Advertising business 1 More than years , But the usual work is mainly with Advertising Engineering of , The core advertising algorithm consists of AI Department support , For us, it can be said that 「 Black box 」 The existence of , Just call the trained model .
In the near future , I plan to systematically study the search and recommendation algorithms in advertising , Of course, more from the perspective of engineering to clarify : The basic principle of the algorithm 、 And how the algorithm solves the performance problem in the face of line data ? The whole process , I will output valuable technical points into a series of articles .
This article belongs to the introduction of recommendation system , This paper does not consider the massive data in the online environment , The purpose is to understand the basic structure of the recommendation system , I will recommend algorithms and programs through diagrams demo In the form of , The content includes :
01 Into the world of recommendation systems
“ Beer and diapers ” I believe many people have heard of it , When young dad goes to the supermarket to buy diapers , I often buy some beer to reward myself . therefore , Wal Mart bundled the two products , In the end, we got better sales .

The theoretical basis behind this story is “ Recommendation algorithm ”, Because diapers and beer often appear in the same shopping cart , So it makes sense to recommend beer to young dads who buy diapers .
1、 What the recommendation system is solving ?
Recommend system from 20 century 90 The age was put forward , But it really enters the public view and becomes popular among the major Internet companies , Or in recent years .
With the development of mobile Internet , More and more information is beginning to spread on the Internet , There's a serious information overload . therefore , How to find the information that users are interested in from a lot of information , This is the value of the recommendation system . Accurate recommendation solves user pain points , Improved user experience , In the end, you can keep users .
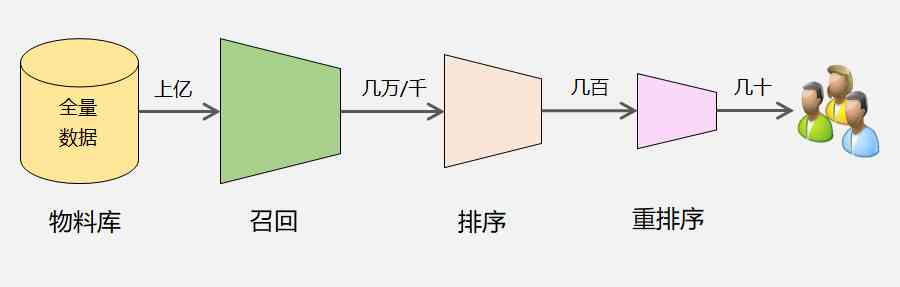
Recommendation system is essentially an information filtering system , Usually divided into : Recall 、 Sort 、 Reorder this 3 A link , Each link is filtered layer by layer , Finally, dozens of items that users may be interested in are selected from the massive material warehouse and recommended to users .
2、 Application scenarios of recommendation system
Where is the mass information , There are recommendation systems everywhere , What we use most every day APP It's all about recommendation :
Information class : Today's headline 、 Tencent News, etc
E-commerce : TaoBao 、 JD.COM 、 A lot of spelling 、 Amazon, etc.
Entertainment : Tiktok 、 Well quickly 、 Iqiyi, etc
Life service : Meituan 、 Public comment 、 Ctrip, etc
Social class : WeChat 、 Mo Mo 、 Pulse, etc
The application scenarios of recommendation system are usually divided into the following two categories :
-
Recommendation based on user dimension : Make recommendations based on users' historical behaviors and interests , For example, Taobao home page guess you like 、 Tiktok recommendation, etc. .
-
Recommendation based on item dimension : Recommend according to the subject matter the user is currently browsing , For example, open Jingdong APP Product details page , Will recommend products related to the main product to you .
3、 Search for 、 recommend 、 The similarities and differences of advertising
Search and recommendation are AI The two most common application scenarios of the algorithm , There are similarities in technology . It's about advertising , The main consideration is that many students who have never done advertising business don't know why advertising and searching 、 Recommendation will matter , So explain .
-
Search for : Have clear search intention , The search results are related to the user's search words .
-
recommend : Not purposeful , Personalized recommendation depends on user's historical behavior and portrait data .
-
advertisement : With the help of search and recommendation technology to achieve accurate advertising , Advertising can be understood as an application scenario of search recommendation , More complex technical solutions , It's about intelligent budget control 、 Advertising bidding, etc .
