当前位置:网站首页>Voice conversion相关语音数据集综合汇总
Voice conversion相关语音数据集综合汇总
2022-08-05 09:14:00 【ASS-ASH】
- CSTR VCTK Corpus:英语语音,109个说话人,每个说话人平均400句话,每句话4至10秒,平行语料。
- TIMIT Acoustic-Phonetic Continuous Speech Corpus:英语语音,630个说话人,每个说话人平均10句话,平行语料。
- LibriSpeech:大型阅读英语语音语料库(目前大小,1000小时,57.2G)。LibriSpeech是由Vassil Panayotov在Daniel Povey的协助下编写的大约1000小时的16kHz阅读英语语音的语料库。数据来自LibriVox项目的有声读物,并经过仔细地分段和对齐。
- TED-LIUM 语料库 TED-LIUM是通过Ubiqus公司与LIUM(法国勒芒大学)的合作完成的 SPH:2351音频对话,包括TED-LIUM 2的对话,452小时的音频,2351个对齐的STM格式。
- VoxForge Voxforge 被设计来收集讲话转录文本,以供自由与开放源代码的语音识别引擎使用。
- Tatoeba Tatoeba 是一个用于语言学习的句子、翻译和口语音频的大型数据库。此下载包含由其社区记录的所有口语。
- Voice Conversion Challenge 2016 语音转换挑战赛(VCC)2016是VCC的第一版。
- Voice Conversion Challenge 2018 语音转换挑战赛(VCC)2018是VCC的第二版,是一项大规模的语音转换挑战赛。 VCC 2018语料库是通过从设备和生产语音(DAPS)数据集[12]中选择说话者准备的,这些数据集是由专业的美国英语使用者在干净和无噪音的环境中录制的。参加挑战的参与者需要使用通过并行或非并行训练数据训练的VC系统,将语音信号从源说话者转换为目标说话者。已通过众包收听测试对参与挑战的所有并行和非并行VC系统进行了自然性和相似性评分评估。
- Voice Conversion Challenge 2020 任务一1.半并行语音4输入语音,4目标语音,每人70句英文,20平行,50不平行。任务二1.不同句子,不同种族语言进行转换
- The Blizzard Challeng2020 9.5小时普通话 3小时上海话 train700句子(New:500,PSC:100,INT:100,///TEST,New:291,Chet:100),test 391句子,普通话仅仅只有文字,上海话语音加文字。TTS数据集。
- VOiCES Dataset
边栏推荐
猜你喜欢

如何实现按键的短按、长按检测?

