当前位置:网站首页>Weekly Report 2022-8-4
Weekly Report 2022-8-4
2022-08-05 09:05:00 【Alice01010101】
周报2022-8-4
一、MoE(Mixture of Experts)相关论文
Adaptive mixtures of local experts, Neural Computation’1991
- 参考:https://zhuanlan.zhihu.com/p/542465517
- 期刊/会议:Neural Computation (1991)
- 论文链接:https://readpaper.com/paper/2150884987
- Representative authors:Michael Jordan, Geoffrey Hinton
- Main Idea:
A new supervised learning process is proposed,A system contains multiple separate networks,Each network processes a subset of all training samples.This approach can be seen as a modular transformation of the multi-layer network.
Suppose we already know that there are some natural subsets in the dataset(such as from differentdomain,不同的topic),Then use a single model to learn,There will be a lot of interference(interference),lead to slow learning、Generalization is difficult.这时,We can use multiple models(i.e. expert,expert)去学习,Use a gate network(gating network)to decide which model should be trained on each data,This mitigates interference between different types of samples.
Actually this approach,Nor is it the first time the paper has been proposed,Similar methods have been proposed earlier.对于一个样本c,第i个 expert 的输出为 o i c o_i^c oic理想的输出是 d c d^c dc,Then the loss function is calculated like this: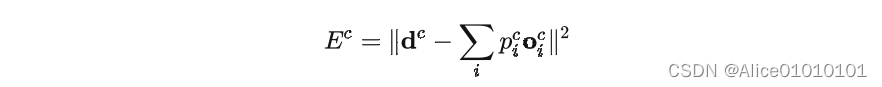
其中 p i c p_i^c pic是 gating network 分配给每个 expert 的权重,相当于多个 expert Work together to get the current sample c c c的输出.
This is a very natural way of designing,但是存在一个问题——不同的 expert The interaction between them will be very large,一个expertparameters have changed,Everything else will follow,That is to say, pulling one hair and moving the whole body.这样的设计,The end result is that one sample will be used a lotexpert来处理.于是,This article designs a new way,调整了一下loss的设计,to encourage the differentexpert之间进行竞争: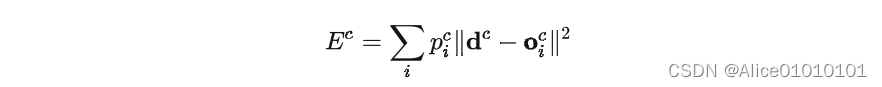
就是让不同的 expert 单独计算 loss,Then the weighted sum is obtained to get the overall loss.这样的话,每个专家,have the ability to make independent judgments,rather than relying on others expert Let's get predictions together.下面是一个示意图: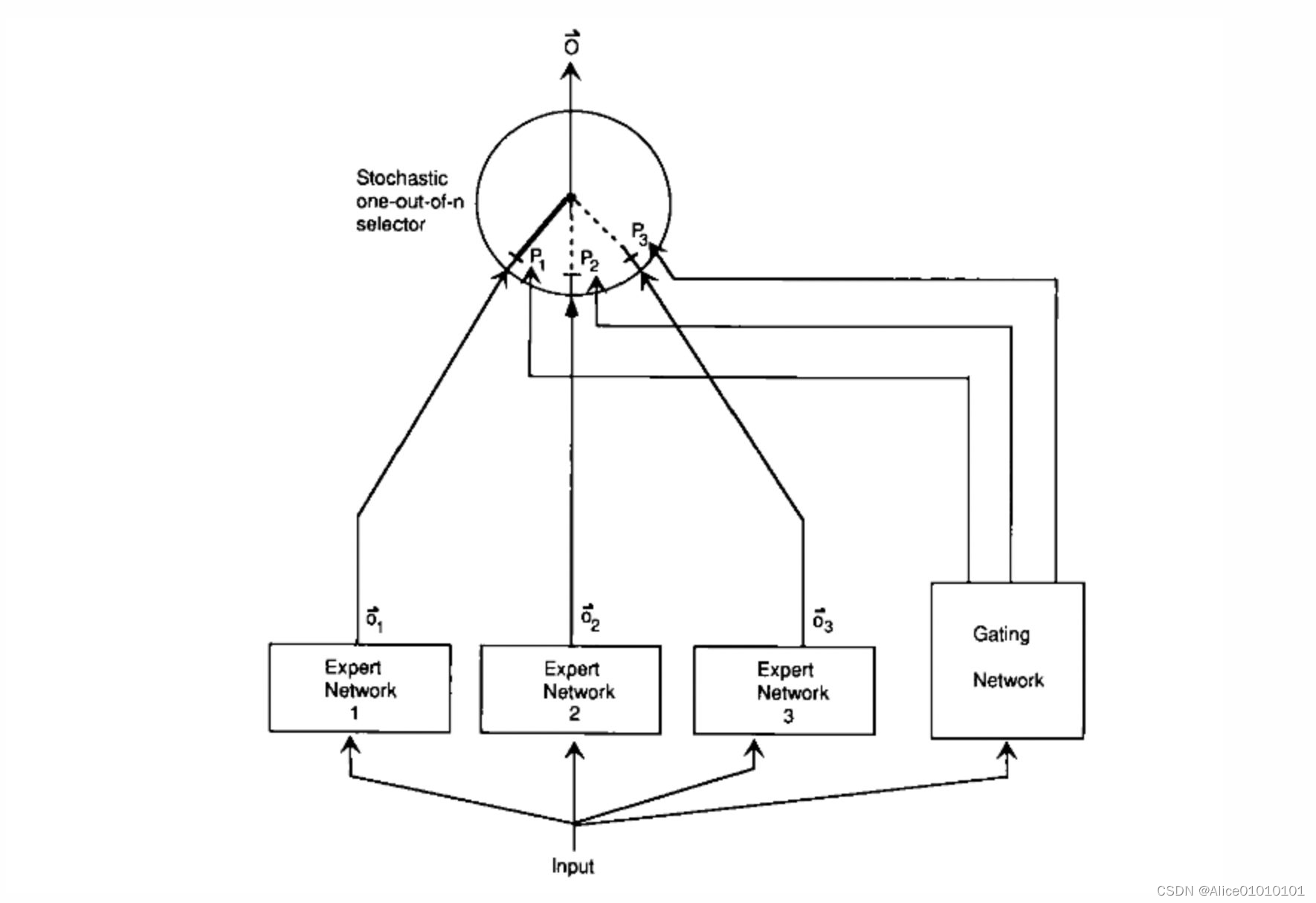
在这种设计下,我们将 experts 和 gating network 一起进行训练,The final system will tend to allow one expert to process a sample.
