当前位置:网站首页>Target detection - pytorch uses mobilenet series (V1, V2, V3) to build yolov4 target detection platform
Target detection - pytorch uses mobilenet series (V1, V2, V3) to build yolov4 target detection platform
2022-07-06 08:38:00 【daoboker】
object detection ——Pytorch utilize mobilenet series (v1,v2,v3) build yolov4 Target detection platform
Learn foreword
Let's see how to use mobilenet Series construction yolov4 Target detection platform .
Source code download
https://github.com/bubbliiiing/mobilenet-yolov4-pytorch
Network replacement implementation ideas
1、 Network structure analysis and replacement thinking analysis
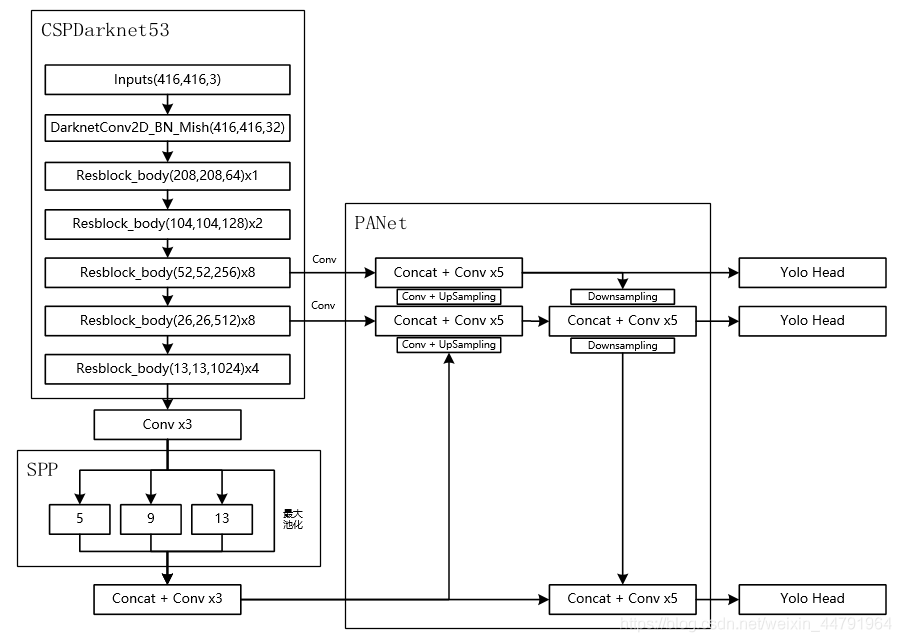
about YoloV4 for , The whole network structure can be divided into three parts .
Namely :
1、 Backbone feature extraction network Backbone, Corresponding to... On the image CSPdarknet53
2、 Strengthen the feature extraction network , Corresponding to... On the image SPP and PANet
3、 Prediction network YoloHead, Use the obtained features to predict
among :
The first part Backbone feature extraction network The function of is to Preliminary feature extraction , Extract network information using backbone features , We can get three Preliminary effective characteristic layer .
The second part Strengthen the feature extraction network The function of is to Enhanced feature extraction , Using enhanced feature extraction network , We can talk about three Preliminary effective characteristic layer Feature fusion , Extract better features , Get three More effective feature layer .
The third part Prediction network The function of is to use more effective special layer to obtain prediction results .
In these three parts , The first 1 Section and section 2 Parts can be modified more easily . The first 3 Some modifiable contents are not big , After all, it's just 3x3 Convolution sum 1x1 The combination of convolutions .
mobilenet A series of networks can be used for classification , Its main part is used for feature extraction , We can use mobilenet Series network replaces yolov4 In the middle of CSPdarknet53 Feature extraction , Will three Preliminary effective characteristic layer identical shape Feature layer to enhance feature extraction , Can will mobilenet Series replacement into yolov4 In the middle .
2、mobilenet Series network introduction
This paper shares three backbone feature extraction networks , Namely mobilenetV1、mobilenetV2、mobilenetV3.
a、mobilenetV1 Introduce
MobileNet The model is Google A lightweight deep neural network is proposed for embedded devices such as mobile phones , The core idea of its use is depthwise separable convolution( Deep separable convolution block ).
For a convolution point :
Let's say I have a 3×3 The size of the convolution layer , Its input channel is 16、 The output channel is 32. Specific for ,32 individual 3×3 The size of the convolution kernel will traverse 16 Each data in one channel , Finally, the required 32 Output channels , The required parameters are 16×32×3×3=4608 individual .
Application depth separable convolution structure block , use 16 individual 3×3 The convolution kernels of size traverse 16 Channel data , Got it 16 A feature map . Before the fusion operation , Then use 32 individual 1×1 The size of the convolution kernel traverses this 16 A feature map , The required parameters are 16×3×3+16×32×1×1=656 individual .
You can see it depthwise separable convolution It can reduce the parameters of the model .
The following picture is depthwise separable convolution Structure 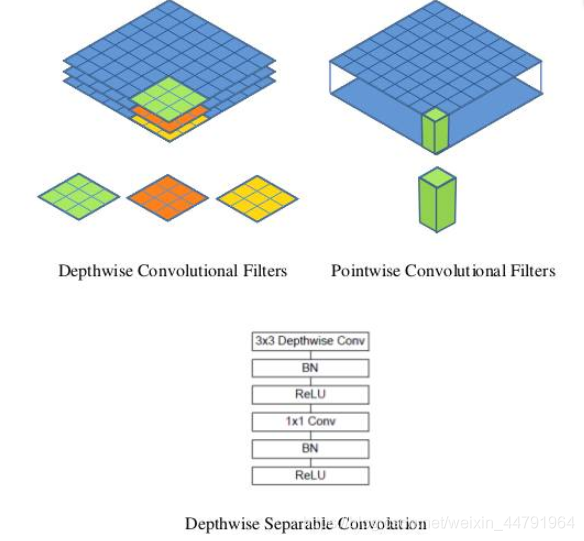
When building the model , You can convolute group Set to in_filters The layer realizes deep separable convolution , And then reuse it 1x1 Convolution adjustment channels Count .
