当前位置:网站首页>Yyds dry goods inventory [Gan Di's one week summary: the most complete and detailed in the whole network]; detailed explanation of MySQL index data structure and index optimization; remember collectio
Yyds dry goods inventory [Gan Di's one week summary: the most complete and detailed in the whole network]; detailed explanation of MySQL index data structure and index optimization; remember collectio
2022-07-05 01:05:00 【Suzhou Kaijie Intelligent Technology】
【 A week's summary : The whole network is the most complete and thinnest 】️Mysql Index data structure and index optimization ️《️ Remember to collect ️》
- Catalog
-
️ To speak! !!!!️ - ? Blogger introduction
- ️1、 Indexes
- 2、 Index data structure
- Binary tree (Binary Trees)
- ️ Red and black trees (Red-Black Trees)
- ️ Other structural problems
- B Trees (B-Trees)
- problem 1: Is the number of positioning rows
- ️ problem 2: Unable to process range query
- ️B + Trees (B+Trees)
- ️B + Tree properties summary
- ️Hash Indexes
- ️3、MySQL Database engine
- ️4、 Overlay index (Covering index)
- ️5、 Joint index
- 6、 Optimization Suggestions
Catalog
<table><tr><td bgcolor=#29b6f6 > ️ To speak! !!!!️</td></tr></table>

? Blogger introduction
? Personal home page : Suzhou Kaijie Intelligent Technology Co., Ltd
? The authors introduce : Founder of Suzhou Kaijie Intelligent Technology Co., Ltd , At present, it mainly cooperates with Huawei 5G Development in the field of industrial robots ,2D、3D Visual project development , Bidding and development of government projects .
? If you have any questions, please send a private letter , I will reply in time when I see it
WeChat official account : Suzhou program white
? Those who want to join the technical exchange group can add my friends , The group will share learning materials
️1、 Indexes
In a relational database , The index is a separate 、 A storage data structure that physically sorts the values of one or more columns in a database table , It is a collection of one or more column values in a table and a corresponding list of logical pointers to the data pages in the table that physically identify these values .
The function of index is equivalent to the catalogue of books , You can quickly find the required content according to the page number in the table of contents .
stay MySQL in , The storage engine uses indexes in a similar way , First find the corresponding value in the index , Then find the corresponding row according to the matching index record .
First of all, let's explain MySQL The index of is mainly based on Hash Watch or B + Trees .
2、 Index data structure
To understand index, we need to learn from the common data structure of index , Here are the common index data structures in the collection .
Binary tree (Binary Trees)
A binary tree has at most two branches per node ( That is, there is no branching degree greater than 2 The node of ) The tree structure of the . It is often called “ The left subtree ” and “ Right subtree ”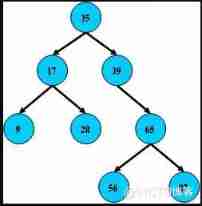
The left subtree < Parent node <= Right subtree
The second order of binary tree i There are at most 2^(i-1) Nodes ,
Depth is K At most, there is one of them 2^k-1 node ( Define the depth of the root node k0=0), And the total number of owning nodes matches , be called “ Full binary tree ”;
Binary trees are usually used as data structures , A typical use is to define a marker function for a node , Relate some values to each node . In this way, the marked binary tree can be realized Binary search tree and Binary heap , And applied to efficient search and sorting .
Learning data structure at the same time , It's also recommended here Data Structure Visualizations To study , It is very intuitive to see the process allowed by the data structure , You can see clearly how to go step by step .
Find one Binary Search Trees Binary tree .
