当前位置:网站首页>[point cloud processing paper crazy reading classic version 10] - pointcnn: revolution on x-transformed points
[point cloud processing paper crazy reading classic version 10] - pointcnn: revolution on x-transformed points
2022-07-03 09:08:00 【LingbinBu】
PointCNN: Convolution On X-Transformed Points
Abstract
- problem : CNN Why so successful , That's because convolution operator Be able to take advantage of spatially-local correlation. But point clouds are irregular and disordered , So direct use kernel Convolution of point features will lead to the loss of shape information and the change of point cloud order
- Method : A simple and general framework is proposed PointCNN, For feature learning of point cloud , Learn from input points X \mathcal{X} X-transformation, It has achieved good results in two aspects :
① The weight of the input feature associated with these points
② Map the order of points to a potential and canonical The order of
stay X \mathcal{X} X-transformation Feature space will also be used convolution operator Multiplication and addition between elements of - Code :
①https://github.com/yangyanli/PointCNN TensorFlow edition
②https://github.com/pyg-team/pytorch_geometric PyTorch edition , This is a library , take PointCNN Encapsulation becomes a function
③https://github.com/nicolas-chaulet/torch-points3d Many classic articles are reproduced in a concentrated way

introduction
hypothesis C C C An unordered set of dimensional input features F = { f a , f b , f c , f d } \mathbb{F}=\left\{ { {f_a},{f_b},{f_c},{f_d}} \right\} F={ fa,fb,fc,fd} In the figure 1(( i i i)-( i v iv iv)) Is the same in all cases , And the size is 4 × C 4 \times C 4×C Of kernel K = [ k α , k β , k γ , k δ ] T \mathbf{K}=\left[k_{\alpha}, k_{\beta}, k_{\gamma}, k_{\delta}\right]^{T} K=[kα,kβ,kγ,kδ]T.
In the figure 1( i i i) in , The structure of the grid following a given rule , Local 2 × 2 2 \times 2 2×2patch The features in can be written with the size 4 × C 4 \times C 4×C Of [ f a , f b , f c , f d ] T \left[f_{a}, f_{b}, f_{c}, f_{d}\right]^{T} [fa,fb,fc,fd]T, Through and with K \mathbf{K} K Convolution , obtain f i = Conv ( K , [ f a , f b , f c , f d ] T ) f_{i}=\operatorname{Conv}\left(\mathbf{K},\left[f_{a}, f_{b}, f_{c}, f_{d}\right]^{T}\right) fi=Conv(K,[fa,fb,fc,fd]T), among Conv ( ⋅ , ⋅ ) \operatorname{Conv}(\cdot, \cdot) Conv(⋅,⋅) It is a simple multiplication between elements and sum 2 ^2 2 The operation of .
