当前位置:网站首页>Are you still reading the log by command? Use kibana, one picture is better than ten thousand lines of log
Are you still reading the log by command? Use kibana, one picture is better than ten thousand lines of log
2022-06-29 14:13:00 【The way of Python data】
link :https://www.cnblogs.com/cjsblog/p/9476813.htmlKibana Is an open source analysis and visualization platform , Designed for and Elasticsearch Working together .
Do you use Kibana To search for , see , And stored in Elasticsearch The data in the index interacts .
You can easily perform advanced data analysis , And with various icons 、 Visualization of data in the form of tables and maps .
Kibana Makes it easy to understand a lot of data . It's simple 、 A browser based interface allows you to quickly create and share dynamic dashboards , real-time display Elasticsearch Changes in queries .
install Kibana


Kibana To configure
https://www.elastic.co/guide/en/kibana/current/settings.html
visit Kibana
Kibana It's a Web Applications , You can go through 5601 To access it . for example :localhost:5601 perhaps http://YOURDOMAIN.com:5601
When accessing Kibana when , By default ,Discover The default index mode was selected when the page was loaded . The time filter is set to recent 15 minute , The search query is set to match-all(*)
Check Kibana state
http://localhost:5601/status

perhaps http://192.168.101.5:5601/api/status return JSON Format status information
use Elasticsearch Connect to Kibana
Before you start using Kibana Before , You need to tell Kibana Which one do you want to explore Elasticsearch Indexes . First visit Kibana yes , You will be prompted to define an index pattern to match the names of one or more indexes .
( Tips : By default ,Kibana The connection is allowed in localhost Upper Elasticsearch example . In order to connect to a different Elasticsearch example , modify kabana.yml in Elasticsearch Of URL, And then restart Kibana.)
In order to configure you want to use Kibana Access to the Elasticsearch Indexes :
1、 visit Kibana UI. for example ,localhost:56011 perhaps http://YOURDOMAIN.com:5601
2、 Specify an index pattern to match one or more of your Elasticsearch Indexes . When you specify your index mode , Any matching index will be displayed .( Voice over :* matching 0 Characters or more ; The index is specified by default to match the index , Exactly match index names )
3、 Click on “Next Step” To select the inclusion you want to use to perform time-based comparisons timestamp Index of field . If your index doesn't have time-based data , So choose “I don’t want to use the Time Filter” Options .
4、 Click on “Create index pattern” Button to add index mode . The first index mode is automatically configured as the default index default , Later when you have multiple index patterns , You can choose which is the default .( Tips :Management > Index Patterns)



