当前位置:网站首页>[paper reading] boostmis: boosting medical image semi supervised learning with adaptive pseudolabeling
[paper reading] boostmis: boosting medical image semi supervised learning with adaptive pseudolabeling
2022-06-11 01:10:00 【xiongxyowo】
[ Address of thesis ] [ Code ] [CVPR 22]
Abstract
In this paper , We put forward a proposal called BoostMIS New semi supervised learning (SSL) frame , It combines adaptive pseudo tags with informative active annotations , To release medical images SSL The potential of models :(1)BoostMIS According to the current learning status , Adaptively normalize using the cluster assumption and the consistency of unlabeled data . This strategy can adaptively generate a single task from task model prediction " hard " label , In order to better carry out task model training .(2) For unselected low confidence unlabeled images , We introduce active learning (AL) Algorithm , Through the use of virtual anti disturbance and model density perception entropy , Find samples with information as annotation candidates . These informative candidate samples are then sent to the next training cycle , In order to better SSL Tag spread . It is worth noting that , Adaptive pseudo tags and active tagging with large amount of information form a learning closed loop , They work together , Promotes medical imaging SSL. In order to verify the effectiveness of the proposed method , We collected a case of metastatic epidural spinal cord compression (MESCC) Data set of , To optimize MESCC Diagnosis and classification of , To improve expert referral and treatment . We are MESCC And another public data set COVIDx On the BoostMIS Extensive experimental research . The experimental results verify the effectiveness and generality of our framework for different medical image datasets , Compared with the most advanced methods , There is a clear improvement .
I. Introduction
This paper is a standard work that combines active learning with semi supervised learning . namely , Active learning is used to continuously select annotation sets in semi supervised , So that "boost" The role of semi supervision , The process is as follows :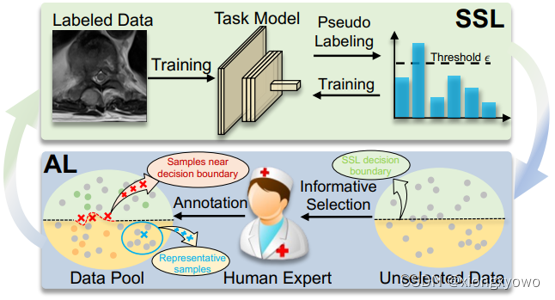
The core point is that the selection of labeled samples in semi supervised learning will have a great impact on the overall performance , In this way, we need active learning algorithm to select " Better dimension sets ". On the whole , The framework of this article is very simple , Technology is not complicated , But the story is very interesting . Different from the natural image segmentation task , Images of medical tasks are highly similar . Due to the small number of samples , It's hard to train , Therefore, it is difficult to find enough high-quality pseudo tags for learning . Besides , Some prediction results with low confidence may indicate that the sample is worth noting . For example , It is precisely because the Internet has not learned some valuable features contained in this picture , That's why I made a wrong prediction .
In this paper, the AL+SSL The process is as follows :
There are still many overall steps . From the top down :
- 1) First of all Medical Image Task Model. Randomly initialize a small number of initial samples , It is used to train the segmentation model . It should be noted that , Similar to most jobs , The training samples are simply enhanced to improve the robustness of the model , This is called weak enhancement (Weakly Augmentation).
- 2) Next is Consistency-based Adaptive Label Propagator. Like many semi supervisory ideas , The unlabeled samples are sent into the model to produce prediction results , Take the samples with high confidence as the true values and prepare them for training . Attention here , This paper presents an adaptive threshold method , To control the quality of sample selection at different stages of the network ; Besides , An auxiliary network is also used to reduce the interference of pseudo label noise on model training , Prevention model in self training In the process of .
- 3) What's more Adversarial Unstability Selector. By disturbing , Look for valuable samples at the decision boundary of the model .
- 4) What's more Balanced Uncertainty Selector. Using density entropy , Looking for high value samples .
The whole idea is , For samples with high confidence , The pseudo tag is directly regarded as the true value for training ; For samples with low confidence , Mining high value samples using active learning algorithm , Manual tagging for training . The core highlight is ( May be ) One of the first AL+SSL Medical segmentation work .
II. Consistency-based Adaptive Label Propagator
Generally speaking , One of the basic methods of semi supervision is pseudo label . namely , Give a confidence manually , If you predict softmax The maximum class probability in the result is higher than this confidence , We think that this result is consistent with GT almost , It can be used directly as a label . In this paper , Author points out , Because the learning ability of the network is dynamic ( Gradually stronger ), Therefore, a fixed confidence threshold may make it difficult to select any pseudo tags in the early stage of the network , Or a large number of false tags with noise are selected in the later stage of the network . therefore , This paper proposes the use of an adaptive ( Gradually increase ) Threshold value for pseudo tag selection .
Look directly at the formula , Train on the Internet until t t t Step time adaptive threshold (Adaptive threShold, AS) ϵ t \epsilon_{t} ϵt The definition is as follows :