In the figure 1 ( i i ) , ( i i i ) (i i),(i i i) (ii),(iii) and ( i v ) (i v) (iv) in , The order of these points is arbitrary . According to the order in the figure , Input feature set F \mathbb{F} F stay ( i i ) (i i) (ii) and ( i i i ) (i i i) (iii) Can be written as [ f a , f b , f c , f d ] T \left[f_{a}, f_{b}, f_{c}, f_{d}\right]^{T} [fa,fb,fc,fd]T, stay ( i v ) (iv) (iv) Can be written as [ f c , f a , f b , f d ] T \left[f_{c}, f_{a}, f_{b}, f_{d}\right]^{T} [fc,fa,fb,fd]T. Based on this , If used directly convolution operator, The output characteristics of the three cases are shown in Figure 1 The formula in (1a). We can notice that , In any case f i i ≡ f i i i f_{i i} \equiv f_{i i i} fii≡fiii All set up , And in most cases f i i i ≠ f i v f_{i i i} \neq f_{i v} fiii=fiv establish . This example shows that the direct use of convolution will lead to the loss of shape information ( f i i ≡ f i i i f_{i i} \equiv f_{i i i} fii≡fiii) And changes in order ( f i i i ≠ f i v f_{i i i} \neq f_{i v} fiii=fiv).
This paper proposes using multi-layer perceptron to learn K × K X K \times K \mathcal{X} K×KX-transformation, Yes K K K Input point cloud ( p 1 , p 2 , … , p K ) \left(p_{1}, p_{2}, \ldots, p_{K}\right) (p1,p2,…,pK) Coordinate transformation , namely X = M L P ( p 1 , p 2 , … , p K ) \mathcal{X}=M L P\left(p_{1}, p_{2}, \ldots, p_{K}\right) X=MLP(p1,p2,…,pK). Our goal is to use this transformation to simultaneously weight and rank the input features , Then convolute the transformed features . The above steps can be called X \mathcal{X} X-Conv, yes PointCNN A foundation in block. X \mathcal{X} X-Conv stay ( i i ) , ( i i i ) (i i),(i i i) (ii),(iii) and ( i v ) (i v) (iv) Can be represented as a graph 1 Chinese formula (1b), among X \mathcal{X} Xs It's a 4 × 4 4 \times 4 4×4 Matrix , Because in the picture K = 4 K=4 K=4. We can notice that , because X i i \mathcal{X}_{i i} Xii and X i i i \mathcal{X}_{i i i} Xiii It is learned from different shapes , So they can be different , Thus, the corresponding weight is applied to the input characteristics , And achieve f i i ≠ f i i i f_{i i} \neq f_{i i i} fii=fiii The effect of . about X i i i \mathcal{X}_{i i i} Xiii and X i v \mathcal{X}_{i v} Xiv, If they can meet after learning X i i i = X i v × Π \mathcal{X}_{i i i}=\mathcal{X}_{i v} \times \Pi Xiii=Xiv×Π, among Π \Pi Π Yes, it will ( c , a , b , d ) (c, a, b, d) (c,a,b,d) The order is ( a , b , c , d ) (a, b, c, d) (a,b,c,d) Sort matrix , Then you can also achieve f i i i ≡ f i v f_{i i i} \equiv f_{i v} fiii≡fiv The effect of .
Pass diagram 1 We can see from the example analysis in , In the ideal X \mathcal{X} X-transformation Next , X \mathcal{X} X-Conv Can consider the shape of the point , At the same time, it has sorting invariance . in fact , What we found and learned X \mathcal{X} X-transformation It's far from what we thought , Especially in the aspect of sort invariance . however , be based on X \mathcal{X} X-Conv Of PointCNN The performance of is better than that of the existing methods .
PointCNN
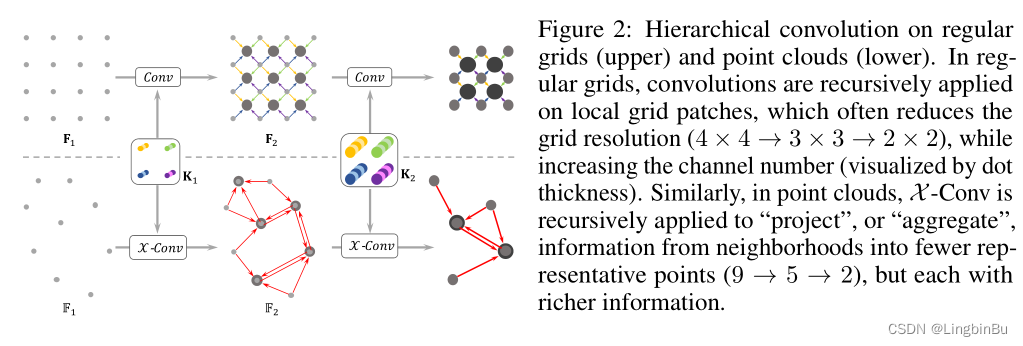
Hierarchical Convolution
