当前位置:网站首页>Graph node classification and message passing
Graph node classification and message passing
2020-11-09 07:30:00 【osc_gnljjuu】

Message passing and node classification

This article mainly solves the problem :
Given a network , Some of these nodes have label, How to assign other nodes to corresponding nodes label Well ? ( There are many examples of this in life , For example, through interactive behavior to determine whether the user is a fleece party ) Intuitively, we will consider the connection between network nodes , The model to be learned in this article is collective classification:
There are three specific methods involved :
- Relational classification;
- Iterative classification;
- Belief propagation;
Relational classification
Correlations Exists In Network
The behavior of nodes in the network is corrlated, There are three kinds of :
- Homophily: Nodes with the same properties may have more network connections , If you have the same music hobby, it's easier to be in the same forum ;
- Influence: The characteristics of one node may be influenced by other nodes , If I recommend music albums that I am interested in to my friends , Some of my friends are likely to become as interested in these albums as I am ;
- Confounding: The environment can affect the characteristics of nodes and the connections between nodes ;
Classification with network data
Motivation
Similar nodes are usually connected to each other in the network , Or the connection is tight ; and ”Guilt-by-association“: Association inference is to consider this part of information to infer the type of nodes in the network ; Therefore, the network node type judgment mainly through the following three sources of characteristics :
- The characteristics of the node itself ;
- Nodes are connected to neighbors label;
- The characteristics of nodes' neighbors ;
Guilt-by-association
"Guilt-by-association" It's better to define , Here's the picture , Given Graph And a small amount of label The node of , How to label the remaining nodes as corresponding label, requirement : The network has homogeneity :
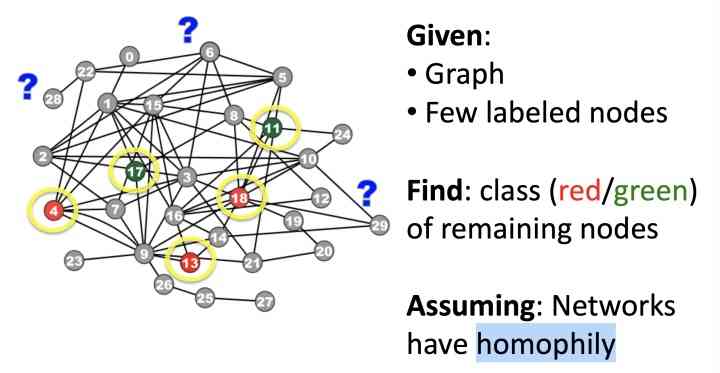
Mathematical modeling of the problem is carried out : Given the adjacency matrix W, The size is n*n, as well as Y Corresponding to node label,1 by positive node ,-1 position negative node , 0 position unlabeled node , forecast unlabeled In the node of postive Probability . Here's the Markov hypothesis : Node label type , Depending only on the connected nodes label type :
Collective classification It usually involves three steps :
- local classifier: Only the node feature information is considered for classification ;
- Relational Classifier: Consider the characteristics and category information of node neighbors ;
- collective inference: take Relational Classifier Apply to every node , Until the whole network ”inconsistency“ To minimize the ;
Probabilistic Relational Classifier
Probabilistic Relational Classifier The basic idea is simple , The probability of each node class is the weighted average of its neighboring nodes , The specific process is as follows :
- For tagged data , Label the class table of nodes as label;
- For data without labels , Initialize its class randomly ;
- Then the adjacent nodes are weighted in random order , Until the whole network converges or reaches the maximum number of iterations :
among It's a node i And nodes j The connection weight of .
There are two problems with this model :
- There is no guarantee that the model will converge ;
- The model does not use the feature information of nodes ;
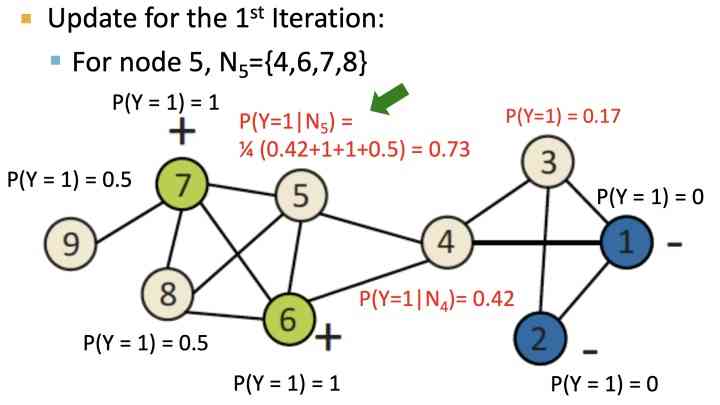
Pictured above , For the initialized node , Press label Adjacent nodes are used to calculate the weight , Get the probability of node type , Until it converges : after 5 After the iteration :
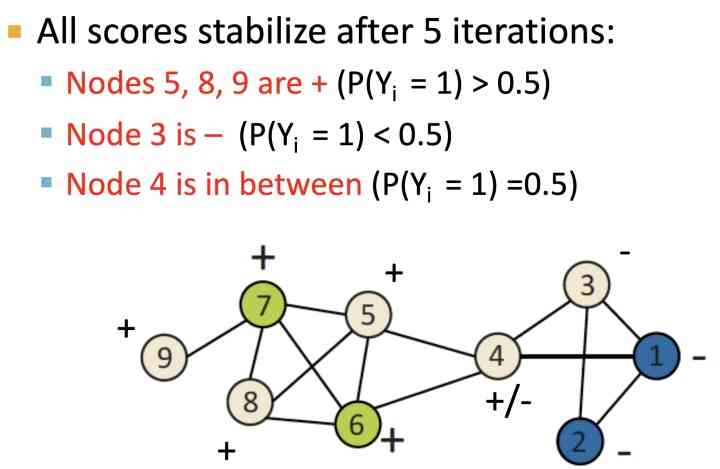
Iterative Classifier
Iterative Classifier That is, the iterative process after adding node features , There are two main processes :
- Bootstrap Phase: The nodes i Express by its characteristics , Use local classifier To calculate the... Of each node label probability ;
- Iteration Phase: Repeat for each node in the network , Update node characteristics and press local classifier Classify the node , until label Stable ;
In the video tutorial , One example is the use of Iterative Classifier By considering network structure information fake review detection Of , I suggest that you can read the paper in detail : REV2_Fraudulent_User_Prediction_in_Rating_Platforms
Collective Classification
Belief Propagation It's a dynamic planning process , Through nodes passing message The means of , It is mainly used to solve the problem of conditional probability in graphs .
