当前位置:网站首页>Paper reading [semantic tag enlarged xlnv model for video captioning]
Paper reading [semantic tag enlarged xlnv model for video captioning]
2022-07-07 05:34:00 【hei_ hei_ hei_】
Semantic Tag Augmented XlanV Model for Video Captioning
- publish :ACMM 2021
- Code :ST-XlanV
- idea: Model generation through pre training semantic tag Reduce the difference between modes , enhance XlanV The power of the model . Use cross-modal attention Capture dynamics & Static features and vision & Interaction between semantic features . Three pre training tasks are designed for tag alignment
Detailed design
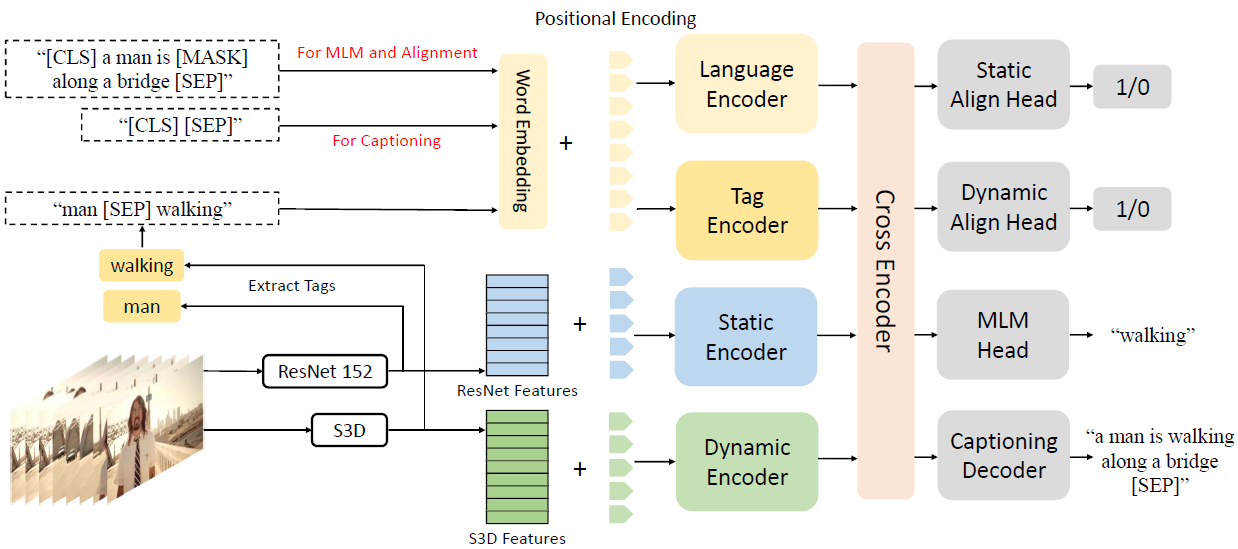
Feeling ACMM The ideas of these articles are very similar , All with the original X-Linear That one is very similar , Just extend it to multimodality .
