当前位置:网站首页>Mmsegmentation series training and reasoning their own data set (3)
Mmsegmentation series training and reasoning their own data set (3)
2022-07-02 02:49:00 【qq_ forty-one million six hundred and twenty-seven thousand six】
1、 Prepare the data directory structure
mstsc
VOCdevkit
│ │ ├── VOC2012
│ │ │ ├── JPEGImages( Original image )
│ │ │ ├── SegmentationClass( Mask image )
│ │ │ ├── ImageSets
│ │ │ │ ├── Segmentation( Data partitioning )
2、 Download pre training model
3、 Modify the configuration file (deeplabv3plus_r50-d8_512x512_40k_voc12aug.py)
1、 Set the number of modified categories ( Model schema configuration file deeplabv3plus_r50-d8_512x512_40k_voc12aug.py)
_base_ = [
'../_base_/models/deeplabv3plus_r50-d8.py',
'../_base_/datasets/pascal_voc12_aug.py', '../_base_/default_runtime.py',
'../_base_/schedules/schedule_40k.py'
]
model = dict(
decode_head=dict(num_classes=21), auxiliary_head=dict(num_classes=21))# Modify according to your own data
2、 Modify data information ( data type 、 Data main path, etc. and batch-size)(…/base/datasets/pascal_voc12_aug.py、pascal_voc12.py)
# dataset settings
dataset_type = 'PascalVOCDataset' # Modify the data type as needed
data_root = 'data/VOCdevkit/VOC2012' # Modify the data master path as needed
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=4, # Modify according to hardware device
workers_per_gpu=4,
train=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages', # Similarly, modify the data as needed
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/train.txt',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=test_pipeline))
_base_ = './pascal_voc12.py'
# dataset settings, Because we didn't Aug So the data is frequently turned off
#data = dict(
# train=dict(
# ann_dir=['SegmentationClass', 'SegmentationClassAug'],
#split=[
# 'ImageSets/Segmentation/train.txt',
# 'ImageSets/Segmentation/aug.txt'
# ]))
important : The default learning rate in the configuration file is 4 gpu and 2 img/gpu( Batch size = 4x2 = 8). similarly , You can also use 8 gpu and 1 imgs/gpu, Because all models use cross_gpu SyncBN.
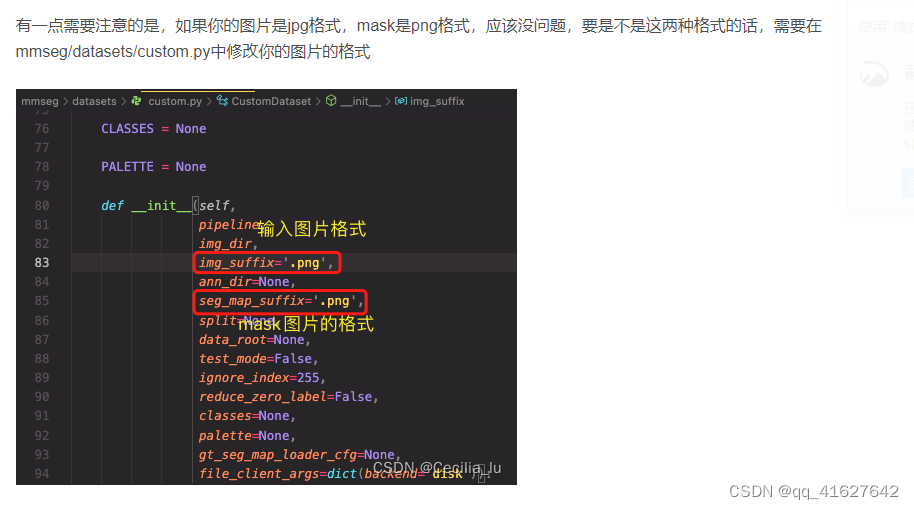
3、 Modify the category name CLASSES(mmseg/datasets/voc.py)
class PascalVOCDataset(CustomDataset):
"""Pascal VOC dataset.
Args:
split (str): Split txt file for Pascal VOC.
"""
CLASSES = ('background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle',
'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa',
'train', 'tvmonitor') # Change to your own data category
4、 Modify the operation information configuration ( Load pre training model and breakpoint training )(configs/-base-/default_runtime.py)
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook', by_epoch=False),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None # You can load the pre training model
resume_from = None # You can load the breakpoint training model
workflow = [('train', 1)]
cudnn_benchmark = True
5、 Modify the operation information configuration ( The maximum number of model training 、 Keep one every few times during training checkpoints、 How many times is the interval between model training , The index of model training evaluation is 、 Keep the best model )(configs/-base-/schedule_40k.py)
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
optimizer_config = dict()
# learning policy
lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
# runtime settings
runner = dict(type='IterBasedRunner', max_iters=40000)#
checkpoint_config = dict(by_epoch=False, interval=4000)
evaluation = dict(interval=4000, metric='mIoU')#save_best='auto'
6、 Model information modification (tiicks)(configs/base/models)
Different Learning Rate(LR) for Backbone and Heads
n MMSegmentation, you may add following lines to config to make the LR of heads 10 times of backbone.
optimizer=dict(
paramwise_cfg = dict(
custom_keys={
'head': dict(lr_mult=10.)}))
Online Hard Example Mining (OHEM)
We implement pixel sampler here for training sampling. Here is an example config of training PSPNet with OHEM enabled.
_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
model=dict(
decode_head=dict(
sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=100000)) )
Class Balanced Loss
For dataset that is not balanced in classes distribution, you may change the loss weight of each class. Here is an example for cityscapes dataset.
_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
model=dict(
decode_head=dict(
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
# DeepLab used this class weight for cityscapes
class_weight=[0.8373, 0.9180, 0.8660, 1.0345, 1.0166, 0.9969, 0.9754,
1.0489, 0.8786, 1.0023, 0.9539, 0.9843, 1.1116, 0.9037,
1.0865, 1.0955, 1.0865, 1.1529, 1.0507])))
Multiple Losses
For loss calculation, we support multiple losses training concurrently. Here is an example config of training unet on DRIVE dataset, whose loss function is 1:3 weighted sum of CrossEntropyLoss and DiceLoss:
_base_ = './fcn_unet_s5-d16_64x64_40k_drive.py'
model = dict(
decode_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
auxiliary_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce',loss_weight=1.0),
dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
)
Ignore specified label index in loss calculation
In default setting, avg_non_ignore=False which means each pixel counts for loss calculation although some of them belong to ignore-index labels.
For loss calculation, we support ignore index of certain label by avg_non_ignore and ignore_index. In this way, the average loss would only be calculated in non-ignored labels which may achieve better performance, and here is the reference. Here is an example config of training unet on Cityscapes dataset: in loss calculation it would ignore label 0 which is background and loss average is only calculated on non-ignore labels:
_base_ = './fcn_unet_s5-d16_4x4_512x1024_160k_cityscapes.py'
model = dict(
decode_head=dict(
ignore_index=0,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0, avg_non_ignore=True),
auxiliary_head=dict(
ignore_index=0,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0, avg_non_ignore=True)),
))