The data insertion process of binary tree can be seen intuitively , as follows :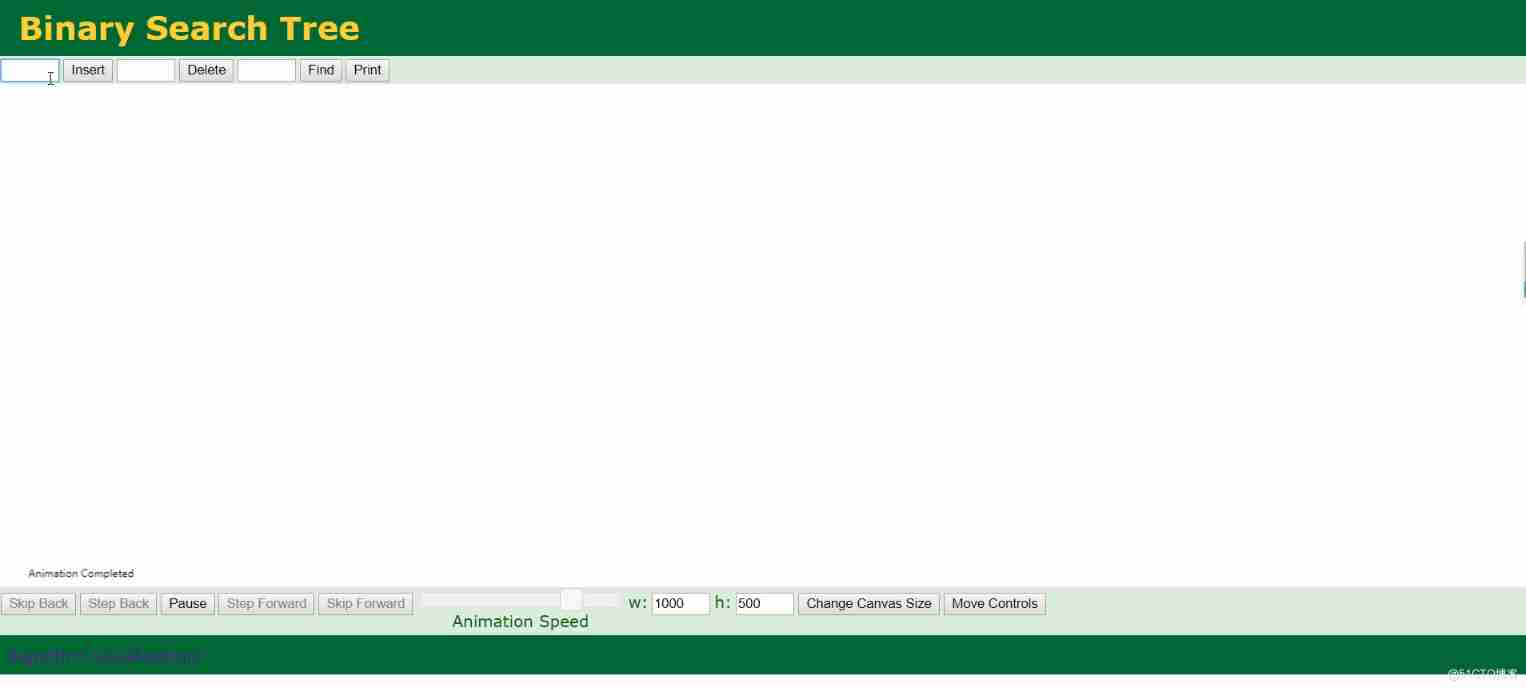
You can see that a binary tree is not suitable for use as an index , If the amount of data is huge , The number of layers of a binary tree will be very large , The efficiency of searching is very slow .
Recommended reading : Wikipedia - Binary tree
️ Red and black trees (Red-Black Trees)
It's a self balanced binary search tree , A typical use is to implement associative arrays .
The structure of the red black tree is complex , But its operation has a good worst-case run time , And efficient in practice : It can be O (log n) Finish searching in time , Insert and delete , there n Is the number of elements in the tree .
<font color=#2962ff size=5 face= “ Regular script ”> Red and black trees follow the following principles :</font>
Nodes are red or black .
The roots are black .
All the leaves are black ( Leaves are NIL node ).
Each red node must have two black child nodes .( You cannot have two consecutive red nodes on all paths from each leaf to the root .)
All simple paths from any node to each of its leaves contain the same number of black nodes .
Here is a specific red and black tree legend :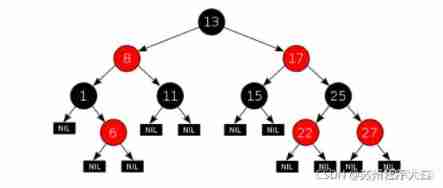
These constraints ensure the key features of the red black tree : The longest possible path from root to leaf is no more than twice as long as the shortest possible path . The result is that the tree is roughly balanced . Because operations like insertion 、 The worst-case time to delete and find a value is required to be proportional to the height of the tree , This theoretical upper limit on height allows trees to be efficient at worst , It's different from ordinary Binary search tree .
Know why these properties ensure this result , Notice the nature of 4 As a result, the path cannot have two adjacent red nodes . The shortest possible paths are all black nodes , The longest possible paths have alternating red and black nodes . Because by nature 5 All the longest paths have the same number of black nodes , This means that no path can be twice as long as any other path .
