当前位置:网站首页>3.1 Monte Carlo Methods & case study: Blackjack of on-Policy Evaluation
3.1 Monte Carlo Methods & case study: Blackjack of on-Policy Evaluation
2022-07-03 10:09:00 【Most appropriate commitment】
Catalog
Monte Carlo
Definition
When we do not know the environemnt, we could not use Dynamic Programming to get the value functions. But I f we could get lots of samples, we could get exact enough value functions by averging these data.
Monte Carlo Prediction
Definition
When we get the samples, we could know the sequence of
 , then we could get returns by equation:
, then we could get returns by equation:
 .
.
So, we could average the samples of returns by averagng them in every state.
First-visit:
only average returns in state s when visiting s for the first time in this sample.
Every-visit:
average returns in state s when visiting s everytime in this sample.
Pesudocode
Initialization:
Returns = [ ]
Loop for N times:
generate an episide following the spesific policy
G = 0
loop for each step of episode, t = T-1, T-2,......,0

find the first visit of every s that appears in the episode and update  ( first - visit monte carlo prediction )
( first - visit monte carlo prediction )
update for every visit of every s that appears in the episode.
Blackjack
case

case analysis
S: 1. current sum number, Ace will be considered as 11, unless it will go bust.
2. rival's shown card number.
3. if Ace can be considered as 1 from 11.
A: hit or stick
R: no immediate reward, the terminal reward is 1, 0, -1 for win, draw, lose
Next S: sum number is below 21
our policy: hits unless 20, 21
rival's policy: hits unless 17 or more
PS: there is no consideration about the finite deck. We think it's a infinite deck ( with replacement )
Code
### settings
import math
import numpy
import random
# visualization
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.ticker import MultipleLocator
UP_BOUNDARY = 21 ;
LIMITE_RIVAL = 17;
LIMITE_AGENT = 20 ;
MIN_S = 4;
MAX_S = 21;
MIN_SHOWN_CARD = 1
MAX_SHOWN_CARD = 10
USEABLE_ACE = 1 ;
NON_USEABLE_ACE =0;
LOOP = 100000 ;
gamma = 1;
### functions and classes
# environment
def get_one_more_card():
card = random.randint(1,14);
card = min(10, card)
return card;
# the class of agent and rival
class Agent_rival_class( ):
def __init__(self):
self.card = 0 ;
self.ace_usable = 0 ;
self.shown_card = 0 ;
self.state = True ; # not go bust: True ; go bust: False
self.cards=[];
for i in range(0,2):
card = get_one_more_card();
self.cards.append(card);
# set the shown card
if i==0:
self.shown_card = card ;
# set the ace_usable state
if card == 1 and self.ace_usable == 0:
card = 11
self.ace_usable = 1
self.card += card
### method
def hit(self):
""" get one more card """
card = get_one_more_card();
self.cards.append(card);
if self.ace_usable == 0:
if card ==1 and self.card + 11 <= 21:
self.ace_usable = 1;
card = 11;
self.card += card ;
else:
if self.card + card <=21:
self.card += card;
else:
self.card -= 10;
self.card += card;
self.ace_usable=0;
# check state
if self.card <= 21:
self.state = True ;
else:
self.state = False;
def show_cards(self):
print("sum of my cards is "+str(self.card));
print("the cards I get are "+str(self.cards));
print("the state is "+ str(self.state));
### main programming
# initalization
v = numpy.zeros((MAX_S-MIN_S+1, MAX_SHOWN_CARD-MIN_SHOWN_CARD+1, 2))
v_update_num = numpy.zeros((MAX_S-MIN_S+1, MAX_SHOWN_CARD-MIN_SHOWN_CARD+1, 2))
for loop in range(0,LOOP):
S=[];
R=[];
agent = Agent_rival_class();
rival = Agent_rival_class();
if agent.card == 21 or rival.card ==21:
continue;
S.append((agent.card-MIN_S, rival.shown_card-MIN_SHOWN_CARD, agent.ace_usable))
### get the sample
while (agent.card < LIMITE_AGENT) :
agent.hit();
if agent.state == True:
R.append(0);
S.append((agent.card-MIN_S, rival.shown_card-MIN_SHOWN_CARD, agent.ace_usable));
else:
R.append(-1);
if agent.state == True:
while (rival.card < LIMITE_RIVAL ):
rival.hit();
if agent.state == True and rival.state == False :
R.append(1);
if agent.state == True and rival.state == True :
if agent.card > rival.card:
R.append(1);
elif agent.card == rival.card:
R.append(0);
else:
R.append(-1);
### sample ends
### update the returns
for j in range(1,len(S)+1):
i=-j;
if i == -1:
#print(S[i])
v[S[i]] = ( v_update_num[S[i]]*v[S[i]] + R[i] )/( v_update_num[S[i]]+1);
v_update_num[S[i]] += 1;
else:
#print(S[i])
v[S[i]] = ( v_update_num[S[i]]*v[S[i]] + R[i] + gamma*v[S[i+1]])/( v_update_num[S[i]]+1);
v_update_num[S[i]] += 1;
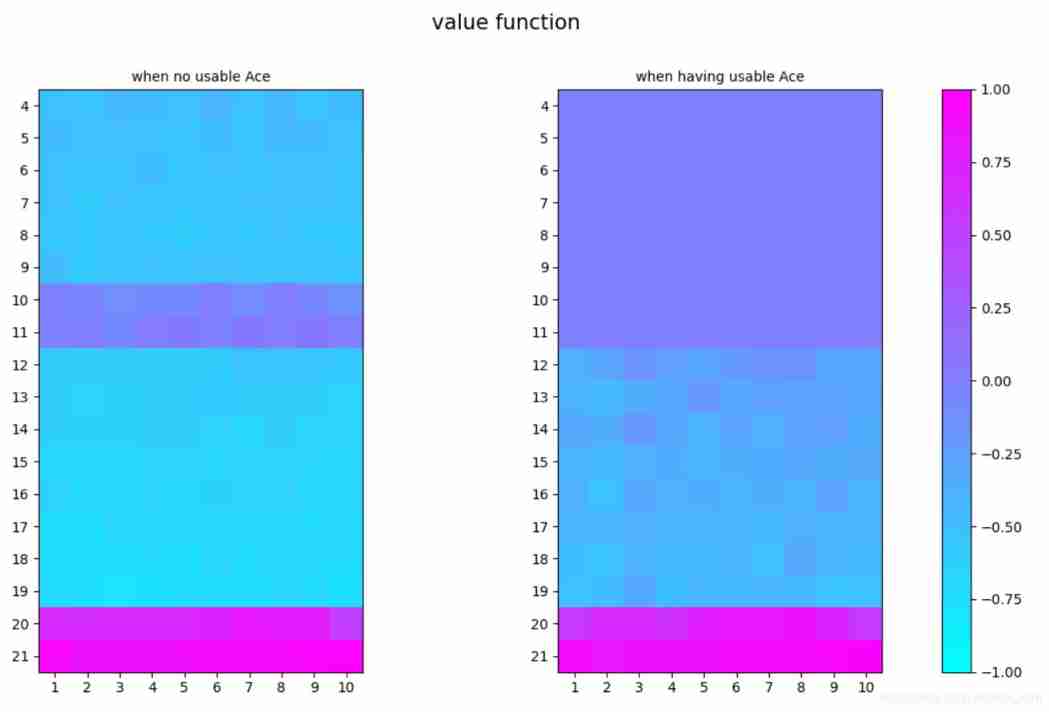
### visualization
v_0 = v[:,:,0]
v_1 = v[:,:,1]
fig, axes = plt.subplots(1,2)
xlabel=[]
ylabel=[]
for i in range(4,21+1):
ylabel.append(str(i))
for j in range(1,10+1):
xlabel.append(str(j))
axes[0].set_xticks(range(0,10,1))
axes[0].set_xticklabels(xlabel)
axes[0].set_yticks(range(0,18,1) )
axes[0].set_yticklabels(ylabel)
axes[0].set_title('when no usable Ace',fontsize=10)
im1 = axes[0].imshow(v_0,cmap=plt.cm.cool,vmin=-1, vmax=1)
axes[1].set_xticks(range(0,10,1))
axes[1].set_xticklabels(xlabel)
axes[1].set_yticks(range(0,18,1) )
axes[1].set_yticklabels(ylabel)
axes[1].set_title('when having usable Ace',fontsize=10)
im2 = axes[1].imshow(v_1,cmap=plt.cm.cool,vmin=-1, vmax=1)
fig = axes[1].figure
fig.suptitle('value function',fontsize=15)
fig.colorbar(im1,ax=axes.ravel().tolist())
plt.show()
Result
边栏推荐
- el-table X轴方向(横向)滚动条默认滑到右边
- [untitled] proteus simulation of traffic lights based on 89C51 Single Chip Microcomputer
- Simulate mouse click
- CV learning notes - clustering
- Crash工具基本使用及实战分享
- Interruption system of 51 single chip microcomputer
- Replace the files under the folder with sed
- 01 business structure of imitation station B project
- Emballage automatique et déballage compris? Quel est le principe?
- There is no shortcut to learning and development, and there is almost no situation that you can learn faster by leading the way
猜你喜欢
ADS simulation design of class AB RF power amplifier