02 The overall architecture of the recommendation system
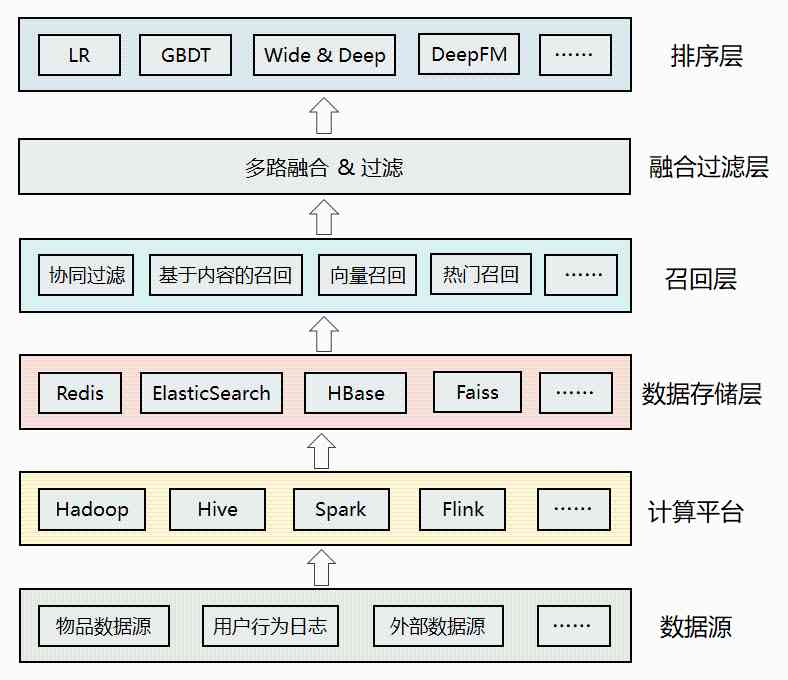
Above is the overall architecture of the recommendation system , It's divided into layers from bottom to top , The main functions of each layer are as follows :
-
data source : The various data sources on which the recommendation algorithm depends , Include item data 、 User data 、 Behavior log 、 Other available business data 、 Even data outside the company .
-
Computing platform : Responsible for cleaning the underlying heterogeneous data 、 machining , Offline computing and real-time computing .
-
Data storage layer : Store the data processed by the computing platform , It can be landed on different storage systems as needed , such as Redis User profile and user profile data can be stored in ,ES Can be used to index item data in ,Faiss Can store users or items in embedding Vector, etc .
-
Recall layer : Including various recommendation strategies or algorithms , For example, the classic collaborative filtering , Content based recall , Recall based on vector , Popular recommendation for the base, etc . In order to cope with the high concurrency of online traffic , Recall results are usually pre calculated , After the inverted index is established, it is stored in the cache .
-
Fusion filter layer : Trigger multiple recall , Since each callback source in the recall layer will return a candidate set , So this layer needs to be fused and filtered .
-
Sort layer : Using machine learning or deep learning models , And a richer set of features to reorder , Screening out smaller 、 A more accurate set of recommendations is returned to the upper business .
From the data storage layer to the recall layer 、 Then to the fusion filter layer and sorting layer , The candidate set is reduced layer by layer , But accuracy is getting higher and higher , Therefore, it also brings about a layer by layer increase in computational complexity , This is the biggest challenge of the recommendation system .
In fact, for recommendation engines , The core part is mainly two pieces : Features and algorithms .
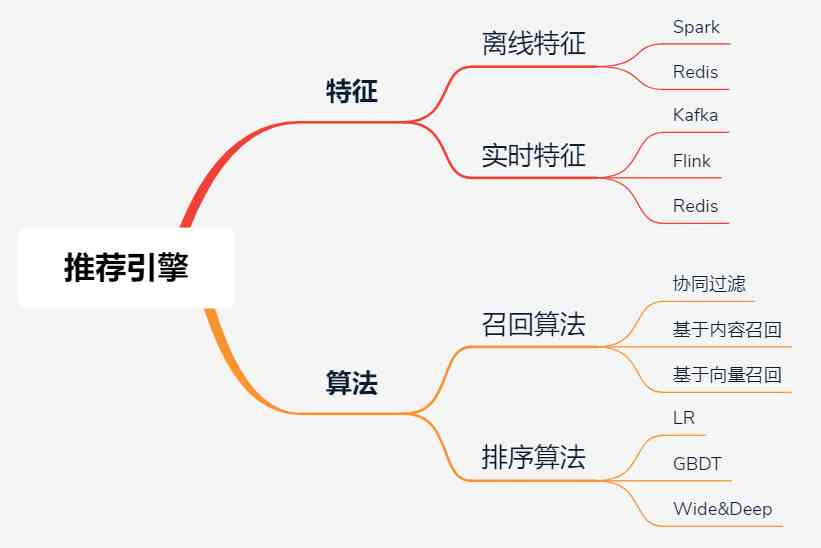
Because of the large amount of data , The offline and real-time processing technology of big data is usually adopted , image Spark、Flink etc. , Then save the calculation results in Redis Or other storage systems ( such as HBase、MongoDB perhaps ES), For recall and sorting modules .