Now? ,Kibana Has been connected to your Elasticsearch data .Kibana Shows a read-only list of fields , These fields are the matched fields of this index configuration .
Discover
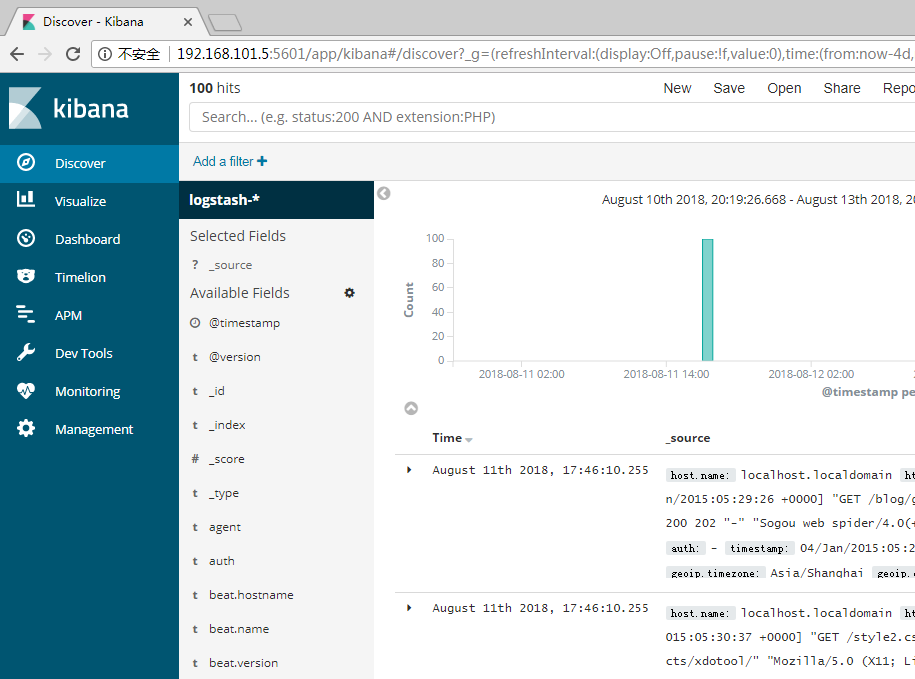
You can start your Discover Explore your data interactively . You can access each document in each index that matches the selected index by default . You can submit a query request , Filter search structure , And view the document data . You can also see the number of documents that match the query request , And field value statistics . If the index mode you choose is configured time Field , The distribution of documents over time will be displayed in the histogram at the top of the page .
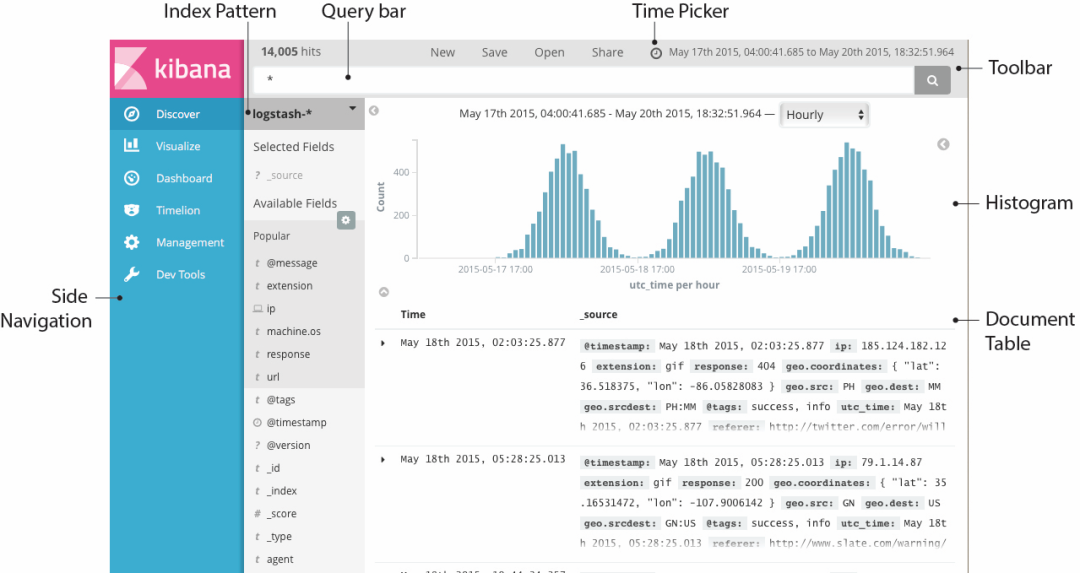
Set time filter



Search data
You can enter the query criteria in the search box to query the index matching the current index pattern . At query time , You can use Kibana Standard query language ( be based on Lucene Query syntax of ) Or based entirely on JSON Of Elasticsearch query language DSL.Kibana Query languages can use automatic completion and simplified query syntax as experimental features , You can find it in the “ Options ” Select from the menu .
When you submit a query request , Histogram 、 The document table and field list are updated , To reflect the search results . hit ( Matching document ) The total is displayed in the toolbar . The document table shows the previous 500 Hits . By default , In reverse chronological order , First show the latest document . You can click “Time” Column to reverse the sort order .


Lucene The query syntax
Kibana The query language is based on Lucene The query syntax . Here are some tips , It might help you :
To perform a text search , You can simply enter a text string . for example , If you want to search web Log of the server , You can type keywords "safari", So you can search for all the information about "safari" Field of
To search for a specific value for a specific field , You can prefix it with the name of the field . for example , You type "status:200", Will find all status The value of the field is 200 Documents
To search for a range value , You can use bracket range syntax ,[START_VALUE TO END_VALUE]. for example , To find the status code is 4xx Documents , You can type status:[400 TO 499]
To specify changing complex query criteria , You can use Boolean operators AND , OR , and NOT. for example , To find the status code is 4xx also extension The fields are php perhaps html Documents , You can type status:[400 TO 499] AND (extension:php OR extension:html)