Commonly understood as 3x3 The convolution kernel is only one layer thick , Then slide on the input tensor layer by layer , Each convolution generates an output channel , When the convolution is complete , Using 1x1 Convolution adjustment thickness of .
Here is MobileNet Structure , among Conv dw It's layered convolution , After that, there will be one 1x1 Convolution for channel processing ,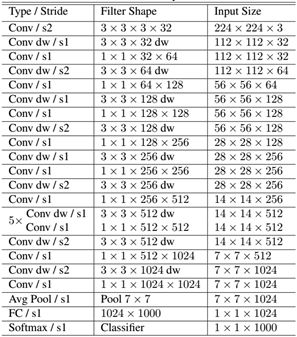
The picture above shows mobilenetV1-1 Structure , Because I can't find pytorch Of mobilenetv1 Weight resources for , I only mobilenetV1-0.25 The weight of , So this article uses mobilenetV1 The version is mobilenetV1-0.25.
mobilenetV1-0.25 yes mobilenetV1-1 The number of channels is compressed to the original 1/4 Network of .
about yolov4 Speaking of , We need to take out its last three shape Effective feature layer to enhance feature extraction .
In the code , We took out out1、out2、out3.
import time
import torch
import torch.nn as nn
import torchvision.models._utils as _utils
import torchvision.models as models
import torch.nn.functional as F
from torch.autograd import Variable
def conv_bn(inp, oup, stride = 1):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
def conv_dw(inp, oup, stride = 1):
return nn.Sequential(
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU6(inplace=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=True),
)
class MobileNetV1(nn.Module):
def __init__(self):
super(MobileNetV1, self).__init__()
self.stage1 = nn.Sequential(
# 640,640,3 -> 320,320,32
conv_bn(3, 32, 2),
# 320,320,32 -> 320,320,64
conv_dw(32, 64, 1),
# 320,320,64 -> 160,160,128
conv_dw(64, 128, 2),
conv_dw(128, 128, 1),
# 160,160,128 -> 80,80,256
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
)
# 80,80,256 -> 40,40,512
self.stage2 = nn.Sequential(
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
)
# 40,40,512 -> 20,20,1024
self.stage3 = nn.Sequential(
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
)
self.avg = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(1024, 1000)
def forward(self, x):
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.avg(x)
# x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
def mobilenet_v1(pretrained=False, progress=True):
model = MobileNetV1()
if pretrained:
print("mobilenet_v1 has no pretrained model")
return model
if __name__ == "__main__":
import torch
from torchsummary import summary
# Need to use device To specify the network at GPU still CPU function
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = mobilenet_v1().to(device)
summary(model, input_size=(3, 416, 416))
b、mobilenetV2 Introduce
MobileNetV2 yes MobileNet Upgraded version , It has a very important feature that it uses Inverted resblock, Whole mobilenetv2 All by Inverted resblock form .
Inverted resblock It can be divided into two parts :
On the left is the trunk , The first use of 1x1 Convolution is used to increase the dimension , And then use it 3x3 Depth separable convolution for feature extraction , And then reuse it 1x1 Convolution dimensionality reduction .
On the right is the residual side , The input and output are directly connected .
The overall network structure is as follows :( among Inverted resblock The operation is the above structure )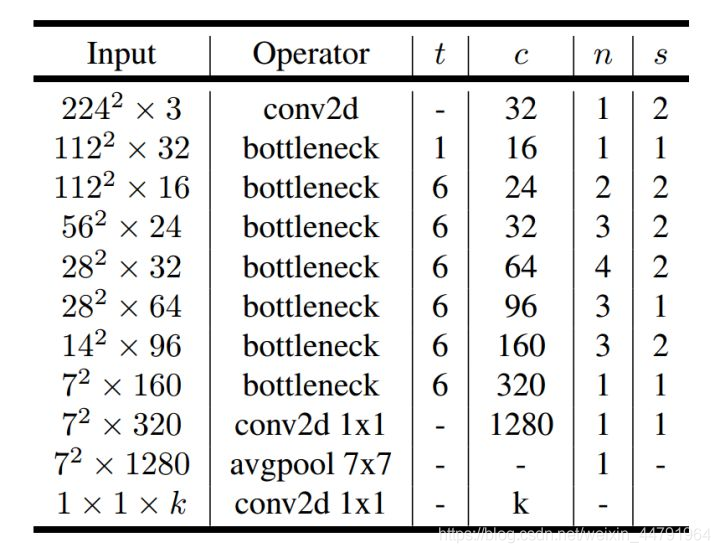
about yolov4 Speaking of , We need to take out its last three shape Effective feature layer to enhance feature extraction .