The function of recall algorithm is : Quickly get a batch of candidate data from massive data , The requirements are fast and as accurate as possible . This layer usually has rich strategies and algorithms , To ensure diversity , For better recommendation effect , Some algorithms will also be made near real time .
The function of sorting algorithm is : The candidate sets of multiple recall are sorted in detail . It takes advantage of things 、 Users and the cross features between them , And then through the complex machine learning or deep learning model to score and sort , The characteristic of this layer is that the calculation is complex, but the result is more accurate .
03 Illustrate the classic collaborative filtering algorithm
After understanding the overall architecture and technical solutions of the recommendation system , Let's take you in-depth details of the algorithm . The star algorithm in the recommendation system is illustrated here : Collaborative filtering (Collaborative Filtering,CF).
For engineering students , May feel that AI The algorithm is obscure , The threshold is too high , It's true that many deep learning algorithms do , But it's a very simple collaborative filtering algorithm , As long as you have the foundation of junior high school mathematics, you can understand .
1、 What is collaborative filtering ?
The core of collaborative filtering algorithm is 「 Look for similarities 」, It's based on the user's historical behavior ( Browse 、 Collection 、 Comments, etc ), To discover the user's preference for the item , And measure and rate the preferences , Finally, the recommended collection is filtered out . It has two branches :
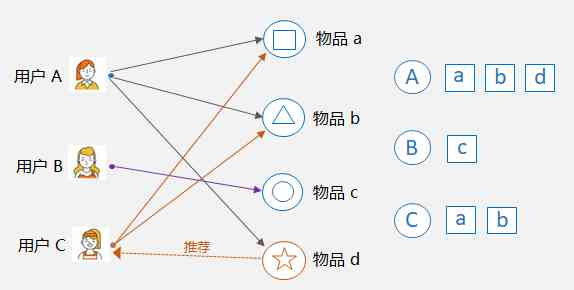
- User based collaborative filtering : User-CF, The core is to find similar people . As shown in the picture below , user A And the user C Have bought things a And objects b, So you could say A and C Is similar to that of , Because they like a lot of things together . such , You can put the user A Items purchased d Recommend to users C .
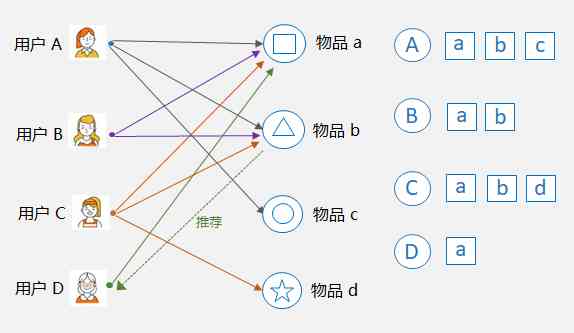
- Collaborative filtering based on items :Item-CF, The core is to find similar objects . As shown in the picture below , goods a And objects b By the user at the same time A,B,C bought , So the object a and goods b Considered to be similar , Because they co-exist a lot . such , If the user D Purchased items a, Then you can combine and items a The most similar items b Recommend to users D.
2、 How to find similarity ?
As mentioned earlier , The core of collaborative filtering is to find similarities ,User-CF It's looking for similarities between users ,Item-CF It's looking for similarities between objects , So how to measure the similarity between two users or items ?
