当前位置:网站首页>MMSegmentation系列之训练与推理自己的数据集(三)
MMSegmentation系列之训练与推理自己的数据集(三)
2022-07-02 02:46:00 【qq_41627642】
1、准备数据目录结构
mstsc
VOCdevkit
│ │ ├── VOC2012
│ │ │ ├── JPEGImages(原始影像)
│ │ │ ├── SegmentationClass(掩膜影像)
│ │ │ ├── ImageSets
│ │ │ │ ├── Segmentation(数据划分)
2、下载预训练模型
3、修改配置文件(deeplabv3plus_r50-d8_512x512_40k_voc12aug.py)
1、 设置修改类别数(模型架构配置文件deeplabv3plus_r50-d8_512x512_40k_voc12aug.py)
_base_ = [
'../_base_/models/deeplabv3plus_r50-d8.py',
'../_base_/datasets/pascal_voc12_aug.py', '../_base_/default_runtime.py',
'../_base_/schedules/schedule_40k.py'
]
model = dict(
decode_head=dict(num_classes=21), auxiliary_head=dict(num_classes=21))#按照自己的数据进行修改
2、修改数据信息(数据类型、数据主路径等和batch-size)(…/base/datasets/pascal_voc12_aug.py、pascal_voc12.py)
# dataset settings
dataset_type = 'PascalVOCDataset' #按照需要修改数据类型
data_root = 'data/VOCdevkit/VOC2012' #按照需要修改数据主路径
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size = (512, 512)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(2048, 512), ratio_range=(0.5, 2.0)),
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(2048, 512),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=4, #按照硬件设备修改
workers_per_gpu=4,
train=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages', #同理按照需要进行数据修改
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/train.txt',
pipeline=train_pipeline),
val=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
data_root=data_root,
img_dir='JPEGImages',
ann_dir='SegmentationClass',
split='ImageSets/Segmentation/val.txt',
pipeline=test_pipeline))
_base_ = './pascal_voc12.py'
# dataset settings,因为我们没有Aug数据所以频闭掉
#data = dict(
# train=dict(
# ann_dir=['SegmentationClass', 'SegmentationClassAug'],
#split=[
# 'ImageSets/Segmentation/train.txt',
# 'ImageSets/Segmentation/aug.txt'
# ]))
重要:配置文件中的默认学习速率为4 gpu和2 img/gpu(批处理大小= 4x2 = 8)。同样地,你也可以使用8 gpu和1 imgs/gpu,因为所有型号都使用cross_gpu SyncBN。
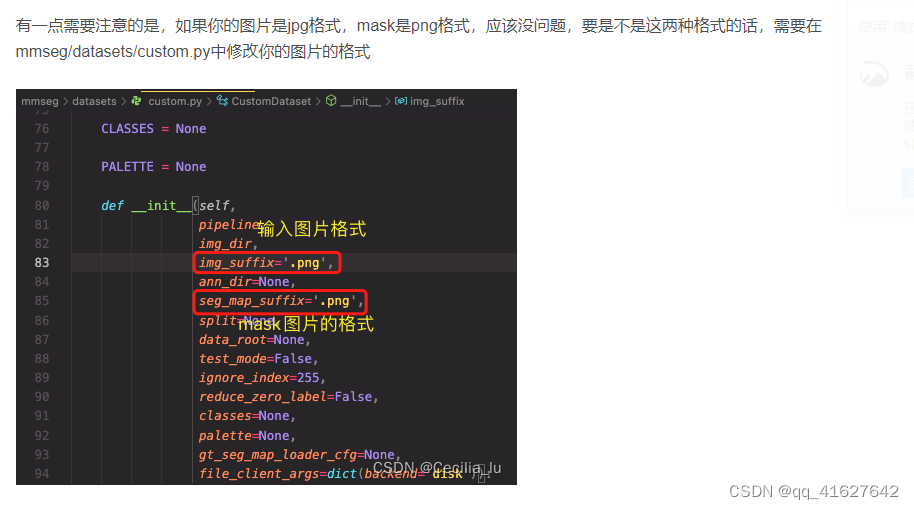
3、修该类别名称CLASSES(mmseg/datasets/voc.py)
class PascalVOCDataset(CustomDataset):
"""Pascal VOC dataset.
Args:
split (str): Split txt file for Pascal VOC.
"""
CLASSES = ('background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle',
'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa',
'train', 'tvmonitor') #修改为自己的数据类别
4、修改运行信息配置(加载预训练模型和断点训练)(configs/-base-/default_runtime.py)
log_config = dict(
interval=50,
hooks=[
dict(type='TextLoggerHook', by_epoch=False),
# dict(type='TensorboardLoggerHook')
])
# yapf:enable
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None #可以加载预训练模型
resume_from = None #可以加载断点训练模型
workflow = [('train', 1)]
cudnn_benchmark = True
5、修改运行信息配置(模型训练的最大次数、训练每个几次保留一个checkpoints、间隔多少次进行模型训练,模型训练评估的指标为、保留最好的模型)(configs/-base-/schedule_40k.py)
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0005)
optimizer_config = dict()
# learning policy
lr_config = dict(policy='poly', power=0.9, min_lr=1e-4, by_epoch=False)
