当前位置:网站首页>Reading the paper [learning to discretely compose reasoning module networks for video captioning]
Reading the paper [learning to discretely compose reasoning module networks for video captioning]
2022-07-01 19:24:00 【hei_ hei_ hei_】
Learning to Discretely Compose Reasoning Module Networks for Video Captioning
1. Summary
- publish :IJCAI 2020
- Code :https://github.com/tgc1997/RMN
- idea: The author believes that the generation of video description is step-by-step Of . For the generation of a sentence , First, we need to locate and describe the subject subject, Then reasoning action , Then locate and describe the object object. And such a process , The author believes that it requires complex spatiotemporal reasoning . For reasoning modules , The author designs three modules locate,relate,func, Respectively used to locate the target (2D), Reasoning relationship (3D) And the generation of some conjunctions ( Such as a、the、and); For the selection module , The author designed Module Selector It is used to select one of the above modules when generating the next word .
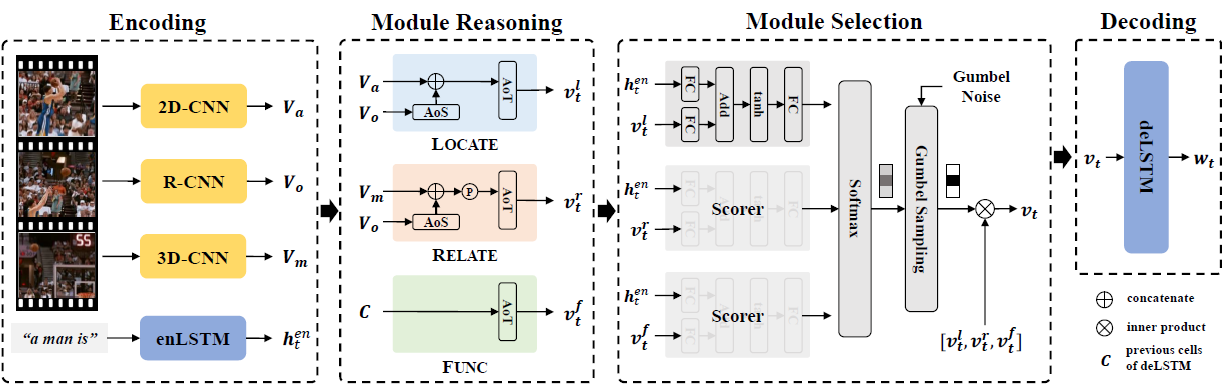
2. Detailed design
2.1 Encoder
- feature extraction : Separate use 2D-CNN, 3D-CNN, R-CNN Extracted video appearance feature V a V_a Va, motion feature V m V_m Vm,object feature V o V_o Vo. Notice the V o V_o Vo With location information ( It's reflected in the code )
- Feature handling : about V a V_a Va and V m V_m Vm, The author has used Bi-LATMs Processing to incorporate temporal information into features .
- Guidance for the entire network h t e n h_t^{en} hten:LSTM The hidden layer output of . Input is global visual information v ˉ \bar v vˉ, Last one step Of the last word generated embedding And hidden layer state