上面的两个 loss function,Actually looks very similar,But one is to encourage cooperation,One is to encourage competition.This is still quite inspiring.
The paper also mentions another very inspiring trick,This is the loss function above,When the author is actually doing the experiment,A variant was used,使得效果更好: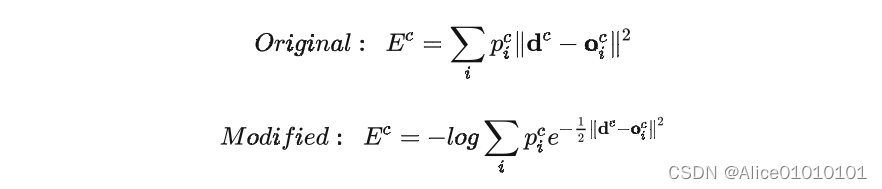
It can be seen by comparison,在计算每个 expert after the loss,It is first indexed and then weighted and summed,最后取了log.This is also a technique we often see in papers.这样做有什么好处呢,We can compare the effects of the two in backpropagation,使用 E c E^c Ec对第 i i i个 expert The output of derivation,分别得到: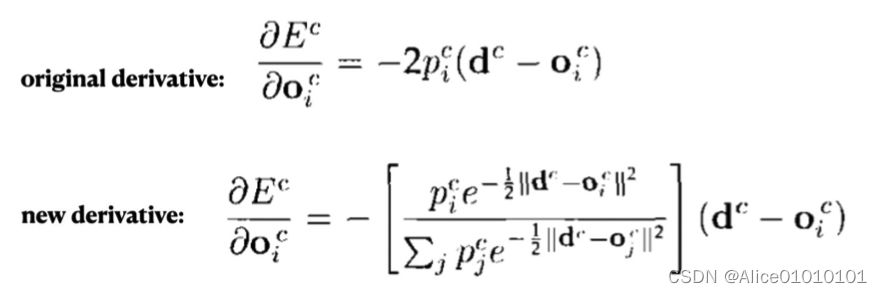
可以看到,derivative of the former,Just follow the current expert 有关,But the latter also considers others experts 跟当前 sample c的匹配程度.换句话说,如果当前 sample 跟其他的 experts also match,那么 E c E^c Ec对 第 i i i个 expert The derivative of the output will also be relatively smaller.(Actually look at this formula,Contrast learning with what we are now everywhereloss真的很像!很多道理都是相通的)

二、Perceiver相关
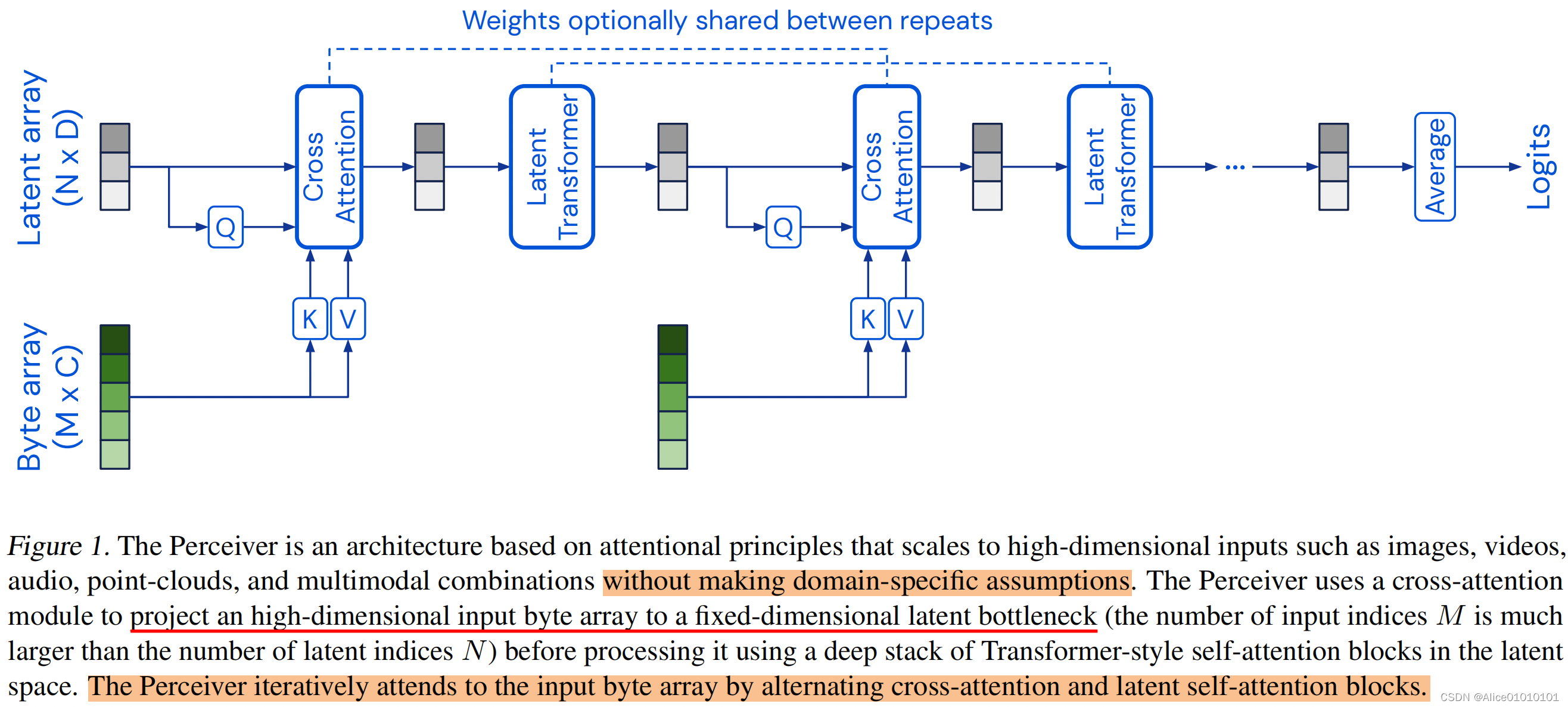
optical flow

- Task definition:Transfer
- Problem: No large-scale realistic training data!