Message Passing
Take an example to explain message passing The process of :
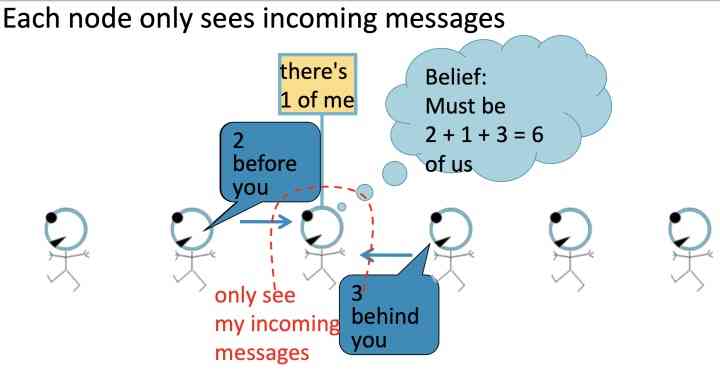
Given the task : Count the number of nodes in the graph , Each node can only interact with its neighbors
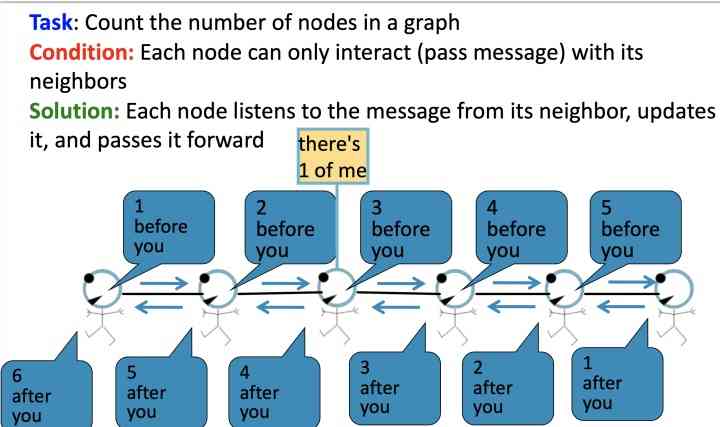
Pictured above , Each node listens for information from its neighbors , And then update the information , And pass it forward , Here's the picture , Nodes marked with a red circle can only receive incoming messages:
- 2 nodes before you;
- 3 nodes behind you:
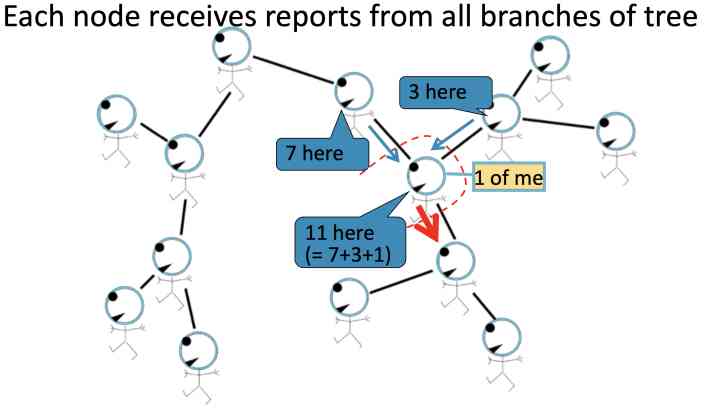
In a slightly more complex tree Type graph To show :
Loopy Belief Propagation
To make it clear , Here's a basic definition :
- Label-Label potential matrix
: Representation node i It's a category
Under the condition of , Its adjacent nodes j For the category
Probability ;
- prior belief
: Representation node i For the category
: node i Predict its adjacent nodes j For state
It's easy to understand : The formula considers nodes i by The prior probability of ψ, According to the state transition matrix, the nodes are obtained j by
, At the same time, all the information transmitted by neighbor nodes is considered
, Random order iterations , Until the final state is stable , Get the node i For the category Y_{i}Yi Probability :
Consider nodes , Doing it message passing when , In fact, there is no way to judge whether there is cycle, therefore LBP In case of cycles It's just a matter of some questions , Here's the picture , There's a little bit of confusion here , If you have any understanding, please discuss in the comments section :
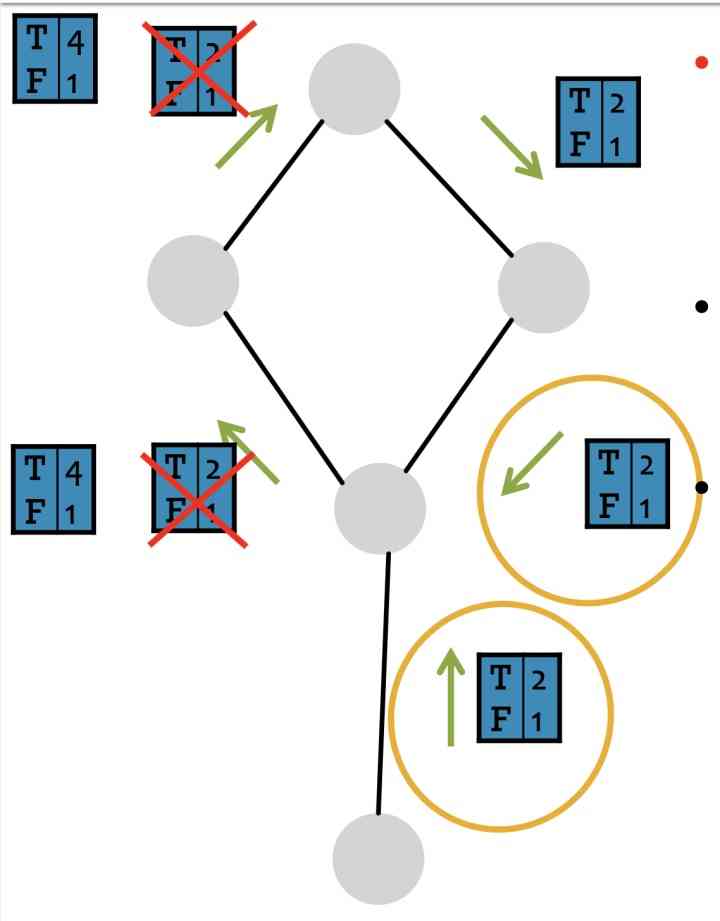
LBP The advantages and disadvantages are as follows :
- advantage :
- Implement a simple , It's easy to parallelize ;
- It's universal , Apply to all graph models ;
- Challenge :
- There is no guarantee of convergence , Especially with a lot of closed connections ;
