当前位置:网站首页>深入浅出边缘云 | 3. 资源配置
深入浅出边缘云 | 3. 资源配置
2022-07-30 20:31:00 【yuff100】
随着技术的发展以及应用对时延、带宽、安全的追求,一个明显的技术趋势是越来越多的应用组件将会被部署到企业所管理的网络边缘。本系列是开源电子书Edge Cloud Operations: A Systems Approach[1]的中文版,详细介绍了基于开源组件构建的边缘云的架构、功能及具体实现。

第3章 资源配置
资源配置是指为应用准备好随时可用的虚拟或物理资源的过程,包含人工操作组件(机架和连接设备)以及引导组件(配置资源如何引导到"就绪"状态)。资源配置发生在首次部署云的时候,即对资源进行初始化,但随着时间的推移,由于添加新资源、删除或者升级旧资源,配置的资源也会随之改变。
资源配置的目标是零接触(zero-touch),由于硬件资源天然需要人工操作,因此是不可能的(我们稍后讨论分配虚拟资源的问题)。实际上,我们的目标是尽量减少物理连接设备之外所需配置步骤的数量和复杂性,请记住,我们需要配置的是从供应商那购买的商品硬件,而不是已经准备好的即插即用设备。
当我们从虚拟资源(例如,在商业云上实例化虚拟机)构建云时,"机架和连接"步骤是通过一系列API调用来完成的,而不需要技术人员亲自动手。当然,我们希望将激活虚拟基础设施所需的一系列调用都自动化,这就产生了被称为"基础设施即代码(Infrastructure-as-Code)"的方法,这是第二章中介绍的"配置即代码(Configuration-as-Code)"概念的特殊情况。一般想法是用一种可"执行"的声明式格式记录基础架构到底是什么样子的以及如何配置。我们使用Terraform作为"基础设施即代码"的开源方法。
当云由虚拟资源和物理资源组合构建(就像Aether这样的混合云)时,需要一种无缝的方式来容纳两者。为此,我们的方法是首先在硬件资源上覆盖一个逻辑结构(logical structure) ,使其大致相当于我们从商业云提供商获得的虚拟资源,这将产生类似图11所示的混合场景。我们使用NetBox作为我们的开源解决方案,在物理硬件上分层这个逻辑结构,NetBox还帮助我们解决跟踪实物库存的需求。
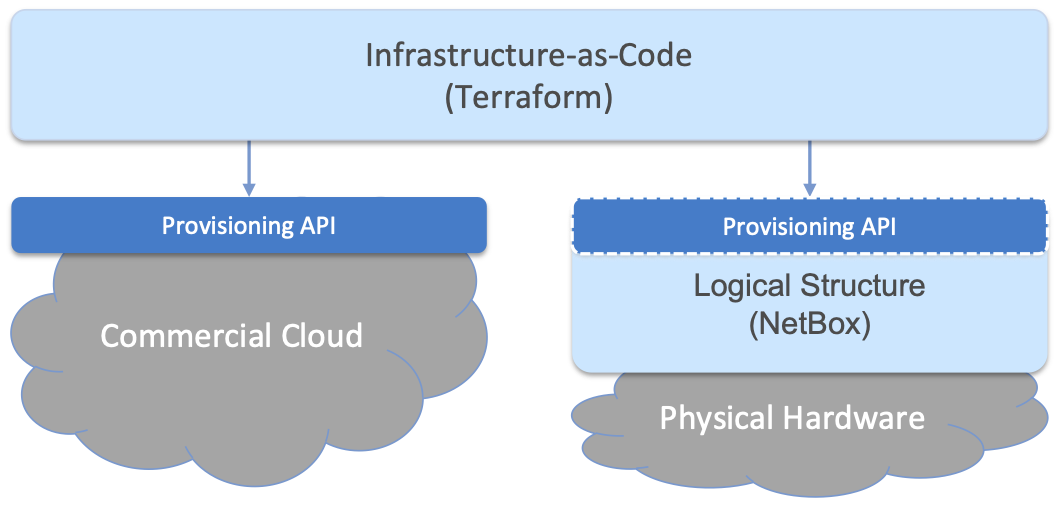
注意,图11中右边显示的Provisioning API不是NetBox API,Terraform不直接与NetBox交互,而是与3.1节中介绍的硬件配置流程工件交互。考虑这一问题的方法是,将硬件引导到"就绪"状态的任务涉及安装和配置若干个共同构成云平台的子系统,Terraform基于我们在3.1节末尾介绍的API与该平台交互。
本章从提供物理基础设施开始,介绍图11的两个方面。我们的方法是专注于初次配置整个站点的挑战。随着更多细节的出现,我们也将讨论更简单的增量配置单个资源的问题。
3.1 物理基础设施
将硬件设备放置到机架上的过程本质上是人力密集型的,需要考虑散热及电缆管理等因素,这些问题超出了本书范围。相反,我们关注的是"物理/虚拟"的边界,从布线规划开始,技术人员将其作为施工蓝图。这种规划的细节是高度特定于部署的,但我们使用图12所示示例帮助说明涉及的所有步骤。该示例通过在企业中部署Aether集群为例,有助于强调所需的专用性设施,通过大量规划指定适当的物料清单(BOM, Bill of Materials) ,其中包括了设备型号细节,但具体设备不在讨论范围之内。
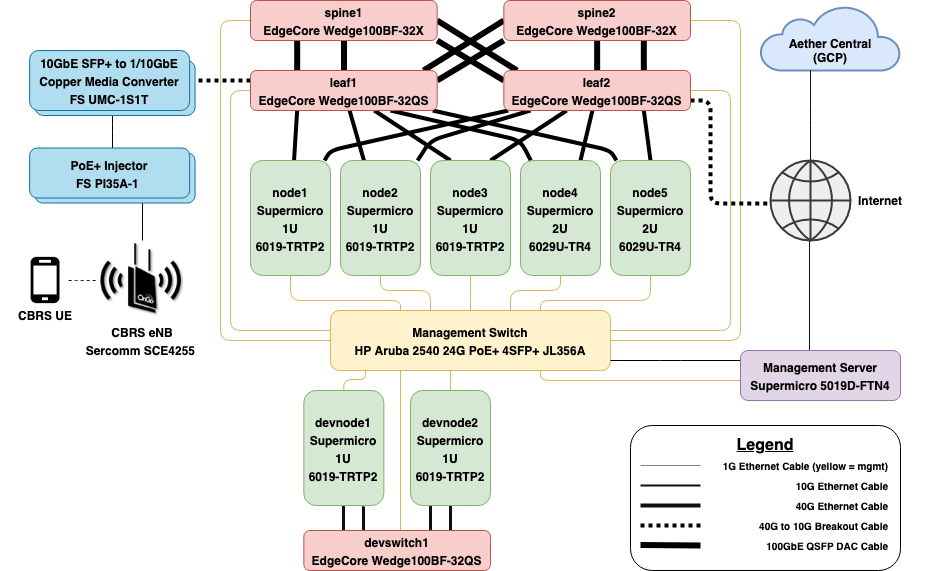
图12所示蓝图实际上包括两个共享管理交换机和管理服务器的逻辑集群。上层集群对应生产部署,包含5台服务器和2x2叶脊交换结构。下层集群用于开发,包括两个服务器和一个交换机。这种硬件资源的逻辑分组并不是Aether独有的,我们也可以要求商业云提供商提供多个逻辑集群,因此能够对物理资源进行相同操作是很自然的需求。
