当前位置:网站首页>Intelligent annotation scheme of entity recognition based on hugging Face Pre training model: generate doccano request JSON format
Intelligent annotation scheme of entity recognition based on hugging Face Pre training model: generate doccano request JSON format
2022-07-07 05:24:00 【Ting】
Reference resources : Data annotation platform doccano---- brief introduction 、 install 、 Use 、 Record on pit
1.hugging face
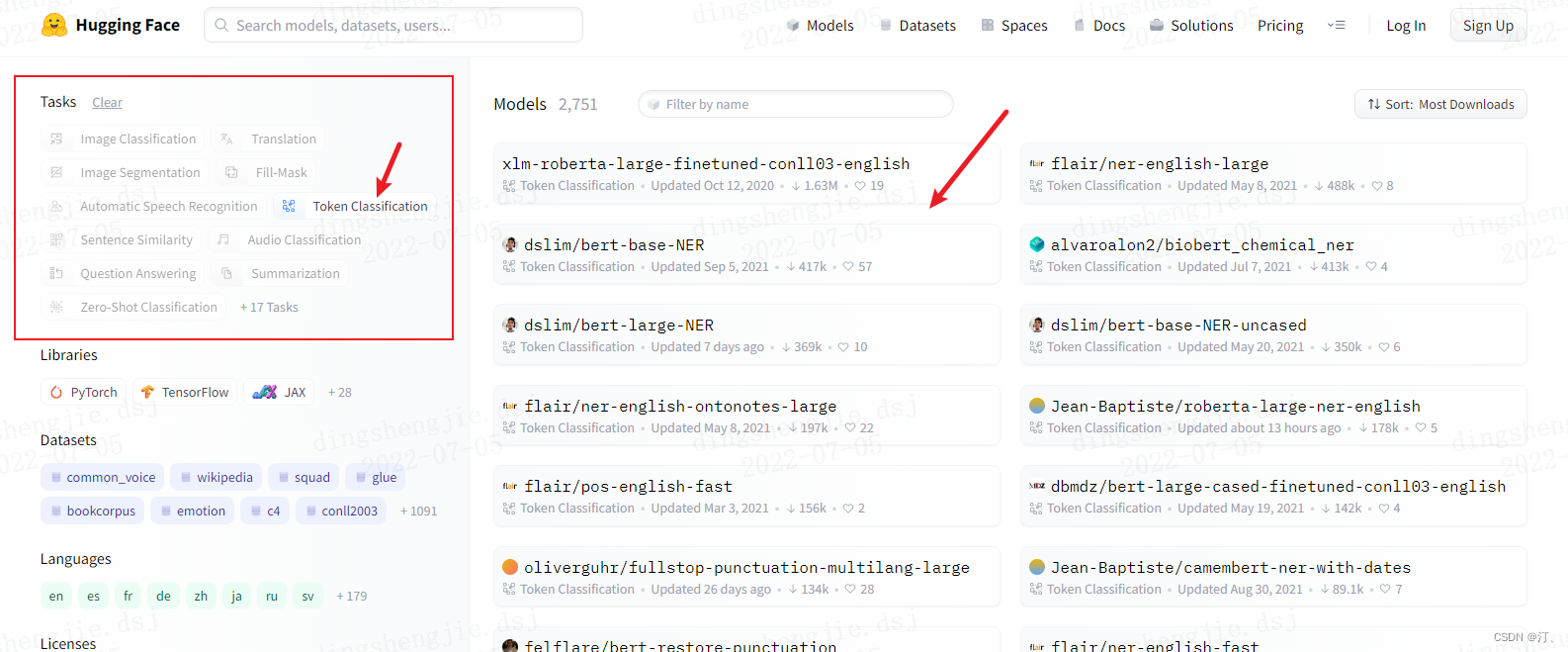
Relevant tutorials refer directly to others' : And training models
【Huggingface Transformers】 Nanny level tutorial — On - You know
huggingface transformers Of trainer Use guide - You know
2.doccano Label platform format requirements
doccano The link at the beginning of the platform operation reference article :
json Format import data format requirements : Entity ; Include relationship style presentation

