当前位置:网站首页>论文阅读【Open-book Video Captioning with Retrieve-Copy-Generate Network】
论文阅读【Open-book Video Captioning with Retrieve-Copy-Generate Network】
2022-07-06 23:36:00 【hei_hei_hei_】
Open-book Video Captioning with Retrieve-Copy-Generate Network
概要
- 发表:CVPR 2021
- idea:作者认为之前的方法由于生成caption的时候缺乏一定的指导,因此生成的caption比较单调,并且由于训练数据集是固定的,所以模型训练后学到的知识是不可扩展的。作者想到通过video-to-text检索任务,从语料库中检索句子作为caption的指导。类似开卷考试(open-domain mechanism)
详细设计
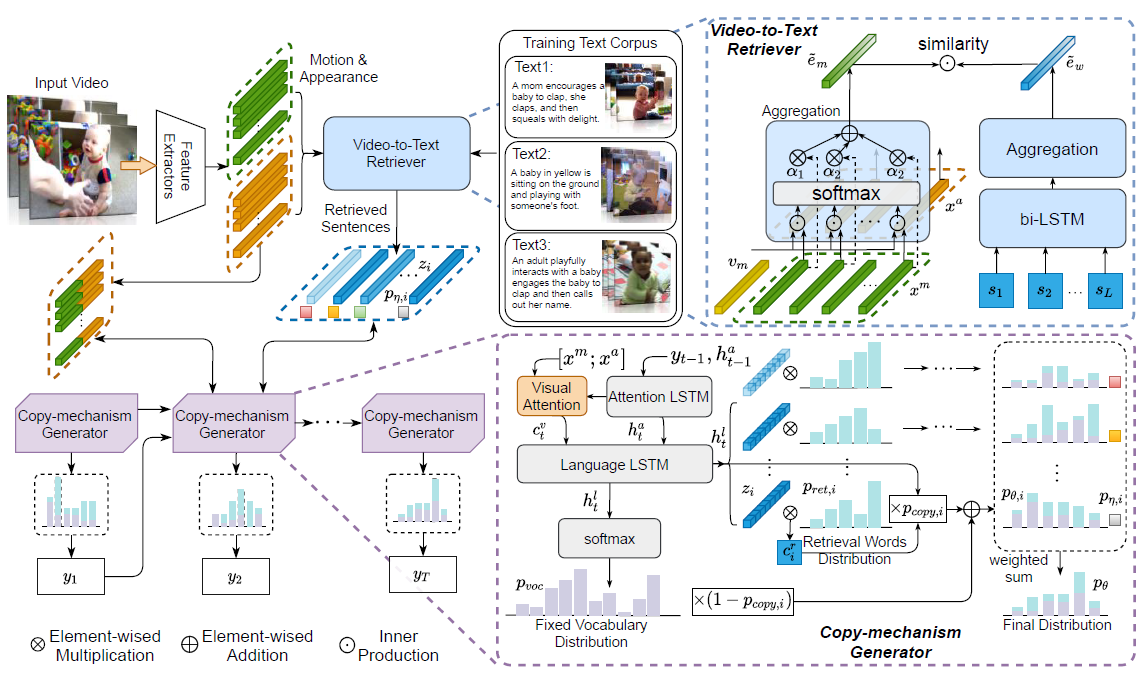
1. Effective Video-to-Text Retriever
将语料库中所有sentences通过一个textual encoder映射到d维,videos通过visual encoder映射到d维,求相似度作为选择标准标准

Textual Encoder:bi-LSTM
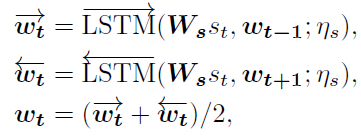
ps: L L L表示句子长度, W s W_s Ws是可学习的embedding矩阵, η s \eta _s ηs为LSTM的参数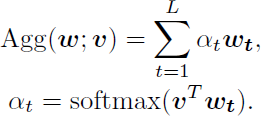
将长度L的sentence聚合成一个d维的vector: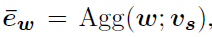
v s v_s vs是聚合参数Visual Encoder:appearance features && motion features

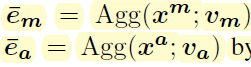
