当前位置:网站首页>Redis getting started complete tutorial: hash description
Redis getting started complete tutorial: hash description
2022-07-04 23:00:00 【Gu Ge academic】
Almost all programming languages provide hashes (hash) type , Their name may be ha
Greek 、 Dictionaries 、 Associative array . stay Redis in , Hash type means that the key itself is a key value pair
structure , Form like value={ {field1,value1},...{fieldN,valueN}},Redis Key value pairs and
The relationship between hash type and hash type can be shown in Figure 2-14 To express .
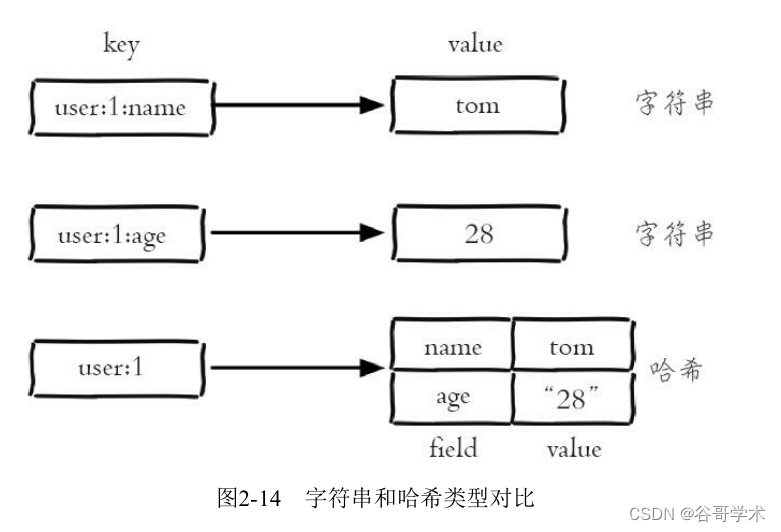
The mapping relationship in a hash type is called field-value, Notice the value Refer to field Corresponding
Value , The key of the value is not , Please note that value Role in different contexts .
2.3.1 command
(1) Set the value
hset key field value
The following is user:1 Add a pair of field-value:
127.0.0.1:6379> hset user:1 name tom
(integer) 1
If the setting is successful, it will return 1, On the contrary, it will return 0. Besides Redis Provides hsetnx command , it
Our relationship is like set and setnx command , It's just that the scope changes from bond to field.
(2) Get value
hget key field
for example , The following operation gets user:1 Of name Domain ( attribute ) Corresponding value :
127.0.0.1:6379> hget user:1 name
"tom"
If the key or field non-existent , Returns the nil:
127.0.0.1:6379> hget user:2 name
(nil)
127.0.0.1:6379> hget user:1 age
(nil)
(3) Delete field
hdel key field [field ...]
hdel Will delete one or more field, The result is successfully deleted field The number of , for example :
127.0.0.1:6379> hdel user:1 name
(integer) 1
127.0.0.1:6379> hdel user:1 age
(integer) 0
(4) Calculation field Number
hlen key
for example user:1 Yes 3 individual field:
127.0.0.1:6379> hset user:1 name tom
(integer) 1
127.0.0.1:6379> hset user:1 age 23
(integer) 1
127.0.0.1:6379> hset user:1 city tianjin
(integer) 1
127.0.0.1:6379> hlen user:1
(integer) 3
(5) Batch set or get field-value
hmget key field [field ...]
hmset key field value [field value ...]
hmset and hmget They are batch setting and obtaining field-value,hmset The required parameter is key
And many pairs field-value,hmget The required parameter is key And multiple field. for example :
127.0.0.1:6379> hmset user:1 name mike age 12 city tianjin
OK
127.0.0.1:6379> hmget user:1 name city
1) "mike"
2) "tianjin"
(6) Judge field Whether there is
hexists key field
for example ,user:1 contain name Domain , So the return result is 1, Return when not included 0:
127.0.0.1:6379> hexists user:1 name
(integer) 1
(7) Get all field
hkeys key
hkeys The order should be hfields More appropriate , It returns all of the field, example
Such as :
127.0.0.1:6379> hkeys user:1
1) "name"
2) "age"
3) "city"
(8) Get all value
hvals key
The following operation gets user:1 All value:
127.0.0.1:6379> hvals user:1
1) "mike"
2) "12"
3) "tianjin"
(9) Get all field-value
hgetall key
The following operation gets user:1 be-all field-value:
127.0.0.1:6379> hgetall user:1
1) "name"
2) "mike"
3) "age"
4) "12"
5) "city"
6) "tianjin"
Development tips
In the use of hgetall when , If there are many hash elements , There will be blocking Redis The possibility of .