In the code , We took out out1、out2、out3.
from torch import nn
from torchvision.models.utils import load_state_dict_from_url
model_urls = {
'mobilenet_v2': 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth',
}
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
class ConvBNReLU(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_planes),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(round(inp * expand_ratio))
self.use_res_connect = self.stride == 1 and inp == oup
layers = []
if expand_ratio != 1:
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
layers.extend([
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, width_mult=1.0, inverted_residual_setting=None, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
if inverted_residual_setting is None:
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
raise ValueError("inverted_residual_setting should be non-empty "
"or a 4-element list, got {}".format(inverted_residual_setting))
input_channel = _make_divisible(input_channel * width_mult, round_nearest)
self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
features = [ConvBNReLU(3, input_channel, stride=2)]
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * width_mult, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
features.append(ConvBNReLU(input_channel, self.last_channel, kernel_size=1))
self.features = nn.Sequential(*features)
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, num_classes),
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = x.mean([2, 3])
x = self.classifier(x)
return x
def mobilenet_v2(pretrained=False, progress=True):
model = MobileNetV2()
if pretrained:
state_dict = load_state_dict_from_url(model_urls['mobilenet_v2'], model_dir="model_data",
progress=progress)
model.load_state_dict(state_dict)
return model
if __name__ == "__main__":
print(mobilenet_v2())
c、mobilenetV3 Introduce
mobilenetV3 Used a special bneck structure .
bneck The structure is shown in the following figure :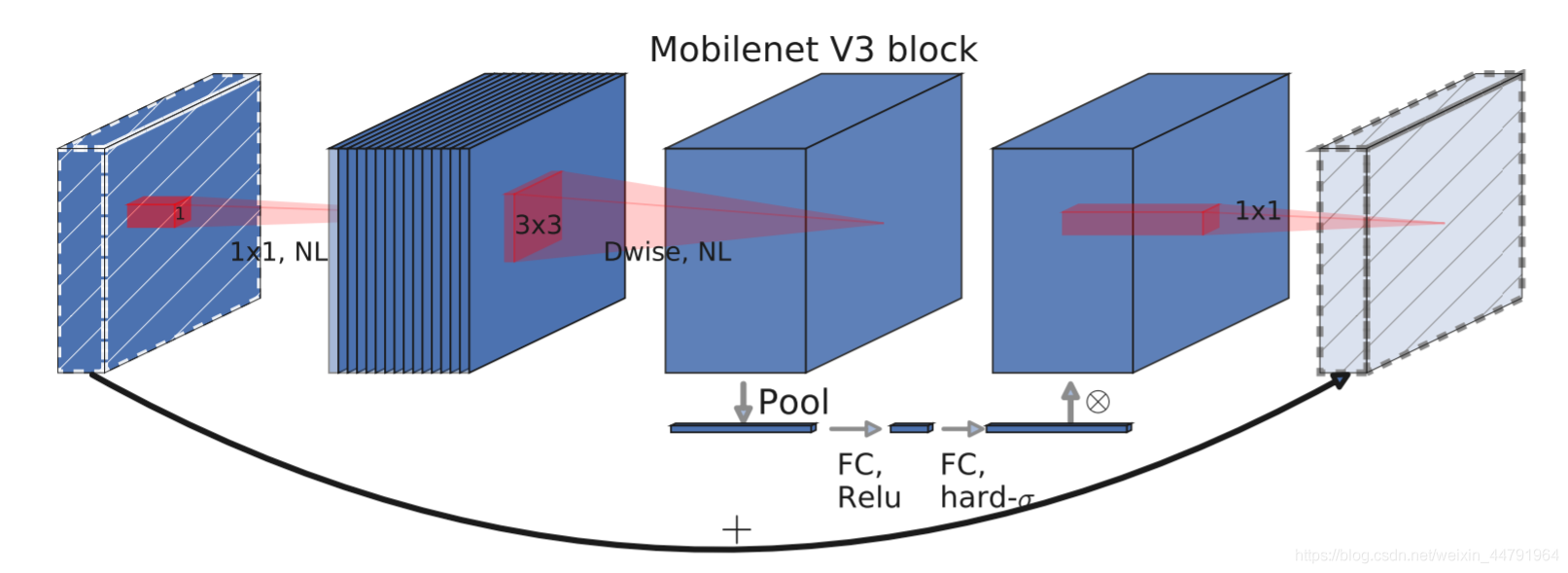
It combines the following four features :
a、MobileNetV2 Inverse residual structure with linear bottleneck (the inverted residual with linear bottleneck).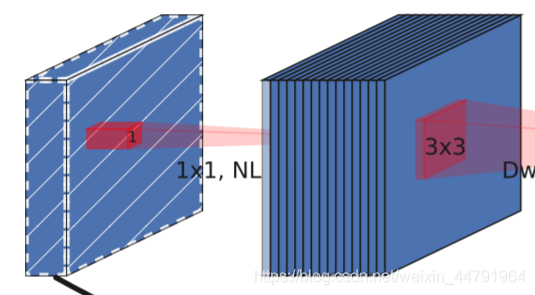
That is, first use 1x1 Convolution carries out ascending dimension , Then perform the following operations , And has residual edges .
b、MobileNetV1 The depth separable convolution (depthwise separable convolutions).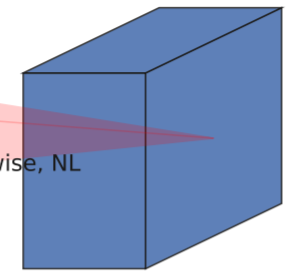
In the input 1x1 After the convolution is carried out to raise the dimension , Conduct 3x3 Depth separates the convolution .
c、 Lightweight attention model .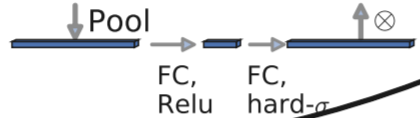
This attention mechanism works by adjusting the weight of each channel .
d、 utilize h-swish Instead of swish function .