除了遵循这个蓝图,技术人员还将物理基础设施的实际数据输入数据库中,以用于后续配置步骤,后面我们将详细介绍。
3.1.1 文档基础设施
在数据库中记录物理基础设施的逻辑结构是我们跨越物理到虚拟鸿沟的方式,涉及到为所收集的信息定义模型(该模型有效的表示了图11中所示逻辑结构),以及输入关于物理设备的相应信息。无论这是更大规模自动化框架(如本书中描述的)的第一阶段,还只是简单记录分配给每个网络设备的IP地址,这个过程对于任何负责管理设备网络的人来说都很熟悉。
有几种开源工具可用于此任务,我们的选择是NetBox。该工具支持IPAM (IP地址管理),能记录关于设备类型及其安装位置的库存相关信息,维护集团和站点的基础设施架构,以及维护设备连接到控制台、网络和电源的信息。在NetBox网站上可以找到更多介绍。
延伸阅读:
NetBox[2]: Information Resource Modeling Application.
NetBox的关键特性之一是能够自定义用于组织收集到的所有信息的模型集。例如,运维人员可以定义机架(Rack) 和站点(Site) 这样的物理分组,也可以定义像组织(Organization) 和部署(Deployment) 这样的逻辑分组[1]。下面我们使用图12所示的Aether网络规划作为示例,重点关注配置单个Aether站点时发生的情况(但请记住,如第2章所述,Aether可以跨越多个站点)。
[1] 在本节中,我们用斜体表示模型和模型字段(例如,Site, Address),并将指定给模型实例的特定值作为常量(例如,
10.0.0.0/22)。
第一步是为准备的站点创建记录,记录该站点所有相关元数据,包括站点(Site)名称(Name) 和位置(Location) ,以及站点所属组织(Organization) 。一个组织(Organization) 可以有多个站点(Site) ,而一个站点(Site) 可以(a)跨越一个或多个机架(Rack) ,(b)托管一个或多个部署(Deployment) 。部署(Deployment) 是一个逻辑集群,例如Production、Staging和Development。图12所示的网络规划包括两个这样的部署。
这也是指定分配给特定边缘部署的VLAN和IP前缀的时间。由于维护VLAN、IP前缀和DNS域名(DNS是自动生成的)之间的明确关系非常重要,因此浏览下面的具体示例很有帮助。我们从每个站点所需的最小VLAN集开始:
ADMIN 1 UPLINK 10 MGMT 800 FABRIC 801
这些都是Aether特有的,也说明了集群可能需要的一组VLAN。至少,人们希望在任何集群中看到一个"管理"网络(本例中为MGMT)和一个"数据"网络(本例中为FABRIC)。同样针对Aether(但具有通用性),如果站点上有多个部署共享一个管理服务器,则会添加额外的VLAN (MGMT/FABRIC的id加10)。例如,第二个Development部署可能定义为:
DEVMGMT 810 DEVFABRIC 811
然后,IP前缀与VLAN相关联,所有边缘IP前缀都可以放入一个/22子网中,然后以与DNS域名管理一致的方式对该子网进行分区。例如,域名是通过将设备(Device) 名(见下文)的第一个<devname>组件与此后缀组合生成的。以10.0.0.0/22为例,有4个边缘前缀,目的如下:
ADMIN前缀为 10.0.0.0/25(用于IPMI)有管理服务器和管理交换机 分配给ADMIN的VLAN为1 域名设置为 admin.<deployment>.<site>.aetherproject.net