4、 Model training
1、Train with a single GPU
python tools/train.py ${CONFIG_FILE} [optional arguments]
If you want to specify the working directory in the command , You can add a parameter --work-dir ${YOUR_WORK_DIR}
python tools/train.py configs/deeplabv3plus/deeplabv3plus_r50-d8_512x512_20k_voc12aug.py --work-dir work_dirs/runs/train/deeplabv3plus
2、Train with multiple GPUs
sh tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
1
–no-validate (not suggested): By default, the codebase will perform evaluation at every k iterations during the training. To disable this behavior, use --no-validate.
–work-dir ${WORK_DIR}: Override the working directory specified in the config file.
–resume-from ${CHECKPOINT_FILE}: Resume from a previous checkpoint file (to continue the training process).
–load-from ${CHECKPOINT_FILE}: Load weights from a checkpoint file (to start finetuning for another task).
–deterministic: Switch on “deterministic” mode which slows down training but the results are reproducible.
5、 Print and plot the model training log
#Plot training logs
tools/analyze_logs.py plots loss/mIoU curves given a training log file
python tools/analyze_logs.py xxx.log.json [--keys ${KEYS}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
Plot the mIoU, mAcc, aAcc metrics.
python tools/analyze_logs.py log.json --keys mIoU mAcc aAcc --legend mIoU mAcc aAcc
Plot loss metric.
python tools/analyze_logs.py log.json --keys loss --legend loss
6、 Model test
single-gpu testing
# Single model test
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show]
# Multiple model tests
/tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}]
./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth 4 --out results.pkl --eval mIoU cityscapes
./tools/dist_test.sh \
configs/cityscapes/mask_rcnn_r50_fpn_1x_cityscapes.py \
checkpoints/mask_rcnn_r50_fpn_1x_cityscapes_20200227-afe51d5a.pth \
8 \
--format-only \
--options "txtfile_prefix=./mask_rcnn_cityscapes_test_results"
error
MMSeg error :RuntimeError: Default process group has not been initialized
边栏推荐
- 2022-2028 global wood vacuum coating machine industry research and trend analysis report
- 2022-2028 global military computer industry research and trend analysis report
- Summary of some experiences in the process of R & D platform splitting
- Pat a-1165 block reversing (25 points)
- Divorce for 3 years to discover the undivided joint property, or
- After marriage
- The wave of layoffs in big factories continues, but I, who was born in both non undergraduate schools, turned against the wind and entered Alibaba
- What are the characteristics of common web proxy IP
- Which brand of sports headset is better? Bluetooth headset suitable for sports
- A list of job levels and salaries in common Internet companies. Those who have conditions must enter big factories. The salary is really high
猜你喜欢