Used in the structure h-swishj Activation function , Instead of swish function , Reduce the amount of computation , Improve performance .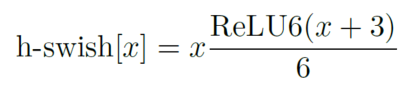
The following figure shows the whole mobilenetV3 Structure diagram :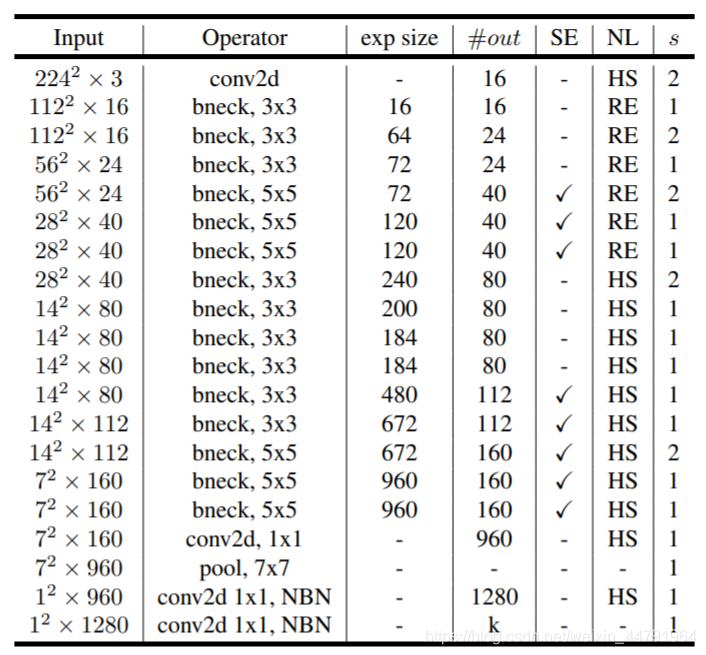
How to understand this watch ? We start from each train :
First column Input representative mobilenetV3 Of each feature layer shape change ;
Second column Operator Represents what each feature layer will experience block structure , We can see in the MobileNetV3 in , Feature extraction has gone through a lot of bneck structure ;
Third 、 The four columns represent bneck The number of channels after the rise of the internal inverse residual structure 、 Input to bneck The number of channels in the feature layer .
The fifth column SE It represents whether to introduce attention mechanism in this layer .
The sixth column NL Represents the type of activation function ,HS representative h-swish,RE representative RELU.
The seventh column s Represents every time block The step size used by the structure .
about yolov4 Speaking of , We need to take out its last three shape Effective feature layer to enhance feature extraction .
In the code , We took out out1、out2、out3.
import torch.nn as nn
import math
import torch
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, _make_divisible(channel // reduction, 8)),
nn.ReLU(inplace=True),
nn.Linear(_make_divisible(channel // reduction, 8), channel),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
def conv_3x3_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
h_swish()
)
def conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
h_swish()
)
class InvertedResidual(nn.Module):
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs):
super(InvertedResidual, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
if inp == hidden_dim:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Identity(),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Identity(),
h_swish() if use_hs else nn.ReLU(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.identity:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV3(nn.Module):
def __init__(self, num_classes=1000, width_mult=1.):
super(MobileNetV3, self).__init__()
# setting of inverted residual blocks
self.cfgs = [
#` k, t, c, SE, HS, s
[3, 1, 16, 0, 0, 1],
[3, 4, 24, 0, 0, 2],
[3, 3, 24, 0, 0, 1],
[5, 3, 40, 1, 0, 2],
[5, 3, 40, 1, 0, 1],
[5, 3, 40, 1, 0, 1],
[3, 6, 80, 0, 1, 2],
[3, 2.5, 80, 0, 1, 1],
[3, 2.3, 80, 0, 1, 1],
[3, 2.3, 80, 0, 1, 1],
[3, 6, 112, 1, 1, 1],
[3, 6, 112, 1, 1, 1],
[5, 6, 160, 1, 1, 2],
[5, 6, 160, 1, 1, 1],
[5, 6, 160, 1, 1, 1]
]
input_channel = _make_divisible(16 * width_mult, 8)
layers = [conv_3x3_bn(3, input_channel, 2)]
block = InvertedResidual
for k, t, c, use_se, use_hs, s in self.cfgs:
output_channel = _make_divisible(c * width_mult, 8)
exp_size = _make_divisible(input_channel * t, 8)
layers.append(block(input_channel, exp_size, output_channel, k, s, use_se, use_hs))
input_channel = output_channel
self.features = nn.Sequential(*layers)
self.conv = conv_1x1_bn(input_channel, exp_size)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
output_channel = _make_divisible(1280 * width_mult, 8) if width_mult > 1.0 else 1280
self.classifier = nn.Sequential(
nn.Linear(exp_size, output_channel),
h_swish(),
nn.Dropout(0.2),
nn.Linear(output_channel, num_classes),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.conv(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def mobilenet_v3(pretrained=False, **kwargs):
model = MobileNetV3(**kwargs)
if pretrained:
state_dict = torch.load('./model_data/mobilenetv3-large-1cd25616.pth')
model.load_state_dict(state_dict, strict=True)
return model
3、 Integrate forecast results into yolov4 In the Internet
about yolov4 Speaking of , We need to use the backbone feature to extract the information obtained by the network Three effective features are used to strengthen the construction of feature pyramid .