CV learning notes - Stereo Vision (point cloud model, spin image, 3D reconstruction)

使用密钥对的形式连接阿里云服务器
Opencv feature extraction sift

Not many people can finally bring their interests to college graduation
My notes on intelligent charging pile development (II): overview of system hardware circuit design

MySQL root user needs sudo login

Installation and removal of MySQL under Windows
Leetcode - 1670 design front, middle and rear queues (Design - two double ended queues)

SCM is now overwhelming, a wide variety, so that developers are overwhelmed
随机推荐
Opencv notes 20 PCA
There is no shortcut to learning and development, and there is almost no situation that you can learn faster by leading the way
Liquid crystal display
LeetCode - 706 设计哈希映射(设计) *
Opencv feature extraction sift
Synchronization control between tasks
LeetCode - 1172 餐盘栈 (设计 - List + 小顶堆 + 栈))
Vgg16 migration learning source code
LeetCode - 1670 设计前中后队列(设计 - 两个双端队列)
Mobile phones are a kind of MCU, but the hardware it uses is not 51 chip
Openeuler kernel technology sharing - Issue 1 - kdump basic principle, use and case introduction
getopt_ Typical use of long function
Crash工具基本使用及实战分享
MySQL root user needs sudo login
byte alignment
For new students, if you have no contact with single-chip microcomputer, it is recommended to get started with 51 single-chip microcomputer
LeetCode - 673. Number of longest increasing subsequences
Leetcode 300 longest ascending subsequence
Toolbutton property settings
Replace the files under the folder with sed