We all know , For two points in coordinates , If the angle between them is smaller , The more similar these two points are , This is the cosine distance I learned in junior high school , Its formula is as follows :
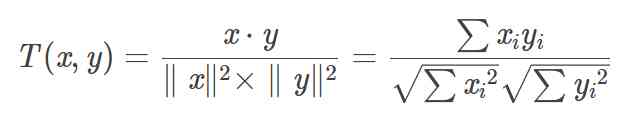
for instance ,A Coordinates are (0,3,1),B Coordinates are (4,3,0), So the cosine distance between these two points is 0.569, The closer the cosine distance is 1, The more similar they are .
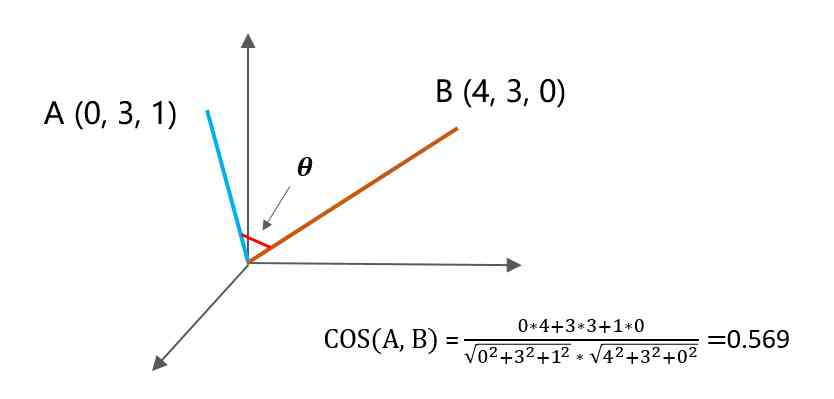
Except for the cosine distance , There are many ways to measure similarity , such as : Euclidean distance 、 Pearson correlation coefficient 、Jaccard Similarity coefficient and so on , There is no expansion here , It's just the difference in the formula .
3、Item-CF Algorithm flow of
When the definition of similarity is clear , Let's say Item-CF For example , In detail, how does this algorithm select recommended items ?
First step : Sort out the co-occurrence matrix of items
Suppose there is A、B、C、D、E 5 Users , Among them, users A Like things a、b、c, user B Like things a、b wait .
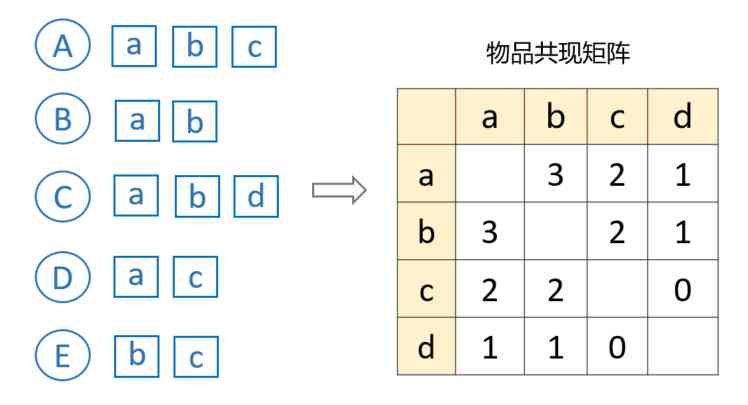
The so-called co-occurrence , namely : Both items are liked by the same user . Such as items a and b, Because they're being used at the same time A、B、C like , therefore a and b The number of CO occurrences is 3, The co-occurrence matrix can be constructed quickly by using this statistical method .
The second step : Calculate the similarity matrix of items
about Item-CF Algorithm , Generally, the cosine distance mentioned above is not used to measure the similarity of objects , Instead, use the following formula :
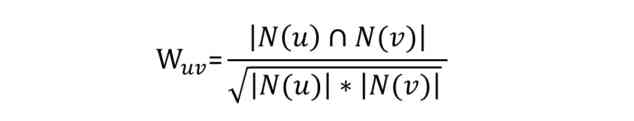
among ,N(u) I like things u Number of users ,N(v) I like things v Number of users , The intersection of the two means that you like things at the same time u And objects v Number of users . Obviously , If two objects are liked by many people at the same time , So the more similar these two objects are .