Use the... Defined in the previous step MobilenetV1、MobilenetV2、MobilenetV3 Three functions, we can get each Mobilenet Three effective feature layers corresponding to the network .
We can use these three effective feature layers to replace the original yolov4 Backbone network CSPdarknet53 Effective feature layer .
In order to further reduce the number of parameters , We can use deep separable convolution instead of yoloV3 The common convolution used in .
The implementation code is as follows :
import torch
import torch.nn as nn
from collections import OrderedDict
from nets.mobilenet_v1 import mobilenet_v1
from nets.mobilenet_v2 import mobilenet_v2
from nets.mobilenet_v3 import mobilenet_v3
class MobileNetV1(nn.Module):
def __init__(self, pretrained = False):
super(MobileNetV1, self).__init__()
self.model = mobilenet_v1(pretrained=pretrained)
def forward(self, x):
out3 = self.model.stage1(x)
out4 = self.model.stage2(out3)
out5 = self.model.stage3(out4)
return out3, out4, out5
class MobileNetV2(nn.Module):
def __init__(self, pretrained = False):
super(MobileNetV2, self).__init__()
self.model = mobilenet_v2(pretrained=pretrained)
def forward(self, x):
out3 = self.model.features[:7](x)
out4 = self.model.features[7:14](out3)
out5 = self.model.features[14:18](out4)
return out3, out4, out5
class MobileNetV3(nn.Module):
def __init__(self, pretrained = False):
super(MobileNetV3, self).__init__()
self.model = mobilenet_v3(pretrained=pretrained)
def forward(self, x):
out3 = self.model.features[:7](x)
out4 = self.model.features[7:13](out3)
out5 = self.model.features[13:16](out4)
return out3, out4, out5
def conv2d(filter_in, filter_out, kernel_size, groups=1, stride=1):
pad = (kernel_size - 1) // 2 if kernel_size else 0
return nn.Sequential(OrderedDict([
("conv", nn.Conv2d(filter_in, filter_out, kernel_size=kernel_size, stride=stride, padding=pad, groups=groups, bias=False)),
("bn", nn.BatchNorm2d(filter_out)),
("relu", nn.ReLU6(inplace=True)),
]))
def conv_dw(filter_in, filter_out, stride = 1):
return nn.Sequential(
nn.Conv2d(filter_in, filter_in, 3, stride, 1, groups=filter_in, bias=False),
nn.BatchNorm2d(filter_in),
nn.ReLU6(inplace=True),
nn.Conv2d(filter_in, filter_out, 1, 1, 0, bias=False),
nn.BatchNorm2d(filter_out),
nn.ReLU6(inplace=True),
)
#---------------------------------------------------#
# SPP structure , Pool using pool cores of different sizes
# Stack after pooling
#---------------------------------------------------#
class SpatialPyramidPooling(nn.Module):
def __init__(self, pool_sizes=[5, 9, 13]):
super(SpatialPyramidPooling, self).__init__()
self.maxpools = nn.ModuleList([nn.MaxPool2d(pool_size, 1, pool_size//2) for pool_size in pool_sizes])
def forward(self, x):
features = [maxpool(x) for maxpool in self.maxpools[::-1]]
features = torch.cat(features + [x], dim=1)
return features
#---------------------------------------------------#
# Convolution + On the sampling
#---------------------------------------------------#
class Upsample(nn.Module):
def __init__(self, in_channels, out_channels):
super(Upsample, self).__init__()
self.upsample = nn.Sequential(
conv2d(in_channels, out_channels, 1),
nn.Upsample(scale_factor=2, mode='nearest')
)
def forward(self, x,):
x = self.upsample(x)
return x
#---------------------------------------------------#
# Cubic convolution block
#---------------------------------------------------#
def make_three_conv(filters_list, in_filters):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 1),
conv_dw(filters_list[0], filters_list[1]),
conv2d(filters_list[1], filters_list[0], 1),
)
return m
#---------------------------------------------------#
# Quintic convolution block
#---------------------------------------------------#
def make_five_conv(filters_list, in_filters):
m = nn.Sequential(
conv2d(in_filters, filters_list[0], 1),
conv_dw(filters_list[0], filters_list[1]),
conv2d(filters_list[1], filters_list[0], 1),
conv_dw(filters_list[0], filters_list[1]),
conv2d(filters_list[1], filters_list[0], 1),
)
return m
#---------------------------------------------------#
# At last get yolov4 Output
#---------------------------------------------------#
def yolo_head(filters_list, in_filters):
m = nn.Sequential(
conv_dw(in_filters, filters_list[0]),
nn.Conv2d(filters_list[0], filters_list[1], 1),
)
return m
#---------------------------------------------------#
# yolo_body
#---------------------------------------------------#
class YoloBody(nn.Module):
def __init__(self, num_anchors, num_classes, backbone="mobilenetv2", pretrained=False):
super(YoloBody, self).__init__()
# backbone
if backbone == "mobilenetv1":
self.backbone = MobileNetV1(pretrained=pretrained)
alpha = 1
in_filters = [256,512,1024]
elif backbone == "mobilenetv2":
self.backbone = MobileNetV2(pretrained=pretrained)
alpha = 1
in_filters = [32,96,320]
elif backbone == "mobilenetv3":
self.backbone = MobileNetV3(pretrained=pretrained)
alpha = 1
in_filters = [40,112,160]
else:
raise ValueError('Unsupported backbone - `{}`, Use mobilenetv1, mobilenetv2, mobilenetv3.'.format(backbone))
self.conv1 = make_three_conv([int(512*alpha), int(1024*alpha)], in_filters[2])