DTcloud 装饰器

全面讲解GET 和 POST请求的本质区别是什么?原来我一直理解错了
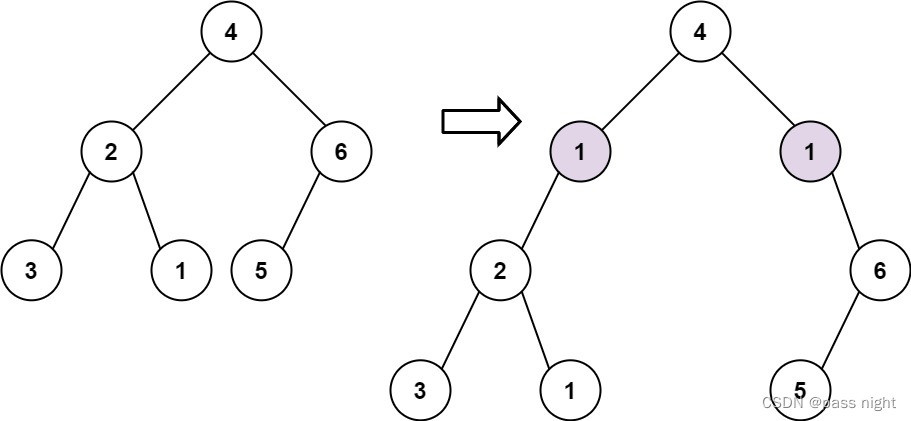
【LeetCode】623. Add a row to the binary tree
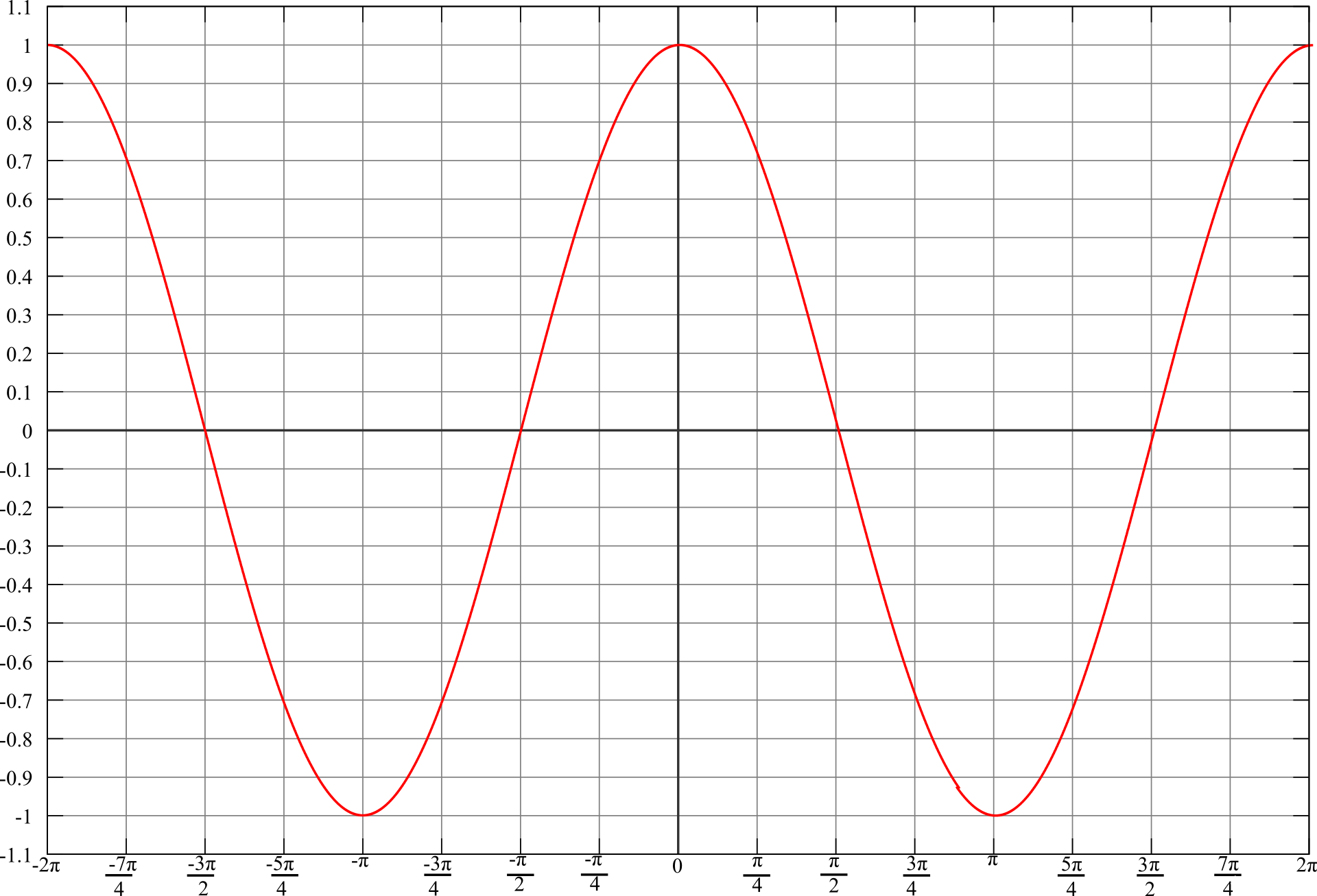
pytorch余弦退火学习率CosineAnnealingLR的使用
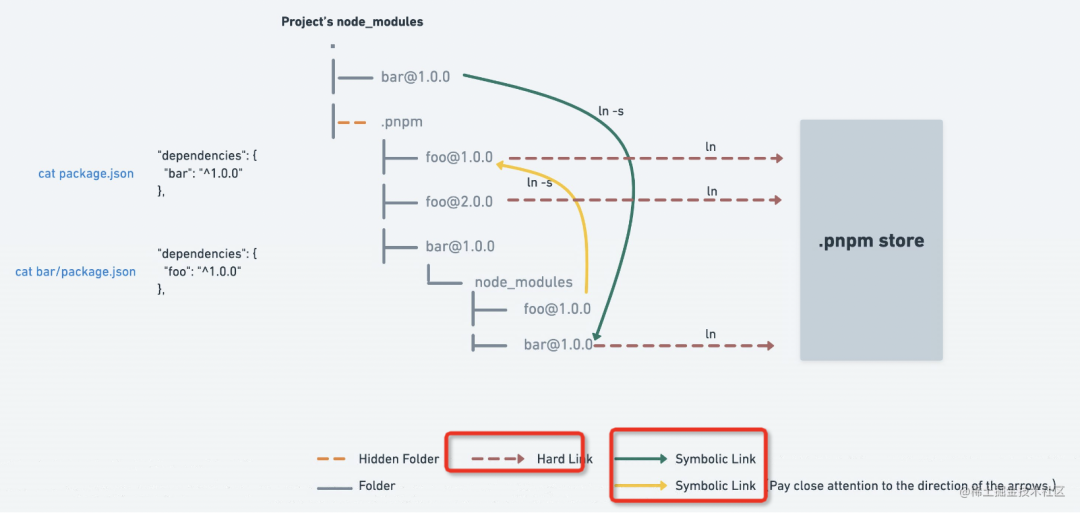
Why is pnpm hitting npm and yarn dimensionality reduction?

