当前位置:网站首页>ETL data cleaning case in MapReduce
ETL data cleaning case in MapReduce
2022-08-03 10:49:00 【QYHuiiQ】
在实际业务场景中,When we process the data, we will first clean the data,For example, filter out some invalid data;Just need to clean the datamap阶段即可,不需要reduce阶段.
In this case, what we want to achieve is that only the department number is left in the employee table datad01的数据.
- 数据准备
001,Tina,d03
002,Sherry,d01
003,Bob,d01
004,Sam,d02
005,Mohan,d01
006,Tom,d03
新建project:
- 引入pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>wyh.test</groupId>
<artifactId>TestETL</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>- 自定义Mapper
package wyh.test;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ETLMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
if("d01".equals(split[2])){
//部门编号为d01,留下
context.write(value, NullWritable.get());
}else{
return;
}
}
}
- 自定义主类
package wyh.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class ETLJobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(super.getConf(), "testETLJob");
//!!!!!!!!!! 集群必须要设置 !!!!!!!!
job.setJarByClass(ETLJobMain.class);
//配置job具体要执行的任务步骤
//指定要读取的文件的路径,这里写了目录,就会将该目录下的所有文件都读取到(这里只需要放employee.txt即可)
FileInputFormat.setInputPaths(job, new Path("D:\\test_hdfs"));
//指定map处理逻辑类
job.setMapperClass(ETLMapper.class);
//指定map阶段输出的k2类型
job.setMapOutputKeyClass(Text.class);
//指定map阶段输出的v2类型
job.setMapOutputValueClass(NullWritable.class);
//由于map端已经把预期的输出结果处理好了,不需要reduce端再处理,所以这里设置reduceTask个数为0
job.setNumReduceTasks(0);
//指定结果输出路径,该目录必须是不存在的目录(如已存在该目录,则会报错),它会自动帮我们创建
FileOutputFormat.setOutputPath(job, new Path("D:\\testETLouput"));
//返回执行状态
boolean status = job.waitForCompletion(true);
//使用三目运算,将布尔类型的返回值转换为整型返回值,其实这个地方的整型返回值就是返回给了下面main()中的runStatus
return status ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
/**
* 参数一是一个Configuration对象,参数二是Tool的实现类对象,参数三是一个String类型的数组参数,可以直接使用main()中的参数args.
* 返回值是一个整型的值,这个值代表了当前这个任务执行的状态.
* 调用ToolRunner的run方法启动job任务.
*/
int runStatus = ToolRunner.run(configuration, new ETLJobMain(), args);
/**
* 任务执行完成后退出,根据上面状态值进行退出,如果任务执行是成功的,那么就是成功退出,如果任务是失败的,就是失败退出
*/
System.exit(runStatus);
}
}
- 运行程序并查看结果
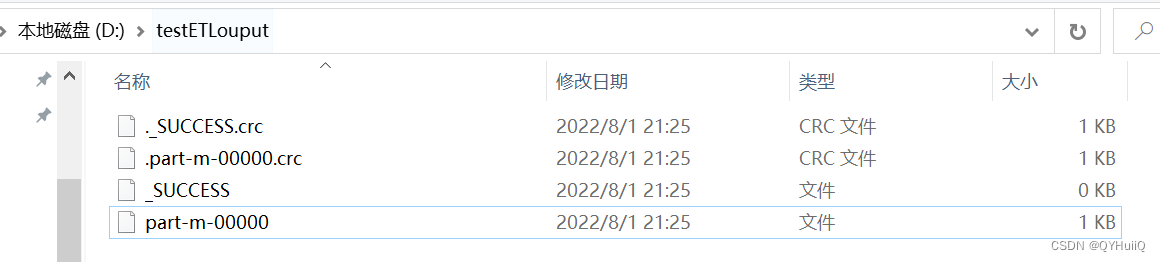
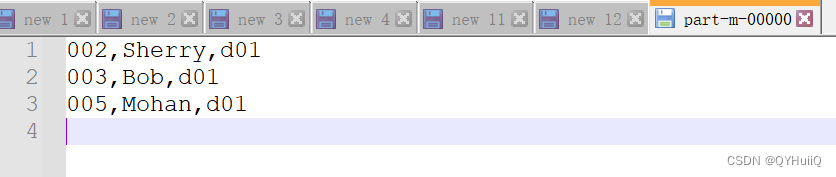
You can see that only the department isd01data remains,符合预期结果.
这样就简单地实现了ETLZhongdi data cleaning process.
边栏推荐
猜你喜欢

Who is more popular for hybrid products, depending on technology or market?

QT with OpenGL(HDR)
Why is the new earth blurred, in-depth analysis of white balls, viewing pictures, and downloading problems

With strong network, China mobile to calculate excitation surging energy network construction

How to use outside the PHP command in the container
在 Chrome 开发者工具里通过 network 选项模拟网站的离线访问模式
Web Server 设置缓存响应字段的一些推荐方案
训练双塔检索模型,可以不用query-doc样本了?明星机构联合发文

MySQL数据库高级使用
MySQL数据库基本使用
随机推荐
Why is the new earth blurred, in-depth analysis of white balls, viewing pictures, and downloading problems
Mysql OCP 74 questions
ECCV2022 | RU&谷歌:用CLIP进行zero-shot目标检测!
QT with OpenGL(HDR)
科普大佬说 | 黑客帝国与6G有什么关系?
投稿有礼,双社区签约博主名额等你赢!
成为优秀架构师必备技能:怎样才能画出让所有人赞不绝口的系统架构图?秘诀是什么?快来打开这篇文章看看吧!...
RecyclerView的item高度自适应
Spinner文字显示不全解决办法
LeetCode第三题(Longest Substring Without Repeating Characters)三部曲之二
白帽黑客与留守儿童破壁对“画”!ISC、中国光华科技基金会、光明网携手启动数字安全元宇宙公益展
从餐桌到太空,孙宇晨的“星辰大海”
oracle计算同、环比
训练双塔检索模型,可以不用query-doc样本了?明星机构联合发文
Boolean 与numeric 无法互转
玉溪卷烟厂通过正确选择时序数据库 轻松应对超万亿行数据
【无标题】函数,对象,方法的区别
Leecode-SQL 1527. 模糊查询匹配(模糊查询用法)
机器学习概述
With strong network, China mobile to calculate excitation surging energy network construction