当前位置:网站首页>如何在 TiDB Cloud 上使用 Databricks 进行数据分析 | TiDB Cloud 使用指南
如何在 TiDB Cloud 上使用 Databricks 进行数据分析 | TiDB Cloud 使用指南
2022-07-31 09:13:00 【TiDB】
作者丨吴强(PingCAP TiDB Cloud 团队工程师)
编辑丨Calvin Weng、Tom Dewan

TiDB Cloud 是为开源分布式数据库 TiDB 打造的全托管 DBaaS (Database-as-a-Service) 服务。
Databricks 是一款搭载 Spark,并基于网页的数据分析平台。Databricks 的数据湖仓架构集成了业界最优秀的数据仓库和数据湖。
借助 Databricks 内置的 JDBC 驱动程序,只需几分钟即可将 TiDB Cloud 对接到 Databricks,随后可以通过 Databricks 分析 TiDB 中的数据。本文主要介绍如何创建 TiDB Cloud Developer Tier 集群、如何将 TiDB 对接到 Databricks,以及如何使用 Databricks 处理 TiDB 中的数据。
设置 TiDB Cloud Dev Tier 集群
使用 TiDB Cloud 前,需进行以下操作:
注册 TiDB Cloud 账号并登录。
在 Create Cluster > Developer Tier 菜单下,选择 1 year Free Trial。
设置集群名称,并为集群选择区域。
单击 Create。大约 1~3 分钟后,TiDB Cloud 集群创建成功。
在 Overview 面板,单击 Connect 并创建流量过滤器。例如,添加 IP 地址 0.0.0.0/0,允许所有 IP 访问。
JDBC URL 稍后将在 Databricks 中使用,请做好记录。
将样例数据导入 TiDB Cloud
创建集群后,即可导入样例数据到 TiDB Cloud。我们将使用共享单车平台 Capital Bikeshare 的系统样例数据集作为演示。样例数据的使用完全遵循 Capital Bikeshare 公司的数据许可协议。
在集群信息窗格,单击 Import。随后,将出现 Data Import Task 页面。
按如下所示配置导入任务:
Data Source Type :
Amazon S3Bucket URL :
s3://tidbcloud-samples/data-ingestion/Data Format :
TiDB DumplingRole-ARN :
arn:aws:iam::385595570414:role/import-sample-access
配置 Target Database 时,键入 TiDB 集群的 Username 和 Password。
单击 Import,开始导入样例数据。整个过程将持续大约 3 分钟。
返回概览面板,单击 Connect to Get the MyCLI URL。
使用 MyCLI 客户端检查样例数据是否导入成功:
$ mycli -u root -h tidb.xxxxxx.aws.tidbcloud.com -P 4000(none)> SELECT COUNT(*) FROM bikeshare.trips; +----------+| COUNT(*) |+----------+| 816090 |+----------+1 row in setTime: 0.786s使用 Databricks 连接 TiDB Cloud
开始之前,请确保您已经使用自己的账号登录到 Databricks 工作区。如果您没有 Databricks 账号,请先免费注册一个。如果您拥有丰富的 Databricks 使用经验,并且想直接导入笔记本,可跳过(可选)将 TiDB Cloud 样例笔记本导入 Databricks。
在本章节中,我们将创建一个新的 Databricks Notebook,并将它关联到一个 Spark 集群,随后通过 JDBC URL 将创建的笔记本连接到 TiDB Cloud。
- 在 Databricks 工作区,按如下所示方式创建并关联 Spark 集群:
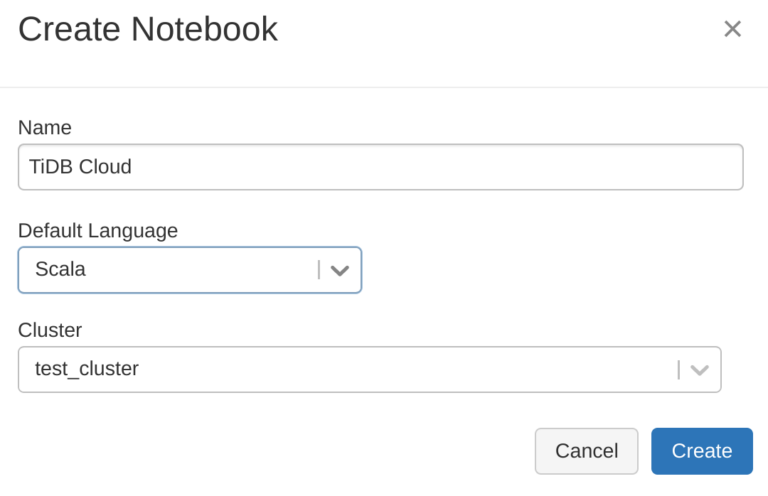
- 在 Databricks 笔记本中配置 JDBC。TiDB 可以使用 Databricks 默认的 JDBC 驱动程序,因此无需配置驱动程序参数:
%scalaval url = "jdbc:mysql://tidb.xxxx.prod.aws.tidbcloud.com:4000"val table = "bikeshare.trips"val user = "root"val password = "xxxxxxxxxx"配置参数说明如下:
url:用于连接 TiDB Cloud 的 JDBC URL
table:指定数据表,例如:${database}.${table}
user:用于连接 TiDB Cloud 的 用户名
password:用户的密码
- 检查 TiDB Cloud 的连通性:
%scalaimport java.sql.DriverManagerval connection = DriverManager.getConnection(url, user, password)connection.isClosed()res2: Boolean = false在 Databricks 中分析数据
只要成功建立连接,即可将 TiDB 数据加载为 Spark DataFrame,并在 Databricks 中分析这些数据。
- 创建一个 Spark DataFrame 用于加载 TiDB 数据。这里,我们将引用在之前步骤中定义的变量:
%scalaval remote_table = spark.read.format("jdbc").option("url", url).option("dbtable", table).option("user", user).option("password", password).load()- 查询数据。Databricks 提供强大的图表显示功能,您可以自定义图表类型:
%scaladisplay(remote_table.select("*"))
- 创建一个 DataFrame 视图或一张 DataFrame 表。我们创建一个名为 “trips” 的视图作为示例:
%scalaremote_table.createOrReplaceTempView("trips")- 使用 SQL 语句查询数据。以下语句将查询每种类型单车的数量:
%sqlSELECT rideable_type, COUNT(*) count FROM trips GROUP BY rideable_type ORDER BY count DESC- 将分析结果写入 TiDB Cloud:
%scalaspark.table("type_count").withColumnRenamed("type", "count").write.format("jdbc").option("url", url).option("dbtable", "bikeshare.type_count").option("user", user).option("password", password).option("isolationLevel", "NONE").mode(SaveMode.Append).save()将 TiDB Cloud 样例笔记本导入 Databricks
我们使用的 TiDB Cloud 样例笔记本包含使用 Databricks 连接 TiDB Cloud 和在 Databricks 中分析 TiDB 数据两个步骤。您可以直接导入该样例笔记本,以便聚焦于分析过程。
在 Databricks 工作区,单击 Create > Import,并粘贴 TiDB Cloud 样例 URL,将笔记本下载到您的 Databricks 工作区。
将该笔记本关联到您的 Spark 集群。
使用您自己的 TiDB Cloud 集群信息替换样例中的 JDBC 配置。
按照笔记本中的步骤,通过 Databricks 使用 TiDB Cloud。
总结
本文主要介绍了如何通过 Databricks 使用 TiDB Cloud。
同时,我们正在编写另一个教程,用来介绍如何通过 TiSpark(TiDB/TiKV 上层用于运行 Apache Spark 的轻量查询层,项目链接:https://github.com/pingcap/tispark)在 TiDB 上使用 Databricks 进行数据分析,敬请期待。
原文链接:https://en.pingcap.com/blog/analytics-on-tidb-cloud-with-databricks/
边栏推荐
- 编译器R8问题Multidex
- ecshop安装的时候提示不支持JPEG格式
- I advise those juniors and juniors who have just started working: If you want to enter a big factory, you must master these core skills!Complete Learning Route!
- MySQL 视图(详解)
- 期刊投递时的 Late News Submission 是什么
- MySQL 日期时间类型精确到毫秒
- ReentrantLock
- js implements the 2020 New Year's Day countdown bulletin board
- 0730~Mysql optimization
- SQL join table (inner join, left join, right join, cross join, full outer join)
猜你喜欢
Flink1.15 source code reading - PER_JOB vs APPLICATION execution process
SSM framework explanation (the most detailed article in history)
I advise those juniors and juniors who have just started working: If you want to enter a big factory, you must master these core skills!Complete Learning Route!