Also in Data Structure Visualizations Choose from Red-Black Trees The insertion process of the red black tree can be seen intuitively :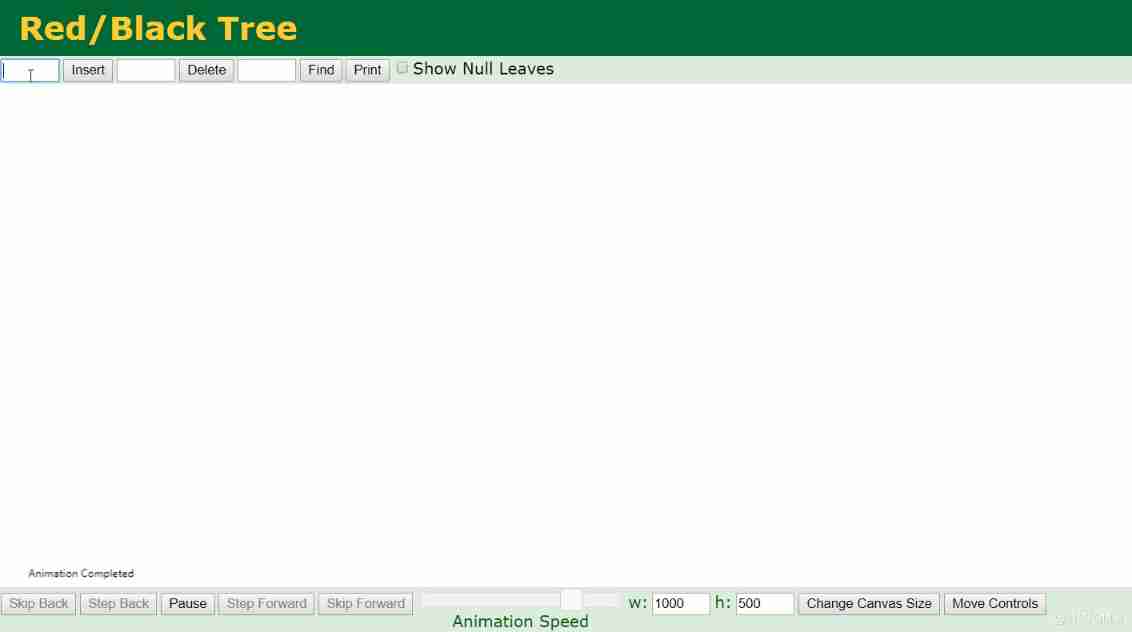
The same is true of black and red trees MySQL The index of , After a huge amount of data , Several layers will also become larger .
Recommended reading :
Wikipedia - Red and black trees
️ Other structural problems
Unable to load memory , It depends on the disk ( or SSD) Storage . Memory can read and write thousands of times faster than disk ( It's about implementation ), therefore , The core issue is “ How to reduce the number of disk reads and writes ”.
First of all, do not consider the page table mechanism , Suppose every time you read 、 Write directly to disk , that :
Linear structure : read / Write average O (n) Time
Binary search tree (
BST): read / Write average O (log2 (n)) Time ; If the tree is unbalanced , Then the worst reading / Write O (n) TimeSelf balanced binary search tree (
AVL): stay BST On the basis of this, a self balancing algorithm is added , read / Write the maximum O (log2 (n)) TimeRed and black trees (
RBT): Another self balancing search tree , read / Write the maximum O (log2 (n)) Time
BST、AVL、RBT It's good to read and write from O (n) Optimize to O (log2 (n)); among ,AVL and RBT All ratio BST More self balancing functions , Reduce the number of reads and writes to the maximum O (log2 (n)).
Let's say we use an auto increment primary key , The primary key itself is ordered , The reading and writing times of tree structure can be optimized to the tree height , The higher the tree, the lower the number of reads and writes ; Self balance ensures the stability of tree structure . If you want to further optimize , Can be introduced B Trees and B+ Trees .
B Trees (B-Trees)
also called : Multiway balanced search tree . Most storage engines support B Tree index .b Trees usually mean that all values are stored in order , And the distance from each leaf node to the root is the same .B Tree index can speed up data access , Because the storage engine no longer needs a full table scan to get data . The following figure is a simple B Trees .
stay B In the tree , Inside ( Not a leaf ) Nodes can have a variable number of children ( The range of quantities is pre-defined ). When data is inserted or removed from a node , Its number of child nodes changes . In order to keep within the preset quantity range , Internal nodes may be merged or detached .
As shown in the figure below :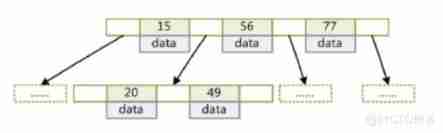
Leaf nodes have the same depth , The pointer to the leaf node is null
All index elements are not duplicate
The data indexes in the node are incrementally arranged from left to right
Both the middle node and the leaf node have satellite data data( The data record that the index element points to )
It only demonstrates the process of insertion , This can be done through delete、find Perform delete and find operations . Intuitively feel B The execution of the tree .
Each node stores multiple Key And subtree , Subtree and Key In order .