If the developer just needs to get part of it field, have access to hmget, If you have to get everything
field-value, have access to hscan command , This command iterates over the hash type ,hscan Will be in
2.7 Section introduction .
(10)hincrby hincrbyfloat
hincrby key field
hincrbyfloat key field
hincrby and hincrbyfloat, It's like incrby and incrbyfloat command , But their work
The domain is filed.
(11) Calculation value String length of ( need Redis3.2 above )
hstrlen key field
for example hget user:1name Of value yes tom, that hstrlen The return result is 3:
127.0.0.1:6379> hstrlen user:1 name
(integer) 3
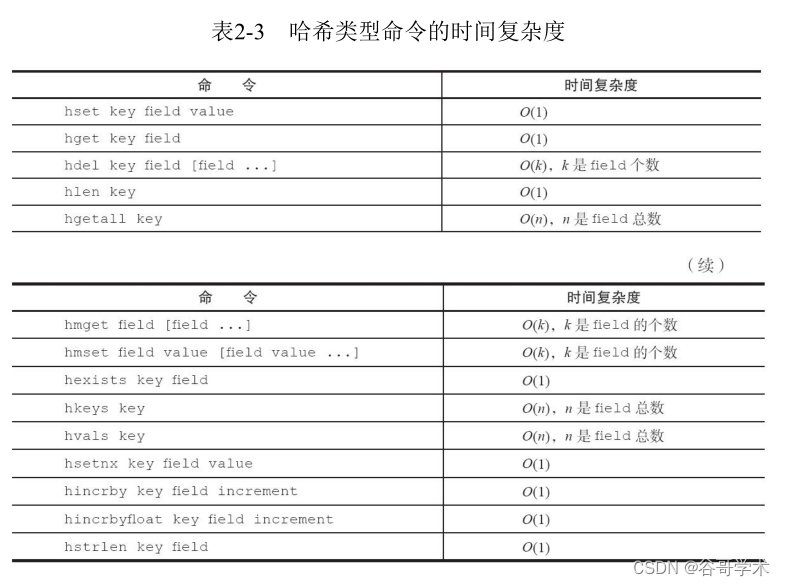
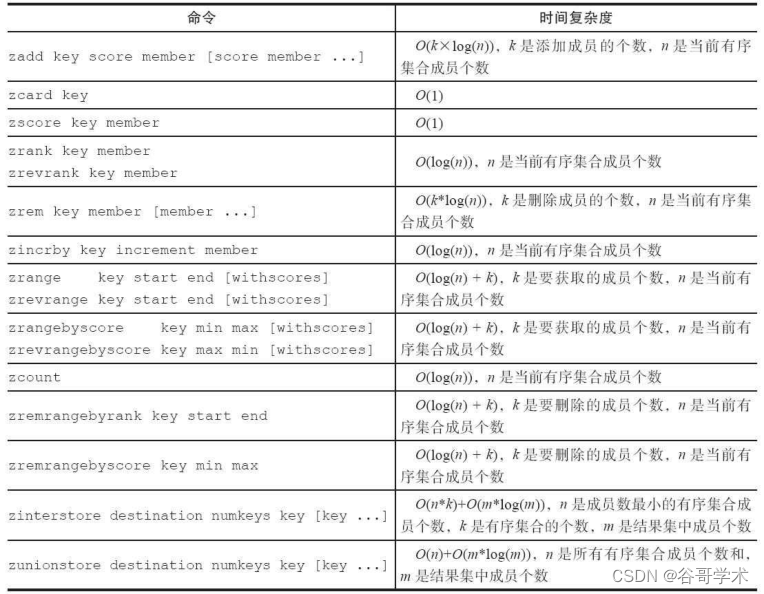
surface 2-3 Is the time complexity of hash type commands , Developers can refer to this table to select the appropriate
The order of .
2.3.2 Internal encoding
There are two types of internal encoding for hash types :
·ziplist( Compressed list ): When the number of hash type elements is less than hash-max-ziplist-entries
To configure ( Default 512 individual )、 At the same time, all values are less than hash-max-ziplist-value To configure ( Default 64
byte ) when ,Redis Will use ziplist As an internal implementation of hash ,ziplist Use more compact
Structure realizes the continuous storage of multiple elements , So in terms of saving memory hashtable Better .
·hashtable( Hashtable ): When the hash type cannot be satisfied ziplist The condition of ,Redis Can make
use hashtable As an internal implementation of hash , Because at this time ziplist The efficiency of reading and writing will decrease , and
hashtable The time complexity of reading and writing is O(1).
The following example demonstrates the internal encoding of a hash type , And the corresponding changes .