Based on the first 1 Step 2 to calculate the co-occurrence matrix and the number of people who like each item , Then we can construct the similarity matrix of objects :
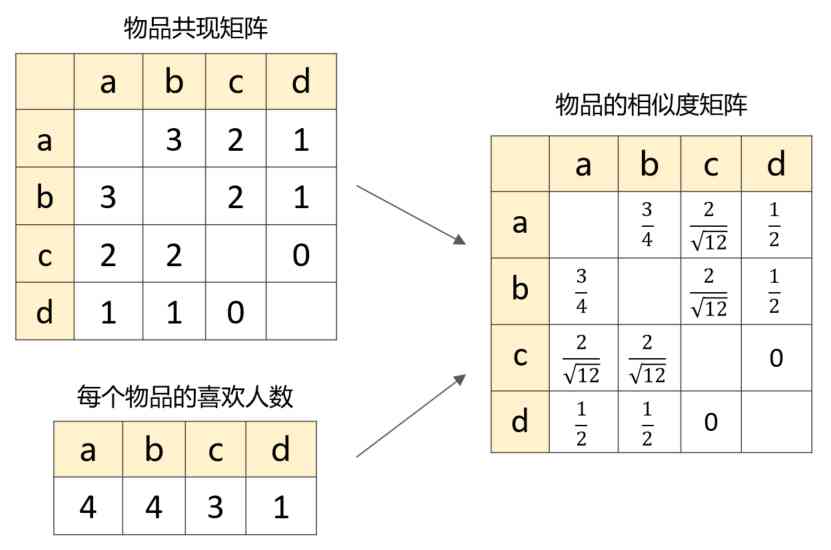
The third step : Recommended items
The last step , Then you can recommend items based on the similarity matrix , The formula is as follows :
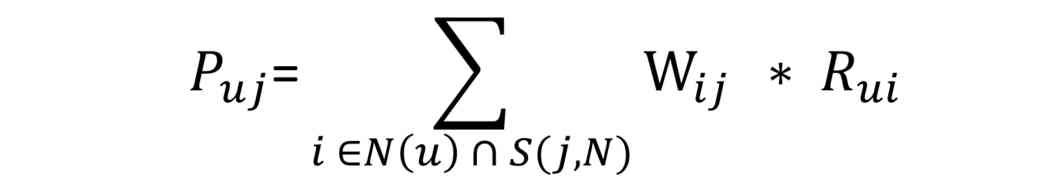
among ,P uj Represent user u For items j Of interest , The bigger the value is. , The more worthy of recommendation .N(u) Represent user u Collection of items of interest ,S(j,N) Presentation and items j The most similar front N Items ,W ij Indicates an item i And objects j The similarity ,R ui Represent user u For items i Of interest .
The above formula is a little abstract , It's easier to understand by looking directly at examples , Suppose I want to give it to users E Recommended items , We already know that users E Like things b And objects c, The degree of liking is assumed to be 0.6 and 0.4. that , Using the above formula, the recommended results are as follows :
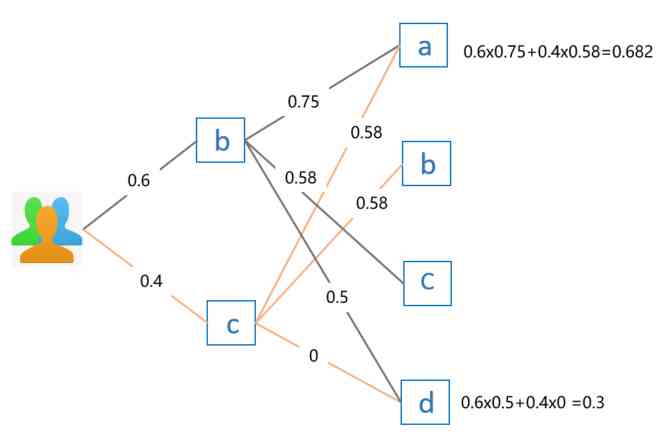
Because of the goods b And objects c Has been used by E I like it , So no repeat recommendation . End user comparison E For items a And objects d Of Be interested in Interest level , because 0.682 > 0.3, So choose recommended items a.
04 from 0 To 1 Build a recommendation system
With the above theoretical basis , We can use it Python Quickly implement a recommendation system .
1、 Choose a dataset
This is the classic recommendation field MovieLens Data sets , It's a data set of movie ratings , There are many different sizes of versions available on the official website , Let's say ml-1m Data sets ( about 100 Ten thousand user rating records ) For example .
Download after decompression , The folder contains :ratings.dat、movies.dat、users.dat 3 File , common 6040 Users ,3900 movie ,1000209 Score records . The format of each file is the same , Each row represents a record , Between fields :: Segmentation .