{
"text": "Google was founded on September 4, 1998, by Larry Page and Sergey Brin.",
"entities": [
{
"id": 0,
"start_offset": 0,
"end_offset": 6,
"label": "ORG"
},
{
"id": 1,
"start_offset": 22,
"end_offset": 39,
"label": "DATE"
},
{
"id": 2,
"start_offset": 44,
"end_offset": 54,
"label": "PERSON"
},
{
"id": 3,
"start_offset": 59,
"end_offset": 70,
"label": "PERSON"
}
],
"relations": [
{
"from_id": 0,
"to_id": 1,
"type": "foundedAt"
},
{
"from_id": 0,
"to_id": 2,
"type": "foundedBy"
},
{
"from_id": 0,
"to_id": 3,
"type": "foundedBy"
}
]
}3. Entity intelligent annotation + format conversion
3.1 Long text ( One txt A long article )
The annotation section contains pre training model recognition entities ; And the format requirements of the wizard annotation assistant
from transformers import pipeline
import os
from tqdm import tqdm
import pandas as pd
from time import time
import json
def return_single_entity(name, start, end):
return [int(start), int(end), name]
# def return_single_entity(name, word, start, end, id, attributes=[]):
# entity = {}
# entity['type'] = 'T'
# entity['name'] = name
# entity['value'] = word
# entity['start'] = int(start)
# entity['end'] = int(end)
# entity['attributes'] = attributes
# entity['id'] = int(id)
# return entity
# input_dir = 'E:/datasets/myUIE/inputs'
input_dir = 'C:/Users/admin/Desktop//test_input.txt'
output_dir = 'C:/Users/admin/Desktop//outputs'
tagger = pipeline(task='ner', model='xlm-roberta-large-finetuned-conll03-english',
aggregation_strategy='simple')
keywords = {'PER': ' people ', 'ORG': ' Institutions '} # loc Location misc Other types of entities
# for filename in tqdm(input_dir):
# # Read data and mark automatically
# json_list = []
with open(input_dir, 'r', encoding='utf8') as f:
text = f.readlines()
json_list = [0 for i in range(len(text))]
for t in text:
i = t.strip("\n").strip("'").strip('"')
named_ents = tagger(i) # Pre training model
# named_ents = tagger(text)
df = pd.DataFrame(named_ents)
""" Mark the results :entity_group score word start end
0 ORG 0.999997 National Science Board 18 40
1 ORG 0.999997 NSB 42 45
2 ORG 0.999997 NSF 71 74"""
# Put it in the loop , Then every time we start a new cycle, we will redefine it , The content defined last time is lost
# json_list = [0 for i in range(len(text))]
entity_list=[]
# entity_list2=[]
for index, elem in df.iterrows():
if not elem.entity_group in keywords:
continue
if elem.end - elem.start <= 1:
continue
entity = return_single_entity(
keywords[elem.entity_group], elem.start, elem.end)
entity_list.append(entity)
# entity_list2.append(entity_list)
json_obj = {"text": text[index], "label": entity_list}
json_list[index] = json.dumps(json_obj)
# entity_list.append(entity)
# data = json.dumps(json_list)
# json_list.append(data)
with open(f'{output_dir}/data_2.json', 'w', encoding='utf8') as f:
for line in json_list:
f.write(line+"\n")
# f.write('\n'.join(data))
# f.write(str(data))
print('done!')
# Convert to wizard annotation assistant import format ( But the elf annotation assistant nlp There is a coding problem in the annotation module , part utf8 Characters cannot be displayed normally , It will affect the annotation results )
# id = 1
# entity_list = ['']
# for index, elem in df.iterrows():
# if not elem.entity_group in keywords:
# continue
# entity = return_single_entity(keywords[elem.entity_group], elem.word, elem.start, elem.end, id)
# id += 1
# entity_list.append(entity)
# python_obj = {'path': f'{input_dir}/{filename}',
# 'outputs': {'annotation': {'T': entity_list, "E": [""], "R": [""], "A": [""]}},
# 'time_labeled': int(1000 * time()), 'labeled': True, 'content': text}
# data = json.dumps(python_obj)
# with open(f'{output_dir}/{filename.rstrip(".txt")}.json', 'w', encoding='utf8') as f:
# f.write(data)Recognition result :
{"text": "The company was founded in 1852 by Jacob Estey\n", "label": [[35, 46, "\u4eba"]]}
{"text": "The company was founded in 1852 by Jacob Estey, who bought out another Brattleboro manufacturing business.", "label": [[35, 46, "\u4eba"], [71, 82, "\u673a\u6784"]]}
You can see label The label is garbled , Don't worry about importing to doccano The platform will display normal