self.SPP = SpatialPyramidPooling()
self.conv2 = make_three_conv([int(512*alpha), int(1024*alpha)], int(2048*alpha))
self.upsample1 = Upsample(int(512*alpha), int(256*alpha))
self.conv_for_P4 = conv2d(in_filters[1], int(256*alpha),1)
self.make_five_conv1 = make_five_conv([int(256*alpha), int(512*alpha)], int(512*alpha))
self.upsample2 = Upsample(int(256*alpha), int(128*alpha))
self.conv_for_P3 = conv2d(in_filters[0], int(128*alpha),1)
self.make_five_conv2 = make_five_conv([ int(128*alpha), int(256*alpha)], int(256*alpha))
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
# 4+1+num_classes
final_out_filter2 = num_anchors * (5 + num_classes)
self.yolo_head3 = yolo_head([int(256*alpha), final_out_filter2],int(128*alpha))
self.down_sample1 = conv_dw(int(128*alpha), int(256*alpha),stride=2)
self.make_five_conv3 = make_five_conv([int(256*alpha), int(512*alpha)],int(512*alpha))
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
final_out_filter1 = num_anchors * (5 + num_classes)
self.yolo_head2 = yolo_head([int(512*alpha), final_out_filter1], int(256*alpha))
self.down_sample2 = conv_dw(int(256*alpha), int(512*alpha),stride=2)
self.make_five_conv4 = make_five_conv([int(512*alpha), int(1024*alpha)], int(1024*alpha))
# 3*(5+num_classes)=3*(5+20)=3*(4+1+20)=75
final_out_filter0 = num_anchors * (5 + num_classes)
self.yolo_head1 = yolo_head([int(1024*alpha), final_out_filter0], int(512*alpha))
def forward(self, x):
# backbone
x2, x1, x0 = self.backbone(x)
P5 = self.conv1(x0)
P5 = self.SPP(P5)
P5 = self.conv2(P5)
P5_upsample = self.upsample1(P5)
P4 = self.conv_for_P4(x1)
P4 = torch.cat([P4,P5_upsample],axis=1)
P4 = self.make_five_conv1(P4)
P4_upsample = self.upsample2(P4)
P3 = self.conv_for_P3(x2)
P3 = torch.cat([P3,P4_upsample],axis=1)
P3 = self.make_five_conv2(P3)
P3_downsample = self.down_sample1(P3)
P4 = torch.cat([P3_downsample,P4],axis=1)
P4 = self.make_five_conv3(P4)
P4_downsample = self.down_sample2(P4)
P5 = torch.cat([P4_downsample,P5],axis=1)
P5 = self.make_five_conv4(P5)
out2 = self.yolo_head3(P3)
out1 = self.yolo_head2(P4)
out0 = self.yolo_head1(P5)
return out0, out1, out2
Train yourself YoloV4 Model
First, go to Github Download the corresponding warehouse , After downloading, use the decompression software to decompress , Then open the folder with programming software .
Note that the open root directory must be correct , Otherwise, if the relative directory is incorrect , The code will not run .
Be sure to note that the root directory after opening is the directory where the files are stored .
One 、 Data set preparation
This article USES the VOC Format for training , Before training, you need to make your own data set , If you don't have your own data set , Can pass Github Connect to download VOC12+07 Try the following data set .
Put the label file in before training VOCdevkit Under folder VOC2007 Under folder Annotation in .
Put the picture file in before training VOCdevkit Under folder VOC2007 Under folder JPEGImages in .
At this point, the placement of the data set has ended .
Two 、 Data set processing
After the data set is placed , We need to do the next step on the dataset , The purpose is to obtain... For training 2007_train.txt as well as 2007_val.txt, You need to use... Under the root directory voc_annotation.py.
voc_annotation.py There are some parameters that need to be set .
Namely annotation_mode、classes_path、trainval_percent、train_percent、VOCdevkit_path, The first training can only modify classes_path
''' annotation_mode Used to specify the contents of the file to be calculated at run time annotation_mode by 0 Represents the entire label processing process , Including getting VOCdevkit/VOC2007/ImageSets Inside txt And for training 2007_train.txt、2007_val.txt annotation_mode by 1 On behalf of VOCdevkit/VOC2007/ImageSets Inside txt annotation_mode by 2 Stands for... For training 2007_train.txt、2007_val.txt '''
annotation_mode = 0
''' It has to be changed , Used to generate 2007_train.txt、2007_val.txt Target information for And the... Used for training and prediction classes_path It's OK to be consistent If generated 2007_train.txt There is no target information in it So it's because classes Not set correctly Only in annotation_mode by 0 and 2 In force '''
classes_path = 'model_data/voc_classes.txt'
''' trainval_percent Is used to specify the ( Training set + Verification set ) Ratio to test set , By default ( Training set + Verification set ): Test set = 9:1 train_percent Is used to specify the ( Training set + Verification set ) The ratio of training set to verification set in , By default Training set : Verification set = 9:1 Only in annotation_mode by 0 and 1 In force '''
trainval_percent = 0.9
train_percent = 0.9
''' Point to VOC The folder where the dataset is located By default, it points to... In the root directory VOC Data sets '''
VOCdevkit_path = 'VOCdevkit'
classes_path Used to point to... Corresponding to the detection category txt, With voc Data sets, for example , We use txt by :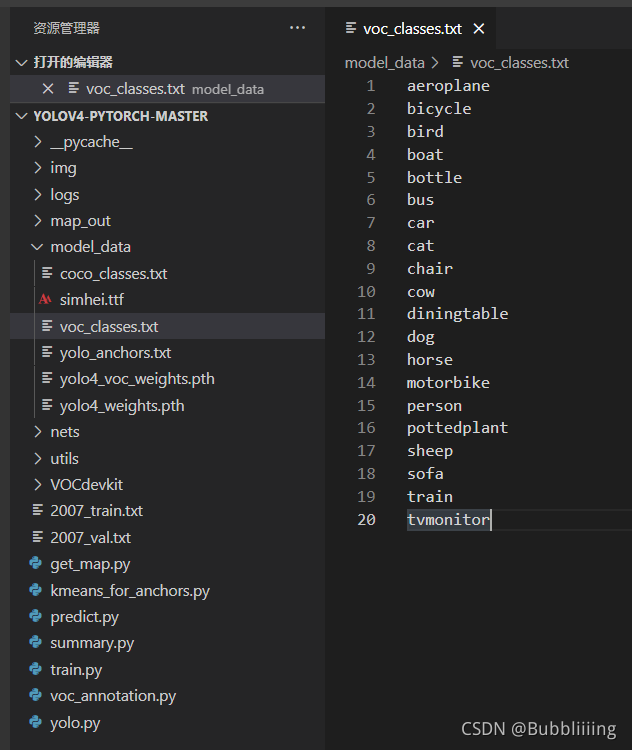
When training your dataset , You can build your own cls_classes.txt, Write the categories you need to distinguish .