Similar to a binary search tree , Each node stores multiple key And subtree , Subtree and key In order .
The directory of the page table is extended external storage + Speed up disk read and write , One page (Page) Usually 4K( Equal to disk data block block Size , see inode And block Analysis of ), The operating system loads content from disk to memory in pages at a time ( To apportion the search cost ), After modifying the page , Write the page back to disk at a later date . Considering the good nature of the page table , You can make the size of each node approximately equal to one page ( send m A very large ), Each time a page is loaded, it can completely cover a node , In order to select the next level of sub tree ; The same goes for subtrees . For page tables ,AVL( or RBT) amount to 1 individual key+2 Of the subtree B Trees , Because logically adjacent nodes , It's usually not physically adjacent , therefore , Read into one 4k page , Most of the space in the page will be invalid data .
hypothesis key、 Sub tree node pointers all occupy 4B, be B The maximum number of tree nodes m * (4 + 4) = 8m B; Page size 4KB. be m = 4 * 1024 / 8m = 512, One 512 Forked B Trees ,1000w The data of , Maximum depth log(512/2)(10^7) = 3.02 ~= 4. Compare binary trees, such as AVL The depth of this is log(2)(10^7) = 23.25 ~= 24, The difference between 5 More than times . shock !B That's how deep the tree index is !
<font color=#2962ff size=5 face= “ Regular script ”> What then? B Count so well , also B + The emergence of trees , It must be to solve B Problems with trees </font>
1、 Is the number of positioning rows
2、 Unable to process range query
problem 1: Is the number of positioning rows
Data table records have multiple fields , Just locating the primary key is not enough , You also need to navigate to the data row . Yes 3 A solution to :
Direct will key Corresponding data row ( May correspond to multiple lines ) In the storage child node .
Data lines are stored separately ; Add a field to the node , location key The location of the corresponding data line .
modify key And the judgment logic of the subtree , Make the subtree equal to or greater than the previous key Less than the next key, Eventually all access will fall to the leaf node ; The location of the data row or data row directly stored in the leaf node .
programme 1 direct pass, Storing data will reduce the number of subtrees in the page ,m Reduce the tree height and increase .
programme 2 A field has been added to the node of , The assumption is 4B The pointer to , It's new m = 4 * 1024 / 12m = 341.33 ~= 341, Maximum depth log(341/2)(10^7) = 3.14 ~= 4.
programme 3 The node of m Constant with depth , But time complexity becomes stable O (logm (n)).
<font color=#2962ff size=5 face= “ Regular script ”> Personally, I think the preferred scheme 3 .</font>
️ problem 2: Unable to process range query
In real business , Range queries are very frequent ,B The tree can only be located in one index location ( May correspond to multiple lines ), It's hard to handle range queries . The smaller change is 2 A plan :
No change ; Check the left boundary first , Then find the right boundary , then DFS( or BFS) Traverse the left bound 、 The node between the right bounds .
stay “ problem 1 - programme 3” On the basis of , Since all data rows are stored in leaf nodes ,B The leaf nodes of the tree are also orderly , You can add a pointer , Point to the next leaf node in the primary key order of the current leaf node ; Check the left boundary first , Then find the right boundary , And then we go from the left bound to the bounded linear traversal .
At first glance, it feels like a plan 1 Comparison scheme 2 good —— Time complexity is the same as constant terms , programme 1 It doesn't need to be changed . But don't forget the principle of locality , No matter what data row or data row location is stored in the node , programme 2 Is that , You can still use the page table and cache to read the information of the next node in advance . And the plan 1 The nodes are logically adjacent 、 Disadvantages of physical separation .
Recommended reading :
️B + Trees (B+Trees)
<font color=#2962ff size=5 face= “ Regular script ”> The main changes are as mentioned above :</font>
modify key Organization logic with subtree , Drop index access to leaf nodes .
String the leaf nodes in sequence ( Convenient range query ).
<font color=#2962ff size=5 face= “ Regular script ”> Go back to the last B Trees , One m Step B Trees have the following characteristics :</font>
1、 The root node has at least two children .
2、 Each intermediate node contains k-1 Elements and k A child , among m/2 <= k <= m.
3、 Each leaf node contains k-1 Elements , among m/2 <= k <= m.
4、 All leaf nodes are on the same layer .
5、 The elements in each node are arranged from small to large , Among the nodes k-1 An element is exactly k The values of the elements contained by children are divided into .
<font color=#2962ff size=5 face= “ Regular script ”> One m Step B + Trees have the following characteristics :</font>
1、 Yes k The middle node of the subtree contains k Elements (B In the tree is k-1 Elements ), Each element does not hold data , Index only , All data is stored in the leaf node .
