当前位置:网站首页>想进阿里必须啃透的12道MySQL面试题
想进阿里必须啃透的12道MySQL面试题
2022-07-05 14:29:00 【InfoQ】
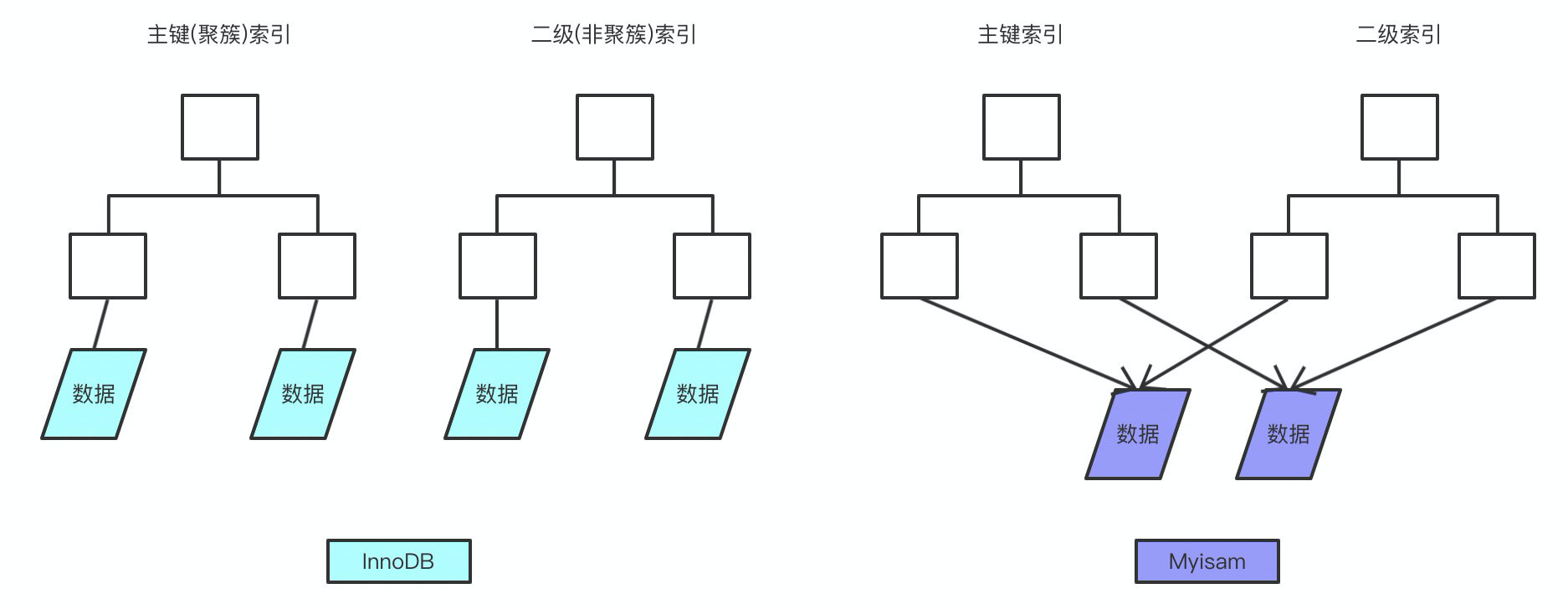
1. 能说下myisam 和 innodb的区别吗?