3、 ... and 、 Start network training
adopt voc_annotation.py We have generated 2007_train.txt as well as 2007_val.txt, Now we can start training .
There are many training parameters , You can read the notes carefully after downloading the library , The most important part is still train.py Inside classes_path.
classes_path Used to point to... Corresponding to the detection category txt, This txt and voc_annotation.py Inside txt equally ! Training your own data set must be modified !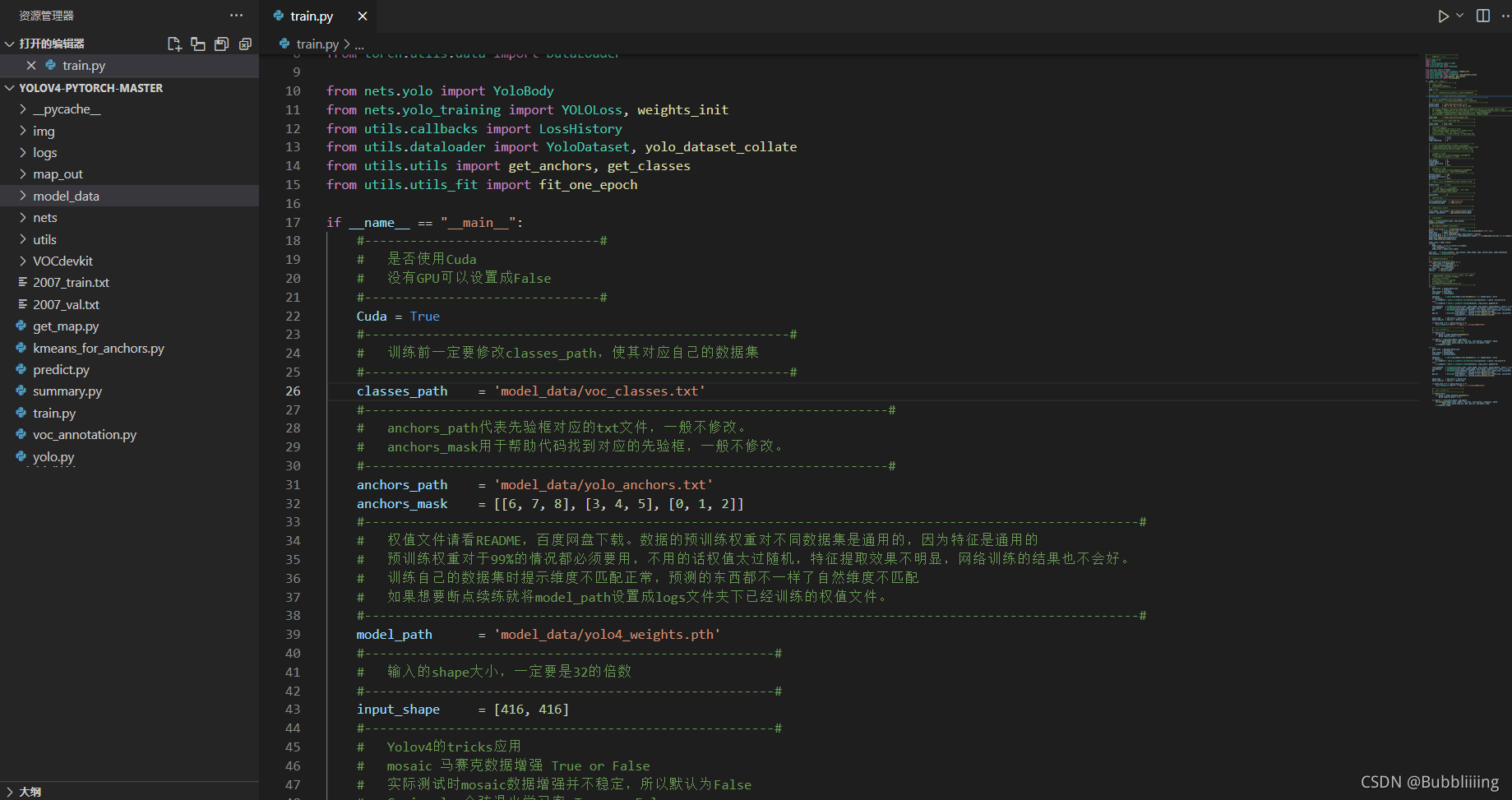
After revising classes_path Then you can run train.py It's training , Training multiple epoch after , Weights will be generated in logs In the folder .
in addition ,backbone Parameter is used to specify the backbone feature extraction network used , Can be in mobilenetv1, mobilenetv2, mobilenetv3 To choose from .