2、 All leaf nodes contain the information of all elements , And pointers to records containing these elements , And the leaf node itself is linked in large order according to the size of the keyword .
3、 All the intermediate node elements exist in the child nodes at the same time , Is the largest of the child node elements ( Or the smallest ) Elements .
️B + Tree properties summary
<font color=#2962ff size=5 face= “ Regular script ”> B + Trees are B Tree upgrade , It has the following characteristics :</font>
Non leaf nodes do not store data, Store index only ( redundancy ), More indexes can be placed .
The leaf node contains all index fields .
The leaf node is connected with a pointer , Improve the performance of interval access .
Only leaf nodes have satellite data data( The data record that the index element points to ).
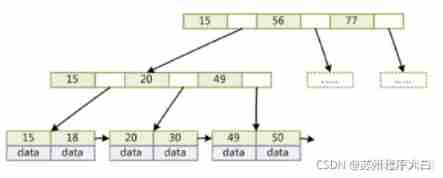
Also in Data Structure Visualizations Choose from B+ TreesB + TreesYou can intuitively see the insertion process by inserting
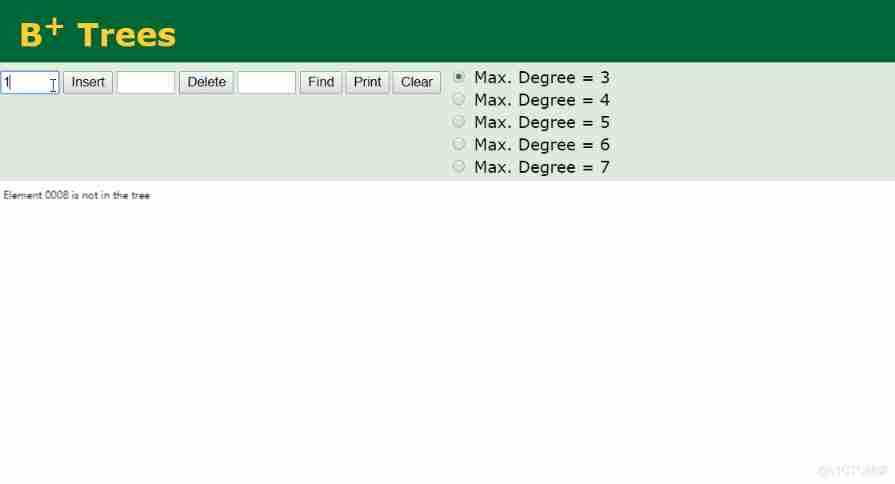
You can see in the moving picture ,B + Each leaf node of the tree has a pointer to the next node , String all the leaf nodes together . Index data is stored in leaf nodes .
<font color=#2962ff size=5 face= “ Regular script ”> B + Trees are compared to B Trees , What are the advantages :</font>
1、 A single node stores more elements , Make the query IO Fewer times .
2、 All queries need to find leaf nodes , Query performance is stable .
3、 All leaf nodes form an ordered list , Easy range query .
summary ,B + Trees are compared to B Trees have three advantages :1.IO Fewer times ;2. Query performance is stable ;3. Range query is simple .
Recommended reading :
️Hash Indexes
hash The index is based on hash Table implementation ,Hash Index is to pass the index key through Hash After the operation , take Hash The result of the calculation Hash The value and the corresponding row pointer information are stored in a Hash In the table . Only queries that accurately match all columns of the index are valid . The index can be retrieved at one time , Unlike B-Tree The index needs to start from the root node to the target node . although Hash The index is fast , Far above B-tree Indexes , But there are also disadvantages .
Hash Index can only satisfy ’=’,’IN’,’<=>’ Inquire about , That is equivalent query , Can't use range query . Very limited .
because Hash Index comparison is to carry out Hash After the operation Hash value , So it can only be used for equivalent filtering , Can't be used for range based filtering , Because after the corresponding Hash After algorithm processing Hash The relationship between the size of the value , There's no guarantee of and Hash It's exactly the same before the operation .
because Hash The index is through hash Table implementation , There is no order in itself .
because Hash What the index stores is the process Hash After calculation Hash value , and Hash The magnitude of the value does not necessarily relate to Hash The key value before the operation is exactly the same , So the database can't use the index data to avoid any sort operation .
Hash Index can't query with partial key .
For composite indexes ,Hash The index is calculating hash When the value is combined, the index key is combined and then calculated together hash value , Not separately hash value , So when you query by combining one or more index keys in front of the index ,Hash Index can't be used .
Hash Index can't avoid table scanning at any time .