ϵ t = { α ⋅ Min { 1 , Count ϵ t Count ϵ t − 1 } + β ⋅ N A 2 K , if t < T max α + β , otherwise \epsilon_{t}= \begin{cases}\alpha \cdot \operatorname{Min}\left\{1, \frac{\text { Count }_{\epsilon_{t}}}{\text { Count }_{\epsilon_{t-1}}}\right\}+\frac{\beta \cdot N_{A}}{2 K}, & \text { if } t<T_{\max } \\ \alpha+\beta, & \text { otherwise }\end{cases} ϵt={ α⋅Min{ 1, Count ϵt−1 Count ϵt}+2Kβ⋅NA,α+β, if t<Tmax otherwise First look at this otherwise. When t ≥ T max t \geq T_{\max } t≥Tmax when , The threshold is locked to a fixed value α + β \alpha+\beta α+β. This means that when the network training reaches a certain level , Its representation learning has been relatively stable and will not change much , At this point, you can directly use the traditional manual threshold . It should be noted that , there " Certain extent " T max T_{\max} Tmax, as well as α \alpha α, β \beta β Are manually specified super parameters , Same as fixed threshold .
When the network representation fluctuates greatly ( t < T max t<T_{\max} t<Tmax) when , At this point, the threshold is adaptive . And this formula also involves a C o u n t Count Count function , So let's first look at its definition : Count ϵ t = ∑ i = 1 N u 1 ( P m ( p i ∣ A w ( u i ) ) > α + β ) \operatorname{Count}_{\epsilon_{t}}=\sum_{i=1}^{N_{u}} \mathbb{1}\left(P_{m}\left(\mathbf{p}_{i} \mid A_{w}\left(\mathbf{u}_{i}\right)\right)>\alpha+\beta\right) Countϵt=i=1∑Nu1(Pm(pi∣Aw(ui))>α+β) among , N u N_{u} Nu For all unmarked samples ( Pseudo label ) The number of , p i \mathbf{p}_{i} pi For the first time i i i False tags predicted by unlabeled samples , A w ( u i ) A_{w}(\mathbf{u}_{i}) Aw(ui) Represents an unlabeled sample enhanced by a weak data , P m ( p i ∣ A w ( u i ) ) P_{m}(\mathbf{p}_{i} | A_{w}(\mathbf{u}_{i})) Pm(pi∣Aw(ui)) Indicates the confidence of the false label predicted by the unlabeled sample . thus , You can find this C o u n t Count Count The function records what can be met in the current learning stage ( Higher ) Number of fake tags for manual threshold .
Go back to the formula above . The left side of the formula is : α ⋅ Min { 1 , Count ϵ t Count ϵ t − 1 } \alpha \cdot \operatorname{Min}\left\{1, \frac{\text { Count }_{\epsilon_{t}}}{\text { Count }_{\epsilon_{t-1}}}\right\} α⋅Min{ 1, Count ϵt−1 Count ϵt} in other words , If Count ϵ t ≥ Count ϵ t − 1 \text { Count }_{\epsilon_{t}} \geq \text { Count }_{\epsilon_{t-1}} Count ϵt≥ Count ϵt−1, It means that the network is in the process of further learning , It can generate more " High quality fake labels ", here α \alpha α It is multiplied by a greater than 1 The coefficient of , Raise the selection threshold , Make the selected labels of higher quality , Give up to some " Just meet the threshold " Of " Relatively low quality " sample ; conversely , If Count ϵ t < Count ϵ t − 1 \text { Count }_{\epsilon_{t}} < \text { Count }_{\epsilon_{t-1}} Count ϵt< Count ϵt−1, α \alpha α unchanged , Maintain the basic selection threshold .
The right side of the formula is : β ⋅ N A 2 K \frac{\beta \cdot N_{A}}{2 K} 2Kβ⋅NA That is to say β \beta β Multiplied by a factor N A 2 K \frac{N_{A}}{2K} 2KNA, K K K It is an artificial hyperparameter , Nothing to say. , N A N_A NA Is the marked sample number . obviously , N A N_A NA It will gradually increase , That is to say β \beta β The impact will gradually increase . But one thing that needs special attention is , Due to the constraints of active learning , N A 2 K \frac{N_{A}}{2K} 2KNA Always less than 1, therefore β \beta β The coefficient multiplied by is gradually from 0 Rise to 1 Of .
as for Consistency Regularization, Because the pseudo tag training is a self training The process of , Possible model crashes , Therefore, an auxiliary network is introduced , The network is enhanced with strong data (Strong Augmentation) The sample of is input , Supervised by fake tags . At this time, the input changes dramatically , Therefore, the network can be forced to learn some deep-seated distinguishing features of images , Reduce the fitting of noise in pseudo tags . This idea is similar to FixMatch Very close to , Therefore, this article is a brief introduction here .
III. Adversarial Unstability Selector
Valuable samples can be divided into two types ,unstable And uncertain, This section describes unstable. The general idea is , For the characterization of unlabeled samples , We artificially add some noise to it . The original characterization and noise treated characterization are sent to the output layer to obtain the output results . If the two softmax The results are quite different ( use KL Divergence measurement ), This indicates that the sample is unstable , High value .
IV. Balanced Uncertainty Selector
This paper deals with entropy Simple improvements have been made , To estimate uncertainty . Easy to use entropy It is easy to introduce outliers 、 Outliers 、 Repeat point , Resulting in poor performance . For this reason, this paper comes up with a density-aware entropy: Ent ( u i u ; θ S ) = Ent ′ ( u i u ; θ S ) ( 1 M ∑ j = 1 M Sim ( u i u , u j u ) ) \operatorname{Ent}\left(\mathbf{u}_{i}^{u} ; \theta_{S}\right)=\operatorname{Ent}^{\prime}\left(\mathbf{u}_{i}^{u} ; \theta_{S}\right)\left(\frac{1}{M} \sum_{j=1}^{M} \operatorname{Sim}\left(\mathbf{u}_{i}^{u}, \mathbf{u}_{j}^{u}\right)\right) Ent(uiu;θS)=Ent′(uiu;θS)(M1j=1∑MSim(uiu,uju)) Ent ′ ( u i u ; θ S ) \operatorname{Ent}^{\prime}\left(\mathbf{u}_{i}^{u} ; \theta_{S}\right) Ent′(uiu;θS) Is the original entropy , A coefficient is multiplied on the basis of it 1 M ∑ j = 1 M Sim ( u i u , u j u ) \frac{1}{M} \sum_{j=1}^{M} \operatorname{Sim}(\mathbf{u}_{i}^{u}, \mathbf{u}_{j}^{u}) M1∑j=1MSim(uiu,uju). The meaning of this coefficient is , For this sample u i u \mathbf{u}_{i}^{u} uiu, Calculate its similarity with other points . If the similarity is high , It means that the sample is representative ( Not outliers ), It should be chosen .
边栏推荐
- Centos7 actual deployment mysql8 (binary mode)
- Win11 uninstall widget
- Slam Kalman filter & nonlinear optimization
- 循环结构语句
- 团队管理|如何提高技术Leader的思考技巧?
- 87.(leaflet之家)leaflet军事标绘-直线箭头修改
- Blend for visual studio overview
- 【NVIDIA驱动的顽固问题】---- /dev/sdax:clean,xxx/xxx files,xxx/xxx blocks ---- 最全解决方法
- Random points in non overlapping rectangles
- 适配器模式
猜你喜欢