v a , v m v_a,v_m va,vm是聚合参数video-to-text similarity:
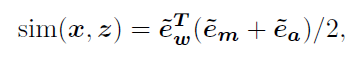
最终得到k个检索出来指导的句子
2. Copy-mechanism Caption Generator
通过Hierarchical Caption Decoder来生成caption,只是在每一个step通过Dynamic Multi-pointers Module决定是否要copy指导的word
2.1 Hierarchical Caption Decoder
由一个attention-LSTM和一个language-LSTM组成。attention-LSTM用于注意visual features用于聚合当前的状态和视觉上下文以生成词汇库的概率分布 p v o c p_{voc} pvoc
- attention-LSTM
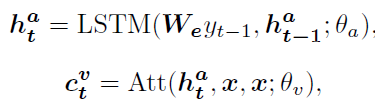
x = [ x m ; x a ] x = [x^m;x^a] x=[xm;xa], y t − 1 y_{t-1} yt−1表示上一step生成的单词 - language-LSTM
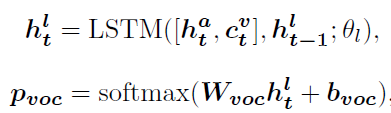
W b o c , b b o c W_{boc},b_{boc} Wboc,bboc都是可学习参数
2.2 Dynamic Multi-pointers Module
前提:已经得到K个候选sentences 每个sentence有L个单词
每个sentence有L个单词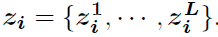
对每个句子分别处理。将decoder中的hidden state h t l h^l_t htl作为Q对句子中L个单词做attention,得到L个单词的注意力概率分布
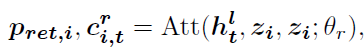