- Potential function :
- It needs magic training ;
- Training learning is based on gradient optimization , There may be a bracelet problem during training ;
Summary
This article is based on cs224w Learning to organize , In this paper, we mainly introduce in node classification There are three classic ways to deal with it :Relational classification、Iterative Classifier、Collective Classification, Introduces the classic solution , Such as Probabilistic Relational Classifier、Message Passing, There are several cases in the article , Because the time is not sorted out , Learn the tutorial in this chapter , And related paper, node classification It's classic graph The problem of , It's used in many anti fraud cases .
版权声明
本文为[osc_gnljjuu]所创,转载请带上原文链接,感谢
边栏推荐
- 14.Kubenetes简介
- B. protocal has 7000eth assets in one week!
- AQS 都看完了,Condition 原理可不能少!
- 失业日志 11月5日
- C++之异常捕获和处理
- File queue in Bifrost (1)
- 亚马逊的无服务器总线EventBridge支持事件溯源 - AWS
- Have you ever thought about why the transaction and refund have to be split into different tables
- python生日贺卡制作以及细节问题的解决最后把python项目发布为exe可执行程序过程
- Copy on write collection -- copyonwritearraylist
猜你喜欢

随机推荐
VIM 入门手册, (VS Code)
How does FC game console work?
C + + adjacency matrix
EasyNTS上云网关设备在雪亮工程项目中的实战应用
python生日贺卡制作以及细节问题的解决最后把python项目发布为exe可执行程序过程
首次开通csdn,这篇文章送给过去的自己和正在发生的你
File queue in Bifrost (1)
Do you know how the computer starts?
1.操作系统是干什么的?
How to do thread dump analysis in Windows Environment
Service grid is still difficult - CNCF
Several common playing methods of sub database and sub table and how to solve the problem of cross database query
服务网格仍然很难 - cncf
First development of STC to stm32
Leetcode-15: sum of three numbers
Bifrost 之 文件队列(一)
C++邻接矩阵
How does semaphore, a thread synchronization tool that uses an up counter, look like?
How to analyze Android anr problems
为什么我们不使用GraphQL? - Wundergraph