Golang configure export goprivate to pull private library code

Infix expression to suffix expression (computer) code
Face++ realizes face detection in the way of flow

Pat a-1165 block reversing (25 points)
![[staff] pitch representation (bass clef | C1 36 note pitch representation | C2 48 note pitch representation | C3 60 note pitch representation)](/img/98/956d8abbccceb1aae47e25825bc63d.jpg)
[staff] pitch representation (bass clef | C1 36 note pitch representation | C2 48 note pitch representation | C3 60 note pitch representation)

2022-2028 global encryption software industry research and trend analysis report
![[staff] diacritical mark (ascending sign | descending sign B | double ascending sign x | double descending sign BB)](/img/96/8c4baa1dd8e35e2cab67461e7c447b.jpg)
[staff] diacritical mark (ascending sign | descending sign B | double ascending sign x | double descending sign BB)

As a software testing engineer, will you choose the bank post? Laolao bank test post

Remote connection to MySQL under windows and Linux system
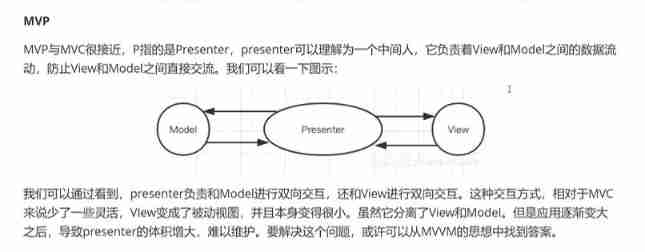
MVVM and MVC

随机推荐
Vsocde has cli every time it is opened js
[untitled]
Which brand of running headphones is good? How many professional running headphones are recommended
After marriage
Start from scratch - Web Host - 01
2022-2028 global military computer industry research and trend analysis report
Baohong industry | four basic knowledge necessary for personal finance
2022-2028 global manual dental cleaning equipment industry research and trend analysis report
[learn C and fly] 1day Chapter 2 (exercise 2.2 find the temperature of Fahrenheit corresponding to 100 ° f)
[question 008: what is UV in unity?]
C write TXT file
使用开源项目【Banner】实现轮播图效果(带小圆点)
QT使用sqllite
2022 low voltage electrician test question simulation test question bank simulation test platform operation
Leetcode question brushing (10) - sequential question brushing 46 to 50
Yyds dry goods inventory accelerating vacuum in PG
Software testing learning notes - network knowledge
Websocket + spingboot realize code scanning login
QT uses sqllite
Comparative analysis of MVC, MVP and MVVM, source code analysis