- Typical protocol:
- Train on highly synthetic scenes(AutoFlow)
- Transfer to more realistic scenes(Sintel,KITTI)
三、多模态ViLT
特色:Multimodal Papers,Remove the target detection fieldRegion Feature.在ViT之前,Processing of image pixels,VLPMainly choose the object detector,Make dense image pixel generation as characteristic、Discretized representation.ViLTThe core idea is for referenceViT,将图像划分为patch,by means of linear mappingpatch转换为embedding,Avoid the tedious process of image feature extraction.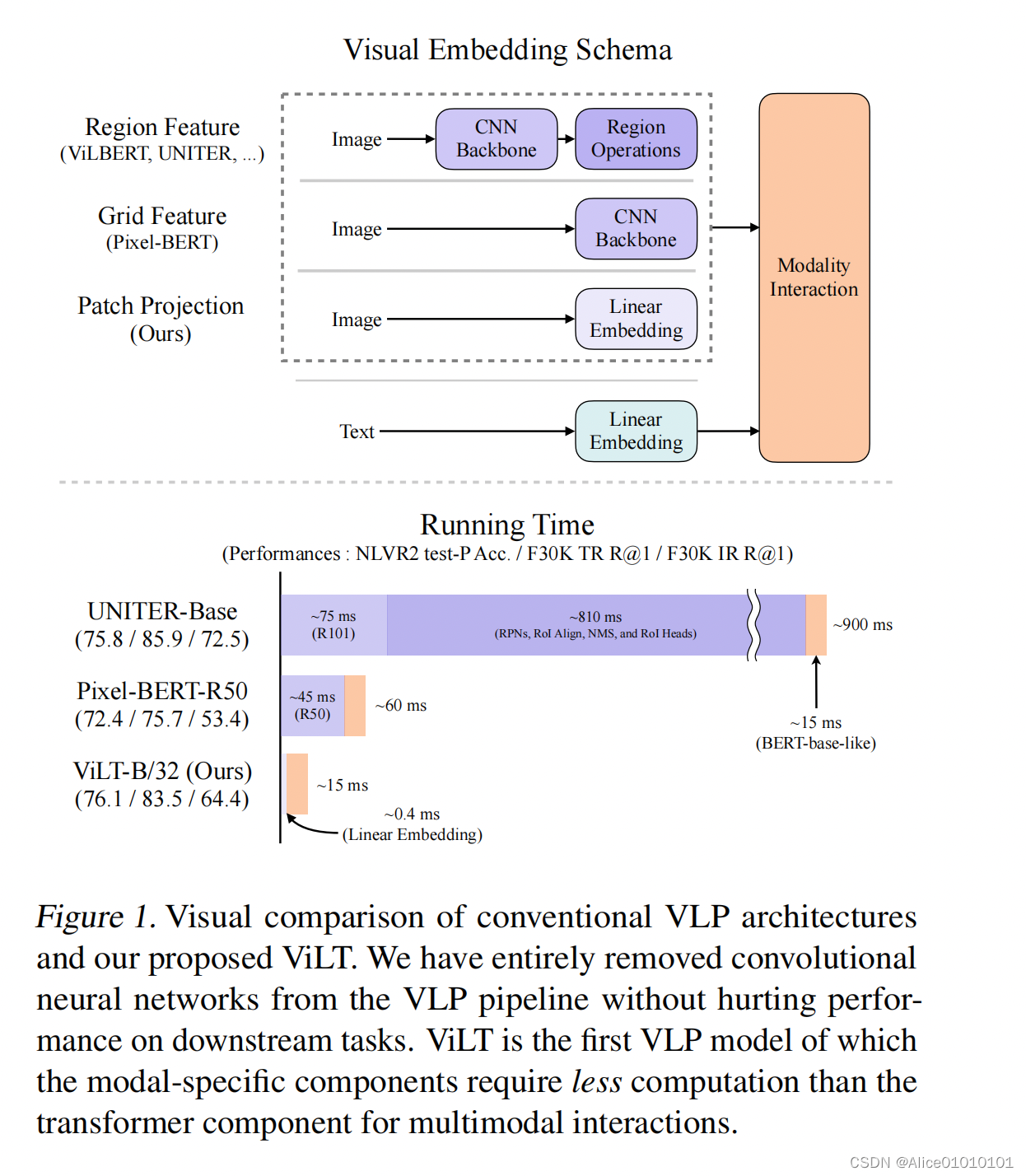
- ViLT is the simplest architecture by far for a vision-and-language model as it commissions the transformer module to extract and process visual features in place of a separate deep visual embedder. This design inherently leads to significant runtime and parameter efficiency.