MGMT前缀为 10.0.0.128/25(用于基础设施控制平面)有服务器管理平面、交换机管理平面 分配给MGMT的VLAN为800 域名设置为 mgmt.<deployment>.<site>.aetherproject.net
FABRIC前缀 10.0.1.0/25(用于基础设施数据平面)计算节点到Fabric交换机以及其他Fabric连接的设备(例如,eNB) 的qsfp0端口的IP地址分配给FABRIC的VLAN为801 域名设置为 fab1.<deployment>.<site>.aetherproject.net
FABRIC前缀 10.0.1.128/25(用于基础设施数据平面)计算节点到fabric交换机的 qsfp1口IP地址分配给FABRIC的VLAN为801 域名设置为 fab2.<deployment>.<site>.aetherproject.net
Kubernetes还使用其他不需要在NetBox中创建的边缘前缀。注意,本例中的qsfp0和qsfp1表示连接交换fabric的收发器端口,其中QSFP表示Quad(4通道) Small Form-factor Pluggable。
记录了站点范围内的信息后,下一步是安装并记录每个设备(Device) 。包括输入<devname>,随后用于为设备生成完全合格的域名: <devname>.<deployment>.<site>.aetherproject.net。创建设备时还需要填写以下字段:
Site Rack & Rack Position Manufacturer Model Serial number Device Type MAC Addresses
注意,通常有一个主接口和一个管理接口(例如BMC/IPMI)。Netbox的一个便利特性是使用设备类型(Device Type) 作为模板,设置接口、电源连接和其他设备型号特定属性的默认命名。
最后,必须指定Device的虚拟接口,并将其Label字段设置为分配给它的物理网络接口。然后将IP地址分配给我们定义的物理和虚拟接口。管理服务器应该总是用每个前缀中的第一个IP地址,按照约定,按如下方式递增分配:
管理服务器(Management Server) eno1- 站点提供的公网IP地址,如果由DHCP提供则为空eno2- 10.0.0.1/25 (ADMIN的第一个),设置为主IPbmc- 10.0.0.2/25 (ADMIN的下一个)mgmt800- 10.0.0.129/25 (MGMT的第一个,在VLAN 800上)fab801- 10.0.1.1/25 (FABRIC的第一个,在VLAN 801上)
管理交换机(Management Switch) gbe1- 10.0.0.3/25 (ADMIN的下一个),设置为主IP
Fabric交换机 eth0- 10.0.0.130/25 (MGMT的下一个),设置为主IPbmc- 10.0.0.131/25
计算服务器(Compute Server) eth0- 10.0.0.132/25 (MGMT的下一个),设置为主IPbmc- 10.0.0.4/25 (ADMIN的下一个)qsfp0- 10.0.1.2/25 (FABRIC的下一个)qsfp1- 10.0.1.3/25
其他Fabric设备(eNB等) eth0或其他主接口 - 10.0.1.4/25 (FABRIC的下一个)
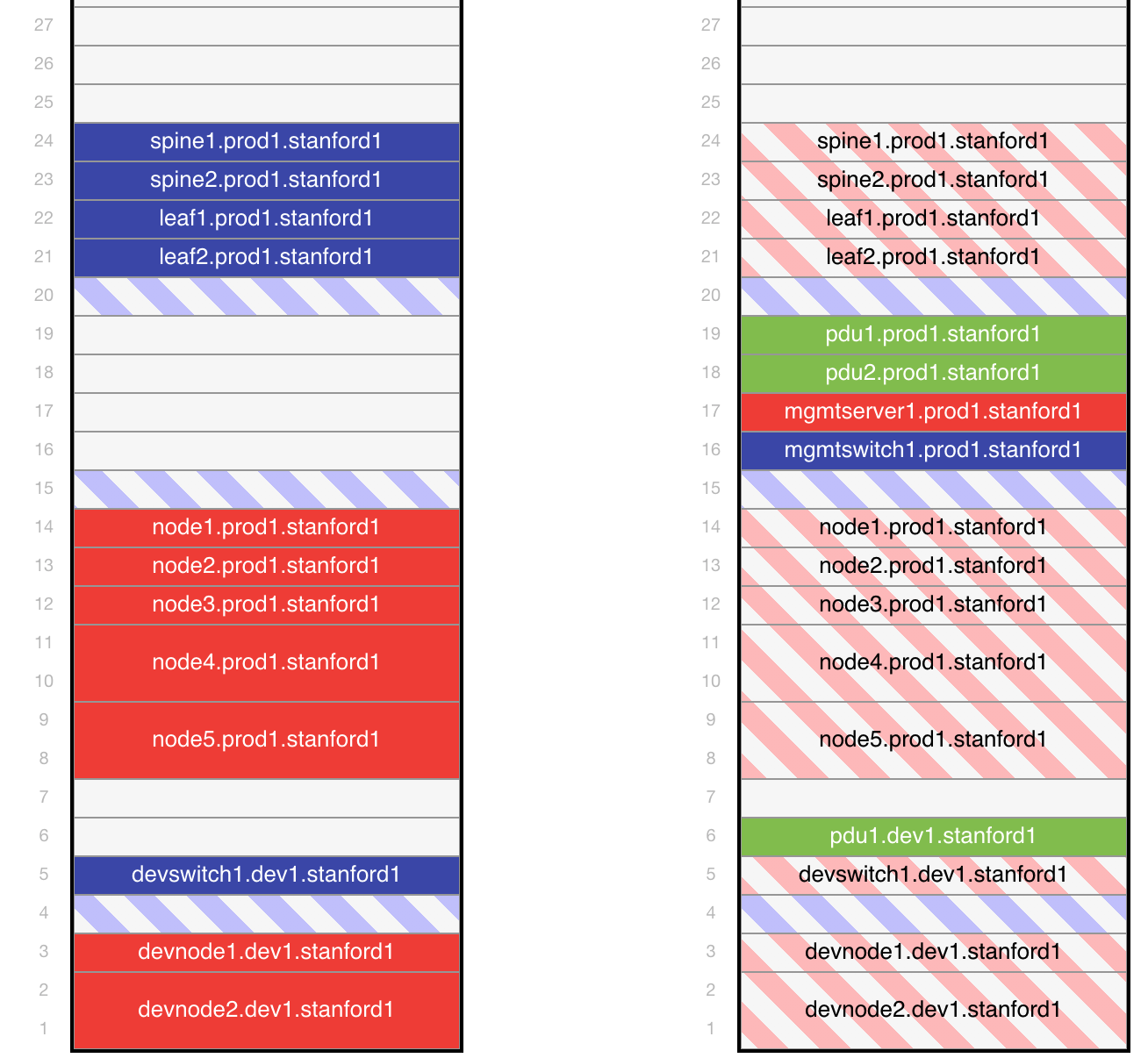
一旦该数据输入到NetBox中,就可以用来生成如图13所示的机架图,对应于图12所示的布线图。请注意,图中显示了位于同一物理机架中的两个逻辑部署(Production和Development)。
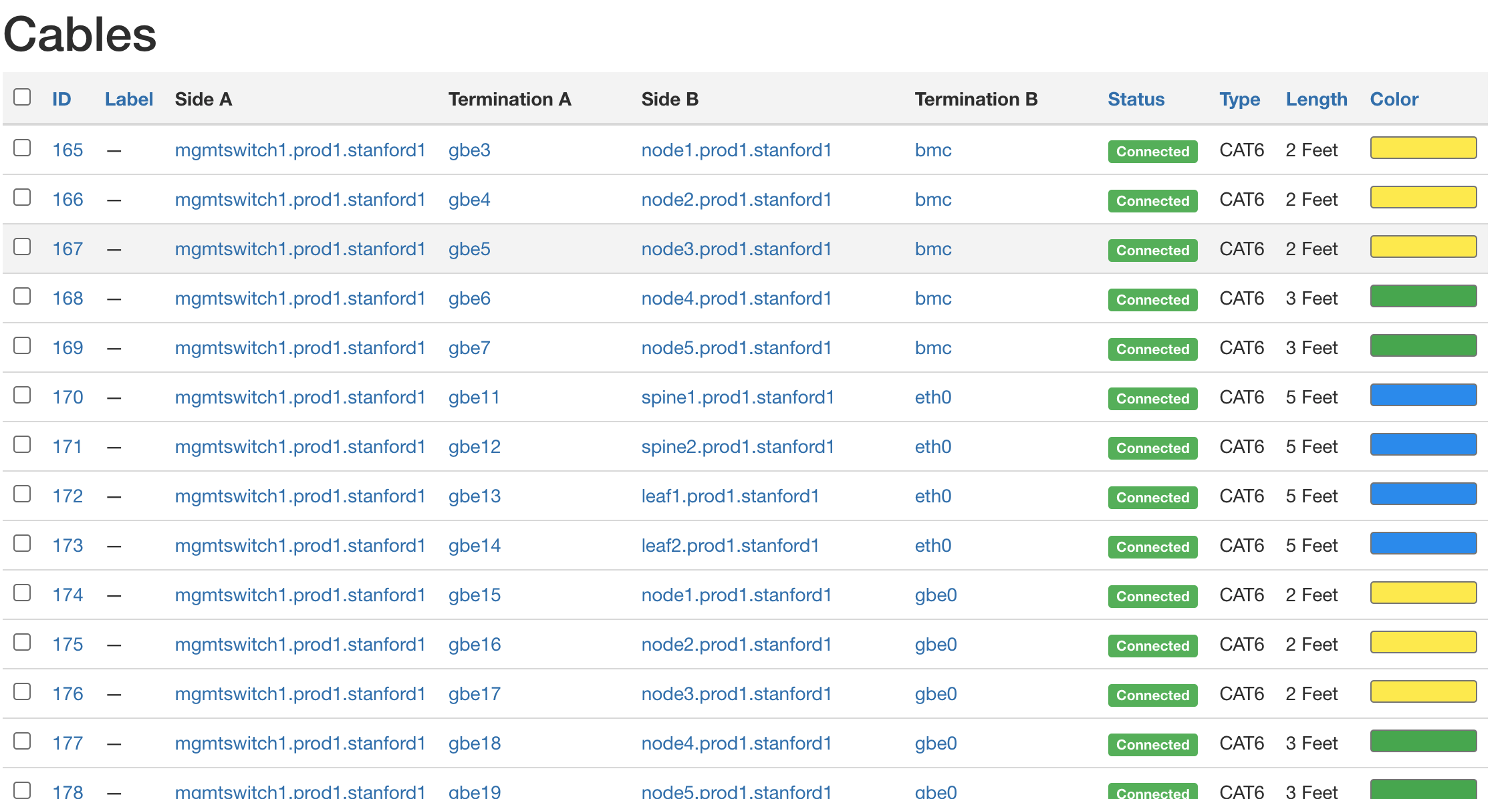