Kibana Query syntax enhancement
New, Simpler Syntax
If you are familiar with Kibana The old Lucene The query syntax , Then you should be familiar with this new grammar . The fundamentals remain the same , We've simply improved something , Make the query language easier to use .
response:200 Will match response The value of the field is 200 Documents
A string enclosed in quotation marks is called phrase search . for example ,message:"Quick brown fox" Will be in message Search for "quick brown fox" The phrase . If there are no quotes , Will match to all documents that contain these words , Regardless of their order . That means , Will match to the "Quick brown fox", It doesn't match "quick fox brown".( Voice over : Quotation marks arise as a whole )
The query parser will no longer split based on Spaces . Multiple search terms must be separated by explicit Boolean operators . Be careful , Boolean operators are case insensitive .
stay Lucene in ,response:200 extension:php Equivalent to response:200 and extension:php. This will match response Field values match 200 also extenion Field values match php Documents .
If we change the middle to or, that response:200 or extension:php Will match response Field matching 200 perhaps extension Field matching php Documents .
By default ,and Than or Higher priority .
response:200 and extension:php or extension:css Will match response yes 200 also extension yes php, Or match extension yes css and response arbitrarily
Brackets can change this priority
response:200 and (extension:php or extension:css) Will match response yes 200 also extension yes php perhaps css Documents
There is also a way to abbreviate :
response:(200 or 404) Will match response The fields are 200 or 404 Documents . Character values can also be multiple , such as :tags:(success and info and security)
You can also use not
not response:200 Will match response No 200 Documents
response:200 and not (extension:php or extension:css) Will match response yes 200 also extension No php Neither css Documents
Scope search and Lucene It's a little different
Instead of byte:>1000, We use it byte > 1000
“, >=, <, <= Are all valid operators
”
response:* Will match all existing response Document for field
Wildcard queries are also possible .machine.os:win* Will match machine.os Field to win The opening document , image "windows 7" and "windows 10" Such values will be matched to .
Wildcards also allow us to search multiple fields at once , for example , Suppose we have machine.os and machine.os.keyword Two fields , We want to search for both fields "windows 10", So we can write like this "machine.os*:windows 10"
Refresh search results

Filter by field
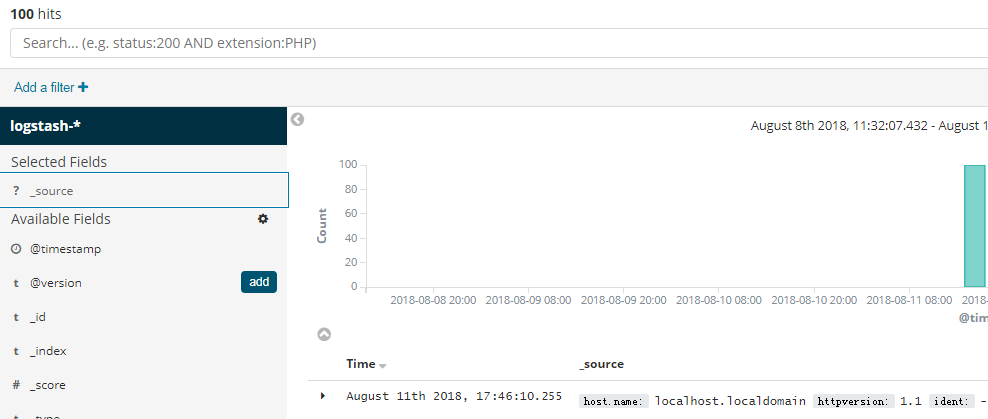
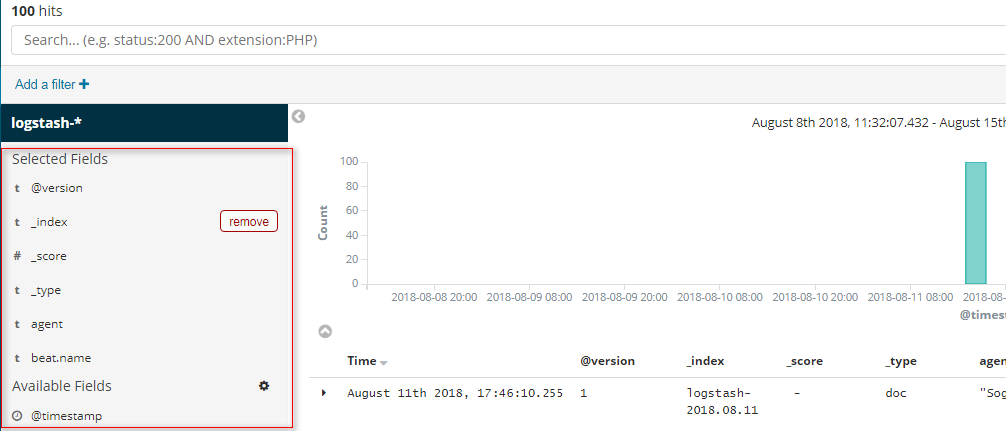
These are the fields displayed in the control list , Another way is to click the small book like icon when viewing the document data