让程序员崩溃的N个瞬间(非程序员误入)
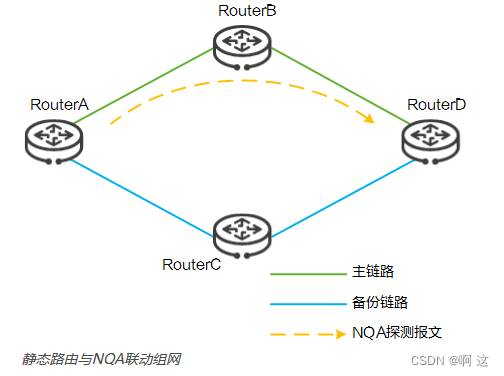
只有一台交换机,如何实现主从自动切换之nqa

Science bosses say | Hong Kong rhubarb KaiBin teacher take you unlock the relationship between the matrix and 6 g
CPU的亲缘性affinity
随机推荐
Dry goods!Generative Model Evaluation and Diagnosis
2022-08-01 Review the basic binary tree and operations
Hundred lines of code launch red hearts, why programmers lose their girlfriends!
eKuiper Newsletter 2022-07|v1.6.0:Flow 编排 + 更好用的 SQL,轻松表达业务逻辑
接口全周期的生产力利器Apifox
There is only one switch, how to realize the nqa of master-slave automatic switching
15.1.1、md—md的基础语法,快速的写文本备忘录
sql server收缩日志的作业和记录,失败就是因为和备份冲突了吗?
施一公:科学需要想象,想象来自阅读
Is there a problem with writing this?How to synchronize data in sql-client
Luogu P1908: 逆序对 [树状数组]
seata源码解析:事务状态及全局锁的存储
基于 Kubernetes 的微服务项目整体设计与实现
21 Days of Deep Learning - Convolutional Neural Networks (CNN): Weather Recognition (Day 5)
CPU的亲缘性affinity
让程序员崩溃的N个瞬间(非程序员误入)
代码审计—PHP
Hbuilder 学习使用中的一些记录
【zeno】为zeno增加子模块/新节点的最小化的例子
手把手教你纯c实现异常捕获try-catch组件