Complete uninstallation of MySQL under Linux

【VBA脚本】提取word文档中所有批注的信息和待解决状态

Complete collection of MySQL exercises (with answers) - you will know everything after practice
ViewPager和底部无线循环的小圆点
阻塞隊列 — DelayedWorkQueue源碼分析

SQL审核 | “云上”用户可以一键使用 SQLE 审核服务啦

Le meilleur outil de tambour créatif: Groove agent 5
【ROS入门教程】---- 02 ROS安装
SQL audit | "cloud" users can use the SQL audit service with one click
ZABBIX offline installation

随机推荐
ViewPager和底部无线循环的小圆点
Pirate OJ 448 luck draw
Cosine similarity calculation summary
Complete uninstallation of MySQL under Linux
dma_ buf_ export
【ROS入门教程】---- 03 ROS基本概念及指令
MySQL trigger
SqlServer中的鎖
嵌入式学习资料和项目汇总
No module named CV2
NVIDIA Jetson之PWM风扇自定义控制
适配器模式
Why is the digital transformation of small and medium-sized enterprises so difficult?
Centos7 actual deployment mysql8 (binary mode)
ion_ mmap
Lucene mind map makes search engines no longer difficult to understand
How to ensure the sequence of messages, that messages are not lost or consumed repeatedly
LeetCode 8. 字符串转换整数 (atoi)(中等、字符串)
[introduction to ROS] - 03 single chip microcomputer, PC host and ROS communication mechanism
【NVIDIA驱动的顽固问题】---- /dev/sdax:clean,xxx/xxx files,xxx/xxx blocks ---- 最全解决方法