Introducing PointCNN Medium hierarchical convolution Before , First, it briefly introduces its application in regular grid , Pictured 2 As shown above . Based on CNN For the grid , The input size is R 1 × R 1 × C 1 R_{1} \times R_{1} \times C_{1} R1×R1×C1 Characteristic graph F 1 \mathbf{F}_{1} F1, among R 1 R_{1} R1 Is the spatial resolution , C 1 C_{1} C1 The characteristic number of channels is . The size is K × K × C 1 × C 2 K \times K \times C_{1} \times C_{2} K×K×C1×C2 Of kernel and F 1 \mathbf{F}_{1} F1 The middle size is K × K × C 1 K \times K \times C_{1} K×K×C1 Of patches Convolution , Get another size of R 2 × R 2 × C 2 R_{2} \times R_{2} \times C_{2} R2×R2×C2 Characteristic graph F 2 \mathbf{F}_{2} F2. In the figure 2 upper-middle , R 1 = 4 , K = 2 R_{1}=4, K=2 R1=4,K=2, R 2 = 3 R_{2}=3 R2=3. With the characteristics of F 1 \mathbf{F}_{1} F1x comparison , F 2 \mathbf{F}_{2} F2 The spatial resolution of is very low ( ( R 2 < R 1 ) \left(R_{2}<R_{1}\right) (R2<R1)), But with a deeper number of channels ( ( C 2 > C 1 ) \left(C_{2}>C_{1}\right) (C2>C1)), And have higher-level information .
PointCNN The input is F 1 = { ( p 1 , i , f 1 , i ) : i = 1 , 2 , … , N 1 } \mathbb{F}_{1}=\left\{\left(p_{1, i}, f_{1, i}\right): i=1,2, \ldots, N_{1}\right\} F1={ (p1,i,f1,i):i=1,2,…,N1}, among { p 1 , i : p 1 , i ∈ \left\{p_{1, i}: p_{1, i} \in\right. { p1,i:p1,i∈ R Dim } \left.\mathbb{R}^{\text {Dim }}\right\} RDim } It's a set of points , There are also features corresponding to each point { f 1 , i : f 1 , i ∈ R C 1 } \left\{f_{1, i}: f_{1, i} \in \mathbb{R}^{C_{1}}\right\} { f1,i:f1,i∈RC1}. Based on grid CNN Layered structure , stay F 1 \mathbb{F}_{1} F1 On the application X \mathcal{X} X-Conv You can get a higher level of expression F 2 = { ( p 2 , i , f 2 , i ) : f 2 , i ∈ R C 2 , i = 1 , 2 , … , N 2 } \mathbb{F}_{2}=\left\{\left(p_{2, i}, f_{2, i}\right): f_{2, i} \in \mathbb{R}^{C_{2}}, i=1,2, \ldots, N_{2}\right\} F2={ (p2,i,f2,i):f2,i∈RC2,i=1,2,…,N2}, among { p 2 , i } \left\{p_{2, i}\right\} { p2,i} yes { p 1 , i } \left\{p_{1, i}\right\} { p1,i} A group of points of , F 2 \mathbb{F}_{2} F2 The spatial resolution ratio of F 1 \mathbb{F}_{1} F1 Small , F 2 \mathbb{F}_{2} F2 The ratio of the number of channels F 1 \mathbb{F}_{1} F1 many , namely N 2 < N 1 N_{2}<N_{1} N2<N1, C 2 > C 1 C_{2}>C_{1} C2>C1. After the above operation cycle , Features with input points will be “ Projection ” or “ polymerization ” To fewer points , But the characteristic information of each point is richer .
{ p 2 , i } \left\{p_{2, i}\right\} { p2,i} The point in the classification task is through { p 1 , i } \left\{p_{1, i}\right\} { p1,i} Obtained by random down sampling , In the segmentation task, it is through Farthest Point Sampling(FPS) The algorithm gets , Because the segmentation task requires even point distribution . If there is a better way to choose points , Then the final result will be better , In the future work, we will conduct in-depth research .
X \mathcal{X} X-Conv Operator