1) When field The number is small and there is no big one value when , The internal code is ziplist:
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2
OK
127.0.0.1:6379> object encoding hashkey
"ziplist"
2.1) When there is value Greater than 64 byte , The internal code will be written by ziplist Turn into hashtable:
127.0.0.1:6379> hset hashkey f3 "one string is bigger than 64 byte... Ignore ..."
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"
2.2) When field The number exceeds 512, Internal coding will also be done by ziplist Turn into hashtable:
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2 f3 v3 ... Ignore ... f513 v513
OK
127.0.0.1:6379> object encoding hashkey
"hashtable"
2.3.3 Use scenarios
chart 2-15 Two pieces of user information recorded for a relational data table , The user's properties are the columns of the table ,
Each user information as a line .
If you store it in a hash type , Pictured 2-16 Shown .
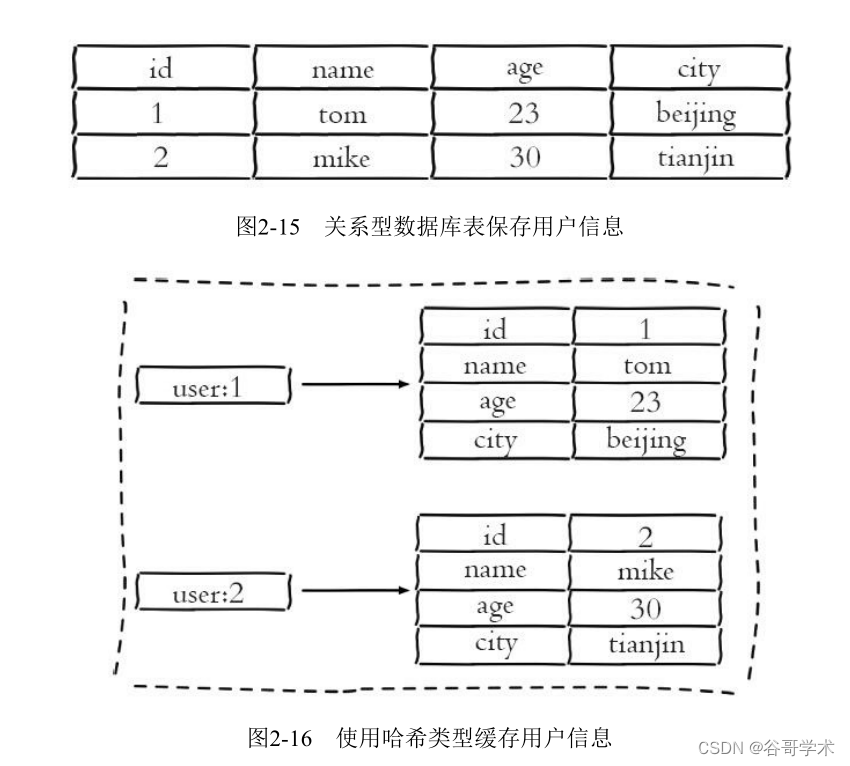
Instead of caching user information using string serialization , Hash types become more intuitive , also
102
It will be more convenient to update . Each user's id Defined as the key suffix , How to field-
value Attribute corresponding to each user , Similar to the following pseudo code :
UserInfo getUserInfo(long id){
// user id As key suffix
userRedisKey = "user:info:" + id;
// Use hgetall Get all user information mapping relationships
userInfoMap = redis.hgetAll(userRedisKey);
UserInfo userInfo;
if (userInfoMap != null) {
// Convert the mapping relationship to UserInfo
userInfo = transferMapToUserInfo(userInfoMap);
} else {
// from MySQL Get user information
userInfo = mysql.get(id);
// take userInfo Change to mapping relation using hmset Save to Redis in
redis.hmset(userRedisKey, transferUserInfoToMap(userInfo));
// Add expiration time
redis.expire(userRedisKey, 3600);
}
return userInfo;
}
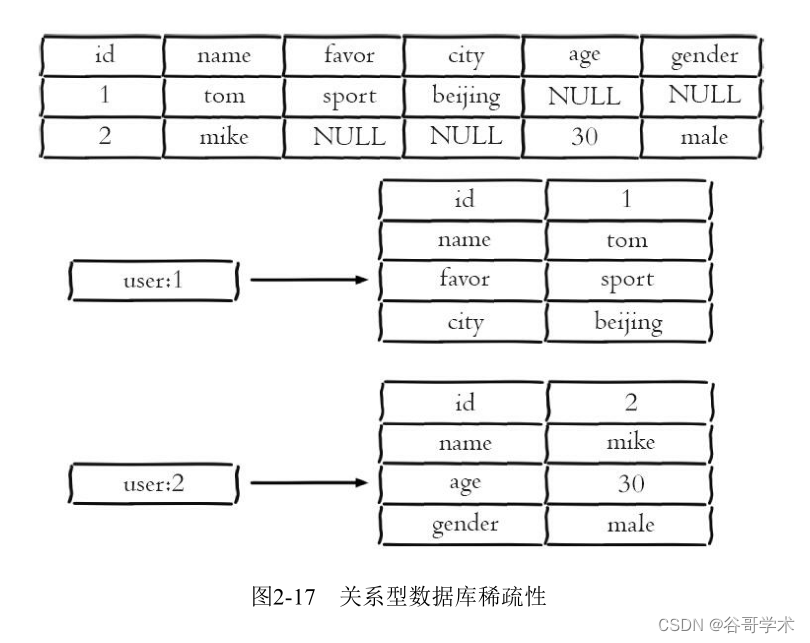
But it should be noted that there are two differences between hash type and relational database :
· Hash type is sparse , And relational databases are completely structured , For example, hash type
Each key can have a different field, Once a new column is added to a relational database , All lines should be
Its setting value ( Even for NULL), Pictured 2-17 Shown .
