当前位置:网站首页>Once the SQL is optimized, the database query speed is increased by 60 times
Once the SQL is optimized, the database query speed is increased by 60 times
2022-07-01 19:13:00 【Java Architect in Penghu】
Introduction
sql Performance optimization can help us optimize data query time , This article mainly introduces 10000w Data in sql After optimization, the query speed is improved 60 Multiple optimization process .
Text
There's a financial statement , Not divided into databases and tables , The current amount of data is 9555695, Paging query uses limit, Query time before optimization 16 s 938 ms (execution: 16 s 831 ms, fetching: 107 ms), Adjust as follows SQL after , Time consuming 347 ms (execution: 163 ms, fetching: 184 ms);
operation :
The query criteria are placed in the subquery , Subqueries only look up primary keys ID, Then use the primary key Association determined in the subquery to query other attribute fields ;
principle :
1、 Reduce the return operation ;
2、 May refer to 《 Alibaba Java Development Manual ( Taishan Edition )》 The fifth chapter -MySQL database 、( Two ) Index specifications 、 The first 7 strip :
【 recommend 】 Use delay association or subquery to optimize the super multi page scenario .
explain :
MySQL I didn't pick it offeset That's ok , It's about taking offset+N That's ok , And then back before giving up offset That's ok , return N That's ok , That's right offset When I was very old , Efficiency is very low , Or control the total number of pages returned , Or for the number of pages over a specific threshold SQL rewrite .
Example :
First, quickly locate what needs to be acquired id paragraph , And then relate :
SELECT a.* FROM surface 1 a,(select id from surface 1 where Conditions LIMIT 100000,20) b where a.id = b.id;
-- Before optimization SQLSELECT Various fields FROM `table_name`WHERE Various conditions LIMIT 0,10;
- After optimization SQLSELECT Various fields FROM `table_name` main_taleRIGHT JOIN (SELECT Subqueries only look up primary keys FROM `table_name`WHERE Various conditions LIMIT 0,10;) temp_table ON temp_table. Primary key = main_table. Primary key
One 、 Preface
Let's start with MySQL Version of :
mysql> select version();+-----------+| version() |+-----------+| 5.7.17 |+-----------+1 row in set (0.00 sec)
Table structure :
mysql> desc test;+--------+---------------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+--------+---------------------+------+-----+---------+----------------+| id | bigint(20) unsigned | NO | PRI | NULL | auto_increment || val | int(10) unsigned | NO | MUL | 0 | || source | int(10) unsigned | NO | | 0 | |+--------+---------------------+------+-----+---------+----------------+3 rows in set (0.00 sec)
id It is an auto increment primary key ,val Is a non unique index .
Pour in a lot of data , common 500 ten thousand :
mysql> select count(*) from test;+----------+| count(*) |+----------+| 5242882 |+----------+1 row in set (4.25 sec)
We know , When limit offset rows Medium offset When a large , There will be efficiency issues :
mysql> select * from test where val=4 limit 300000,5;+---------+-----+--------+| id | val | source |+---------+-----+--------+| 3327622 | 4 | 4 || 3327632 | 4 | 4 || 3327642 | 4 | 4 || 3327652 | 4 | 4 || 3327662 | 4 | 4 |+---------+-----+--------+5 rows in set (15.98 sec)
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;+---------+-----+--------+---------+| id | val | source | id |+---------+-----+--------+---------+| 3327622 | 4 | 4 | 3327622 || 3327632 | 4 | 4 | 3327632 || 3327642 | 4 | 4 | 3327642 || 3327652 | 4 | 4 | 3327652 || 3327662 | 4 | 4 | 3327662 |+---------+-----+--------+---------+5 rows in set (0.38 sec)
In order to achieve the same goal , We usually rewrite it as follows :
The time difference is obvious .
Why did the above result appear ? Let's see select * from test where val=4 limit 300000,5; Query process of :
- Query the index leaf node data .
- According to the primary key value of the leaf node, query all the required field values on the cluster index .
It's similar to the picture below :
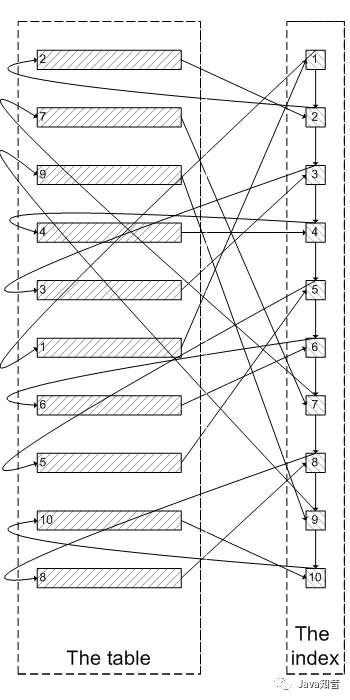
Like above , Need to check 300005 Secondary inode , Inquire about 300005 Data of secondary cluster index , Finally, filter out the results 300000 strip , Take out the last 5 strip .MySQL It takes a lot of randomness I/O On the query cluster index data , But there is 300000 Sub random I/O The query data will not appear in the result set .