Deletion is also possible

We can also edit a DSL Query statement , For filtering , for example

View document data


View the document context

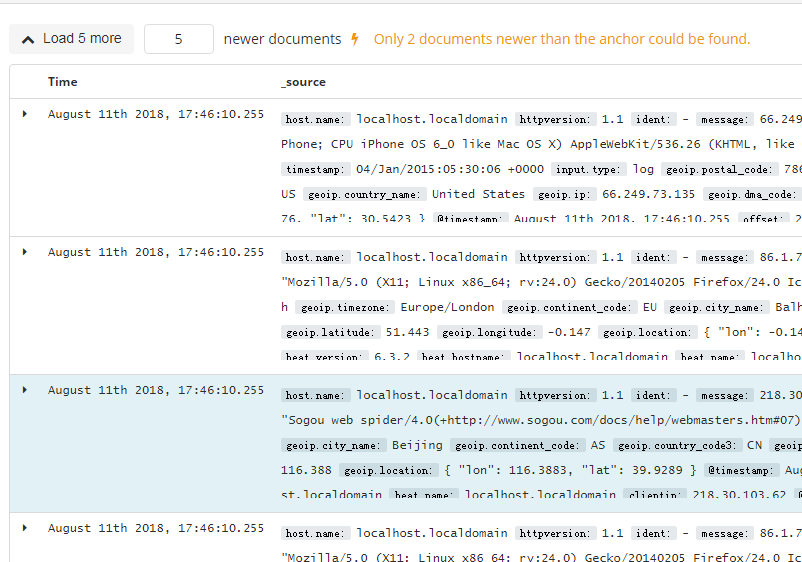
View field statistics


Visualize
Visualize So that you can create in your Elasticsearch Visualization of data in an index . then , You can build dashboard To show the relevant Visualization .
Kibana Visualization is based on Elasticsearch Of the query . By using a series of Elasticsearch Aggregate to extract and process your data , You can create images to show the trends you need to know online 、 Peaks and lows .
Create a visualization
To create a visual view :
The first 1 Step : Click... In the left navigation bar “Visualize” Button
The first 2 Step : Click on “Create new visualization” Button or
**plus(+)**ButtonThe first 3 Step : Choose a visualization type
The first 4 Step : Specify a search query to retrieve visual data
The first 5 Step : Select... In the visual builder Y The aggregation operation of the axis . for example ,sum,average,count wait
The first 6 Step : Set up X Axis
for example :




Dashboard
Kibana The dashboard displays a collection of visualizations and searches . You can arrange 、 Adjust and edit dashboard content , Then save the dashboard to share it .
Construct a Dashboard
The first 1 Step : Click on the navigation bar “Dashboard”
The first 2 Step : Click on “Create new dashboard” perhaps “ plus (+)” Button
The first 3 Step : Click on “Add” Button
The first 4 Step : To add a visualization , Select one from the visualization list , Or click “Add new visualization” Button to create a new
The first 5 Step : To add a saved query , Click on “Saved Search” tab , Then select one from the list
The first 6 Step : When you're done adding and adjusting dashboard After the content of , Go to the top menu bar , Click on “Save”, Then type in a name .
By default ,Kibana The dashboard uses a light color theme . To use a dark theme , single click “ Options ” And select “ Use a dark theme ”. To put dark Theme set to default , Please go to Administration >Management > Advanced , And will dashboard:defaultDarkTheme Set to On.