# runtime settings
runner = dict(type='IterBasedRunner', max_iters=40000)#
checkpoint_config = dict(by_epoch=False, interval=4000)
evaluation = dict(interval=4000, metric='mIoU')#save_best='auto'
6、模型信息修改(tiicks)(configs/base/models)
Different Learning Rate(LR) for Backbone and Heads
n MMSegmentation, you may add following lines to config to make the LR of heads 10 times of backbone.
optimizer=dict(
paramwise_cfg = dict(
custom_keys={
'head': dict(lr_mult=10.)}))
Online Hard Example Mining (OHEM)
We implement pixel sampler here for training sampling. Here is an example config of training PSPNet with OHEM enabled.
_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
model=dict(
decode_head=dict(
sampler=dict(type='OHEMPixelSampler', thresh=0.7, min_kept=100000)) )
Class Balanced Loss
For dataset that is not balanced in classes distribution, you may change the loss weight of each class. Here is an example for cityscapes dataset.
_base_ = './pspnet_r50-d8_512x1024_40k_cityscapes.py'
model=dict(
decode_head=dict(
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0,
# DeepLab used this class weight for cityscapes
class_weight=[0.8373, 0.9180, 0.8660, 1.0345, 1.0166, 0.9969, 0.9754,
1.0489, 0.8786, 1.0023, 0.9539, 0.9843, 1.1116, 0.9037,
1.0865, 1.0955, 1.0865, 1.1529, 1.0507])))
Multiple Losses
For loss calculation, we support multiple losses training concurrently. Here is an example config of training unet on DRIVE dataset, whose loss function is 1:3 weighted sum of CrossEntropyLoss and DiceLoss:
_base_ = './fcn_unet_s5-d16_64x64_40k_drive.py'
model = dict(
decode_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce', loss_weight=1.0),
dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
auxiliary_head=dict(loss_decode=[dict(type='CrossEntropyLoss', loss_name='loss_ce',loss_weight=1.0),
dict(type='DiceLoss', loss_name='loss_dice', loss_weight=3.0)]),
)
Ignore specified label index in loss calculation
In default setting, avg_non_ignore=False which means each pixel counts for loss calculation although some of them belong to ignore-index labels.
For loss calculation, we support ignore index of certain label by avg_non_ignore and ignore_index. In this way, the average loss would only be calculated in non-ignored labels which may achieve better performance, and here is the reference. Here is an example config of training unet on Cityscapes dataset: in loss calculation it would ignore label 0 which is background and loss average is only calculated on non-ignore labels:
_base_ = './fcn_unet_s5-d16_4x4_512x1024_160k_cityscapes.py'
model = dict(
decode_head=dict(
ignore_index=0,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0, avg_non_ignore=True),
auxiliary_head=dict(
ignore_index=0,
loss_decode=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0, avg_non_ignore=True)),
))

