当前位置:网站首页>从交互模型中蒸馏知识!中科大&美团提出VIRT,兼具双塔模型的效率和交互模型的性能,在文本匹配上实现性能和效率的平衡!...
从交互模型中蒸馏知识!中科大&美团提出VIRT,兼具双塔模型的效率和交互模型的性能,在文本匹配上实现性能和效率的平衡!...
2022-07-06 10:09:00 【我爱计算机视觉】
关注公众号,发现CV技术之美
本篇分享论文『VIRT: Improving Representation-based Models for Text Matching through Virtual Interaction』,从交互模型中蒸馏知识!中科大&美团提出VIRT,兼具双塔模型的效率和交互模型的性能,在文本匹配上实现性能和效率的平衡!
详细信息如下:

论文链接:https://arxiv.org/abs/2112.04195
01
摘要
随着预训练Transformer的蓬勃发展,基于孪生Transformer编码器的表示模型已成为高效文本匹配的主流技术。然而,与基于交互的模型相比,由于文本对之间缺乏交互,这些模型的性能严重下降。现有技术试图通过对孪生编码表示进行额外的交互来解决这一问题,而编码过程中的交互仍然被忽略。
为了解决这一问题,作者提出了一种虚拟交互机制(VIRT),通过注意力图提取将交互知识从基于交互的模型转移到孪生编码器。VIRT作为一个仅用于训练运行时的组件,可以完全保持孪生结构的高效性,并且在推理过程中不会带来额外的计算成本。为了充分利用所学的交互知识,作者进一步设计了一种适应VIRT的交互策略。
在多个文本匹配数据集上的实验结果表明,本文的方法优于现有的基于表示的模型。此外,VIRT可以轻松地集成到现有的基于表示的方法中,以实现进一步的改进。
02
Motivation
文本匹配旨在对一对文本之间的语义关联进行建模,这是各种自然语言理解应用中的一个基本问题。例如,在社区问答(CQA)系统中,一个关键组件是通过问题匹配从数据库中找到与用户问题相关的类似问题。类似地,对话代理需要通过预测用户陈述和一些预定义假设之间的蕴含关系来进行逻辑推断。
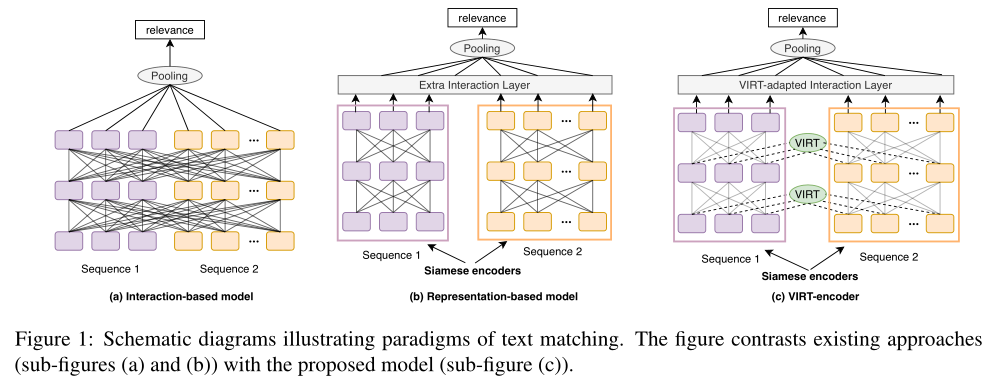
最近,深度预训练Transformer的广泛使用在文本匹配任务方面取得了显著进展。通常有两种基于微调Transformer编码器的范例:基于交互的模型(即交叉编码器)和基于表示的模型(即双编码器),如上图(a)和(b)所示。基于交互的模型(例如,BERT)将文本对concat为单个序列,并在文本对之间执行完全交互。虽然完全交互提供了从模型底部到顶部的丰富匹配信号,但它也带来了较高的计算成本和推理延迟,这使得它很难在实际场景中部署。
例如,在一个电子商务搜索系统中,由于有数百万个好的查询对,使用基于交互的模型对这些对进行评分需要花费数十天的时间。相反,基于表示的模型由两个孪生编码器独立编码文本对,而无需任何交互。因此,它支持嵌入的离线计算,这大大减少了在线延迟,从而使此类模型在实践中非常有用。不幸的是,没有任何交互的独立编码可能会丢失匹配信号,从而导致性能严重下降。
为了平衡效率和效能,一些工作试图为孪生结构配备交互模块。已经提出了各种交互策略,例如注意力层和Transformer层。然而,出于效率考虑,这些交互模块是在孪生编码器之后添加的,为了保留孪生特性,孪生编码器编码过程中的交互仍然被忽略。因此,丰富的交互信号丢失,现有的基于表示的模型在以下方面仍然远远落后于基于交互的模型。