1. Semantic Tag Augmented XlanV Model
The general framework is similar to the previous one , All right. multi-modal feature Pass respectively XLAN encoder Extract high-order features , then concate After input cross encoder Extract contains cross-modal interactions Of feature, Last input LSTM Decode and generate captions
2. Cross-modal Attention
Each feature passes its own encoder Add location information after coding , then concate Together and enter a XLAN encoder in , The output characteristic is cross-modal feature. Input after average pooling LSTM in . The specific calculation is as follows :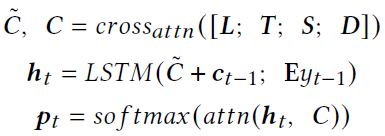
C ~ \widetilde C C Represents the characteristics after average pooling , E y t − 1 E_{y_{t-1}} Eyt−1 Indicates the output word of the last moment embedding
3. Pre-training Tasks
- Tag Alignment Prediction (TAP): Randomly replace the semantic tags of the current video with other tags , The probability of 50%, And predict whether the tag has been replaced
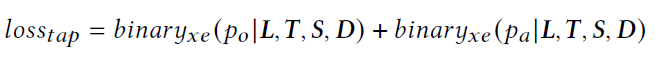
- Mask Language Modeling (MLM): And bert similar , Random mask fall 15% The words of the input sentence
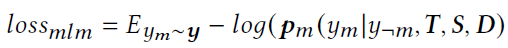
- Video Captioning(VCAP):caption generation
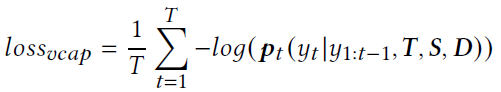
experimental result
Ablative Studies
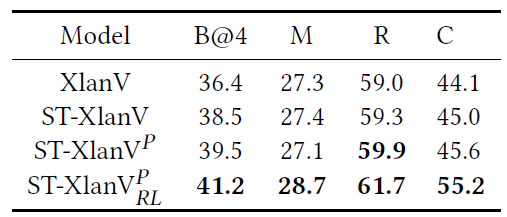
summary :semantic tag It's about getting up vision and language The bridge ; The pre training task is conducive to the full use of the model multi-modal interactions; Reinforcement learning strategies can improve the performance of the modelPerformance Comparison
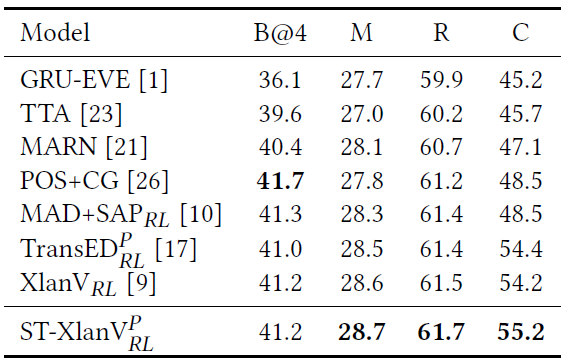
P P P Indicates that the model uses a pre training task ; R L RL RL Indicates the use of reinforcement learning strategies
边栏推荐
- Digital innovation driven guide
- 淘宝商品详情页API接口、淘宝商品列表API接口,淘宝商品销量API接口,淘宝APP详情API接口,淘宝详情API接口
- Senior programmers must know and master. This article explains in detail the principle of MySQL master-slave synchronization, and recommends collecting
- 基于 hugging face 预训练模型的实体识别智能标注方案:生成doccano要求json格式
- 说一说MVCC多版本并发控制器?
- Leetcode 1189 maximum number of "balloons" [map] the leetcode road of heroding
- Autowired注解用于List时的现象解析
- Vector and class copy constructors
- Jhok-zbl1 leakage relay
- CentOS 7.9 installing Oracle 21C Adventures
猜你喜欢



随机推荐
[PHP SPL notes]
Two methods of thread synchronization
Linkedblockingqueue source code analysis - initialization
JHOK-ZBG2漏电继电器
sql优化常用技巧及理解
论文阅读【Semantic Tag Augmented XlanV Model for Video Captioning】
论文阅读【Open-book Video Captioning with Retrieve-Copy-Generate Network】
张平安:加快云上数字创新,共建产业智慧生态
拼多多商品详情接口、拼多多商品基本信息、拼多多商品属性接口
The founder has a debt of 1billion. Let's start the class. Is it about to "end the class"?
JVM(二十) -- 性能监控与调优(一) -- 概述
Digital innovation driven guide
Mapbox Chinese map address
《2》 Label
Pytest testing framework -- data driven
Taobao commodity details page API interface, Taobao commodity list API interface, Taobao commodity sales API interface, Taobao app details API interface, Taobao details API interface
AOSP ~binder communication principle (I) - Overview
Mysql database learning (7) -- a brief introduction to pymysql
Is the human body sensor easy to use? How to use it? Which do you buy between aqara green rice and Xiaomi
Wonderful express | Tencent cloud database June issue