2.2 Reasoning Modules
All reasoning modules are based on the following attention Calculation (Neural machine translation by jointly learning to align and translate.ICLR 2015)
Defined in this way attention You can follow the specified latitude , In order to better model the direction of space and time , The author defines... In time latitude and space latitude respectively attention: A o S ( ⋅ ) AoS(\cdot) AoS(⋅) and A o T ( ⋅ ) AoT(\cdot) AoT(⋅)
- Locate Module
Mainly for the generation of object words, Such as “man”、“basketball” etc. . Modules need to pay attention in time and space region Information , Therefore, the author will first V o V_o Vo Send in A o S ( ⋅ ) AoS(\cdot) AoS(⋅), And then with V a V_a Va Send together A o T ( ⋅ ) AoT(\cdot) AoT(⋅)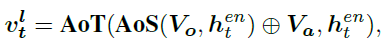
there ⨁ \bigoplus ⨁ Express concate operation - Relate Module
Mainly to generate verbs , for example “shoting”、“riding” etc. . In the picture shown below , To generate verbs “shoting”, Models need to be aware of different scenarios object Change of state , So in Relate Module In any pair of spaces attention After processing the V o V_o Vo Paired , Then the execution time attention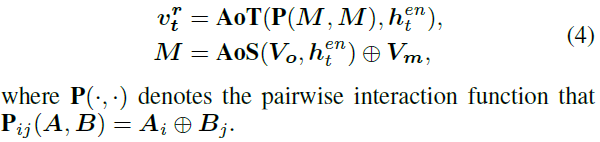
- Func Module
It is mainly to generate some conjunctions to make the whole sentence coherent , Such as “of”,“and” etc. . There is no need for visual information , Only language information is needed , So right. decoder LSTM The history of cell states perform AoT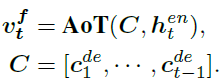
It can be found that these three modules are closely around the first mentioned in this section attention The operation is in progress , take h t e n h_t^{en} hten As attention Of Q.
Module Selector
In the generation module , every last step Generated word It can only be one of the above three modules , Therefore, we need to design a selection module to choose . The specific implementation is to score each module , Then choose the highest score . The scoring function is designed as follows :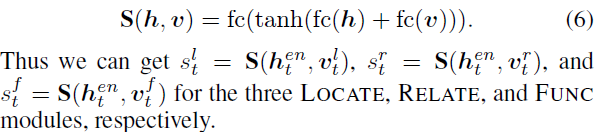
But because of max The function is non differentiable , So the author uses an approximate method to one-hot vector z t z_t zt Convert to continuous values z t ~ \tilde {z_t} zt~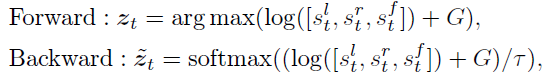
The final result of visual reasoning is :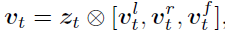
there ⨂ \bigotimes ⨂ Express inner product
Decoder
Used one LSTM decode , Input is the result of visual information v t v_t vt,encoder The hidden layer of 
Then the visual information 、 Hidden layer information follows MLP Output the probability distribution of the corresponding dictionary to get the generated word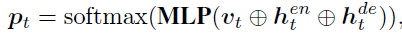
Training
- Caption Loss:cross-entropy loss
Used to measure the accuracy of generated sentences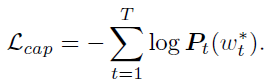
T T T Indicates the length of the sentence - POS Loss:KLD loss
Used to measure the accuracy of the selection module , Specifically, put the sentence POS Convert to one-hot code , And then use KLD(Kullback-Leibler Divergence) loss To measure the similarity of two distributions . The actual implementation in code is also used cross-entropy loss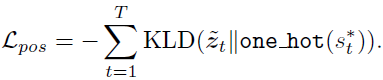
- The final loss

边栏推荐
- Openai video pre training (VPT): action learning based on watching unmarked online videos
- C端梦难做,科大讯飞靠什么撑起10亿用户目标?
- Today, with the popularity of micro services, how does service mesh exist?
- AI training speed breaks Moore's law; Song shuran's team won the RSS 2022 Best Paper Award
- AppGallery Connect场景化开发实战—图片存储分享
- Stanford, salesforce|maskvit: masked vision pre training for video prediction
- Lumiprobe phosphide hexaethylene phosphide specification
- 实现一个Prometheus exporter
- 云服务器ECS夏日省钱秘籍,这次@老用户快来领走
- Supervarimag superconducting magnet system SVM series
猜你喜欢

The intelligent epidemic prevention system provides safety guarantee for the resumption of work and production at the construction site
11. Users, groups, and permissions (1)