4、模型进行训练
1、Train with a single GPU
python tools/train.py ${CONFIG_FILE} [optional arguments]
如果您想在命令中指定工作目录,您可以添加一个参数--work-dir ${YOUR_WORK_DIR}
python tools/train.py configs/deeplabv3plus/deeplabv3plus_r50-d8_512x512_20k_voc12aug.py --work-dir work_dirs/runs/train/deeplabv3plus
2、Train with multiple GPUs
sh tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [optional arguments]
1
–no-validate (not suggested): By default, the codebase will perform evaluation at every k iterations during the training. To disable this behavior, use --no-validate.
–work-dir ${WORK_DIR}: Override the working directory specified in the config file.
–resume-from ${CHECKPOINT_FILE}: Resume from a previous checkpoint file (to continue the training process).
–load-from ${CHECKPOINT_FILE}: Load weights from a checkpoint file (to start finetuning for another task).
–deterministic: Switch on “deterministic” mode which slows down training but the results are reproducible.
5、模型训练日志的打印划图
#Plot training logs
tools/analyze_logs.py plots loss/mIoU curves given a training log file
python tools/analyze_logs.py xxx.log.json [--keys ${KEYS}] [--legend ${LEGEND}] [--backend ${BACKEND}] [--style ${STYLE}] [--out ${OUT_FILE}]
Plot the mIoU, mAcc, aAcc metrics.
python tools/analyze_logs.py log.json --keys mIoU mAcc aAcc --legend mIoU mAcc aAcc
Plot loss metric.
python tools/analyze_logs.py log.json --keys loss --legend loss
6、模型测试
single-gpu testing
#单个模型测试
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}] [--show]
#多个模型测试
/tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [--out ${RESULT_FILE}] [--eval ${EVAL_METRICS}]
./tools/dist_test.sh configs/pspnet/pspnet_r50-d8_512x1024_40k_cityscapes.py checkpoints/pspnet_r50-d8_512x1024_40k_cityscapes_20200605_003338-2966598c.pth 4 --out results.pkl --eval mIoU cityscapes
./tools/dist_test.sh \
configs/cityscapes/mask_rcnn_r50_fpn_1x_cityscapes.py \
checkpoints/mask_rcnn_r50_fpn_1x_cityscapes_20200227-afe51d5a.pth \
8 \
--format-only \
--options "txtfile_prefix=./mask_rcnn_cityscapes_test_results"
错误
MMSeg错误:RuntimeError: Default process group has not been initialized
边栏推荐
- 【带你学c带你飞】day 5 第2章 用C语言编写程序(习题2)
- [Chongqing Guangdong education] Sichuan University concise university chemistry · material structure part introductory reference materials
- What is the principle of bone conduction earphones and who is suitable for bone conduction earphones
- 超图iServer rest服务之feature查询
- Query word weight, search word weight calculation
- Kibana操控ES
- Actual battle of financial risk control - under Feature Engineering
- Which kind of sports headphones is easier to use? The most recommended sports headphones
- [staff] pitch representation (bass clef | C1 36 note pitch representation | C2 48 note pitch representation | C3 60 note pitch representation)
- 离婚3年以发现尚未分割的共同财产,还可以要么
猜你喜欢
![[learn C and fly] 3day Chapter 2 program in C language (exercise 2.3 calculate piecewise functions)](/img/8e/a86a9724251718d98ce172a6a96e53.png)
[learn C and fly] 3day Chapter 2 program in C language (exercise 2.3 calculate piecewise functions)
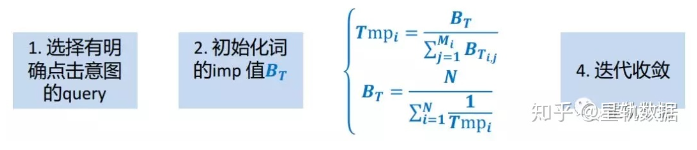
query词权重, 搜索词权重计算
Face++ realizes face detection in the way of flow
![[Chongqing Guangdong education] Sichuan University concise university chemistry · material structure part introductory reference materials](/img/ae/7edbdf55795400166650c795c8bd58.jpg)
[Chongqing Guangdong education] Sichuan University concise university chemistry · material structure part introductory reference materials
Connected block template and variants (4 questions in total)

2022-2028 global manual dental cleaning equipment industry research and trend analysis report
How to batch add background and transition effects to videos?

Analysis of FLV packaging format

buu_ re_ crackMe

STM32__ 05 - PWM controlled DC motor

随机推荐
Stack - es - official documents - filter search results
Oracle creates a user with read-only permission in four simple steps
批量检测url是否存在cdn—高准确率
[opencv] - comprehensive examples of five image filters
QT implementation interface jump
What is the difference between an intermediate human resource manager and an intermediate economist (human resources direction)?
【带你学c带你飞】1day 第2章 (练习2.2 求华氏温度 100°F 对应的摄氏温度
Es interview questions
After marriage
2022-2028 global aluminum beverage can coating industry research and trend analysis report
What is the principle of bone conduction earphones and who is suitable for bone conduction earphones
Systemserver service and servicemanager service analysis
MongoDB非關系型數據庫
Batch detect whether there is CDN in URL - high accuracy
How does proxy IP participate in the direct battle between web crawlers and anti crawlers
使用 useDeferredValue 进行异步渲染
Quality means doing it right when no one is looking
Mongodb base de données non relationnelle
About DNS
Infix expression to suffix expression (computer) code