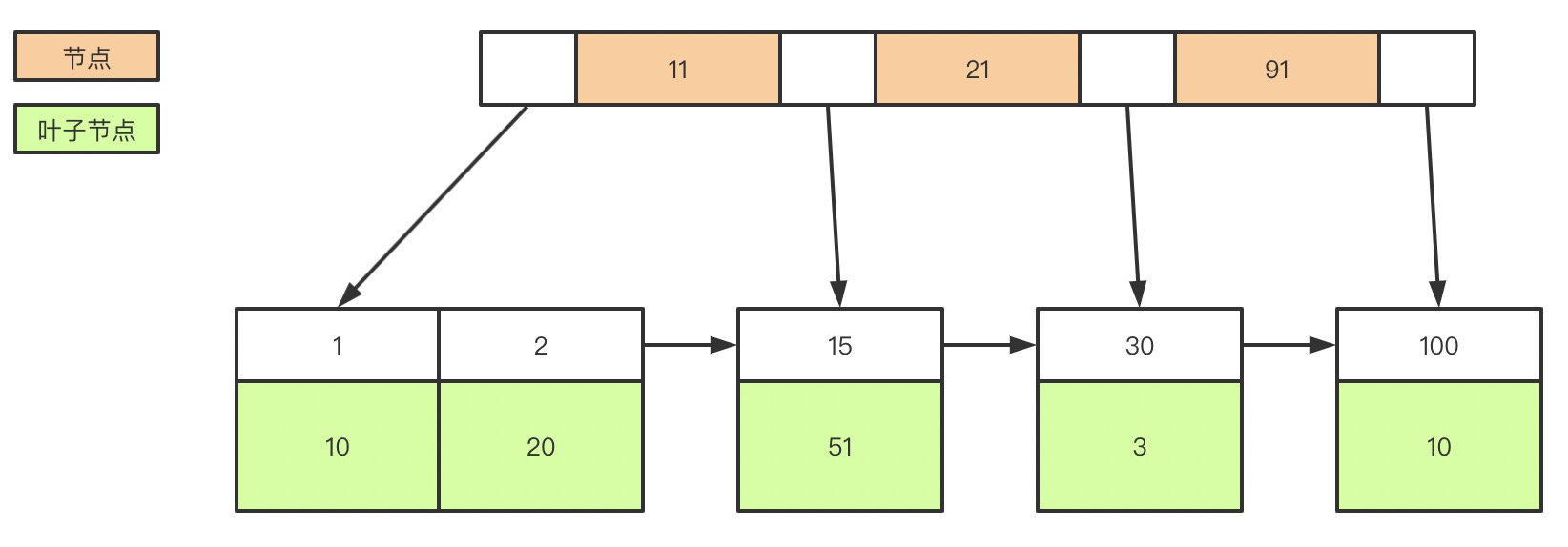
2. 说下mysql的索引有哪些吧,聚簇和非聚簇索引又是什么?
create table user(
id int(11) not null,
age int(11) not null,
primary key(id),
key(age)
);
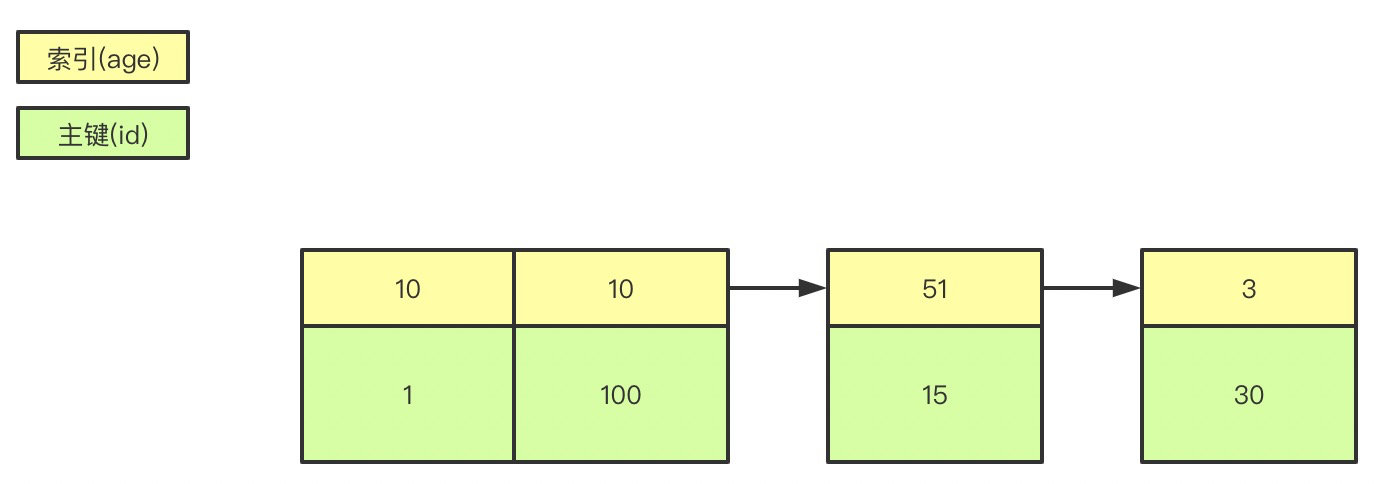
3. 那你知道什么是覆盖索引和回表吗?
explain select * from user where age=1; //查询的name无法从索引数据获取
explain select id,age from user where age=1; //可以直接从索引获取
4. 锁的类型有哪些呢
5. 你能说下事务的基本特性和隔离级别吗?