X \mathcal{X} X-Conv Operate in a local area of the point cloud , Because the output characteristics should be consistent with the representation point { p 2 , i } \left\{p_{2, i}\right\} { p2,i} Related to , therefore X \mathcal{X} X-Conv Put them in { p 1 , i } \left\{p_{1, i}\right\} { p1,i} Neighborhood points in 、 Relevant characteristics as input , To convolute . For a simpler description , remember p p p by { p 2 , i } \left\{p_{2, i}\right\} { p2,i} Points in , p p p Is characterized by f f f, p p p stay { p 1 , i } \left\{p_{1, i}\right\} { p1,i} The adjacent points of are N \mathbb{N} N. therefore , For a particular point p p p for , X \mathcal{X} X-Conv The input is S = { ( p i , f i ) : p i ∈ N } \mathbb{S}=\left\{\left(p_{i}, f_{i}\right): p_{i} \in \mathbb{N}\right\} S={ (pi,fi):pi∈N}. S \mathbb{S} S Is an unordered set . Without losing generality , S \mathbb{S} S It can be written. K × D i m K \times Dim K×Dim Matrix P = ( p 1 , p 2 , … , p K ) T \mathbf{P}=\left(p_{1}, p_{2}, \ldots, p_{K}\right)^{T} P=(p1,p2,…,pK)T and K × C 1 K \times C_{1} K×C1 Matrix F = ( f 1 , f 2 , … , f K ) T \mathbf{F}=\left(f_{1}, f_{2}, \ldots, f_{K}\right)^{T} F=(f1,f2,…,fK)T, K \mathbf{K} K It means to train kernel. With these inputs , You can calculate p p p The output characteristics of :
F p = X − Conv ( K , p , P , F ) = Conv ( K , MLP ( P − p ) × [ M L P δ ( P − p ) , F ] ) , \mathbf{F}_{p}=\mathcal{X}-\operatorname{Conv}(\mathbf{K}, p, \mathbf{P}, \mathbf{F})=\operatorname{Conv}\left(\mathbf{K}, \operatorname{MLP}(\mathbf{P}-p) \times\left[M L P_{\delta}(\mathbf{P}-p), \mathbf{F}\right]\right), Fp=X−Conv(K,p,P,F)=Conv(K,MLP(P−p)×[MLPδ(P−p),F]),
among M L P δ ( ⋅ ) M L P_{\delta}(\cdot) MLPδ(⋅) It is a multi-layer perceptron acting on a single point , stay X \mathcal{X} X-Conv All operations , Conv ( ⋅ , ⋅ ) , MLP ( ⋅ ) \operatorname{Conv}(\cdot, \cdot), \operatorname{MLP}(\cdot) Conv(⋅,⋅),MLP(⋅), Matrix multiplication ( ⋅ ) × ( ⋅ ) (\cdot) \times(\cdot) (⋅)×(⋅) and M L P δ ( ⋅ ) M L P_{\delta}(\cdot) MLPδ(⋅) It's all derivable , that X \mathcal{X} X-Conv It's also derivable , So it can be used in other back propagation neural networks .
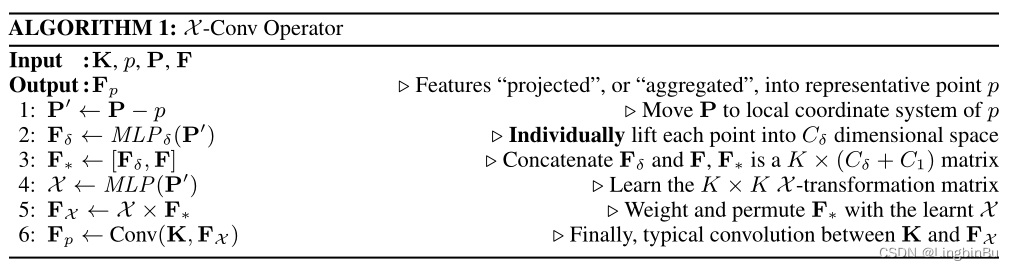
Algorithm 1 No 4-6 Line mainly expresses the equation 1b( X \mathcal{X} X-transformation).
Algorithm 1 No 1-3 In line , Normalize the neighborhood points to points p p p On the relative position of , So as to obtain local features . When outputting features , Neighborhood points and corresponding features need to be determined together , But the dimension and representation of local coordinates are different from the corresponding features . To solve this problem , First, raise the coordinates to a higher dimension and a more abstract representation ( Such as algorithm 1 Of the 2 Line ), Then it is spliced with the corresponding features ( Algorithm 1 Of the 3 That's ok ), For later processing ( chart 3 c).