Someone must have asked : Since it was indexed in the beginning , Why not follow the index leaf node to find the last needed 5 Nodes , Then query the actual data in the cluster index . It just needs 5 Sub random I/O, Similar to the process shown in the following picture :
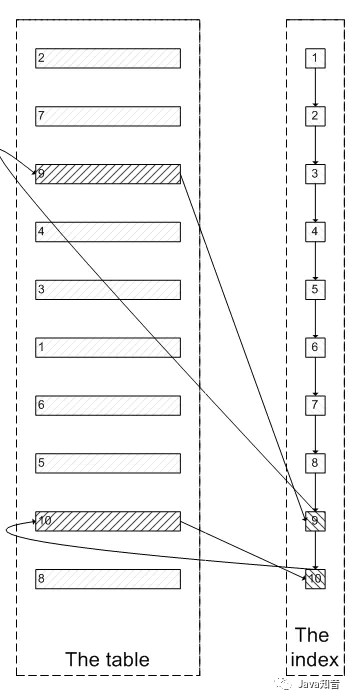
In fact, I also want to ask this question .
confirmed
Now let's take a practical operation to confirm the above inference :
To confirm select * from test where val=4 limit 300000,5 It's a scan 300005 Index nodes and 300005 Data nodes on clustered indexes , We need to know MySQL Is there any way to count in a sql The number of times a data node is queried through an index node in . I tried first Handler_read_* series , Unfortunately, none of the variables can satisfy the condition .
I can only prove it indirectly :
InnoDB There is buffer pool. It contains recently accessed data pages , Including data pages and index pages . So we need to run two sql, To compare buffer pool Number of data pages in . The prediction is to run select * from test a inner join (select id from test where val=4 limit 300000,5); after ,buffer pool The number of data pages in is far less than select * from test where val=4 limit 300000,5; Corresponding quantity , Because of the previous one sql Only visit 5 Secondary data page , The second one sql visit 300005 Secondary data page .
select * from test where val=4 limit 300000,5
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;Empty set (0.04 sec)
It can be seen that , at present buffer pool There's nothing about test Table data page .
mysql> select * from test where val=4 limit 300000,5;+---------+-----+--------+| id | val | source |+---------+-----+--------+| 3327622 | 4 | 4 || 3327632 | 4 | 4 || 3327642 | 4 | 4 || 3327652 | 4 | 4 || 3327662 | 4 | 4 |+---------+-----+--------+5 rows in set (26.19 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;+------------+----------+| index_name | count(*) |+------------+----------+| PRIMARY | 4098 || val | 208 |+------------+----------+2 rows in set (0.04 sec)
It can be seen that , here buffer pool About China test Table has 4098 Data pages ,208 Index pages .
select * from test a inner join (select id from test where val=4 limit 300000,5) ; To prevent the effect of the last test , We need to empty buffer pool, restart mysql.
mysqladmin shutdown/usr/local/bin/mysqld_safe &
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;Empty set (0.03 sec)
function sql:
mysql> select * from test a inner join (select id from test where val=4 limit 300000,5) b on a.id=b.id;+---------+-----+--------+---------+| id | val | source | id |+---------+-----+--------+---------+| 3327622 | 4 | 4 | 3327622 || 3327632 | 4 | 4 | 3327632 || 3327642 | 4 | 4 | 3327642 || 3327652 | 4 | 4 | 3327652 || 3327662 | 4 | 4 | 3327662 |+---------+-----+--------+---------+5 rows in set (0.09 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('val','primary') and TABLE_NAME like '%test%' group by index_name;+------------+----------+| index_name | count(*) |+------------+----------+| PRIMARY | 5 || val | 390 |+------------+----------+2 rows in set (0.03 sec)
We can see clearly the difference between the two : first sql To load the 4098 Data pages to buffer pool, And the second one. sql Only loaded 5 Data pages to buffer pool. In line with our prediction . It also confirms why the first sql Will be slow : Read a lot of useless data rows (300000), Finally, he abandoned .
And it creates a problem : Loaded a lot of hot, not very high data pages to buffer pool, Can cause buffer pool Pollution of , Occupy buffer pool Space .
Problems encountered
To make sure it's cleared every time you restart buffer pool, We need to close innodb_buffer_pool_dump_at_shutdown and innodb_buffer_pool_load_at_startup, These two options control when the database is shut down dump Out buffer pool The data in the database and when the database is opened is loaded on the disk for backup buffer pool The data of .、
边栏推荐
- OpenAI|视频预训练 (VPT):基于观看未标记的在线视频的行动学习
- Halcon image calibration enables subsequent image processing to become the same as the template image
- Prices of Apple products rose across the board in Japan, with iphone13 up 19%
- 数商云:从规划到落地,五矿集团如何快速构建数字化发展新格局?
- GameFramework食用指南
- Clean up system cache and free memory under Linux
- M91快速霍尔测量仪—在更短的时间内进行更好的测量
- kubernetes命令入门(namespaces,pods)
- ETL development of data warehouse (IV)
- SuperVariMag 超导磁体系统 — SVM 系列
猜你喜欢