I already know that ,Hash Index is to pass the index key through Hash After the operation , take Hash The result of the calculation Hash The value and the corresponding row pointer information are stored in a Hash In the table , Because different index keys are the same Hash value , So even if you meet someone Hash Number of records of key value data , I can't go from Hash Direct query in index , You still need to access the actual data in the table for corresponding comparison , And get the corresponding result .
Hash Index encountered a lot of Hash When the values are equal, the performance is not necessarily better than B-Tree High index .
For index keys with low selectivity , If you create Hash Indexes , Then there will be a lot of record pointer information stored in the same Hash Correlation of values . In this way, it will be very troublesome to locate a record , Will waste many times table data access , And the overall performance is low .
️3、MySQL Database engine
adopt navicat Tool view table design options , You can see from the engine MySQL So many engines . Specific breakdown to each table , Different watch engines can be different .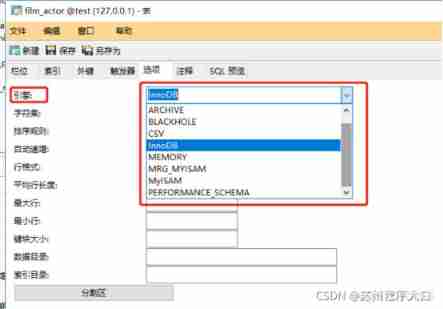
️MyISAM
Create a new table t_test_myisam, Engine USES MyISAM, You can see that there are 3 File 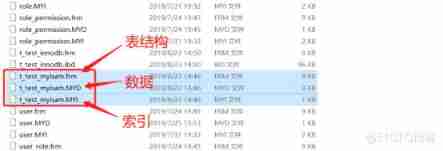
You can see that the index and the data are separate , The index file only stores the address of the data record , So it belongs to Nonclustered index .
primary key (Primary Index)
MyISAM Engine USES B+Tree As an index structure , Leaf node data It's the address of the data record . As shown below MyISAM Schematic diagram of primary key index .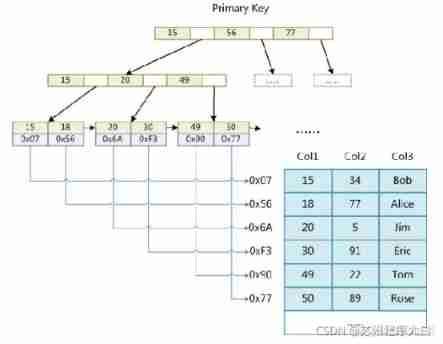
among Col1 Primary key , It can be seen that MyISAM The index file of holds only the address of the data record .
Secondary index (Secondary Index)
stay Col2 Create a secondary index on , As shown in the schematic diagram of auxiliary index .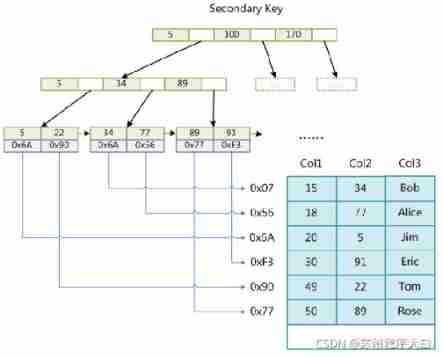
You can see that there is no difference from the primary key index , It's just the primary key index key Is the only one. , And the secondary index key Can be repeated .
MyISAM The algorithm of index retrieval in B+Tree Search algorithm search index , If specified Key There is , Then remove it. data Domain value , And then to data The value of the field is the address , Read the corresponding data record .
Three of these fields are the union index .
Due to the emergence of joint index ,key Consists of multiple columns , The order of columns determines the number of columns that can hit the index . Also called Leftmost prefix matches .
Index can only be used to find key Whether there is ( equal ), Range lookup encountered (>,<,=,between,like Left match ) You can't match further .
️InnoDB
Create a new table t_test_innodb, Engine USES InnoDB, You can see that there are 2 File 
primary key (Primary Index)
InnoDB The index and data of are in one file .
according to B+Tree An index structure of an organization .
The leaf node holds the complete data record and index . This kind of index is called cluster index .
Indexed Key Is the primary key of the data , therefore InnoDB The table data file itself is the primary index .
Here's the picture :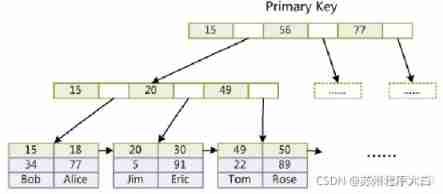
You can see that the leaf node contains the complete data record .
because InnoDB The data file itself should be aggregated according to the primary key , therefore InnoDB requirement Must have primary key . If not explicitly specified , be MySQL The system will automatically select a column that can uniquely identify the data record as the primary key , If there is no such column , be MySQL Automatically for InnoDB Table generates an implicit field rowid A primary key , The length of this field is 6 Bytes , The type is long plastic .