More information about M91 fast hall measuring instrument

Chinese and English instructions human soluble advanced glycation end products receptor (sRAGE) ELISA Kit
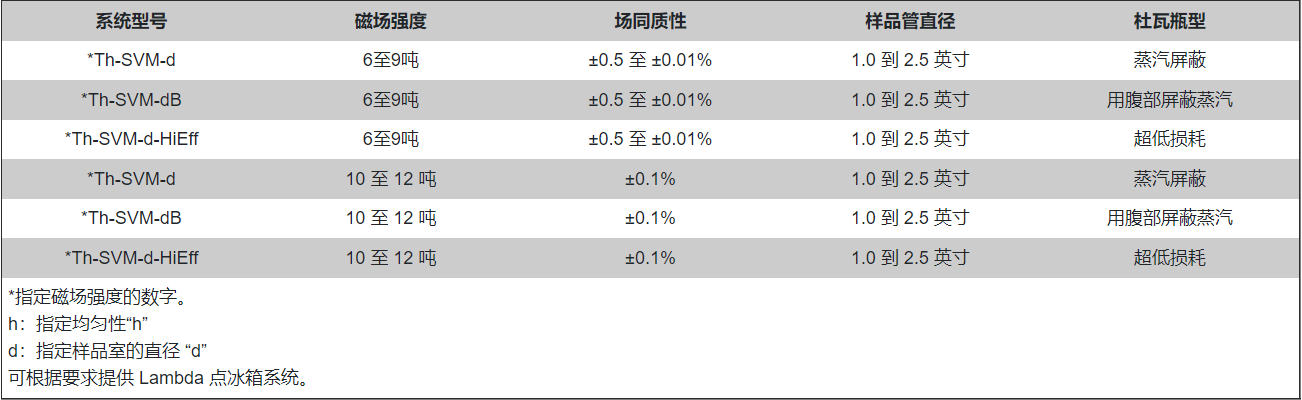
SuperVariMag 超导磁体系统 — SVM 系列
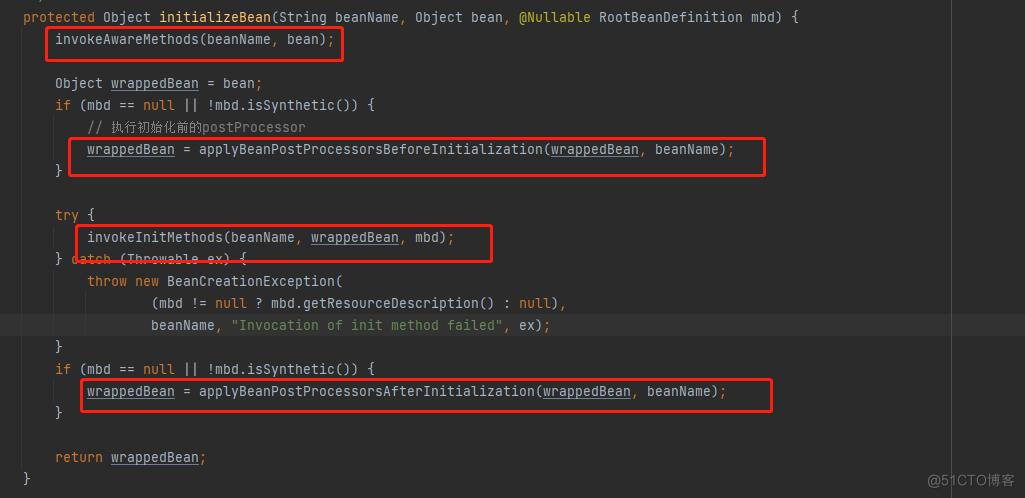
Summary of the core steps in the life cycle of beans