还可以为部署生成其他有用的指标,帮助技术人员确认所记录的逻辑指标是否与实际物理表示相匹配。例如,图14显示了一组电缆,以及如何在我们的示例部署中连接硬件。
如果你觉得这些细节看起来过于冗长乏味,那你就了解到本节的要点了。云控制和管理自动化的一切都依赖于拥有相关资源的完整准确的数据,保持这些信息与物理基础设施的现实同步通常是此过程中最薄弱的环节。唯一可取之处是信息是高度结构化的,像NetBox这样的工具可以帮助我们维护这种结构。
3.1.2 配置和启动
在安装硬件并记录有关安装的相关事实之后,下一步是配置和引导硬件,以便为接下来的自动化过程做好准备。我们的目标是最小化图12所示物理基础设施所需的手动配置,但是零接触(zero-touch) 是一个很高的标准。为了说明这一点,完成示例部署的准备所需的引导步骤目前包括:
配置管理交换机,使其知道正在使用的VLAN集。 配置管理服务器,使其通过额外提供的USB密钥启动。 运行必要的Ansible角色和剧本,在管理服务器上完成配置。 配置计算服务器,从管理服务器(通过iPXE)启动。 配置Fabric交换机,从管理服务器(通过Nginx)启动。 配置eNB(移动基站),使它们知道自己的IP地址。
这些都是手动配置步骤,需要控制台访问或将信息输入到设备web界面,这样任何后续配置步骤都可以完全灵活的自动化完成。请注意,虽然这些步骤不能自动完成,但也不一定必须现场执行,可以提前将准备发送到远程站点的硬件准备好。还要注意的是,不要使用可以稍后完成的配置来覆盖这一步骤。例如,在物理安装eNB时,可以在eNB上设置各种无线电参数,不过一旦集群联机,这些参数将通过管理平台进行设置。
应该尽量减少在这个阶段所做的手动配置工作,大多数系统应该使用自动化的配置方法。例如,广泛使用DHCP和MAC预留来分配IP地址,而不是手工配置每个接口,从而允许管理零接触,并简化未来的重配置。
配置的自动化方面被实现为一组Ansible角色(role) 和剧本(playbook) ,按照第二章图6所示高层概要,对应于代表"零接触配置(系统)"的方框。换句话说,我们没有现成的ZTP解决方案可以使用(也就是说,必须有人编写剧本),但是通过访问NetBox维护的所有配置参数,可以大大简化这一问题。
总体思路如下。对于每个需要配置的网络服务(如DNS, DHCP, iPXE, Nginx)和每个设备子系统(如网络接口,Docker),都有对应的Ansible角色和剧本[2]。一旦管理网络联机,上面总结的各阶段手动配置就将被应用于管理服务器。
[2] 我们将忽略Ansible中角色(role) 和剧本(playbook) 之间的区别,而将重点放在脚本(script) 这一概念上,并通过一组输入参数运行这个脚本。
Ansible剧本在管理服务器上安装和配置网络服务。DNS和DHCP的作用显而易见。至于iPXE和Nginx,它们被用来引导其余的基础设施。计算服务器通过DHCP/TFTP方式下发iPXE配置,然后在Nginx web服务器上加载脚本安装操作系统。fabric交换机从Nginx加载Stratum OS包。
在大部分情况下,剧本将使用从NetBox提取的参数,例如VLAN、IP地址、DNS名称等。图15说明了这种方法,并填充了一些细节。例如,一个自制的Python程序(edgeconfig.py)使用REST API从NetBox提取数据,并输出一组相应的YAML文件,精心制作成Ansible的输入,这在管理和计算系统上创建了更多的配置。其中一个例子是Netplan文件,它在Ubuntu中用于管理网络接口。关于Ansible和Netplan的更多信息可以在它们各自的网站上找到。
延伸阅读:
Ansible[3]: Automation Platform.
