当前位置:网站首页>Popular understanding of linear regression (I)
Popular understanding of linear regression (I)
2022-07-03 15:16:00 【alw_ one hundred and twenty-three】
I have planned to present this series of blog posts in the form of animated interesting popular science , If you're interested Click here .
#0 What is return ?
Suppose linear regression is a black box , According to the programmer's thinking , This black box is a function , so what , We just need to pass some parameters to this function as input , You can get a result as output . What does return mean ? In fact, it's plain , The result of this black box output is a continuous value . If the output is not a continuous value but a discrete value, it is called classification . What is continuous value ? It's simple , Take a chestnut : For example, I tell you I have a house here , This house has 40 flat , At the subway entrance , Then guess how much my house is worth in total ? This is the continuous value , Because the house may be worth 80 ten thousand , It may also be worth 80.2 ten thousand , It may also be worth 80.111 ten thousand . Another example , I tell you I have a house ,120 flat , At the subway entrance , Total value 180 ten thousand , Then guess how many bedrooms my house will have ? Then this is the discrete value . Because the number of bedrooms can only be 1, 2, 3,4, At best 5 It's capped , And the number of bedrooms can't be anything 1.1, 2.9 individual . So , about ML Mengxin says , As long as you know that my task is to predict a continuous value , Then the task is to return . If it is a discrete value, it is classification .(PS: At present, only supervised learning is discussed )
#1 Linear regression
OK, Now that we know what regression is , Now let's talk about linear . In fact, this thing is also very simple , We all learned the linear equation in junior high school, didn't we ? Come on, come on , Let's recall what the linear equation is ?
y = k x + b y=kx+b y=kx+b
here , This is the straight-line equation that our junior high school math teacher taught us . All the students who went to junior high school know , This expression expresses , When I know k( Parameters ) and b( Parameters ) Under the circumstances , I'll just give one x I can calculate through this equation y Come on . And , This formula is linear , Why? ? Because intuitively , You all know , The function image of this formula is a straight line .... In theory , This formula satisfies the properties of linear system .( As for what a linear system is , I'll stop talking , Or it will be endless ) Some students may feel confused , This section is about linear regression , I pull this low Why force the linear equation ? Actually , To put it bluntly , Linear regression is nothing more than N Finding a function in dimensional space in the form of a linear equation to fit the data . for instance , I have this picture now , The abscissa represents the area of the house , The ordinate represents the house price .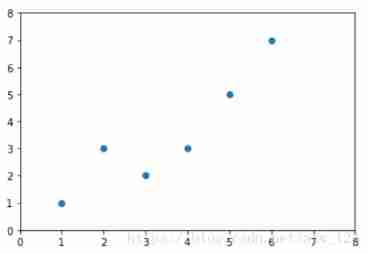
so what , Linear regression is to find a straight line , And let this line fit the data points in the graph as much as possible .
So if you let 1000 If an old iron comes to find this straight line, he may find 1000 A straight line , Such as this 
such 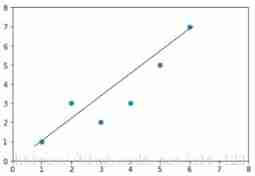
Or so 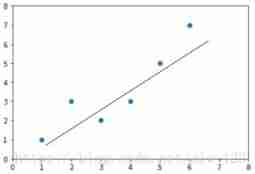
here , In fact, the process of finding a straight line is doing linear regression , It's just that this name is more powerful ...
#2 Loss function
Since it's looking for a straight line , There must be a standard for judging , To judge which line is the best .OK, We all know the truth , How to judge ? In fact, simple yuppies ... Just calculate the difference between the actual house price and the house price predicted by the straight line based on the size of the house I found . To put it bluntly, it's the distance between two points . When we compare all the actual house prices with the predicted house prices ( distance ) Calculate it and add it , We can quantify the error between our predicted house prices and actual house prices . For example, in the figure below, I draw many decimal lines , Each decimal line is the difference between the actual house price and the predicted house price ( distance )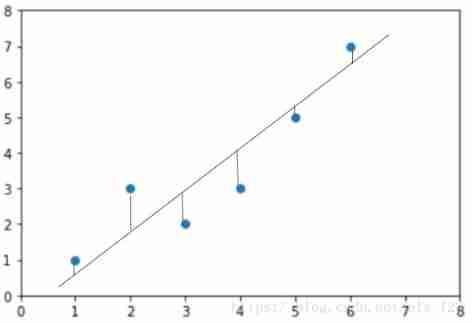
Then add up the length of each small vertical line, which is equal to the gap between the predicted house price and the actual house price . What is the sum of the length of each small vertical line ? It's actually European distance plus , The formula is as follows .( among y(i) It means the real house price ,y^(i) It means predicting house prices )
This Euclidean distance summation is actually a function used to quantify the error between the predicted result and the real result . stay ML It is called the loss function ( To put it bluntly, it is a function of the calculation error ). So with this function , We have a criterion , When the value of this function is smaller , The more it shows that the straight line we find can better fit our house price data . So say , Linear regression is nothing more than to find a straight line by using this loss function as the evaluation standard .
The example I just gave is a one-dimensional example ( The feature is only the size of the house ), Now let's assume that another feature of my data is the floor spacing , The image may be mauve .
We can see from the picture , Even in two-dimensional space , Or find a straight line to fit our data . So! , The soup does not change the dressing , The loss function is still the sum of Euclidean distances .
Let's start with this , Because if the space is too long , It's not very friendly for Mengxin , And later I want to talk about the normal equation solution of linear regression , So gather strength first .
边栏推荐
- 什么是Label encoding?one-hot encoding ,label encoding两种编码该如何区分和使用?
- Troubleshooting method of CPU surge
- Yolov5 advanced 8 format conversion between high and low versions
- 视觉上位系统设计开发(halcon-winform)-1.流程节点设计
- Halcon与Winform学习第一节
- 【注意力机制】【首篇ViT】DETR,End-to-End Object Detection with Transformers网络的主要组成是CNN和Transformer
- Concurrency-01-create thread, sleep, yield, wait, join, interrupt, thread state, synchronized, park, reentrantlock
- Finally, someone explained the financial risk management clearly
- Jvm-03-runtime data area PC, stack, local method stack
- 在MapReduce中利用MultipleOutputs输出多个文件
猜你喜欢
5.4-5.5