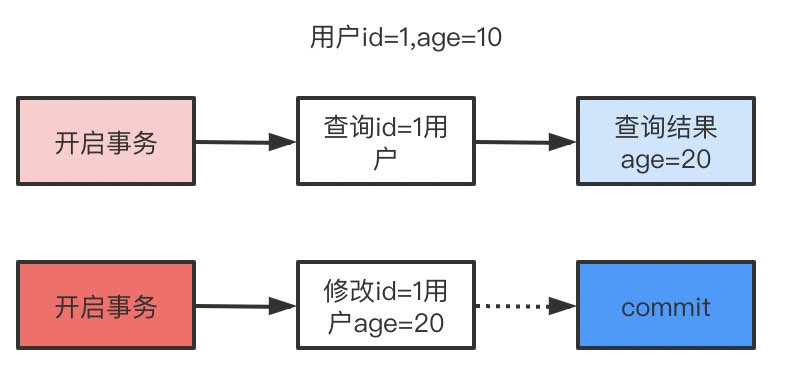
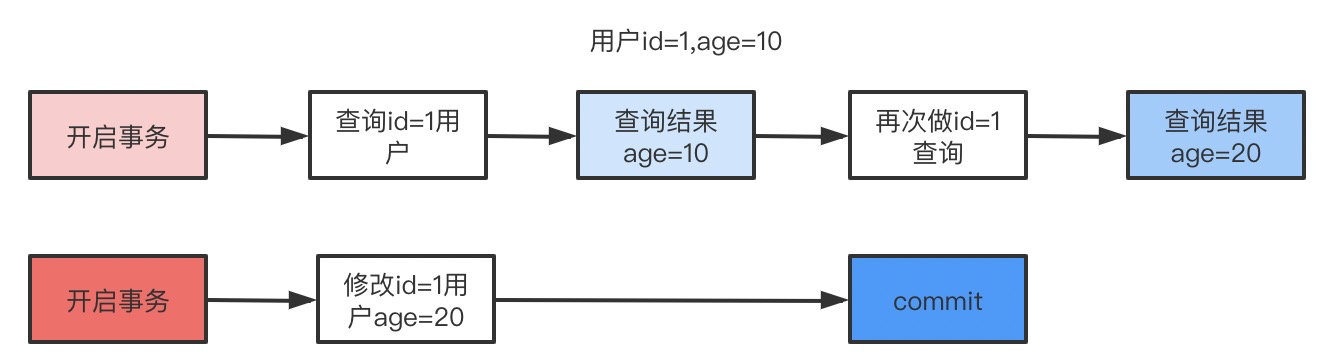
6. 那你说说什么是幻读,什么是MVCC?

select * from user where id<=3;
update user set name='张三三' where id=1;

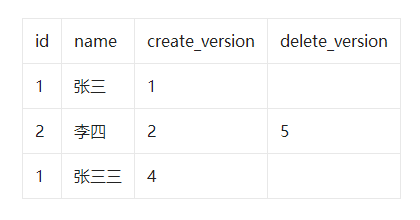
select * from user where id<=3 and create_version<=3 and (delete_version>3 or delete_version is null);
- 小明开启事务current_version=6查询名字为'王五'的记录,发现不存在。
- 小红开启事务current_version=7插入一条数据,结果是这样:

- 小明执行插入名字'王五'的记录,发现唯一索引冲突,无法插入,这就是幻读。
7. 那ACID靠什么保证的呢?
8. 那你知道什么是间隙锁吗?
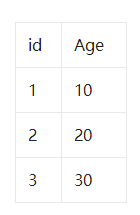
begin;
select * from user where age=20 for update;
begin;
insert into user(age) values(10); #成功
insert into user(age) values(11); #失败
insert into user(age) values(20); #失败
insert into user(age) values(21); #失败
insert into user(age) values(30); #失败
(negative infinity,10],(10,20],(20,30],(30,positive infinity)
9. 那分表后的ID怎么保证唯一性的呢?