Netplan[4]: Network Configuration Abstraction Renderer.
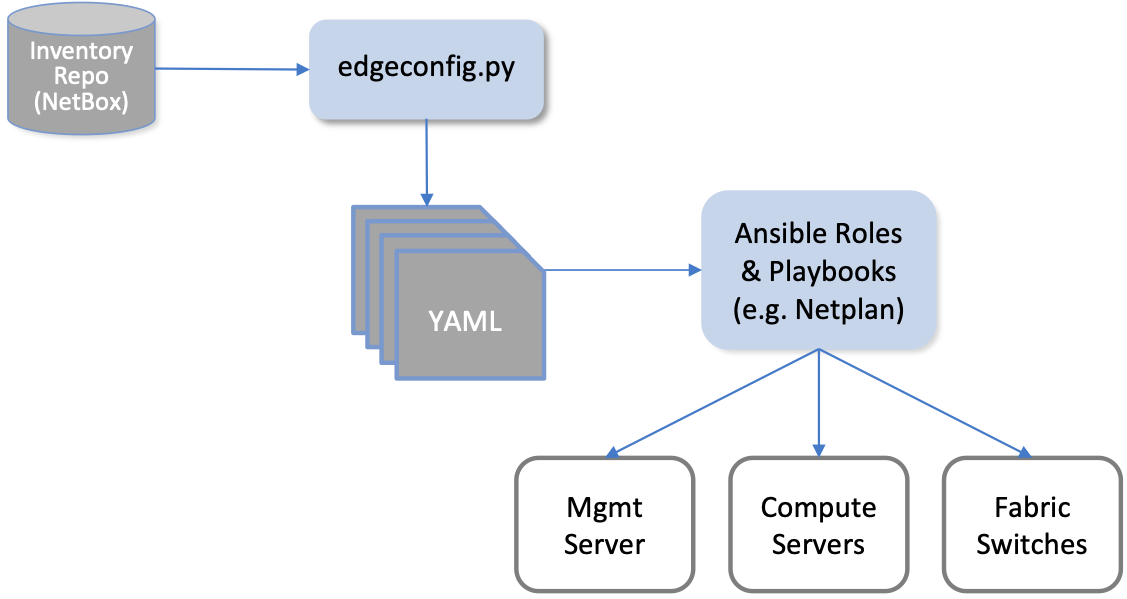
虽然图15强调了Ansible是如何与Netplan配对来配置内核级细节的,但也有一个Ansible剧本用于在每个计算服务器和fabric交换机上安装Docker,然后启动Docker容器,运行"finalize"镜像。该镜像调用配置栈的下一层,有效表明集群正在运行并准备好接受进一步指令。现在我们准备介绍这一层。
3.1.3 Provisioning API
到目前为止,根据我们所介绍的步骤,可以假设每个服务器和交换机都已启动并运行,但是仍然需要做一些工作为配置栈中的下一层准备裸金属集群,本质上是在图11所示的混合云的左右两边之间建立对应关系。如果你问自己"谷歌会怎么做?"这就减少了为裸金属边缘云设置类似GCP API的任务。这个API主要包含了Kubernetes API,但不仅提供了使用Kubernetes的方法,还包括了管理Kubernetes的调用。
简而言之,这个"管理Kubernetes"的任务就是把一组相互连接的服务器和交换机变成一个完全实例化的Kubernetes集群。对于初学者来说,API需要提供一种在每个物理集群上安装和配置Kubernetes的方法,包括指定运行哪个版本的Kubernetes,选择正确的容器网络接口(CNI)插件(虚拟网络适配器)组合,以及将Kubernetes连接到本地网络(以及可能需要的任何VPN)。这一层还需要提供一种方法来设置访问和使用每个Kubernetes集群的帐户(和相关凭据),以及管理部署在给定集群上的独立项目的方法(例如为多个应用程序管理名称空间)。
例如,Aether目前使用Rancher管理裸金属集群上的Kubernetes, Rancher的一个集中化实例负责管理所有边缘站点。这将产生如图16所示的配置,为了强调Rancher的范围,显示了多个边缘集群。虽然图中没有显示,但GCP提供的API,就像Rancher一样,也跨越了多个物理站点(例如,us-west1-a,europe-north1-b,asia-south2-c,等等)。

最后需要指出的是,虽然我们经常把Kubernetes当作全行业标准来对待,但事实并非如此,每个云供应商都提供自己的定制版本:
Microsoft Azure提供了Azure Kubernetes Service (AKS) AWS提供了Amazon Elastic Kubernetes Service (EKS) Google Cloud提供了Google Kubernetes Engine (GKE) Aether边缘云运行Rancher认证的Kubernetes版本 (RKE)
虽然CNCF(云原生计算基金会,负责管理Kubernetes项目的开源组织)对这些版本和其他版本的Kubernetes进行了认证,但这只是建立了一致性基线。每个版本都可以在此基础上进行改进,这些改进通常以附加特性的形式提供并控制Kubernetes集群。我们在云管理层的工作是为运营商提供一种管理这种异构性的方法。正如我们将在第3.2节中看到的,这是基础设施即代码层解决的主要挑战。
3.1.4 配置虚拟机
通过考虑提供虚拟机(VM)的含义,我们结束了对配置物理机所需步骤的讨论。当我们向AKS、EKS或GKE请求Kubernetes集群时,这是"幕后"发生的事情,因为超大规模云服务商可以选择将Kubernetes服务分层放在他们的基础设施即服务(IaaS)之上。我们正在构建的边缘云也需要类似的东西吗?