- For the first time, we achieve competent performance on vision-and-language tasks without using region features or deep convolutional visual embedders in general.
- Also, for the first time, we empirically show that whole word masking and image augmentations that were unprecedented in VLP training schemes further drive downstream performance.
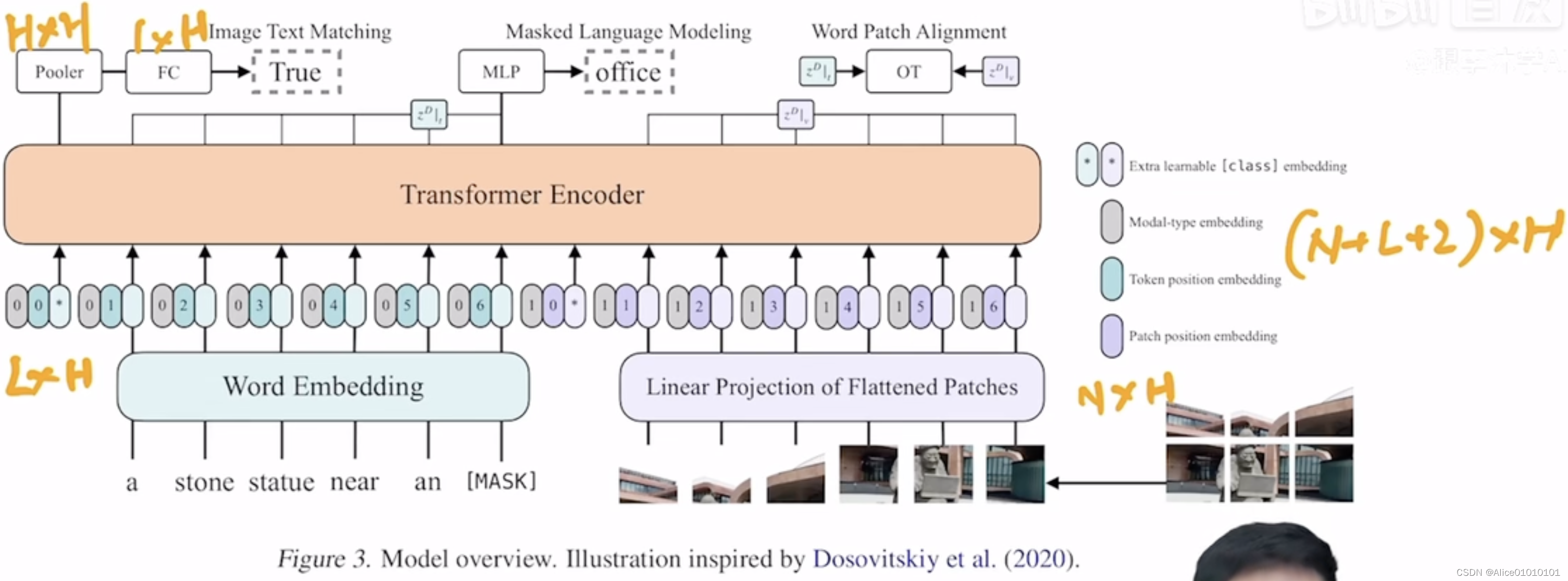
Multimodality needs to keep the text and image matching.So when doing data augmentation of images and text,需要保持一致.