- 设定步长,比如1-1024张表我们设定1024的基础步长,这样主键落到不同的表就不会冲突了。
- 分布式ID,自己实现一套分布式ID生成算法或者使用开源的比如雪花算法这种
- 分表后不使用主键作为查询依据,而是每张表单独新增一个字段作为唯一主键使用,比如订单表订单号是唯一的,不管最终落在哪张表都基于订单号作为查询依据,更新也一样。
10. 你们数据量级多大?分库分表怎么做的?

11. 分表后非sharding_key的查询怎么处理呢?
- 可以做一个mapping表,比如这时候商家要查询订单列表怎么办呢?不带user_id查询的话你总不能扫全表吧?所以我们可以做一个映射关系表,保存商家和用户的关系,查询的时候先通过商家查询到用户列表,再通过user_id去查询。
- 打宽表,一般而言,商户端对数据实时性要求并不是很高,比如查询订单列表,可以把订单表同步到离线(实时)数仓,再基于数仓去做成一张宽表,再基于其他如es提供查询服务。
- 数据量不是很大的话,比如后台的一些查询之类的,也可以通过多线程扫表,然后再聚合结果的方式来做。或者异步的形式也是可以的。
List<Callable<List<User>>> taskList = Lists.newArrayList();
for (int shardingIndex = 0; shardingIndex < 1024; shardingIndex++) {
taskList.add(() -> (userMapper.getProcessingAccountList(shardingIndex)));
}
List<ThirdAccountInfo> list = null;
try {
list = taskExecutor.executeTask(taskList);
} catch (Exception e) {
//do something
}
public class TaskExecutor {
public <T> List<T> executeTask(Collection<? extends Callable<T>> tasks) throws Exception {
List<T> result = Lists.newArrayList();
List<Future<T>> futures = ExecutorUtil.invokeAll(tasks);
for (Future<T> future : futures) {
result.add(future.get());
}
return result;
}
}
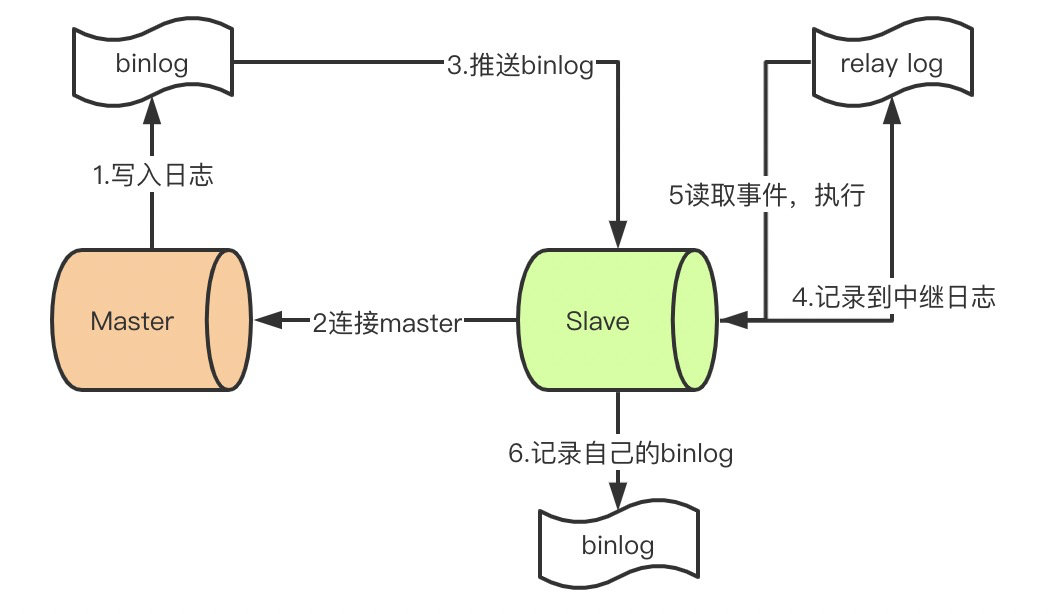
12. 说说mysql主从同步怎么做的吧?
- master提交完事务后,写入binlog
- slave连接到master,获取binlog
- master创建dump线程,推送binglog到slave
- slave启动一个IO线程读取同步过来的master的binlog,记录到relay log中继日志中
- slave再开启一个sql线程读取relay log事件并在slave执行,完成同步
- slave记录自己的binglog
13. 那主从的延迟怎么解决呢?