不一定。因为我们的目标是支持一组精心策划的边缘服务,为企业用户提供价值,而不是支持不受信任的第三方启动他们想要的任何应用程序的容器即服务(Container-as-a-Service),所以不需要"作为服务"来管理VM。但是,我们仍然可能希望使用VM作为一种将Kubernetes的工作负载隔离在有限数量的物理服务器上的方法。这可以作为配置的一个步骤,类似于连接和引导物理机,但使用KVM和Proxmox等虚拟化机制来完成,而不需要类似OpenStack这样成熟的IaaS机制。然后,这些VM将被记录为NetBox和本节介绍的其他工具中的一级云资源,与物理机器没有区别。
考虑到Kubernetes允许我们在单个集群上部署多个应用程序,为什么要这样做呢?这个问题没有固定答案。一个原因是支持细粒度的资源隔离,从而可以(a)确保每个Kubernetes应用能够获取完成工作所需的处理器、内存和存储资源,(b)减少应用程序之间的信息泄露风险。例如,假设除了SD-Fabric、SD-RAN和SD-Core工作负载(默认情况下)运行在每个边缘站点之外,我们还想运行一个或多个其他边缘应用,比如在2.3节中介绍的OpenVINO平台。为了确保这些应用程序之间不存在干扰,可以为每个应用专门部署一个物理服务器子集。物理分区是共享物理集群的粗粒度方法。通过实例化VM,能够在多个应用之间"分割"一个或多个服务器,这为运维人员分配资源提供了更大的灵活性,通常意味着更少的总体资源需求。请注意,还有其他方法可以指定如何在应用程序之间共享集群资源(我们将在第4.4节中看到),但是配置(provisioning)层是可以解决这个问题的一个选项。
3.2 基础设施即代码(Infrastructure-as-Code)
刚刚介绍的Kubernetes配置接口包含可编程API、命令行接口(CLI)和图形用户界面(GUI)。如果你尝试了本书推荐的任何教程,可能会使用后两种教程中的一种。然而,对于运维部署来说,让运维人员与CLI或GUI交互是有问题的,不仅因为人类容易出错,还因为几乎不可能始终如一地重复一系列配置步骤。能够持续重复这个过程是下一章所介绍的生命周期管理的核心。
解决方案是以声明式语法定义基础架构,包含需要实例化的Kubernetes集群信息(例如,一部分运行在裸金属上的边缘集群,一部分在GCP中实例化),以及相关配置信息,然后自动化调用可编程API。这是"基础设施即代码"的本质,正如前面说的,我们使用Terraform作为开源示例。
由于Terraform规范是声明式的,所以理解的最佳方法是浏览特定示例。这样做的目的不是记录Terraform(对更详细的内容感兴趣的人可以使用在线文档和循序渐进的教程),而是建立关于该层在管理云方面所扮演角色的直觉。
延伸阅读:
Terraform Documentation.
Terraform Getting Started Tutorials.
为了理解示例,关于Terraform配置语言,其主要内容在于提供了一种方法(1)为不同类型的资源指定模板(这些是.tf文件),(2)为这些资源模板的特定实例填充变量(这些是.tfvars文件)。然后给定一组.tf和.tfvars文件,Terraform实现两阶段过程。第一阶段,基于执行的前一个计划以来发生的变化构建执行计划。第二阶段,Terraform执行一系列任务,使底层基础设施符合最新定义的规格说明。请注意,目前我们的工作是编写这些规格文件,并将它们签入配置存储库(Config Repo)。在第4章中,Terraform将作为CI/CD流水线的一部分被调用。
现在来看具体的文件。在最上层,运维人员定义了计划合并到基础设施中的供应商(provider) 集合。我们可以认为每个供应商对应于一个云后端,提供了图16中介绍的相应配置API。在我们的示例中,只展示两个供应商: Rancher管理的边缘集群和GCP管理的集中式集群。注意,示例文件为每个供应商声明了一组相关变量(例如url、access-key),这些变量由下面介绍的特定实例的变量文件"填充"。
terraform {
required_version = ">= 0.13"
required_providers {
rancher2 = {
source = "rancher/rancher2"
version = "= 1.15.1"
}
google = {
source = "hashicorp/google"
version = "~> 3.65.0"
}
null = {
source = "hashicorp/null"
version = "~> 2.1.2"
}
}
}
variable "rancher" {
description = "Rancher credential"
type = object({
url = string
access_key = string
secret_key = string
})
}
variable "gcp_config" {
description = "GCP project and network configuration"
type = object({
region = string
compute_project = string
network_project = string
network_name = string
subnet_name = string
})
}
provider "rancher2" {
api_url = var.rancher.url
access_key = var.rancher.access_key
secret_key = var.rancher.secret_key
}
provider "google" {
# Provide GCP credential using GOOGLE_CREDENTIALS environment variable
project = var.gcp_config.compute_project
region = var.gcp_config.region
}
下一步是为我们希望配置的实际集群集填充详细信息(定义值)。让我们来看两个示例,对应于刚才指定的两个供应商。第一个显示了由GCP托管的集群(名为amp-gcp),托管AMP工作负载。(类似的有一个sdcore-gcp托管SD-Core实例。)Terraform通过给特定集群分配相关标签(例如,env = "production")和管理堆栈的其他层(根据相关标签有选择的采取不同的操作)之间建立联系,我们将在第4.4节中看到使用这些标签的示例。
cluster_name = "amp-gcp"
cluster_nodes = {
amp-us-west2-a = {
host = "10.168.0.18"
roles = ["etcd", "controlplane", "worker"]
labels = []
taints = []
},
amp-us-west2-b = {
host = "10.168.0.17"
roles = ["etcd", "controlplane", "worker"]
labels = []
taints = []
},
amp-us-west2-c = {
host = "10.168.0.250"
roles = ["etcd", "controlplane", "worker"]
labels = []
taints = []
}
}
cluster_labels = {
env = "production"
clusterInfra = "gcp"
clusterRole = "amp"
k8s = "self-managed"
backup = "enabled"
}
第二个示例展示了一个在Site X上实例化的边缘集群(名为ace-X)。在示例代码中可以看到,这是一个由5个服务器和4个交换机(两个叶交换机和两个脊交换机)组成的裸金属集群。每个设备的地址必须与3.1节中介绍的硬件配置阶段分配的地址相匹配。理想情况下,该节中介绍的NetBox(以及相关的)工具链将自动生成Terraform变量文件,但在实践中,通常仍然需要手动输入数据。