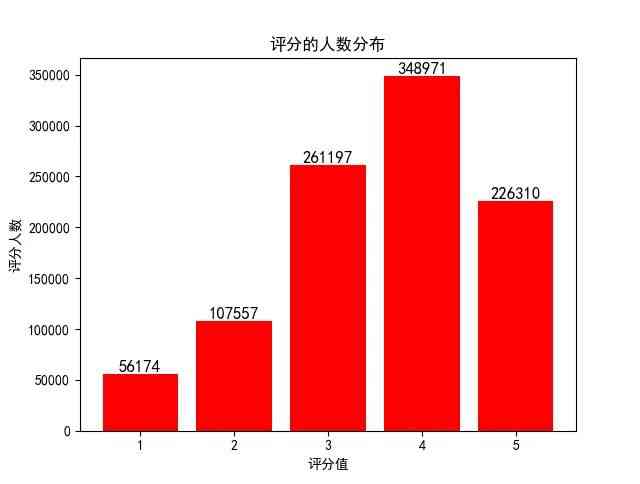
With ratings.dat For example , Each line includes 4 Attributes : UserID, MovieID, Rating, Timestamp. The script can be used to calculate the distribution of people with different scores :
2、 Read raw data
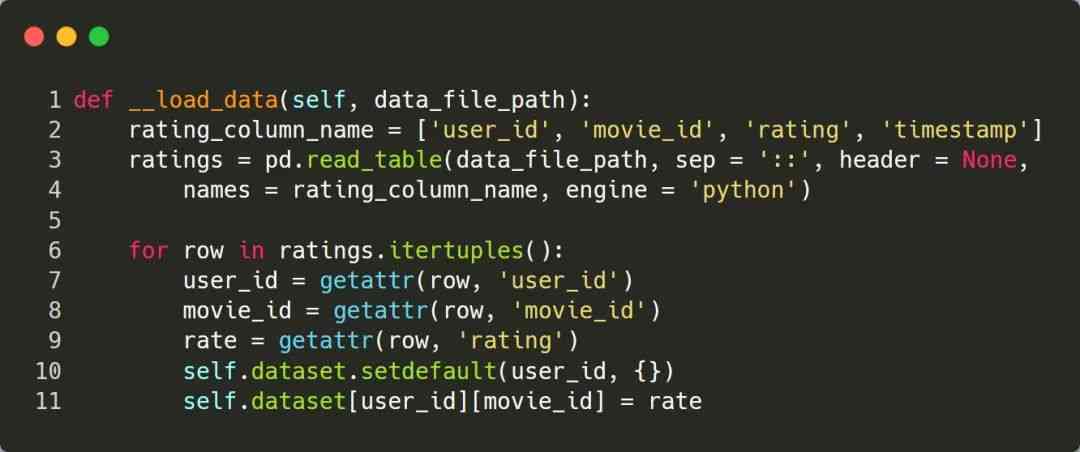
The program mainly uses ratings.dat This file , By parsing the file , Take out user_id、movie_id、rating 3 A field , Finally, the data that the algorithm depends on is constructed , And save it in the variable dataset in , Its format is :dict[user_id][movie_id] = rate
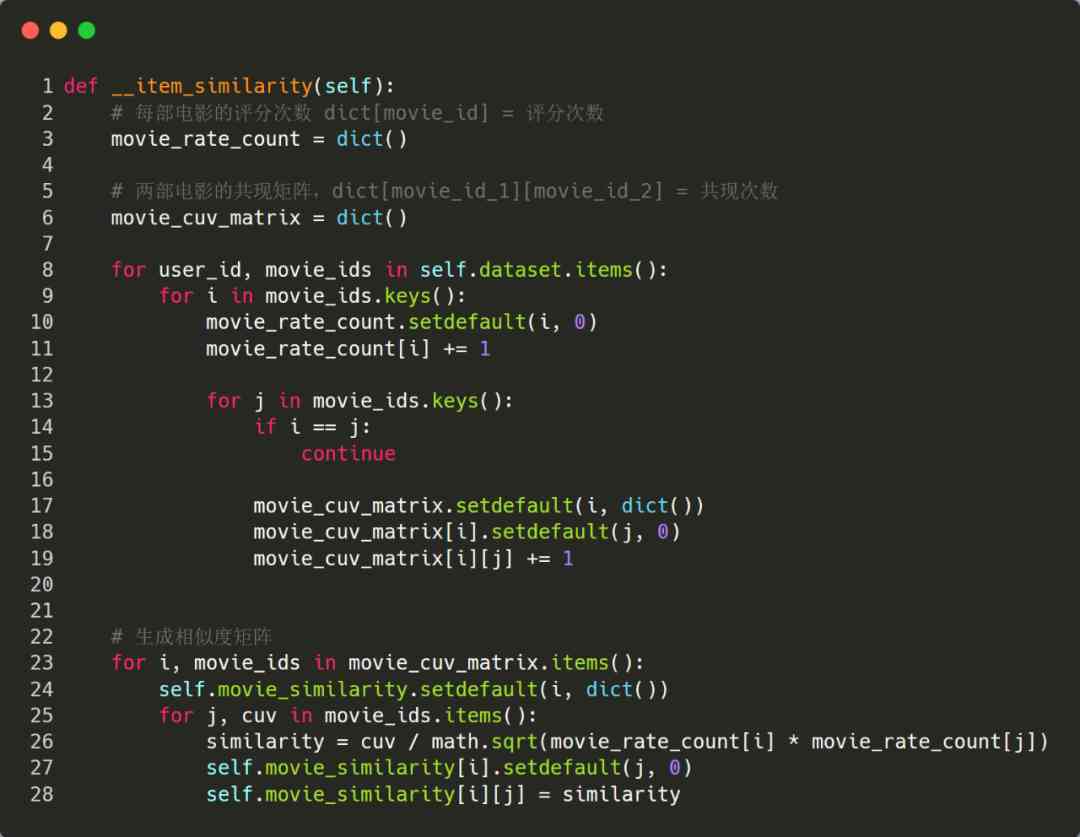
