当前位置:网站首页>论文阅读【MM21 Pre-training for Video Understanding Challenge:Video Captioning with Pretraining Techniqu】
论文阅读【MM21 Pre-training for Video Understanding Challenge:Video Captioning with Pretraining Techniqu】
2022-07-06 23:35:00 【hei_hei_hei_】
MM21 Pre-training for Video Understanding Challenge:Video Captioning with Pretraining Technique
概述
- 发表:ACMM 2021
- idea:使用X-Linear Attention,借鉴XLAN的思路对Multi-modality Feature进行融合,提出一种multi-path XLAN模型能够对多个单模态特征进行融合,得到一种较好的融合后的特征。此外在视频理解预训练模型比赛中通过数据扩充技术以及集成multi-path XLAN(early fuse)和微调pretrained OPT(late fuse)获得第一
详细设计
1. Single-Modality Pretrained Feature Fusion
Multi-Modality Feature Extraction
几乎考虑到了视频中所有模态的特征,包括:
(1)appearance feature( 30 f r a m e s ∗ 2048 d i m s 30 frames * 2048 dims 30frames∗2048dims):FixResNeXt-101 network pretrained on the ImageNet-1k dataset
(2)motion feature( 30 f r a m e s ∗ 2048 d i m s 30 frames * 2048 dims 30frames∗2048dims):irCSN-152 network pretrained on the Kinetics-400 dataset
(3)region feature( 50 f r a m e s ∗ 2048 d i m s 50 frames * 2048 dims 50frames∗2048dims):vinvl model pretrained on Visual Genome dataset
(4)audio feature( 30 f r a m e s ∗ 2048 d i m s 30 frames * 2048 dims 30frames∗2048dims):CNN14 network pretrained on the AudioSet datasetMulti-Modality Feature Fusion
感觉就是OPT+XLAN,几乎没什么改动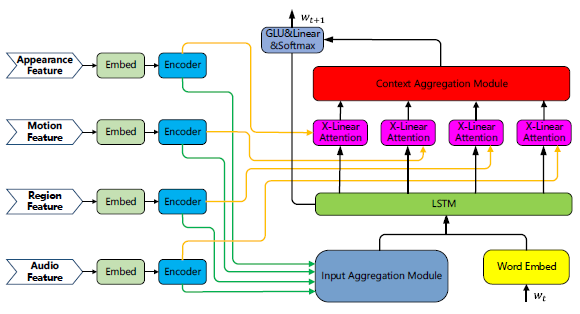
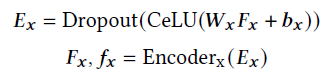
F x F_x Fx表示输入特征, E x E_x Ex主要是将各种模态特征嵌入到相同的语义隐藏空间, E n c o d e r x Encoder_x Encoderx是XLAN encoder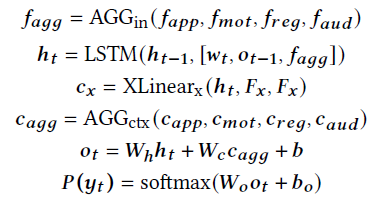
这里的 A G G i n AGG_in AGGin和 A G G c t x AGG_ctx AGGctx表示聚合方式,有以下几种选择方式:average pooling、concatenation、additional attention
2. Multi-Modality Pretrained Model Finetuning
对pretrained Omni-Perception Pre-Trainer model (OPT)进行微调。
- OPT
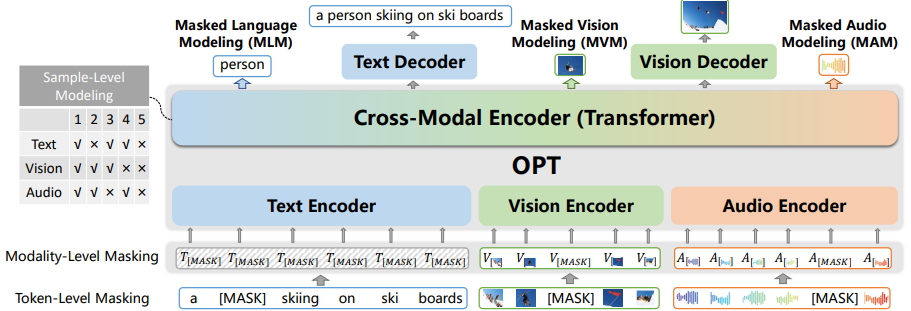
分别使用三个encoder对文本、图片、声音进行编码并将特征转换到相同的latent space;然后使用transformer对三种特征进行融合(inter- and intra interactions),然后接入text decoder 和 visual decoder分别生成文本和图片。同时设计了token-level、modality-level和sample-level的任务以让模型具有跨模态理解和生成的能力。作者在这上面使用MSR-VTT数据集进行微调。
实验
- Ablation Studies
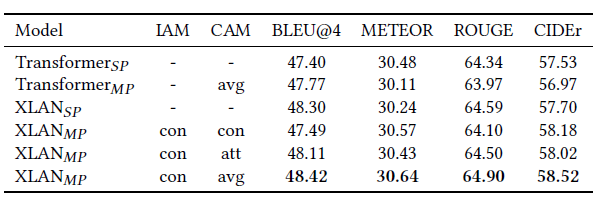
S P SP SP指直接将multi-modality features concate然后进行reduce dimension到1024然后输入encoder-decoder的XLAN/Transformer modal中 - Comparison to State-of-the-art
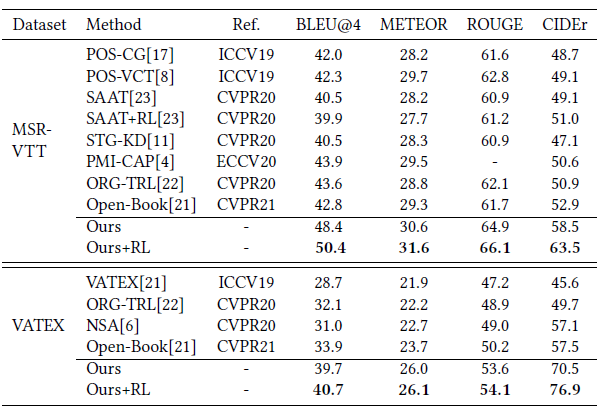
+ R L +RL +RL表示微调的时候使用了reinforcement learning
边栏推荐
- [JS component] date display.
- JHOK-ZBL1漏电继电器
- Full link voltage test: the dispute between shadow database and shadow table
- Use Zhiyun reader to translate statistical genetics books
- If you‘re running pod install manually, make sure flutter pub get is executed first.
- When deleting a file, the prompt "the length of the source file name is greater than the length supported by the system" cannot be deleted. Solution
- pmp真的有用吗?
- Dbsync adds support for mongodb and ES
- 漏电继电器JOLX-GS62零序孔径Φ100
- Complete code of C language neural network and its meaning
猜你喜欢