· Relational databases can do complex relational queries , and Redis To simulate complex relational queries
Development is difficult , Maintenance costs are high .
Developers need to understand the characteristics of both , In order to use the right technology in the right scene
Technique . up to now , We've been able to cache user information in three ways , Three methods are given below
Implementation method and analysis of advantages and disadvantages of the case .
1) Native string type : One key per attribute .
set user:1:name tom
set user:1:age 23
set user:1:city beijing
advantage : Simple and intuitive , Each property supports update operations .
shortcoming : Too many keys , Large memory consumption , At the same time, the cohesion of user information is relatively poor ,
So this kind of solution will not be used in the production environment .
2) Serialized string type : Serialize user information and save it with a key .
set user:1 serialize(userInfo)
advantage : Simplify programming , If the reasonable use of serialization can improve the efficiency of memory use .
shortcoming : Serialization and deserialization have some overhead , At the same time, every time the attribute is updated, the full
Part of the data is taken out for deserialization , Update and serialize to Redis in .
3) Hash type : Each user attribute uses a pair of field-value, But with only one key
save .
hmset user:1 name tomage 23 city beijing
advantage : Simple and intuitive , If used reasonably, it can reduce the use of memory space .
shortcoming : To control the hash in ziplist and hashtable Conversion of two internal codes ,hashtable Meeting
Consume more memory .
边栏推荐
- 小程序vant tab组件解决文字过多显示不全的问题
- The new version judges the code of PC and mobile terminal, the mobile terminal jumps to the mobile terminal, and the PC jumps to the latest valid code of PC terminal
- A complete tutorial for getting started with redis: redis shell
- 剑指 Offer 65. 不用加减乘除做加法
- 攻防世界 MISC 进阶区 hong
- Google Earth engine (GEE) -- take modis/006/mcd19a2 as an example to batch download the daily mean, maximum, minimum, standard deviation, statistical analysis of variance and CSV download of daily AOD
- Redis入门完整教程:键管理
- 云服务器设置ssh密钥登录
- Google collab trample pit
- P2181 diagonal and p1030 [noip2001 popularization group] arrange in order
猜你喜欢
蓝队攻防演练中的三段作战
Redis入门完整教程:有序集合详解
Unity修仙手游 | lua动态滑动功能(3种源码具体实现)
Duplicate ADMAS part name
The overview and definition of clusters can be seen at a glance
Redis getting started complete tutorial: Geo
Attack and Defense World MISC Advanced Area Erik baleog and Olaf
Redis démarrer le tutoriel complet: Pipeline
Redis introduction complete tutorial: client communication protocol
质量体系建设之路的分分合合
随机推荐
【剑指Offer】6-10题
Detailed explanation of heap sort code
Gnawing down the big bone - sorting (II)
The new version judges the code of PC and mobile terminal, the mobile terminal jumps to the mobile terminal, and the PC jumps to the latest valid code of PC terminal
Redis: redis configuration file related configuration and redis persistence
Analysis of environmental encryption technology
Unity Xiuxian mobile game | Lua dynamic sliding function (specific implementation of three source codes)
sobel过滤器
Redis的持久化机制
攻防世界 MISC 进阶 glance-50
Analog rocker controlled steering gear
Redis getting started complete tutorial: publish and subscribe
Redis入门完整教程:事务与Lua
Pagoda 7.9.2 pagoda control panel bypasses mobile phone binding authentication bypasses official authentication
剑指 Offer 65. 不用加减乘除做加法
Attack and defense world misc master advanced zone 001 normal_ png
mamp下缺少pcntl扩展的解决办法,Fatal error: Call to undefined function pcntl_signal()
Redis入门完整教程:Redis使用场景
MySQL Architecture - logical architecture
Erik baleog and Olaf, advanced area of misc in the attack and defense world