- 针对特定的业务场景,读写请求都强制走主库
- 读请求走从库,如果没有数据,去主库做二次查询
边栏推荐
- Tidb DM alarm DM_ sync_ process_ exists_ with_ Error troubleshooting
- mysql8.0JSON_CONTAINS的使用说明
- What about SSL certificate errors? Solutions to common SSL certificate errors in browsers
- freesurfer运行完recon-all怎么快速查看有没有报错?——核心命令tail重定向
- R language ggplot2 visualization: gganimate package is based on Transition_ The time function creates dynamic scatter animation (GIF) and uses shadow_ Mark function adds static scatter diagram as anim
- Postman简介、安装、入门使用方法详细攻略!
- Oneconnect listed in Hong Kong: with a market value of HK $6.3 billion, ye Wangchun said that he was honest and trustworthy, and long-term success
- MySQL user-defined function ID number to age (supports 15 / 18 digit ID card)
- The speed monitoring chip based on Bernoulli principle can be used for natural gas pipeline leakage detection
- Interpretation of tiflash source code (IV) | design and implementation analysis of tiflash DDL module
猜你喜欢

快消品行业SaaS多租户解决方案,构建全产业链数字化营销竞争力
日化用品行业智能供应链协同系统解决方案:数智化SCM供应链,为企业转型“加速度”

家用电器行业商业供应链协同平台解决方案:供应链系统管理精益化,助推企业智造升级
ASP.NET大型外卖订餐系统源码 (PC版+手机版+商户版)
Opengauss database source code analysis series articles -- detailed explanation of dense equivalent query technology (Part 2)
无密码身份验证如何保障用户隐私安全?

微帧科技荣获全球云计算大会“云鼎奖”!
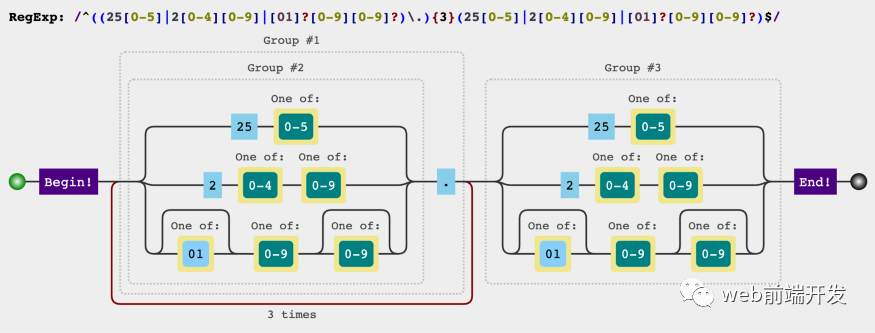
Sharing the 12 most commonly used regular expressions can solve most of your problems
Thymeleaf 使用后台自定义工具类处理文本

周大福践行「百周年承诺」,真诚服务推动绿色环保
随机推荐
Chow Tai Fook fulfills the "centenary commitment" and sincerely serves to promote green environmental protection
Which Internet companies are worth going to in Shenzhen for software testers [Special Edition for software testers]
04_ Use of solrj7.3 of solr7.3
【学习笔记】图的连通性与回路
SaaS multi tenant solution for FMCG industry to build digital marketing competitiveness of the whole industry chain
R语言dplyr包select函数、group_by函数、mutate函数、cumsum函数计算dataframe分组数据中指定数值变量的累加值、并生成累加数据列
做自媒体视频二次剪辑,怎样剪辑不算侵权
CyCa children's physical etiquette Ningbo training results assessment came to a successful conclusion
启牛学堂班主任给的证券账户安全吗?能开户吗?
C语言中限定符的作用
dynamic programming
最长公共子序列 - 动态规划
The simplest way to open more functions without certificates
Make the seckill Carnival more leisurely: the database behind the promotion (Part 2)
矩阵链乘 - 动态规划实例
Sorter evolution of ticdc 6.0 principle
Catch all asynchronous artifact completable future
Introduction, installation, introduction and detailed introduction to postman!
分享 20 个稀奇古怪的 JS 表达式,看看你能答对多少
LeetCode_ 2 (add two numbers)