3、 Construct similarity matrix of items
Based on the first 2 Step by step dataset, We can further calculate the rating times of each film and the symbiosis matrix of the film , Then the similarity matrix is generated .
4、 Recommend items based on similarity matrix
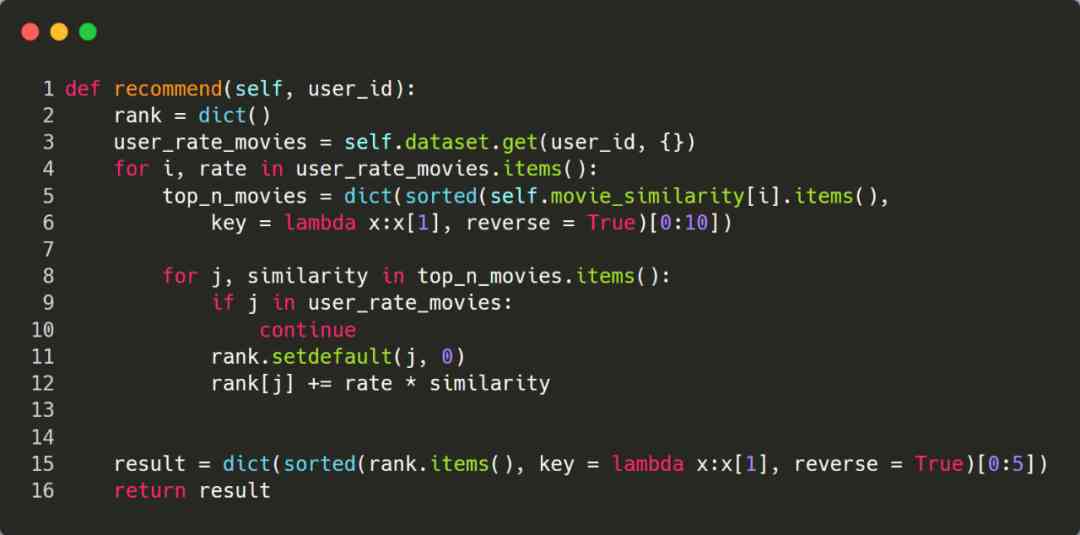
Last , It can be recommended based on the similarity matrix , Enter a user id, First, for the movie that the user has scored , Select in turn top 10 The most similar film , The final score of each candidate film is calculated after weighted sum , Finally, before scoring 5 To recommend the movie .