在这项工作中,作者试图打破基于交互的模型和基于表示的模型之间的困境。关键思想是在基于表示的模型中,在不破坏孪生结构的情况下,整合孪生编码过程中的交互。为此,作者提出了虚拟交互(VIRT),这是一种将文本对交互中的知识传递到基于表示的模型的孪生编码器的新机制。
具体来说,孪生编码器通过模仿完整的交互来学习这对文本之间的交互信息,并以基于交互的模型传递的知识为指导。将知识转移作为训练过程中的注意图提取任务来实现,在推理过程中可以删除该任务以保持孪生特征。因此称之为“虚拟互动”。此外,为了进一步利用孪生编码后所学的交互知识,作者设计了一种虚拟适应的交互策略。在一个名为VIRT编码器的基于表示的模型联合实现了VIRT和VIRT适应的交互策略,如上图(c)所示。
本文的贡献可以总结如下:
作者提出了一种新的虚拟交互机制VIRT,通过从基于交互的模型中提取注意力图,将其集成到基于表示的模型的孪生编码器中,而无需额外的推理成本。
大量实验表明,本文提出的VIRT编码器优于以前基于SOTA表示的模型,同时保持了推理效率。
VIRT可以很容易地集成到其他基于表示的文本匹配模型中,以进一步提高其性能。
03
方法
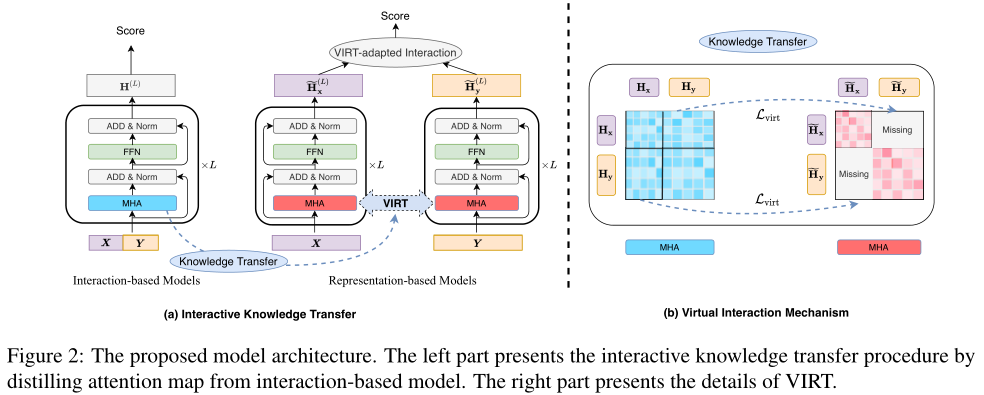
在本节中,作者将首先描述基于交互的模型和基于表示的模型。然后,介绍虚拟交互机制(VIRT),它将交互知识从基于交互的模型提取到孪生编码器。此外,通过VIRT适应的交互策略,可以充分利用所学的交互知识。VIRT的体系结构如上图所示。
3.1 Interaction-based Models
给定两个文本序列和作为输入,基于交互的模型将X和Y concat为,并使用L层Transformer对进行编码:。Transformer的每一层由两个残差子层组成:一个多头注意力操作(MHA)和一个前馈网络(FFN):
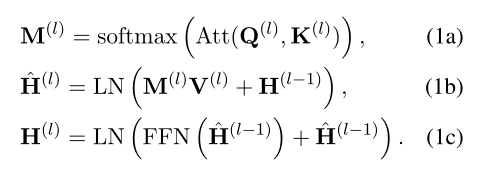
,其中d是隐藏状态的维数。这里,为了便于描述,省略了batch大小和注意力头的维度。
402 Payment Required
是第(l-1)层的中间表示,它对X和Y之间的交互信息进行编码。 和 是第l层的注意力参数,由 映射而来。 表示LayerNorm操作。可以看到,基于交互的模型能够通过完全注意力机制将交互信息编码到X和Y的表示中。具体地,组合表示以生成注意力图M,其表示不同交互信号的权重。这些表示根据M来进行选择和融合。
3.2 Representation-based Models
与基于交互的模型相比,基于表示的模型首先通过两个独立的孪生Transformer编码器分别对X和Y进行编码(这里假设每个编码器有L个Transformer层):,。然后,它们对孪生编码的和进行额外的相互作用。transformer的结构与基于交互的模型相同,只是注意图(或)仅用X(或Y)单独计算:
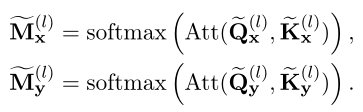
与基于交互的模型相比,编码过程中X和Y之间没有交互。在基于表示的模型中,X和Y之间的细粒度交互信息会丢失,这会导致性能下降。
3.3 Virtual Interaction