adopt point-wise M L P δ ( ⋅ ) M L P_{\delta}(\cdot) MLPδ(⋅) Map coordinates to features , This is related to PointNet The methods used in are similar , The difference is that symmetric functions are not used for processing . This passage X \mathcal{X} X-transformation Weight and sort coordinates and features , This X \mathcal{X} X-transformation It is learned by all adjacent points . The final X \mathcal{X} X Depends on the order of points , This is expected , because X \mathcal{X} X The pairs should be arranged according to the input points F ∗ \mathbf{F}_{*} F∗ Sort , Therefore, you must know the specific input order . For input point clouds without any additional features , namely F \mathbf{F} F It's empty , first X \mathcal{X} X-Conv Layers only use F δ \mathbf{F}_{\delta} Fδ. therefore ,PointCNN Point clouds with or without additional features can be handled in a robust general way .
X \mathcal{X} X
PointCNN Architectures
Conv layers in grid-based CNNs and X \mathcal{X} X-Conv layers in PointCNN There are two differences :
- The methods of local feature extraction are different ( K × K K \times K K×K patches vs. Indicates K K K Adjacent points )
- There are different ways to learn from local areas (Conv vs. X \mathcal{X} X-Conv)
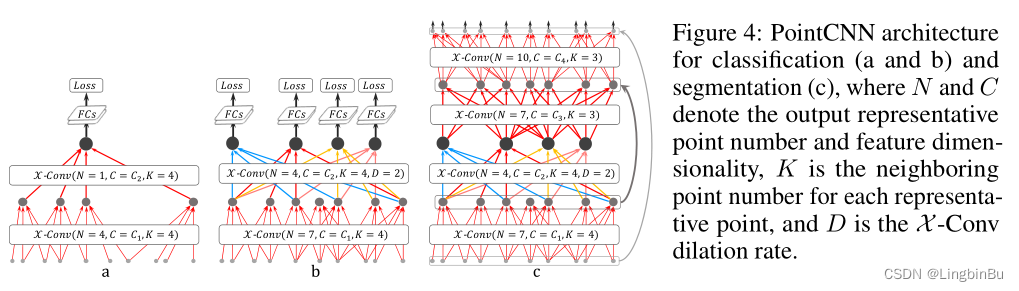
chart 4(a) Describes one with two X \mathcal{X} X-Conv Layer of PointCNN structure , Will enter a point ( With or without features ) Gradually become few representation points , But these points have rich characteristics . In the second X \mathcal{X} X-Conv After the layer , There is only one representation point left , This is the representation point from which the information of all points in the previous layers is aggregated . stay PointCNN in , The perception domain of each representation point can be defined as a proportion K / N K/N K/N, among K K K Is the number of adjacent points , N N N Is the number of points on the previous floor . such , The last point can “ notice ” Points of all previous layers , Therefore, the proportion of its perception domain is 1.0—— It has a global view of the entire shape , And its features are also very informative for the semantic understanding of shapes . At the end of the X \mathcal{X} X-Conv Add a full connection layer behind the layer , Then we can train the network with a loss function .
We noticed that the number of points is above X \mathcal{X} X-Conv The layer drops quickly ( chart 4a), It makes the simple network unable to carry out comprehensive training . To solve this problem , A method with dense connections is proposed PointCNN Model , Pictured 4b Shown . stay X \mathcal{X} X-Conv More representation points are reserved in the layer . however , Our goal is to keep the depth of the network unchanged , While maintaining the growth rate of the perception domain , Only such a deep expression point can “ notice ” A larger area of the whole shape . therefore , stay PointCNN From grid-based CNNs Borrowed from dilated convolution thought . No longer in a fixed K K K Adjacent points as input , But randomly from K × D K \times D K×D Randomly sampled from adjacent points K K K Input points , among D D D yes dilation rate. under these circumstances , Without increasing the sum of the actual number of adjacent points kernel In case of size , The proportion of perception domain ranges from K / N K/N K/N Growth to ( K × D ) / N (K\times D)/N (K×D)/N.
And graph 4a comparison , chart 4b Last of all X \mathcal{X} X-Conv Layer. 4 All points are ok “ notice ” Entire shape , Therefore, they are suitable for prediction . In the test phase ,softmax Previously, multiple prediction results can be averaged , Make the prediction result more stable .
For split tasks , You need to output the original resolution points , This can be done by constructing Conv-DeConv Structure implementation , among DeConv Part is the process of spreading global information to higher resolution prediction , See the picture 4c. It is worth noting that ,PointCNN Segment the network “Conv” and “DecConv” It's all the same X \mathcal{X} X-Conv operation .“Conv” and “DeConv” The only difference between them is that the output of the latter has more points , Fewer channels .
Use in front of the last full connection layer dropout Reduce over fitting , Also used. subvolume supervision Further reduce over fitting . At the end of the X \mathcal{X} X-Conv Layer , The proportion of perception domain is set to be less than 1 Number of numbers , So that only part of the information is observed . In the process of training , The network is required to learn more difficult from some information , In this way, it will perform better in the test . under these circumstances , It is important to represent the global coordinates of points , So by M L P g ( ⋅ ) MLP_{g}(\cdot) MLPg(⋅) Promote the global coordinates to the feature space R C g \mathbb{R}^{C_g} RCg, And spliced to X \mathcal{X} X-Conv in , For further processing through subsequent layers .
Data augmentation
To improve generalization , Random sampling of input points and shuffle, such batch And batch The set and order of adjacent points will be different . In order to train a quantity of N N N As input , choice N ( N , ( N / 8 ) 2 ) \mathcal{N}(N,(N/8)^2) N(N,(N/8)2) Points for training , among N \mathcal{N} N Represents Gaussian distribution , This is good for PointCNN Training is crucial .
experiment
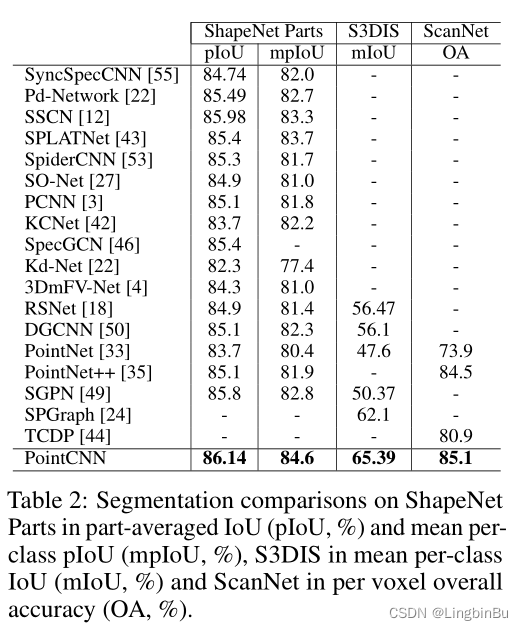
Classification