Introduction, use and principle of synchronized
Dataframe returns the whole row according to the value

Basic SQL tutorial

Jvm-08-garbage collector

Kubernetes vous emmène du début à la fin

Idea does not specify an output path for the module
视觉上位系统设计开发(halcon-winform)-4.通信管理
Concurrency-01-create thread, sleep, yield, wait, join, interrupt, thread state, synchronized, park, reentrantlock
High quality workplace human beings must use software to recommend, and you certainly don't know the last one
随机推荐
Incluxdb2 buckets create database
Idea does not specify an output path for the module
[cloud native training camp] module VIII kubernetes life cycle management and service discovery
The method of parameter estimation of user-defined function in MATLAB
Final review points of human-computer interaction
Kubernetes will show you from beginning to end
什么是Label encoding?one-hot encoding ,label encoding两种编码该如何区分和使用?
Enable multi-threaded download of chrome and edge browsers
使用JMeter对WebService进行压力测试
Jvm-06-execution engine
el-switch 赋值后状态不变化
Using Tengine to solve the session problem of load balancing
Remote server background hangs nohup
Yolov5 advanced seven target tracking latest environment construction (II)
Global and Chinese market of Bus HVAC systems 2022-2028: Research Report on technology, participants, trends, market size and share
视觉上位系统设计开发(halcon-winform)-3.图像控件
[transform] [practice] use pytoch's torch nn. Multiheadattention to realize self attention
Global and Chinese market of air cargo logistics 2022-2028: Research Report on technology, participants, trends, market size and share
解决pushgateway数据多次推送会覆盖的问题
Jvm-02-class loading subsystem