p r e t , i p_{ret,i} pret,i表示第i个句子中各个单词的注意力分布权重; c i , t r c_{i,t}^r ci,tr表示加权后的结果。决定是否copy选择的单词
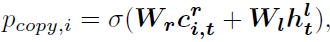
得到最终所有词汇的概率分布( p r e t p_{ret} pret被扩展, p c o p y p_{copy} pcopy被广播)
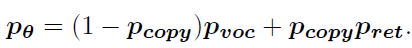
3. Training
- 策略1:为了可扩展语料库,可以固定retriever,fine-tuning generator。
- 策略2:也可以二者一起训练,但是如果直接更新retriever会导致generator从一开始就训练得很差,所以对Loss中添加了限制
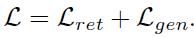
实验结果
- 消融实验
different K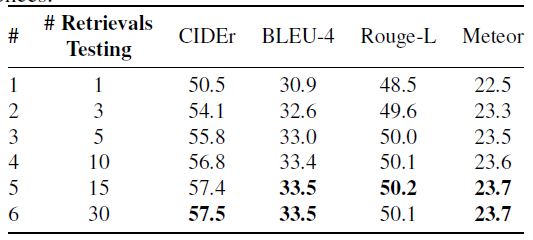
different corpus size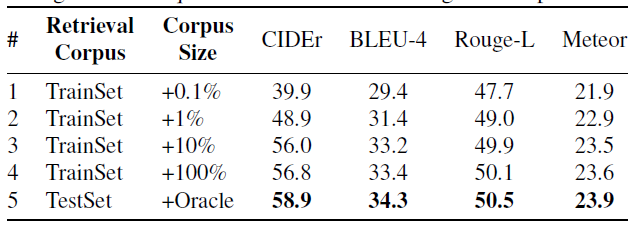
- Comparison Performance
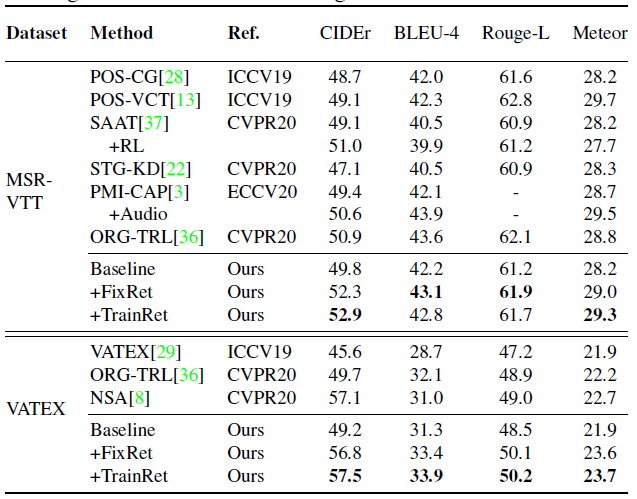
结果其实一般,都没有超过20年的一些实验
边栏推荐
猜你喜欢
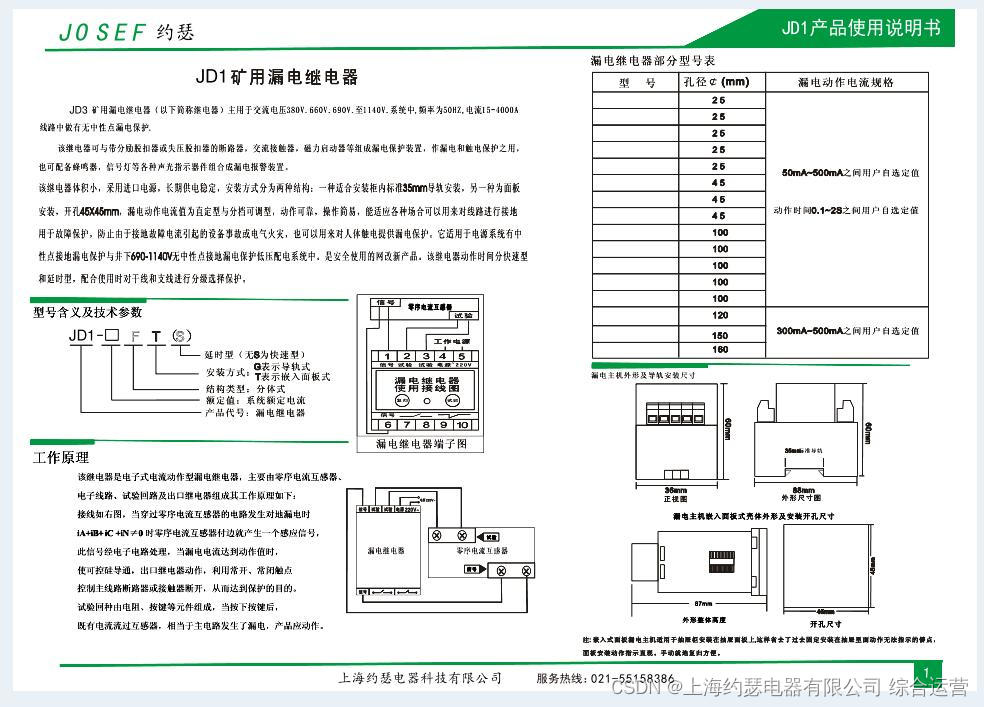
漏电继电器JD1-100
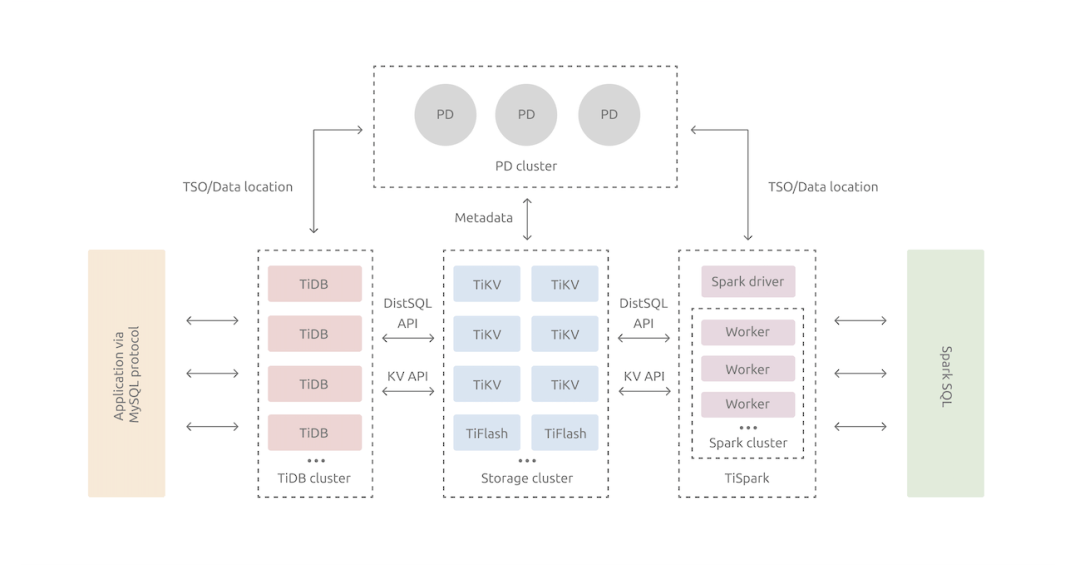
带你遨游银河系的 10 种分布式数据库
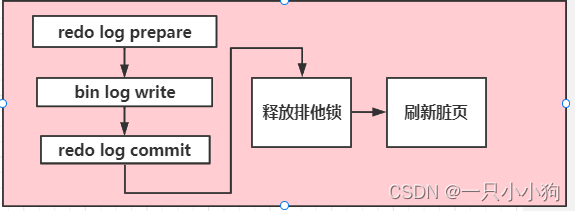
一条 update 语句的生命经历
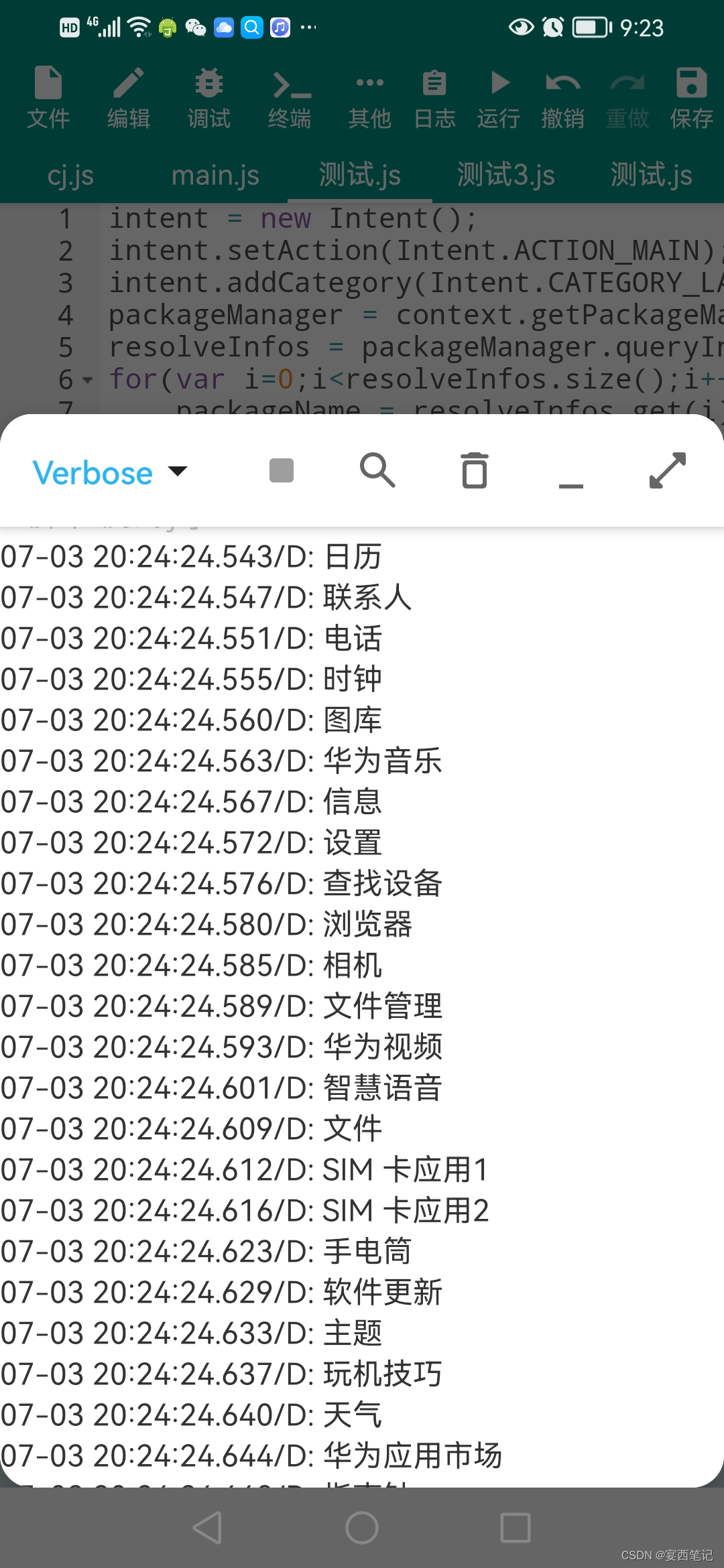
Auto.js 获取手机所有app名字
![[opencv] image morphological operation opencv marks the positions of different connected domains](/img/c3/f437bad9432dedbbb14c8a62ba5180.png)
[opencv] image morphological operation opencv marks the positions of different connected domains

How Alibaba cloud's DPCA architecture works | popular science diagram
《2》 Label

pmp真的有用吗?
MySQL数据库学习(8) -- mysql 内容补充
Autowired注解用于List时的现象解析
随机推荐
痛心啊 收到教训了
Harmonyos fourth training
Batch size setting skills
LinkedBlockingQueue源码分析-初始化
Is PMP really useful?
SQL injection cookie injection
ThinkPHP Association preload with
DFS, BFS and traversal search of Graphs
【opencv】图像形态学操作-opencv标记不同连通域的位置
app clear data源码追踪
Two person game based on bevy game engine and FPGA
利用OPNET进行网络单播(一服务器多客户端)仿真的设计、配置及注意点
[Oracle] simple date and time formatting and sorting problem
《4》 Form
[optimal web page width and its implementation] [recommended collection "
漏电继电器JELR-250FG
HarmonyOS第四次培训
Summary of the mean value theorem of higher numbers
局部变量的数组初始化问题
np. random. Shuffle and np Use swapaxis or transfer with caution