浏览器使用占比js雷达图

【问题记录】TypeError: eval() arg 1 must be a string, bytes or code object

Kotlin—基本语法 (五)

How to Install MySQL on Linux

Feign介绍
djangoWeb应用框架+MySQL数据4
安装gnome-screenshot截图工具
随机推荐
ARC在编译和运行做了什么?
MySQL 排序
Spark 在 Yarn 上运行 Spark 应用程序
qt在不同的线程中传递自定义结构体参数
ScheduledExecutorService - 定时周期执行任务
skynet中一条消息从取出到处理完整流程(源码刨析)
SQL join table (inner join, left join, right join, cross join, full outer join)
Flink1.15源码阅读——PER_JOB vs APPLICATION执行流程
Golang-based swagger super intimate and super detailed usage guide [there are many pits]
JS中原型和原型链的详细讲解(附代码示例)以及 new关键字具体做了什么的详细讲解
Scala基础【seq、set、map、元组、WordCount、队列、并行】
第二十三课,抗锯齿(Anti Aliasing)
MUI获取相机权限
[What is the role of auto_increment in MySQL?】
来n遍剑指--09. 用两个栈实现队列
2022 Hangzhou Electric Cup Super League 3
数字加分隔符
2019 NeurIPS | Graph Convolutional Policy Network for Goal-Directed Molecular Graph Generation
vue element form表单规则校验 点击提交后直接报数据库错误,没有显示错误信息
js department budget and expenditure radar chart