3.2 Multiple essays (txt file )
from transformers import pipeline
import os
from tqdm import tqdm
import pandas as pd
import json
def return_single_entity(name, start, end):
return [int(start), int(end), name]
input_dir = 'C:/Users/admin/Desktop/inputs_test'
output_dir = 'C:/Users/admin/Desktop//outputs'
tagger = pipeline(task='ner', model='xlm-roberta-large-finetuned-conll03-english', aggregation_strategy='simple')
json_list = []
keywords = {'PER': ' people ', 'ORG': ' Institutions '}
for filename in tqdm(os.listdir(input_dir)[:3]):
# Read data and mark automatically
with open(f'{input_dir}/{filename}', 'r', encoding='utf8') as f:
text = f.read()
named_ents = tagger(text)
df = pd.DataFrame(named_ents)
# Turn into doccano Import format
entity_list = []
for index, elem in df.iterrows():
if not elem.entity_group in keywords:
continue
if elem.end - elem.start <= 1:
continue
entity = return_single_entity(keywords[elem.entity_group], elem.start, elem.end)
entity_list.append(entity)
file_obj = {'text': text, 'label': entity_list}
json_obj = json.dumps(file_obj)
json_list.append(json_obj)
with open(f'{output_dir}/data3.json', 'w', encoding='utf8') as f:
f.write('\n'.join(json_list))
print('done!')
3.3 Including annotation wizard format, which requires conversion
from transformers import pipeline
import os
from tqdm import tqdm
import pandas as pd
from time import time
import json
def return_single_entity(name, word, start, end, id, attributes=[]):
entity = {}
entity['type'] = 'T'
entity['name'] = name
entity['value'] = word
entity['start'] = int(start)
entity['end'] = int(end)
entity['attributes'] = attributes
entity['id'] = int(id)
return entity
input_dir = 'E:/datasets/myUIE/inputs'
output_dir = 'E:/datasets/myUIE/outputs'
tagger = pipeline(task='ner', model='xlm-roberta-large-finetuned-conll03-english', aggregation_strategy='simple')
keywords = {'PER': ' people ', 'ORG': ' Institutions '}
for filename in tqdm(os.listdir(input_dir)):
# Read data and mark automatically
with open(f'{input_dir}/{filename}', 'r', encoding='utf8') as f:
text = f.read()
named_ents = tagger(text)
df = pd.DataFrame(named_ents)
# Convert to wizard annotation assistant import format ( But the elf annotation assistant nlp There is a coding problem in the annotation module , part utf8 Characters cannot be displayed normally , It will affect the annotation results )
id = 1
entity_list = ['']
for index, elem in df.iterrows():
if not elem.entity_group in keywords:
continue
entity = return_single_entity(keywords[elem.entity_group], elem.word, elem.start, elem.end, id)
id += 1
entity_list.append(entity)
python_obj = {'path': f'{input_dir}/{filename}',
'outputs': {'annotation': {'T': entity_list, "E": [""], "R": [""], "A": [""]}},
'time_labeled': int(1000 * time()), 'labeled': True, 'content': text}
data = json.dumps(python_obj)
with open(f'{output_dir}/{filename.rstrip(".txt")}.json', 'w', encoding='utf8') as f:
f.write(data)
print('done!')
边栏推荐
- 【opencv】图像形态学操作-opencv标记不同连通域的位置
- 想要选择一些部门优先使用 OKR, 应该如何选择试点部门?
- A cool "ghost" console tool
- U++ game learning notes
- MySQL数据库学习(8) -- mysql 内容补充
- Annotation初体验
- 张平安:加快云上数字创新,共建产业智慧生态
- 删除文件时提示‘源文件名长度大于系统支持的长度’无法删除解决办法
- [opencv] image morphological operation opencv marks the positions of different connected domains
- Pytest testing framework -- data driven
猜你喜欢
Salesforce 容器化 ISV 场景下的软件供应链安全落地实践
Longest palindrome substring (dynamic programming)
一条 update 语句的生命经历
Is it necessary to renew the PMP certificate?

数字化如何影响工作流程自动化

pmp真的有用吗?

Under the trend of Micah, orebo and apple homekit, how does zhiting stand out?
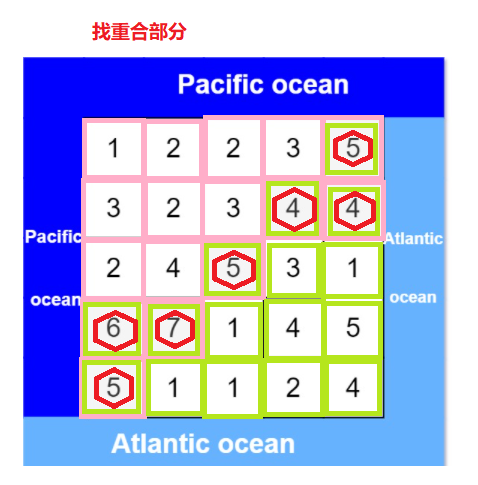
Leetcode(417)——太平洋大西洋水流问题
y58.第三章 Kubernetes从入门到精通 -- 持续集成与部署(三一)
记录一次压测经验总结
随机推荐
2039: [Bluebridge cup 2022 preliminaries] Li Bai's enhanced version (dynamic planning)
DFS,BFS以及图的遍历搜索
Phenomenon analysis when Autowired annotation is used for list
AIDL 与Service
删除文件时提示‘源文件名长度大于系统支持的长度’无法删除解决办法
Pytest testing framework -- data driven
batch size设置技巧
Is it necessary to renew the PMP certificate?
背包问题(01背包,完全背包,动态规划)
腾讯云数据库公有云市场稳居TOP 2!
痛心啊 收到教训了
Torch optimizer small parsing
Two methods of thread synchronization
Record a pressure measurement experience summary
Dynamically generate tables
PMP证书有没有必要续期?
Tencent cloud database public cloud market ranks top 2!
AOSP ~binder communication principle (I) - Overview
Leetcode(417)——太平洋大西洋水流问题
Let f (x) = Σ x^n/n^2, prove that f (x) + F (1-x) + lnxln (1-x) = Σ 1/n^2