Leetcode-141 circular linked list
实例讲解将Graph Explorer搬上JupyterLab

Clean up system cache and free memory under Linux

Lumiprobe bifunctional crosslinker sulfo cyanine 5 bis NHS ester

SuperOptiMag 超导磁体系统 — SOM、SOM2 系列

Huawei game failed to initialize init with error code 907135000

ACM MM 2022视频理解挑战赛视频分类赛道冠军AutoX团队技术分享
微服务大行其道的今天,Service Mesh是怎样一种存在?

Love business in Little Red Book
Openai video pre training (VPT): action learning based on watching unmarked online videos
随机推荐
Solution: you can ping others, but others can't ping me
[live broadcast appointment] database obcp certification comprehensive upgrade open class
Go language self-study series | go language data type
Summary of the core steps in the life cycle of beans
机械设备行业数字化供应链集采平台解决方案:优化资源配置,实现降本增效
【AGC】如何解决事件分析数据本地和AGC面板中显示不一致的问题?
Superoptimag superconducting magnet system - SOM, Som2 series
Shell array
Lake Shore—CRX-EM-HF 型低温探针台
Netease games, radical going to sea
[AGC] how to solve the problem that the local display of event analysis data is inconsistent with that in AGC panel?
制造业SRM管理系统供应商全方位闭环管理,实现采购寻源与流程高效协同
What designs are needed in the architecture to build a general monitoring and alarm platform
C-end dream is difficult to achieve. What does iFLYTEK rely on to support the goal of 1billion users?
精益思想:来源,支柱,落地。看了这篇文章就懂了
The market value evaporated by 74billion yuan, and the big man turned and entered the prefabricated vegetables
app发版后的缓存问题
The best landing practice of cave state in an Internet ⽹⾦ financial technology enterprise
linux下清理系统缓存并释放内存
Salesmartly has some tricks for Facebook chat!