小红书上的爱情买卖
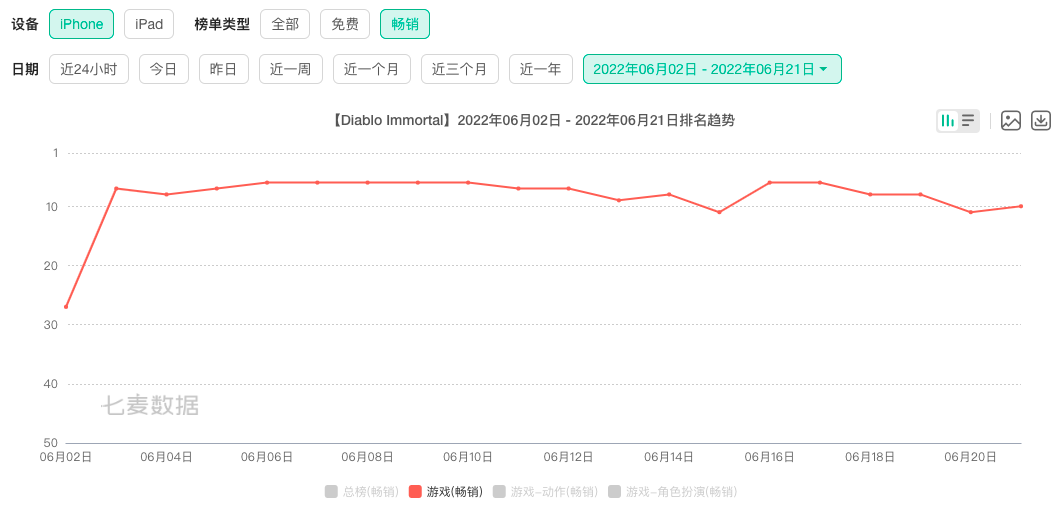
网易游戏,激进出海

The best landing practice of cave state in an Internet ⽹⾦ financial technology enterprise
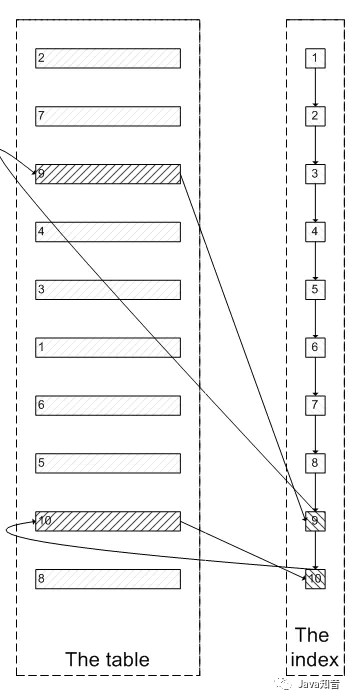
一次SQL优化,数据库查询速度提升 60 倍
随机推荐
indexof和includes的区别
Nacos configuration file publishing failed, please check whether the parameters are correct solution
XML语法、约束
Chinese and English instructions human soluble advanced glycation end products receptor (sRAGE) ELISA Kit
实现一个Prometheus exporter
June issue | antdb database participated in the preparation of the "Database Development Research Report" and appeared on the list of information technology and entrepreneurship industries
Three ways for redis to realize current limiting
组队学习! 14天鸿蒙设备开发“学练考”实战营限时免费加入!
精益思想:来源,支柱,落地。看了这篇文章就懂了
助力数字经济发展,夯实数字人才底座—数字人才大赛在昆成功举办
【AGC】如何解决事件分析数据本地和AGC面板中显示不一致的问题?
Lean thinking: source, pillar, landing. I understand it after reading this article
Huawei cloud experts explain the new features of gaussdb (for MySQL)
Improve yolov5 with gsconv+slim neck to maximize performance!
见证时代!“人玑协同 未来已来”2022弘玑生态伙伴大会开启直播预约
学习笔记【gumbel softmax】
[pytorch record] automatic hybrid accuracy training torch cuda. amp
Digital business cloud: from planning to implementation, how does Minmetals Group quickly build a new pattern of digital development?
Cdga | if you are engaged in the communication industry, you should get a data management certificate
VBA simple macro programming of Excel