognized images
def resize_norm_img(img, max_wh_ratio):
rec_image_shape = [3, 32, 320]
imgC, imgH, imgW = rec_image_shape
assert imgC == img.shape[2]
character_type = "ch"
if character_type == "ch":
imgW = int((32 * max_wh_ratio))
h, w = img.shape[:2]
ratio = w / float(h)
if math.ceil(imgH * ratio) > imgW:
resized_w = imgW
else:
resized_w = int(math.ceil(imgH * ratio))
resized_image = cv2.resize(img, (resized_w, imgH))
resized_image = resized_image.astype('float32')
resized_image = resized_image.transpose((2, 0, 1)) / 255
resized_image -= 0.5
resized_image /= 0.5
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
Load the Network
model_dir = "./inference/ch_ppocr_mobile_v2.0_rec_infer"
model_file_path = model_dir + "/inference.pdmodel"
params_file_path = model_dir + "/inference.pdiparams"
ie = IECore()
net = ie.read_network(model_file_path)
Begin to recognize ancient poetry
img_num = len(img_crop_list)
# Calculate the aspect ratio of all text bars
width_list = []
for img in img_crop_list:
width_list.append(img.shape[1] / float(img.shape[0]))
# Sorting can speed up the recognition process
indices = np.argsort(np.array(width_list))
rec_res = [['', 0.0]] * img_num
rec_batch_num = 6
batch_num = rec_batch_num
rec_processing_times = 0
for beg_img_no in range(0, img_num, batch_num):
end_img_no = min(img_num, beg_img_no + batch_num)
norm_img_batch = []
max_wh_ratio = 0
for ino in range(beg_img_no, end_img_no):
h, w = img_crop_list[indices[ino]].shape[0:2]
wh_ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, wh_ratio)
for ino in range(beg_img_no, end_img_no):
norm_img = resize_norm_img(img_crop_list[indices[ino]],max_wh_ratio)
norm_img = norm_img[np.newaxis, :]
norm_img_batch.append(norm_img)
norm_img_batch = np.concatenate(norm_img_batch)
norm_img_batch = norm_img_batch.copy()
# pdmodel might be dynamic shape, this will reshape based on the input
input_key = list(net.input_info.items())[0][0] # 'inputs'
net.reshape({input_key: norm_img_batch.shape})
#load the network on CPU
start_time = time.time()
exec_net = ie.load_network(net, 'CPU')
stop_time = time.time()
assert isinstance(exec_net, ExecutableNetwork)
rec_processing_times += stop_time - start_time
for index in range(len(norm_img_batch)):
output = exec_net.infer({input_key: norm_img_batch})
result_ie = list(output.values())
preds = result_ie[0]
postprocess_op = build_post_process(postprocess_params)
rec_result = postprocess_op(preds)
for rno in range(len(rec_result)):
rec_res[indices[beg_img_no + rno]] = rec_result[rno]
final_stop_time = time.time()
processing_time = final_stop_time - det_start_time
print("The total prediction and processing time is ", processing_time)
The total prediction and processing time is 0.3596353530883789
print("The total inference time for detection is ", det_infer_time)
print("The total inference time for recognition is ", rec_processing_times)
The total inference time for detection is 0.030055999755859375
The total inference time for recognition is 0.127180814743042
Visual detection and recognition results
src_im = draw_text_det_res(dt_boxes, image_file)
img_name_pure = os.path.split(image_file)[-1]
img_path = "det_res_{}".format(img_name_pure)
cv2.imwrite(img_path, src_im)
#Visualization Paddle Detection results
_,ret_array = cv2.imencode('.jpg', src_im)
i = display.Image(data=ret_array)
display.display(i)

#Visualization Paddle Recognition results, format
print(rec_res)
[(‘ Jielu in the human environment, there is no noise of cars and horses ’, 0.7947357), (‘ Ask you how you can be far away from your heart ’, 0.78279454), (‘ At the foot of the East crane, you can see the South Mountain gas day and night ’, 0.8802729), (‘ There is a genuine desire to return the beautiful birds ’, 0.8675663), (‘ Argumentation ’, 0.38597608)]
边栏推荐
- BeanFactoryPostProcessor 与 BeanPostProcessor 相关子类概述
- The data mark is a piece of fat meat, and it is not only China Manfu technology that focuses on this meat
- BUU-Crypto-[GXYCTF2019]CheckIn
- 一键过滤选择百度网盘文件
- Enterprise level log analysis system elk (if things backfire, there must be other arrangements)
- 【微服务】Nacos集群搭建以及加载文件配置
- 1.1 history of Statistics
- HMS v1.0 appointment. PHP editid parameter SQL injection vulnerability (cve-2022-25491)
- Grounding relay dd-1/60
- Win10 clear quick access - leave no trace
猜你喜欢
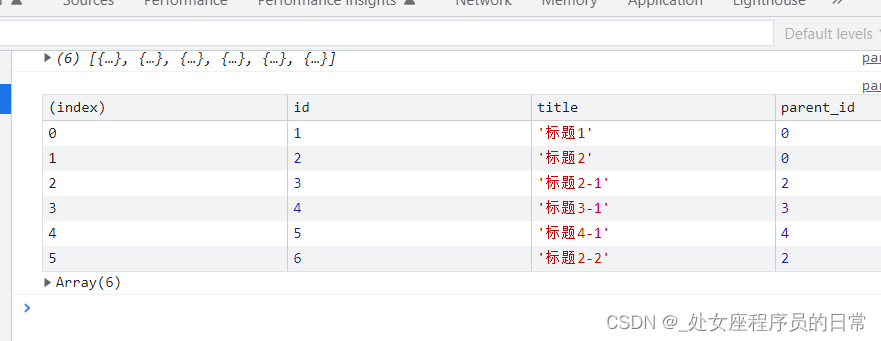





随机推荐
Easy change
Accidentally deleted the data file of Clickhouse, can it be restored?
Basic concept of bus
一键过滤选择百度网盘文件
509. 斐波那契数、爬楼梯所有路径、爬楼梯最小花费
Flask
Take you to quickly learn how to use qsort and simulate qsort
The data mark is a piece of fat meat, and it is not only China Manfu technology that focuses on this meat
SQL performance optimization skills
每周小结(*63):关于正能量
JS string splicing
Excel 比较日器
724. 寻找数组的中心下标
How to use postman to realize simple interface Association [add, delete, modify and query]
left_and_right_net可解释性设计
Flask
Solar insect killing system based on single chip microcomputer
el-select如何实现懒加载(带搜索功能)
VB. Net simple processing pictures, black and white (class library - 7)
509. Fibonacci number, all paths of climbing stairs, minimum cost of climbing stairs