Secondary index (Secondary Index)
Secondary index , The second line on the way name, As an index, see Figure :
InnoDB Tables are based on clustered indexes . The implementation of clustering index makes the search according to the primary key very efficient , But need First retrieve the secondary index to get the primary key , Then use the primary key to retrieve the record in the primary index .
because InnoDB Implementation features of index , It is recommended to use auto increment primary key of shaping .
<font color=#2962ff size=5 face= “ Regular script ”> There are three benefits :</font>
Self increasing key It's usually int Equal integer type ,key It's compact , such m It can be very large , And the index takes up little space . The most extreme example , If you use 50B Of varchar( Including the length ), that m = 4 * 1024 / 54m = 75.85 ~= 76, Maximum depth log(76/2)(10^7) = 4.43 ~= 5, Plus cache defect 、 The cost of string comparison , The cost of time increases a lot . meanwhile ,key from 4B Growth to 50B, The increase of the space occupation of the whole index tree is also extremely terrifying ( If the secondary index uses the primary key to locate data rows , Then space growth is more serious ).
MySQL The data comparison at the bottom of index is all integer comparison , If the primary key is of string type , There is also English , You have to change ASCII Code comparison . So it's not recommended uuid A primary key .
The increasing primary key makes the insertion of data row fall to the right of index number for example , The frequency of node splitting is low .B+Tree Actually operate the insertion process . If it's not a non monotonic primary key , The insertion process can cause a lot of node rearrangement , Not conducive to the original intention of index optimization .
️InnoDB Index and MyISAM The difference between indexes
One is the difference between main indexes :InnoDB The data file itself is the index file . and MyISAM The index and data of are separated .
The second is the difference of auxiliary index :InnoDB Secondary index of data The domain stores the value of the corresponding record primary key instead of the address . and MyISAM There is not much difference between the secondary index and the primary index .
️4、 Overlay index (Covering index)
InnoDB The storage engine supports overriding indexes , That is, from the secondary index, you can get the query records , Instead of querying the records in the clustered index , It's what I usually say. There's no need to go back to the table .
Can reduce a lot of IO operation . If you want to query fields not included in the secondary index , You have to traverse the secondary index first , Then traverse the clustered index , And if the value of the field to be queried is on the secondary index , There's no need to look up the clustered index , This will obviously reduce IO operation .
️5、 Joint index
Union index refers to index multiple columns on a table . The schematic diagram of joint index is shown in the figure below
InnoDB The storage engine supports overriding indexes , That is, from the secondary index, you can get the query records , There is no need to query the records in the clustered index . Can reduce a lot of IO operation .
If you want to query fields that are not included in the secondary index , You have to traverse the secondary index first , Then traverse the clustered index , And if the value of the field to be queried is on the secondary index , There's no need to look up the clustered index , This will obviously reduce IO operation .
for example , Joint index (a,b,c,d), Query criteria a=1 and b=3 and c>3 and d=4; Will hit... In turn a,b,c, Can't hit d, This is the leftmost prefix match .
Index on two or more columns . As shown in the schematic diagram of joint index :
The union index in the figure above has three , From top to bottom , Sort strictly according to .
6、 Optimization Suggestions
<font color=#2962ff size=5 face= “ Regular script ”> 1、 Leftmost prefix matches </font>
The index can be as simple as a column (a), Can also be complex as multiple columns (a, b, c, d), namely Joint index . If it's a joint index , that key It also consists of multiple columns , meanwhile , Index can only be used to find key Whether there is ( equal ), Range query encountered (>、<、between、like Left match ) We can't match any more , Then it degenerates to linear search . therefore , The order of columns determines the number of columns that can hit the index .
If there is an index (a, b, c, d), Query criteria a = 1 and b = 2 and c > 3 and d = 4, It will hit each node in turn a、b、c, Can't hit d. That is, the leftmost prefix matching principle .
<font color=#2962ff size=5 face= “ Regular script ”> 2、in Automatically optimize the sequence </font>
There is no need to consider =、in The order of waiting ,mysql Will automatically optimize the order of these conditions , To match as many index columns as possible .
If there is an index (a, b, c, d), Query criteria c > 3 and b = 2 and a = 1 and d < 4 And a = 1 and c > 3 and b = 2 and d < 4 And so on ,MySQL Will automatically optimize to a = 1 and b = 2 and c > 3 and d < 4, Hit... In turn a、b、c.
<font color=#2962ff size=5 face= “ Regular script ”> The index column cannot participate in the calculation </font>
Query conditions with index columns participating in calculation are not friendly to index ( You can't even use indexes ), Such as from_unixtime(create_time) = '2021-08-27'.