Monitoring
Elasticsearch Console print log
[2018-08-15T14:48:26,874][INFO ][o.e.c.m.MetaDataCreateIndexService] [Px524Ts] [.monitoring-kibana-6-2018.08.15] creating index, cause [auto(bulk api)], templates [.monitoring-kibana], shards [1]/[0], mappings [doc]Kibana Console print log
log [03:26:53.605] [info][license][xpack] Imported license information from Elasticsearch for the [monitoring] cluster: mode: basic | status: active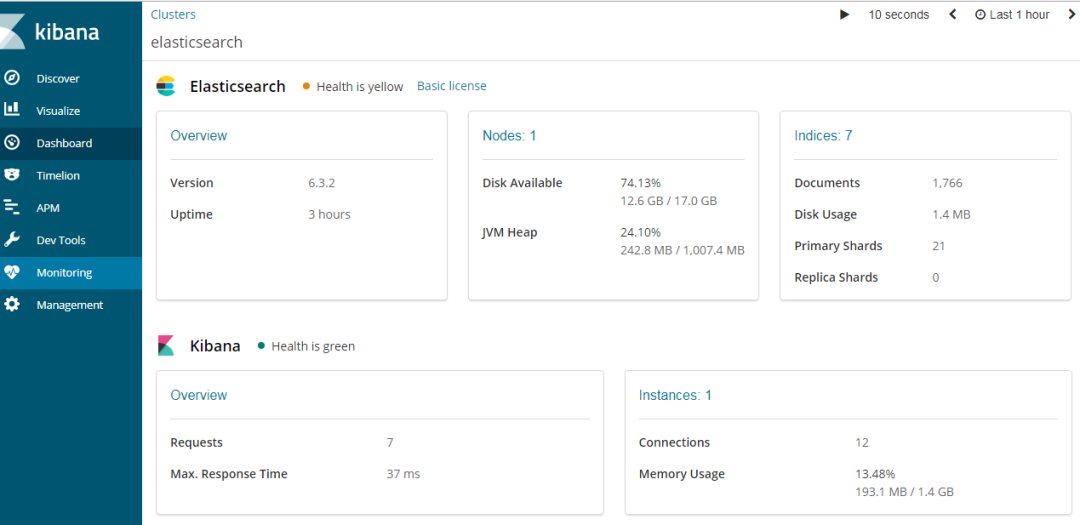



边栏推荐
- 如何优雅的写 Controller 层代码?
- 喜迎市科协“十大”•致敬科技工作者 | 卢毅:守护电网传输安全的探索者
- 纳人才,谋发展 | 人大金仓喜获“最佳雇主校招案例奖”
- Leetcode question brushing: String 07 (repeated substring)
- College girls wear cheongsam to defend! Netizen: the tutor said it would be nice if the paper were as beautiful as the cheongsam
- NuScenes关于Radar的配置信息
- 内网穿透(nc)
- 微信小程序:全新獨家雲開發微群人脈
- Which is better and safer for Dongguan Humen securities company to open a stock account?
- 一次mysql的.ibd文件过大处理过程记录
猜你喜欢

Investors fell off the altar: 0 sales in half a year, transferred to business and delivered takeout

Installation and removal of cover for CPU protection on desktop motherboard

BYD has three years left

数字IC手撕代码--交通灯

Wechat applet: Yunkai publishes white wall wechat applet source code download server free and domain name support traffic main revenue

微信小程序:大红喜庆版UI猜灯谜又叫猜字谜

动荡的中介生意,不安的租房人

Unity SplashImage 缩放问题

uniApp问题清单与经验

mysql函数和约束
随机推荐
中康控股开启招股:拟募资净额3.95亿港元,预计7月12日上市
Redis哨兵机制原理详解
Interview high concurrent, cool!! (high energy in the whole process, collection recommended)
Turbulent intermediary business, restless renters
MySQL数据库:存储引擎
传输层 选择性确认 SACK
[high concurrency] 28000 words' summary of callable and future interview knowledge points. After reading it, I went directly to ByteDance. Forgive me for being a little drifting (Part 1)
golang代码规范整理
Go unit testing introductory practice
Stable currency risk profile: are usdt and usdc safe?
【重要通知】中国图象图形学学会2022年度系列奖励推荐工作启动
微信小程序:云开发表白墙微信小程序源码下载免服务器和域名支持流量主收益
leetcode:226. Flip binary tree
Dynamic feedback load balancing strategy based on Cluster
[network bandwidth] Mbps & Mbps
Normalization layer of pytorch learning (batchnorm, layernorm, instancenorm, groupnorm) [easy to understand]
常用postgresql数据操作备忘:时间
Introduction to reverse commissioning -pe file section table and block 03/07
Istio网格中访问外部服务方法
Navicat连接MySQL8.0的正确方法(亲测有效)