5、 Recommend system call
Next choice UserId=1 This user , Take a look at the execution of the program . Because the output of the recommended program is movieId list , In order to understand the recommendation results more intuitively , This is converted to the title of the movie for output .
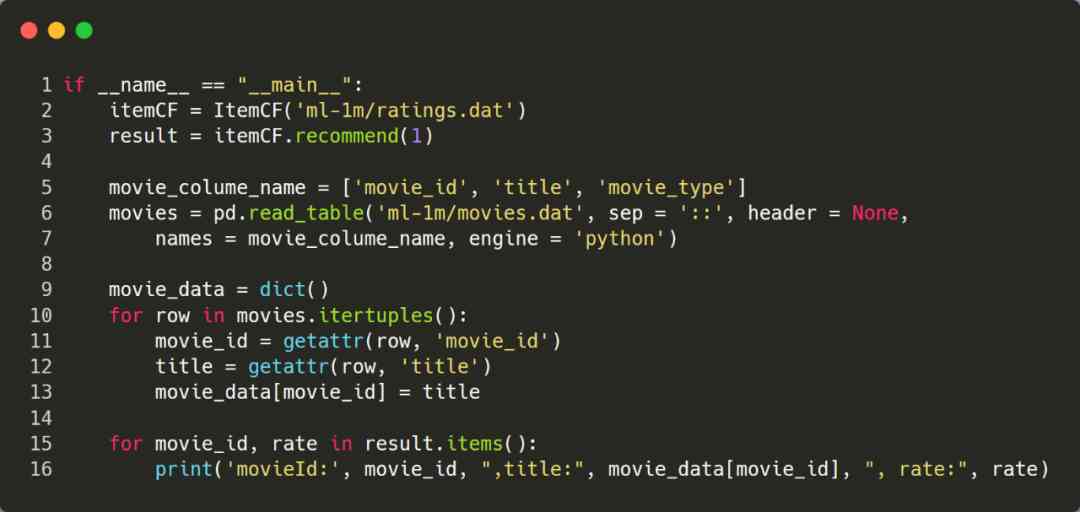
Before final recommendation 5 Movies for :

05 The challenge of online recommendation systems
Through the introduction above , We should have a preliminary understanding of the basic composition of the recommendation system , But when it comes to the real online environment , There will also be many algorithmic and engineering challenges , Absolutely not dozens of lines Python The code can handle it .
1、 The example above uses a standardized dataset , And the data in the online environment is not standardized , So it involves the collection of massive data 、 Cleaning and processing , Finally, the data set that the model can use is constructed .
2、 Complex and cumbersome Feature Engineering , It is said that the upper limit of algorithm model is determined by data and characteristics . For online environments , You need to select the available features from a business perspective , Then clean the data 、 Standardization 、 normalization 、 discretization , The experimental results further verify the effectiveness of the features .
3、 How to reduce the complexity of the algorithm ? Like the above Item-CF Algorithm , The complexity of time and space is O(N×N), And the data of online environment is tens of millions or even hundreds of millions , If you don't do algorithm optimization , Maybe you can't run the data for a few days , Or the memory simply can't put such a large matrix data .
4、 How to satisfy real-time ? Because users' interests change in real time with their latest behavior , If the model is only recommended based on historical data , Maybe the results are not accurate enough . therefore , How to meet the real-time requirements , And how to recommend new items or users , They are all problems to be solved .
5、 The tradeoff between algorithm effect and performance . Seeking diversity and accuracy from the perspective of algorithm , Pursue performance from an engineering point of view , There has to be a balance between the two .
6、 Stability and effect tracking of recommendation system . Need to have a set of perfect data monitoring and application monitoring system , At the same time there is ABTest Gray scale experiment was carried out on the platform , Compare the effect .
At the end
This article is an introduction to the recommendation system , The purpose is to let everyone have an overall understanding of the recommendation system , I will continue to publish some articles later , This paper introduces in detail the specific business and line volume data , How should the recommendation system be designed ?
If needed in the article Item CF Of Python Source code and dataset , Can be downloaded from Baidu online disk :
link : https://pan.baidu.com/s/18-RihJQhnYDxpevEVlP9MQ , Extraction code : cax7
Author's brief introduction :985 master , Former Amazon Engineer , present 58 Transfer to technical director
Welcome to scan the QR code below , Pay attention to my official account :IT People's career advancement