当前位置:网站首页>【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
【MEDICAL】Attend to Medical Ontologies: Content Selection for Clinical Abstractive Summarization
2022-07-02 07:20:00 【lwgkzl】
Mission :
According to the author , The medical image report in English has two descriptions at the same time , One is FINDINGS, The details and characteristics of the whole image are described , The other one is IMPRESSION, Only focus on the key information in the image , These key information is contained in FINDINGS Inside . All in all , What this paper does is to use this FINDINGS To generate IMPRESSION, That is, the application of text summarization in the medical field .
Model :
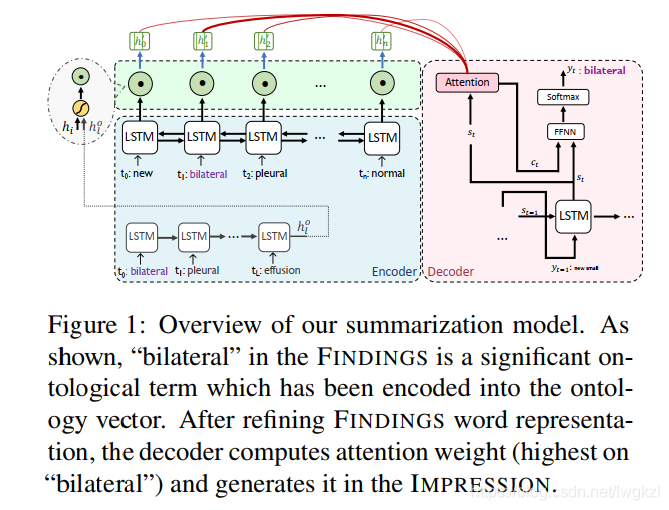
Content Selector:
This selector is implemented in the form of sequence annotation , Whole FINDINGS Each word in the sequence has 0,1 Two kinds of labels . If the current word is a medical proprietary entity , And he is corresponding IMPRESSION If it happens , Then mark this position as 1, Otherwise, it is marked as 0. Learn a model like this , It can be used to mark on the test set FINDINGS, And select some key medical proprietary entities .
Then see the figure
On the left is encoder,encoder The upper one inside lstm be used for encoder Whole FINDINGS, Get the code of each position hi, Then the one below lstm be used for encoder Content Selector Selected key medical proprietary entities . This of the medical proprietary entity LSTM Get the final one hl0 Vector , This vector represents the current FINDINGS It contains information about all significant medical proprietary entities . Then use this information to fuse to the above code FINDINGS Of LSTM in , Get a new vector for each position :
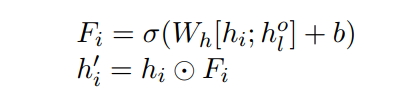
hi It's the top LSTM Output of each position , hl0 It's below LSTM Output of the last position . Merge , Then do with the output of each position before element-wise The multiplication operation of , That is, the circle of the second formula . After fusion hi' And finally decoder Sit in every position attention, To guide decoder Generation .
After reading the summary :
Whole article paper Our model is not difficult , It's still old-fashioned seq2seq Infrastructure for , And it uses lstm ecoder and lstm decoder The pattern of . The only bright spot is Content Selector The idea of sequence tagging is used , This is a bit like copy Mechanism , But it's not the last step to modify the distribution . The whole paper has only made such a small change , Then we can prove that he is really effective , That's all right. .
边栏推荐
猜你喜欢

Write a thread pool by hand, and take you to learn the implementation principle of ThreadPoolExecutor thread pool

Oracle EBS database monitoring -zabbix+zabbix-agent2+orabbix
【论文介绍】R-Drop: Regularized Dropout for Neural Networks

如何高效开发一款微信小程序

外币记账及重估总账余额表变化(下)

Sqli-labs customs clearance (less2-less5)
Only the background of famous universities and factories can programmers have a way out? Netizen: two, big factory background is OK

Three principles of architecture design
TCP攻击
How to efficiently develop a wechat applet
随机推荐
How to efficiently develop a wechat applet
在php的开发环境中如何调取WebService?
ssm垃圾分类管理系统
Oracle APEX 21.2 installation et déploiement en une seule touche
解决万恶的open failed: ENOENT (No such file or directory)/(Operation not permitted)
Three principles of architecture design
架构设计三原则
Cloud picture says | distributed transaction management DTM: the little helper behind "buy buy buy"
Laravel8中的find_in_set、upsert的使用方法
parser.parse_args 布尔值类型将False解析为True
Sqli labs customs clearance summary-page1
矩阵的Jordan分解实例
ORACLE EBS接口开发-json格式数据快捷生成
Ding Dong, here comes the redis om object mapping framework
view的绘制机制(二)
Oracle EBS ADI development steps
php中获取汉字拼音大写首字母
Sqli Labs clearance summary - page 2
Explanation of suffix of Oracle EBS standard table
Oracle段顾问、怎么处理行链接行迁移、降低高水位