如前所述,基于表示的模型的主要缺点是在单独编码两个输入序列时缺乏交互。直观地说,基于交互的模型通过MHA机制执行交互。通过对应于X和Y的表示来计算。与基于交互的模型相比,基于表示的模型仅通过X(或Y)单独计算(或)。在接下来的部分中,将首先详细说明这两种模型在MHA操作方面的差异。接下来,介绍了VIRT机制,它可以在不增加额外推理成本的情况下改进基于表示的模型。
首先分解基于交互模型的MHA操作,如上图(b)中的蓝色注意图所示。具体而言,基于交互的模型中第l层的输入表示,即,可分解为X部分和Y部分。因此,,其中,
402 Payment Required
。基于此,注意力参数也可以重写为X部分(表示为 和 )和Y部分(表示为 和 )的组合。Softmax(·)操作之前的最终注意力得分(表示为 )可分解为以下分区矩阵: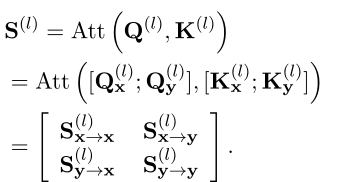
因此可以分为四部分:
402 Payment Required
,即: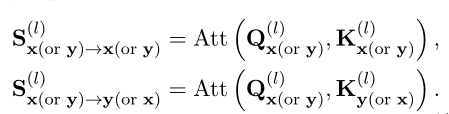
是仅在X或Y中执行的MHA操作,其对应于基于表示的模型中的MHA操作。和指基于交互的模型中x和Y之间的交互,这些模型负责用交互信息丰富表示。然而,它们在基于表示的模型中缺失,从而导致这两种模型之间的性能差距。
通过以上分析,可以将基于表示的模型的缺失交互提取为X和Y之间的MHA操作。为了恢复这种缺失的交互,让基于表征的模型模拟基于交互模型中的交互,如下所示:
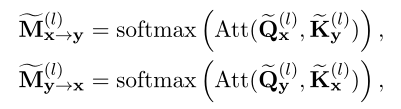
其中表示由attend到生成的注意力图,表示由attend到生成的注意力图。这两个额外的注意力图表示基于表示的模型中缺少的交互信号。
由于希望将基于表征的模型的性能改进为基于交互的模型,因此作者提出将缺失的注意图与其在基于交互的模型中已经存在的对应关系进行对齐。基于交互的模型中的注意图可以指导表征(即和)朝着交互丰富的方向发展,就好像表示在编码过程中相互作用一样。通过这种方式,在交互过程中提取知识,并将其传输到双编码器中,而不需要任何额外的计算开销。这就是为什么称这种机制为“虚拟交互”。
为了实现VIRT,作者采用了知识蒸馏技术,其中一个经过训练的基于交互的模型被视为教师,一个需要训练的基于表示的模型被视为学生。和对应基于交互的模型中X和Y之间的交互。他们可以直接从softmax(·)之前的注意力分数中得到:是的前m行和最后n列部分,对应于最后n行和前m列。除了softmax操作之外,作者还直接挑选这两个切片,以从基于交互的模型中形成引导注意图:
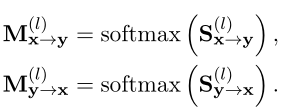
作为有监督的交互知识进一步转移,以指导VIRT。具体来说,目标是最小化和的L2距离:
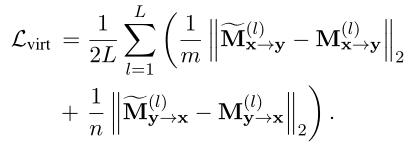
仅在训练阶段将上述公式作为优化目标,并在推理期间将其删除。这保留了基于表示的模型的孪生属性,同时不会带来额外的推理成本。
3.4 VIRT-Adapted Interaction
通过VIRT,交互知识可以深入到基于表示的模型的每个编码层中。然而,在孪生编码后,最后一层的表示,即和,仍然无法看到对方,因此缺乏明确的交互。为了充分利用所学的交互知识,作者进一步设计了一种适应VIRT的交互策略,该策略在VIRT学习的注意力图的指导下融合了和。
具体而言,作者在以下过程中执行和之间的VIRT适应交互。生成的注意图公式如下:
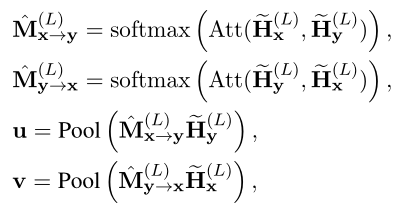
其中Pool(·)表示平均池化操作。最后,利用简单融合预测匹配标签y:
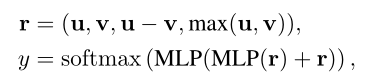
其中是concat操作,MLP表示多层感知机。总体训练目标是将特定任务的监督损失(即交叉熵损失)和的组合降至最低:
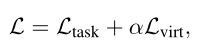
其中α是衡量虚拟交互影响的超参数。
值得注意的是,VIRT是一种通用策略,可用于增强任何基于表示的匹配模型。
04
实验
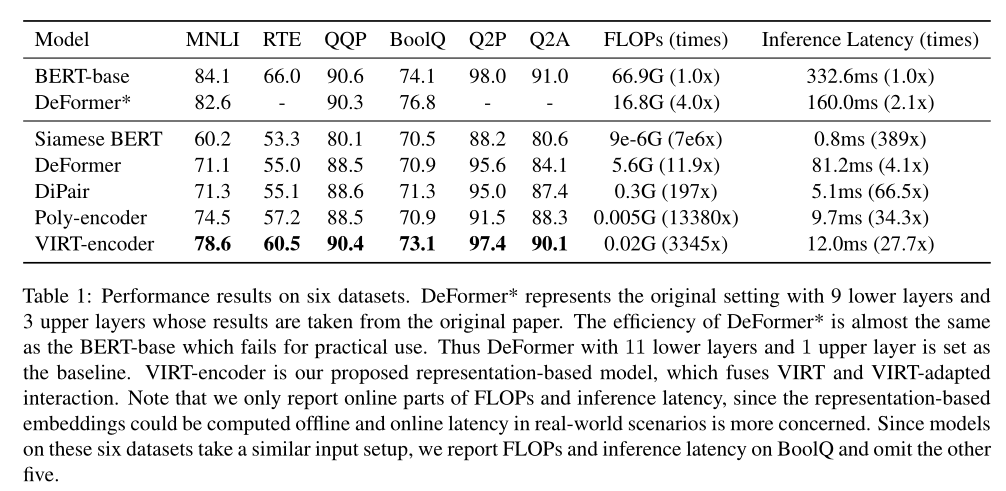
不同方法的性能如上表所示。BERT-base作为一个强大的基于交互的模型,显示了它的有效性。与BERT相比,Siamese BERT的性能显著下降。本文提出的VIRT编码器实现了最好的性能,优于所有基于表示的baseline,甚至与基于交互的BERT模型相比具有竞争力。这证明VIRT能够近似基于交互的模型的深度交互建模能力。
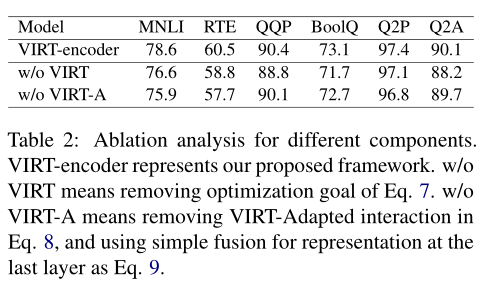
上表显示了本文提出的VIRT以及VIRT适应相互作用的贡献。不使用VIRT或VIRT适应交互的性能下降表明了这两种体系结构的有效性。对于MNLI和RTE,由于移除VIRT适应的交互而导致的性能下降更为严重。
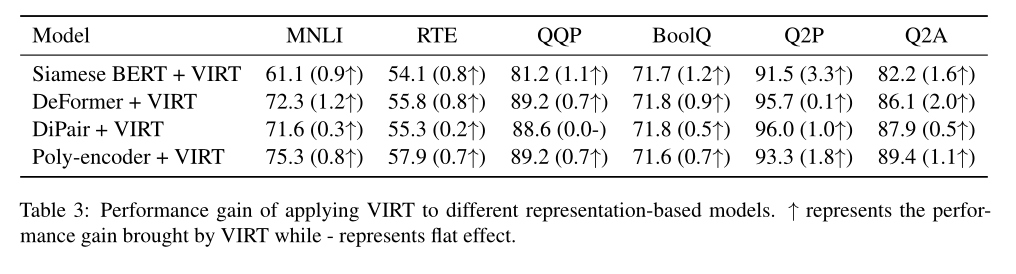
为了验证所提出的VIRT的通用性,作者进一步将其导入到上述基于表示的模型中。结果如上表所示。根据结果,可以观察到VIRT可以很容易地集成到其他基于表示的文本匹配模型中,以进一步提高性能。
05
总结
基于表示的模型因其效率高而被广泛应用于文本匹配任务中,而基于交互的模型由于缺乏交互而性能不佳。以前的工作经常引入额外的交互层,而孪生编码器中的交互仍然缺失。
在本文中,作者提出了一种虚拟交互(VIRT)机制,该机制可以通过从基于交互的模型中提取注意图到基于表示模型的孪生编码器来近似交互建模能力,而无需额外的推理成本。
所提出的VIRT编码器采用VIRT和VIRT适应交互策略,在多个文本匹配任务中实现了现有基于表示的模型的最新性能。此外,VIRT对现有的基于表示的模型进行了进一步的改进。
参考资料
[1]https://arxiv.org/abs/2112.04195

END
加入「计算机视觉」交流群备注:CV

边栏推荐
- Codeforces Round #803 (Div. 2)
- IP, subnet mask, gateway, default gateway
- Redis的五种数据结构
- EasyCVR接入设备开启音频后,视频无法正常播放是什么原因?
- 10 advanced concepts that must be understood in learning SQL
- 模板于泛型编程之declval
- Pytest learning ----- detailed explanation of the request for interface automation test
- 中移动、蚂蚁、顺丰、兴盛优选技术专家,带你了解架构稳定性保障
- 1700C - Helping the Nature
- FlutterWeb瀏覽器刷新後無法回退的解决方案
猜你喜欢