U++ metadata specifier learning notes
SQL injection HTTP header injection

拿到PMP认证带来什么改变?
Two person game based on bevy game engine and FPGA

EGR-20USCM接地故障继电器
JVM(十九) -- 字节码与类的加载(四) -- 再谈类的加载器

How Alibaba cloud's DPCA architecture works | popular science diagram

数字化创新驱动指南
PMP证书有没有必要续期?
Complete code of C language neural network and its meaning
随机推荐
Creation and use of thread pool
AIDL 与Service
[JS component] custom select
痛心啊 收到教训了
The founder has a debt of 1billion. Let's start the class. Is it about to "end the class"?
实现网页内容可编辑
U++4 interface learning notes
Is the human body sensor easy to use? How to use it? Which do you buy between aqara green rice and Xiaomi
LabVIEW is opening a new reference, indicating that the memory is full
K6EL-100漏电继电器
JHOK-ZBG2漏电继电器
Record a pressure measurement experience summary
Life experience of an update statement
Most commonly used high number formula
How Alibaba cloud's DPCA architecture works | popular science diagram
【QT】自定义控件-Loading
10 distributed databases that take you to the galaxy
照片选择器CollectionView
[optimal web page width and its implementation] [recommended collection "
阿里云的神龙架构是怎么工作的 | 科普图解