cluster_name = "ace-X"
cluster_nodes = {
leaf1 = {
user = "terraform"
private_key = "~/.ssh/id_rsa_terraform"
host = "10.64.10.133"
roles = ["worker"]
labels = ["node-role.aetherproject.org=switch"]
taints = ["node-role.aetherproject.org=switch:NoSchedule"]
},
leaf2 = {
user = "terraform"
private_key = "~/.ssh/id_rsa_terraform"
host = "10.64.10.137"
roles = ["worker"]
labels = ["node-role.aetherproject.org=switch"]
taints = ["node-role.aetherproject.org=switch:NoSchedule"]
},
spine1 = {
user = "terraform"
private_key = "~/.ssh/id_rsa_terraform"
host = "10.64.10.131"
roles = ["worker"]
labels = ["node-role.aetherproject.org=switch"]
taints = ["node-role.aetherproject.org=switch:NoSchedule"]
},
spine2 = {
user = "terraform"
private_key = "~/.ssh/id_rsa_terraform"
host = "10.64.10.135"
roles = ["worker"]
labels = ["node-role.aetherproject.org=switch"]
taints = ["node-role.aetherproject.org=switch:NoSchedule"]
},
server-1 = {
user = "terraform"
private_key = "~/.ssh/id_rsa_terraform"
host = "10.64.10.138"
roles = ["etcd", "controlplane", "worker"]
labels = []
taints = []
},
server-2 = {
user = "terraform"
private_key = "~/.ssh/id_rsa_terraform"
host = "10.64.10.139"
roles = ["etcd", "controlplane", "worker"]
labels = []
taints = []
},
server-3 = {
user = "terraform"
private_key = "~/.ssh/id_rsa_terraform"
host = "10.64.10.140"
roles = ["etcd", "controlplane", "worker"]
labels = []
taints = []
},
server-4 = {
user = "terraform"
private_key = "~/.ssh/id_rsa_terraform"
host = "10.64.10.141"
roles = ["worker"]
labels = []
taints = []
},
server-5 = {
user = "terraform"
private_key = "~/.ssh/id_rsa_terraform"
host = "10.64.10.142"
roles = ["worker"]
labels = []
taints = []
}
}
cluster_labels = {
env = "production"
clusterInfra = "bare-metal"
clusterRole = "ace"
k8s = "self-managed"
coreType = "4g"
upfType = "up4"
}
最后一块拼图是填写关于如何实例化每个Kubernetes集群的其余细节。本例中,我们只展示用于配置边缘集群的特定于RKE模块,如果你理解Kubernetes,那么其中大部分细节都很简单。例如,该模块指定每个边缘集群应该加载calico和multus CNI插件,还定义了如何调用kubectl根据这些规范配置Kubernetes。也许对SCTPSupport的引用会比较陌生,这表明特定的Kubernetes集群是否需要支持SCTP, SCTP是一种面向电信的网络协议,并不包含在普通Kubernetes部署中,但SD-Core需要。
terraform {
required_providers {
rancher2 = {
source = "rancher/rancher2"
}
null = {
source = "hashicorp/null"
version = "~> 2.1.2"
}
}
}
resource "rancher2_cluster" "cluster" {
name = var.cluster_config.cluster_name
enable_cluster_monitoring = false
enable_cluster_alerting = false
labels = var.cluster_labels
rke_config {
kubernetes_version = var.cluster_config.k8s_version
authentication {
strategy = "x509"
}
monitoring {
provider = "none"
}
network {
plugin = "calico"
}
services {
etcd {
backup_config {
enabled = true
interval_hours = 6
retention = 30
}
retention = "72h"
snapshot = false
}
kube_api {
service_cluster_ip_range = var.cluster_config.k8s_cluster_ip_range
extra_args = {
feature-gates = "SCTPSupport=True"
}
}
kubelet {
cluster_domain = var.cluster_config.cluster_domain
cluster_dns_server = var.cluster_config.kube_dns_cluster_ip
fail_swap_on = false
extra_args = {
cpu-manager-policy = "static"
kube-reserved = "cpu=500m,memory=256Mi"
system-reserved = "cpu=500m,memory=256Mi"
feature-gates = "SCTPSupport=True"
}
}
kube_controller {
cluster_cidr = var.cluster_config.k8s_pod_range
service_cluster_ip_range = var.cluster_config.k8s_cluster_ip_range
extra_args = {
feature-gates = "SCTPSupport=True"
}
}
scheduler {
extra_args = {
feature-gates = "SCTPSupport=True"
}
}
kubeproxy {
extra_args = {
feature-gates = "SCTPSupport=True"
proxy-mode = "ipvs"
}
}
}