李书福为何要亲自挂帅造手机?

RB157-ASEMI整流桥RB157
What is the reason why the video cannot be played normally after the easycvr access device turns on the audio?
面试突击62:group by 有哪些注意事项?
Distinguish between basic disk and dynamic disk RAID disk redundant array

Unity粒子特效系列-闪星星的宝箱
虚拟机VirtualBox和Vagrant安装

递归的方式
第三季百度网盘AI大赛盛夏来袭,寻找热爱AI的你!
Olivetin can safely run shell commands on Web pages (Part 1)
随机推荐
趣-关于undefined的问题
HMS core machine learning service creates a new "sound" state of simultaneous interpreting translation, and AI makes international exchanges smoother
编译原理——预测表C语言实现
Transfer data to event object in wechat applet
Sqoop I have everything you want
Alertmanager sends the alarm email and specifies it as the Alibaba mailbox of the company
第三季百度网盘AI大赛盛夏来袭,寻找热爱AI的你!
QT中Model-View-Delegate委托代理机制用法介绍
Pytest learning ----- pytest confitest of interface automation test Py file details
Unity tips - draw aiming Center
Interview shock 62: what are the precautions for group by?
Open source and safe "song of ice and fire"
Codeforces Round #803 (Div. 2)
Kill -9 system call used by PID to kill process
Take you through ancient Rome, the meta universe bus is coming # Invisible Cities
Alibaba brand data bank: introduction to the most complete data bank
面向程序员的精品开源字体
VR panoramic wedding helps couples record romantic and beautiful scenes
Summary of Android interview questions of Dachang in 2022 (I) (including answers)
Nodejs developer roadmap 2022 zero foundation Learning Guide