当前位置:网站首页>[introduction to information retrieval] Chapter 7 scoring calculation in search system
[introduction to information retrieval] Chapter 7 scoring calculation in search system
2022-07-02 07:22:00 【lwgkzl】
1. executive summary
This chapter mainly solves the following problems :
- For hundreds of billions of documents , Sorting the document library for each query is unrealistic , If you can quickly retrieve the most relevant topk A document ?
- except query And document Beyond the similarity of , Whether other indicators are needed in the process of sorting documents ? How to synthesize these indicators
- What modules does a complete information retrieval system need to include ?
- Whether the vector space model supports Wildcard Queries ?
2. Quick scoring and sorting
This chapter mainly introduces some heuristic methods , It is used to quickly find the one that is more relevant to a query K A document , The documents found do not completely contain the most relevant topk, But we will return with truth topk The score is close K A document .
a. Index removal optimization :
Consider only documents that contain multiple query items in the query , Or only consider including more than a certain number of words idf Threshold document .
b. Winner list
For each word item in the inverted list , Find the most relevant t A document , Then in the subsequent query , For each word, only t The document with the highest score , That is, for a query , We only need the word items contained in the query corresponding to N* t Select from documents topk that will do , among N The number of terms included for this query .
c. Static score of the document
Use in combination with the winner table , You can use the static score of the document as the first choice of each word t Basis of documents . The static score of the document represents the quality of the document , Such as the website users' comments on the website . As shown in the figure below :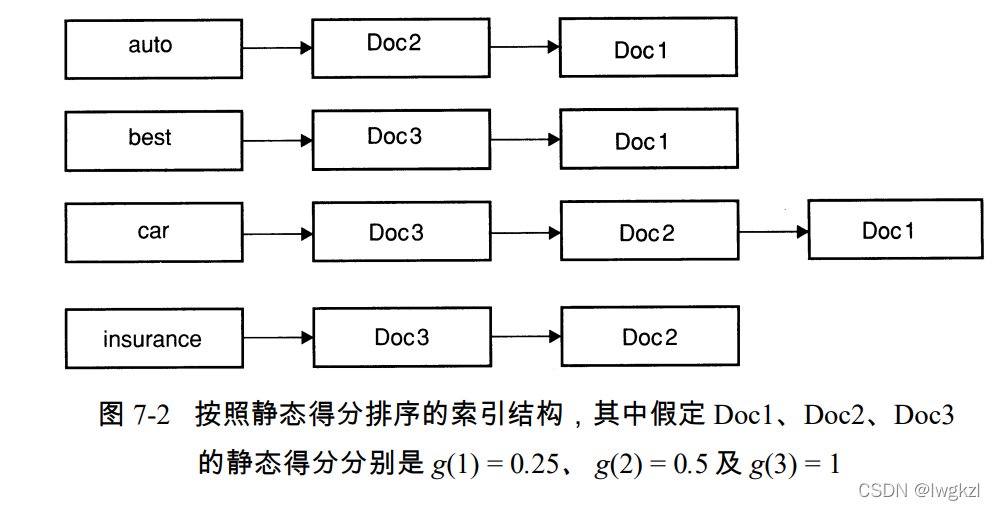
d. Cluster pruning
Use document vectors for clustering , Then choose ( N ) \sqrt(N) (N) Cluster centers , It is expected that each cluster will contain ( N ) \sqrt(N) (N) A document , among N Is the number of documents . Then choose leave query The nearest cluster center as a candidate , Here ( N ) \sqrt(N) (N) Select from documents topk Geli query Recent documents .
3. Composition of information retrieval system
a. Hierarchical index :
As shown in the figure above , Divide into different levels through scores , When searching, search from top to bottom , Until I find K Candidate documents .
b. Lexical proximity :
The closer the word items in the query are in the document , The higher the score of this document . As for how to evaluate the score of the word item approaching , Content requiring machine learning .
c. Calculation of scoring function :
ditto , Comprehensive scoring for a document , Static scores need to be considered , query Similarity with documents , Word proximity and other factors , According to the different emphasis of application , Manual rules can be formulated to comprehensively score documents , You can also regard the above scores as characteristics , Then input these features into the machine learning model for scoring .
d. Composition of information retrieval system :
On the document side : Indexing to imprecise retrieval
On user side : From spelling correction to retrieval , To sort and grade documents through machine learning algorithms .
4. Support of vector space model for various query operations
a. Boolean query
Obviously, the vector space model can support the Boolean query of a single word , But the Boolean query expression of multiple word combinations , It is not easy to accumulate scores by vector space model .
b. Wildcard query
Wildcards can be parsed first , Resolve the query terms that wildcards may represent , Then take all possible terms as candidates query Go to query , Finally, integrate all query Query results of . Therefore, vector space model can solve
c. Phrase query :
Because the vector space model does not consider the relative position of each word in the phrase , Therefore, vector space model is not suitable for phrase query .
5. Summary
- For hundreds of billions of documents , Sorting the document library for each query is unrealistic , If you can quickly retrieve the most relevant topk A document ?
answer : Use heuristic algorithms , Like the winner table , The method of hierarchical indexing , Find a relatively good topk A document . - except query And document Beyond the similarity of , Whether other indicators are needed in the process of sorting documents ? How to synthesize these indicators .
answer : There are many other indicators , Such as static scoring of documents , Word item nearest neighbor score, etc , Finally, it can be comprehensively scored by means of manual rules or machine learning . - What modules does a complete information retrieval system need to include ?
answer : See the picture 3.d - Whether the vector space model supports Wildcard Queries ?
answer : Support .
6. Mind mapping

边栏推荐
- 使用MAME32K进行联机游戏
- Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK
- ssm+mysql实现进销存系统
- 【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
- 离线数仓和bi开发的实践和思考
- 外币记账及重估总账余额表变化(下)
- 如何高效开发一款微信小程序
- 一份Slide两张表格带你快速了解目标检测
- Principle analysis of spark
- Sqli-labs customs clearance (less1)
猜你喜欢

Oracle apex Ajax process + dy verification

Classloader and parental delegation mechanism
Network security -- intrusion detection of emergency response

view的绘制机制(一)

Yaml file of ingress controller 0.47.0

架构设计三原则

Sqli-labs customs clearance (less2-less5)

IDEA2020中测试PySpark的运行出错

ORACLE 11G利用 ORDS+pljson来实现json_table 效果

Message queue fnd in Oracle EBS_ msg_ pub、fnd_ Application of message in pl/sql
随机推荐
ORACLE EBS DATAGUARD 搭建
ERNIE1.0 与 ERNIE2.0 论文解读
MapReduce concepts and cases (Shang Silicon Valley Learning Notes)
华为机试题
外币记账及重估总账余额表变化(下)
2021-07-17c /cad secondary development creation circle (5)
Oracle segment advisor, how to deal with row link row migration, reduce high water level
view的绘制机制(一)
A summary of a middle-aged programmer's study of modern Chinese history
Illustration of etcd access in kubernetes
php中获取汉字拼音大写首字母
Oracle 11g sysaux table space full processing and the difference between move and shrink
Feeling after reading "agile and tidy way: return to origin"
Oracle EBS ADI development steps
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
Ceaspectuss shipping company shipping artificial intelligence products, anytime, anywhere container inspection and reporting to achieve cloud yard, shipping company intelligent digital container contr
Yolov5 practice: teach object detection by hand
@Transational踩坑
软件开发模式之敏捷开发(scrum)
DNS攻击详解