addons_include = ["https://raw.githubusercontent.com/k8snetworkplumbingwg/multus-cni/release-3.7/images/multus-daemonset.yml"]
addons = var.addon_manifests
}
}
resource "null_resource" "nodes" {
triggers = {
cluster_nodes = length(var.nodes)
}
for_each = var.nodes
connection {
type = "ssh"
bastion_host = var.bastion_host
bastion_private_key = file(var.bastion_private_key)
bastion_user = var.bastion_user
user = each.value.user
host = each.value.host
private_key = file(each.value.private_key)
}
provisioner "remote-exec" {
inline = [<<EOT
${rancher2_cluster.cluster.cluster_registration_token[0].node_command} \
${join(" ", formatlist("--%s", each.value.roles))} \
${join(" ", formatlist("--taints %s", each.value.taints))} \
${join(" ", formatlist("--label %s", each.value.labels))}
EOT
]
}
}
resource "rancher2_cluster_sync" "cluster-wait" {
cluster_id = rancher2_cluster.cluster.id
provisioner "local-exec" {
command = <<EOT
kubectl set env daemonset/calico-node \
--server ${yamldecode(rancher2_cluster.cluster.kube_config).clusters[0].cluster.server} \
--token ${yamldecode(rancher2_cluster.cluster.kube_config).users[0].user.token} \
--namespace kube-system \
IP_AUTODETECTION_METHOD=${var.cluster_config.calico_ip_detect_method}
EOT
}
}
还有其他一些松耦合端点需要绑定,例如定义用于连接边缘集群到GCP中对应节点的VPN,但是上面示例足以说明基础设施即代码在云管理堆栈中所扮演的角色。关键是Terraform处理的所有事情都可以由人工运维人员在后端配置API上通过一系列CLI命令(或GUI点击)来完成,但经验表明,这种方法容易出错,而且难以重复。从声明式语言开始并自动生成正确的API调用序列是克服这个问题的一种经过验证的方法。
最后请注意这样一个事实: 虽然我们现在为云基础设施定义了一个声明性规范,我们称之为Aether平台,但这些规范文件是我们在配置存储库中签入的一个软件工件。这就是我们所说的"基础架构即代码": 基础架构规范被签入到存储库中,并像任何其他代码一样接受版本控制。这个存储库反过来为下一章介绍的生命周期管理流水线提供了输入。3.1节中介绍的物理配置步骤发生在流水线的"外部"(这就是为什么我们不只是将资源配置加入生命周期管理),但将资源配置看作生命周期管理的"阶段0"是比较公平的定义。
3.3 平台定义
定义系统架构(在我们的例子中是混合云的管理框架)的艺术在于决定在平台中包含什么以及在平台上运行的应用程序之间划清界限。对于Aether,我们决定在平台中包含SD-Fabric(以及Kubernetes),而SD-Core和SD-RAN被视为应用程序,尽管这三者都是作为基于Kubernetes的微服务实现的。这个决定的后果是SD-Fabric被初始化为本章介绍的配置系统的一部分(与NetBox、Ansible、Rancher和Terraform扮演角色共同完成),而SD-Core和SD-RAN是基于第4章介绍的应用级机制部署。
可能还有其他边缘应用作为Kubernetes工作负载运行,这使情况变得更加复杂,因为从他们的角度来看,所有Aether组件(包括SD-Core和SD-RAN实现的5G连接)都假定是平台的一部分。换句话说,Aether划了两条线,一条划分了Aether基础平台(Kubernetes加上SD-Fabric),另一条划分了Aether PaaS(包括运行在平台上的SD-Core和SD-RAN,加上管理整个系统的AMP)。"基础平台"和"PaaS"之间的区别很细微,但本质上分别对应于软件堆栈和托管服务。
从某些方面来说,这只是一个术语问题,当然也很重要,不过与我们的讨论相关的是,由于有多个重叠机制,因此我们有不止一种方法来解决遇到的每个工程问题,从而很容易对可分离关注点实现不必要的合并而结束。明确、一致的界定什么是平台、什么是应用是健全的整体设计的先决条件。同样重要的是要认识到内部工程决策(例如,使用什么机制来部署给定组件)和外部可见的体系架构决策(例如,通过公共API公开什么功能)之间的区别。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。
微信公众号:DeepNoMind
参考资料
Edge Cloud Operations: A Systems Approach: https://ops.systemsapproach.org
[2]NetBox: https://docs.netbox.dev
[3]Ansible: https://www.ansible.com
[4]Netplan: https://netplan.io
边栏推荐
猜你喜欢

【软件工程之美 - 专栏笔记】31 | 软件测试要为产品质量负责吗?

从离线到实时对客,湖仓一体释放全量数据价值
ENS 表情包域名火了!是炒作还是机遇?
如何解决gedit 深色模式下高亮文本不可见?

MySQL_关于JSON数据的查询
Difference Between Concurrency and Parallelism
Flink_CDC搭建及简单使用

银行数据资产转换能力弱?思迈特软件助力解决银行困境

MySQL的Replace用法详解

【考研词汇训练营】Day18 —— amount,max,consider,account,actual,eliminate,letter,significant,embarrass,collapse
随机推荐
MySQL (2)
推荐系统:冷启动问题【用户冷启动、物品冷启动、系统冷启动】
想要写出好的测试用例,先要学会测试设计
[Ask] SQL statement to calculate the sum of column 2 by deduplicating column 1?
MySQL_关于JSON数据的查询
无法正常访问服务器
Mysql 回表
使用map函数,对list中的每个元素进行操作 好像不用map
Mysql索引特性(重要)
肖特基二极管厂家ASEMI带你认识电路中的三大重要元器件
6.3有定型性 第七章
Recommendation System - Sorting Layer: Sorting Layer Architecture [User and Item Feature Processing Steps]
从离线到实时对客,湖仓一体释放全量数据价值
TensorFlow2: Overview
MySQL 多表关联一对多查询实现取最新一条数据
@RequestParam使用
chrome扩展:如何使对话框位于当前窗口的右侧?
微信读书,导出笔记
如何优化OpenSumi终端性能?
PR视频剪辑软件教程