The reason is simple , How to find the corresponding key? If linear scanning , It needs to be recalculated every time , The cost is too high ; If binary search , We need to focus on from_unixtime Method to determine the size relationship .
therefore , The index column cannot participate in the calculation . Above from_unixtime(create_time) = '2021-08-27' The sentence should be written as create_time = unix_timestamp('2021-08-27').
<font color=#2962ff size=5 face= “ Regular script ”> Don't create new indexes if you can expand </font>
If you already have an index (a), Want to index (a, b), Try to change the index (a) Index (a, b).
The cost of creating a new index is easy to understand . And based on Index (a) Change to index (a, b) Words ,MySQL It can be directly in the index a Of B + on the tree , After splitting 、 Merge, etc. to index (a, b).
<font color=#2962ff size=5 face= “ Regular script ”> There is no need to index prefixes with inclusion relationships </font>
If you already have an index (a, b), There is no need to index (a), But if necessary , You still need to think about indexing (b).
<font color=#2962ff size=5 face= “ Regular script ”> Select the column with high differentiation as index </font>
It's easy to understand . Such as , Index by sex , Then the index can only 1000w The row data is divided into two parts ( Such as 500w male ,500w Woman ), The index is almost invalid .
Degree of differentiation The formula is count(distinct <col>) / count(*), Indicates the proportion of fields that do not repeat , The larger the ratio, the better the differentiation . The only key differentiator is 1, And some states 、 Gender fields may have a similar degree of differentiation in front of big data 0.

边栏推荐
- Actual combat simulation │ JWT login authentication
- Identifiers and keywords
- 【大型电商项目开发】性能压测-性能监控-堆内存与垃圾回收-39
- 【纯音听力测试】基于MATLAB的纯音听力测试系统
- Grabbing and sorting out external articles -- status bar [4]
- What if the programmer's SQL data script coding ability is weak and Bi can't do it?
- FEG founder rox:smartdefi will be the benchmark of the entire decentralized financial market
- 7. Scala process control
- MySQL uses the explain tool to view the execution plan
- Talking about JVM 4: class loading mechanism
猜你喜欢

User login function: simple but difficult
leetcode494,474
dotnet-exec 0.6.0 released

Basic operations of database and table ----- create index
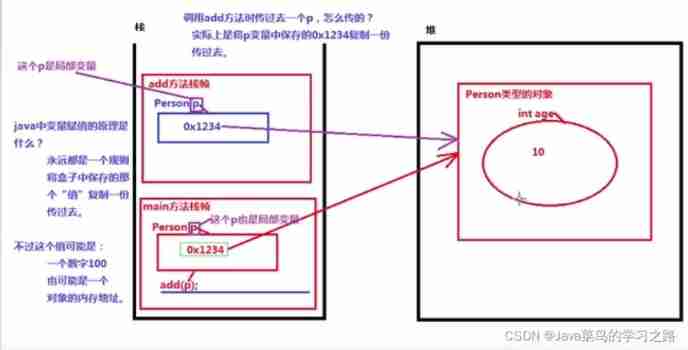
Parameter passing mechanism of member methods
Several simplified forms of lambda expression
【C】 (written examination questions) pointer and array, pointer
Basic concept and usage of redis
107. SAP UI5 OverflowToolbar 容器控件以及 resize 事件处理的一些细节介绍

“薪资倒挂”、“毕业生平替” 这些现象说明测试行业已经...
随机推荐
"Upside down salary", "equal replacement of graduates" these phenomena show that the testing industry has
[development of large e-commerce projects] performance pressure test - Performance Monitoring - heap memory and garbage collection -39
107. Some details of SAP ui5 overflow toolbar container control and resize event processing
Mongodb series learning notes tutorial summary
Global and Chinese markets for stratospheric UAV payloads 2022-2028: Research Report on technology, participants, trends, market size and share
Sorting selection sorting
Inventory of more than 17 typical security incidents in January 2022
Basic concept and usage of redis
pycharm专业版下载安装教程
【纯音听力测试】基于MATLAB的纯音听力测试系统
Getting started with Paxos
SAP UI5 应用的主-从-从(Master-Detail-Detail)布局模式的实现步骤
创新引领方向 华为智慧生活全场景新品齐发
Digital DP template
【海浪建模1】海浪建模的理论分析和matlab仿真
Relationship between classes and objects
BGP comprehensive experiment
视频网站手绘
Expose testing outsourcing companies. You may have heard such a voice about outsourcing
Global and Chinese market of nutrient analyzer 2022-2028: Research Report on technology, participants, trends, market size and share