建议:Read recent papersfuture workSee if there is a hole to fill.
边栏推荐
猜你喜欢
pytorch余弦退火学习率CosineAnnealingLR的使用
最 Cool 的 Kubernetes 网络方案 Cilium 入门教程
链表中的数字相加----链表专题
网页直接访问链接不让安全中心拦截

MySQL database error The server quit without updating PID file (/var/lib/mysql/localhost.localdomain.pid)
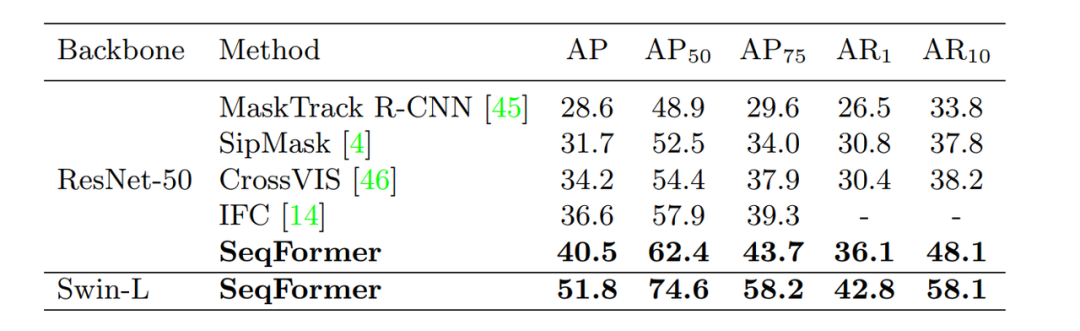
ECCV 2022 Oral 视频实例分割新SOTA:SeqFormer&IDOL及CVPR 2022 视频实例分割竞赛冠军方案...
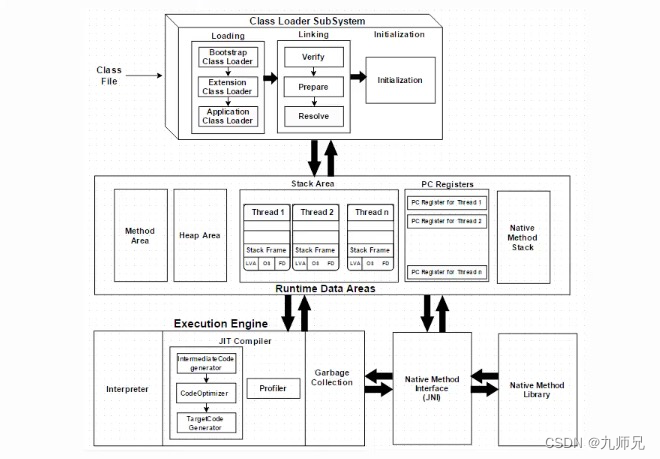
【ASM】字节码操作 方法的初始化 Frame
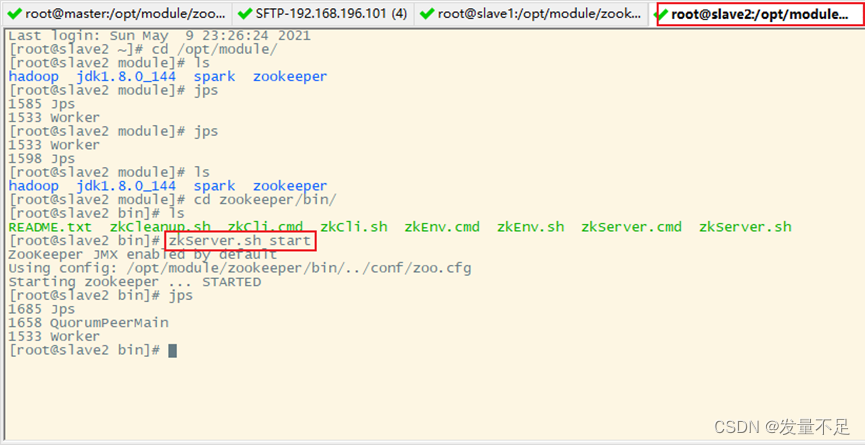
Spark cluster deployment (third bullet)
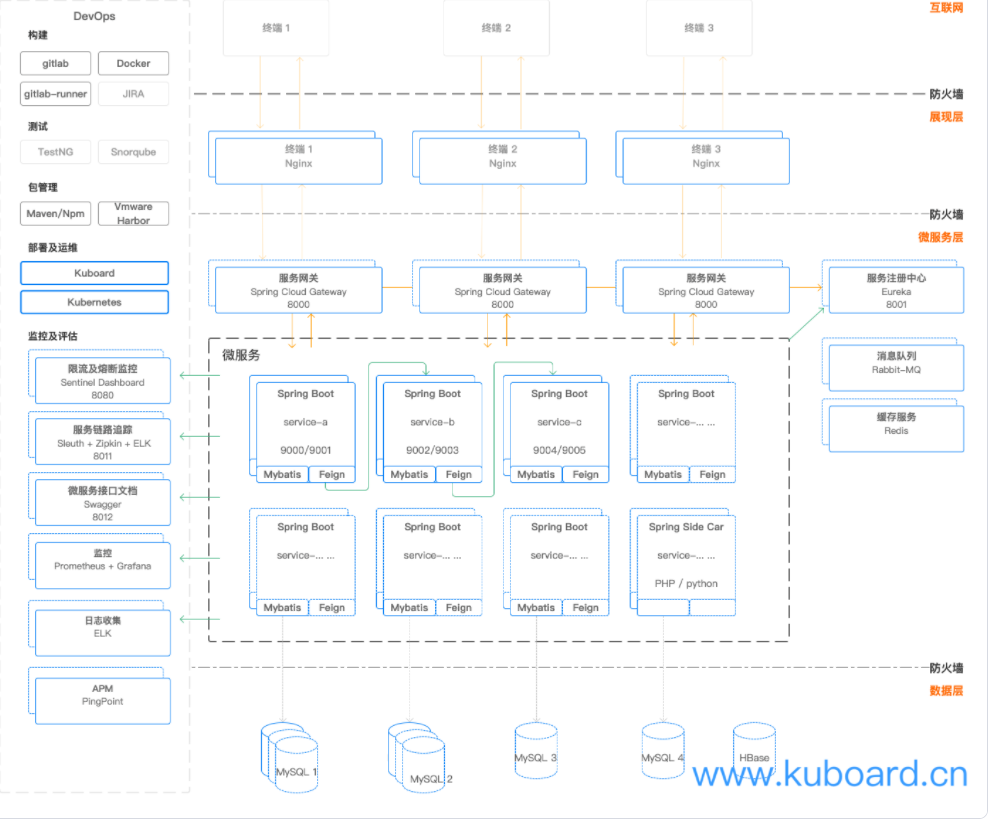
基于 Kubernetes 的微服务项目整体设计与实现
画法几何及工程制图考试卷A卷
随机推荐
Luogu: P2574 XOR的艺术 [线段树]
CROS and JSONP configuration
七夕看什么电影好?爬取电影评分并存入csv文件
thinkPHP5 realizes clicks (data increment/decrement)
动态库之间回调函数使用
最 Cool 的 Kubernetes 网络方案 Cilium 入门教程
这样写有问题吗?怎么在sql-client 是可以做到数据的同步的
selectPage 动态改变参数方法
ps怎么替换颜色,自学ps软件photoshop2022,ps一张图片的一种颜色全部替换成另外一种颜色
程序员的七种武器
php fails to write data to mysql
512-color chromatogram
Thinking after writing a code with a very high CPU usage
openpyxl操作Excel文件
宝塔实测-搭建中小型民宿酒店管理源码
周报2022-8-4
生命的颜色占卜
让程序员崩溃的N个瞬间(非程序员误入)
今天是元宵节~~
thinkPHP5 实现点击量(数据自增/自减)