Segmentation
Ablation Experiments

Visualizations

Optimizer, model size, memory usage and timing

Conclusion
- How to understand and propose the effectiveness of the network is still a big problem
- take PointCNN And imageCNN It is also a very interesting field to combine processing pairs of point clouds and images
边栏推荐
- LeetCode 515. Find the maximum value in each tree row
- 传统企业数字化转型需要经过哪几个阶段?
- What is the difference between sudo apt install and sudo apt -get install?
- Wonderful review | i/o extended 2022 activity dry goods sharing
- Character pyramid
- Memory search acwing 901 skiing
- On the setting of global variable position in C language
- 状态压缩DP AcWing 91. 最短Hamilton路径
- LeetCode 30. 串联所有单词的子串
- AcWing 788. 逆序对的数量
猜你喜欢

Tree DP acwing 285 A dance without a boss

剑指 Offer II 091. 粉刷房子

Markdown learning

20220630 learning clock in

网络安全必会的基础知识
【点云处理之论文狂读经典版12】—— FoldingNet: Point Cloud Auto-encoder via Deep Grid Deformation
AcWing 787. 归并排序(模板)

Query XML documents with XPath

【点云处理之论文狂读经典版8】—— O-CNN: Octree-based Convolutional Neural Networks for 3D Shape Analysis

LeetCode 57. 插入区间
随机推荐
Gif remove blank frame frame number adjustment
LeetCode 532. K-diff number pairs in array
Complex character + number pyramid
excel一小时不如JNPF表单3分钟,这样做报表,领导都得点赞!
SQL statement error of common bug caused by Excel cell content that is not paid attention to for a long time
树形DP AcWing 285. 没有上司的舞会
php public private protected
LeetCode 871. Minimum refueling times
Use of sort command in shell
Facial expression recognition based on pytorch convolution -- graduation project
PHP mnemonic code full text 400 words to extract the first letter of each Chinese character
The difference between if -n and -z in shell
Use the interface colmap interface of openmvs to generate the pose file required by openmvs mvs
22-06-28 Xi'an redis (02) persistence mechanism, entry, transaction control, master-slave replication mechanism
Method of intercepting string in shell
【点云处理之论文狂读经典版11】—— Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling
too many open files解决方案
LeetCode 515. Find the maximum value in each tree row
22-06-27 Xian redis (01) commands for installing five common data types: redis and redis
Tree DP acwing 285 A dance without a boss