Pay attention to what you use before training mobilenet Alignment of version and pre training weights .
The functions of other parameters are as follows :
#-------------------------------#
# Whether to use Cuda
# No, GPU It can be set to False
#-------------------------------#
Cuda = True
#--------------------------------------------------------#
# Be sure to modify before training classes_path, Make it correspond to its own data set
#--------------------------------------------------------#
classes_path = 'model_data/voc_classes.txt'
#---------------------------------------------------------------------#
# anchors_path Represents the corresponding a priori box txt file , Generally, it is not modified .
# anchors_mask Used to help the code find the corresponding a priori box , Generally, it is not modified .
#---------------------------------------------------------------------#
anchors_path = 'model_data/yolo_anchors.txt'
anchors_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
#------------------------------------------------------------------------------------------------------#
# For the weight file, please see README, Baidu online disk download . The pre training weight of data is universal for different data sets , Because features are universal
# The pre training weight is for 99% In all cases, you must use , If not, the weight is too random , The effect of feature extraction is not obvious , The results of online training will not be good .
# When training your dataset, you will be prompted that the dimensions do not match , The predictions are different, and the natural dimensions don't match
# If you want to continue practicing, you will model_path Set to logs The weight files that have been trained under the folder .
#------------------------------------------------------------------------------------------------------#
model_path = 'model_data/yolov4_mobilenet_v1_voc.pth'
#------------------------------------------------------#
# Input shape size , Must be 32 Multiple
#------------------------------------------------------#
input_shape = [416, 416]
#-------------------------------#
# Backbone feature extraction network used
# mobilenetv1
# mobilenetv2
# mobilenetv3
# ghostnet
#-------------------------------#
backbone = "mobilenetv1"
#----------------------------------#
# Whether to use the pre training weight of the backbone network
# Only the trunk part , And model_path irrelevant
#----------------------------------#
pretrained = False
#------------------------------------------------------#
# Yolov4 Of tricks application
# mosaic Mosaic data enhancement True or False
# In the actual test mosaic Data enhancement is not stable , So the default is False
# Cosine_scheduler Cosine annealing learning rate True or False
# label_smoothing Label smoothing 0.01 The following general Such as 0.01、0.005
#------------------------------------------------------#
mosaic = False
Cosine_lr = False
label_smoothing = 0
Four 、 Prediction of training results
The prediction of training results requires two files , Namely yolo.py and predict.py.
We need to go first yolo.py Modify inside model_path as well as classes_path, These two parameters must be modified .
in addition ,backbone Parameter is used to specify the backbone feature extraction network used , Can be in mobilenetv1, mobilenetv2, mobilenetv3 To choose from .
model_path Point to the trained weight file , stay logs Folder .
classes_path Point to the... Corresponding to the detection category txt.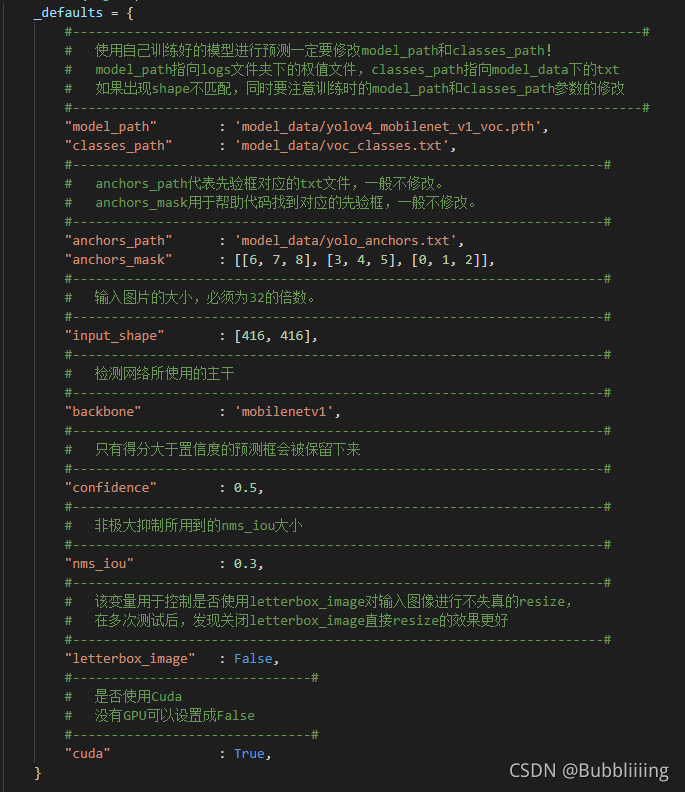
After the modification, you can run predict.py It's been tested . After running, enter the picture path to detect .
边栏推荐
- China vanadium battery Market Research and future prospects report (2022 Edition)
- Deep analysis of C language pointer
- Sublime text using ctrl+b to run another program without closing other runs
- The network model established by torch is displayed by torch viz
- Report on Market Research and investment prospects of China's silver powder industry (2022 Edition)
- Process of obtaining the electronic version of academic qualifications of xuexin.com
- Zhong Xuegao, who cannot be melted, cannot escape the life cycle of online celebrity products
- Image,cv2读取图片的numpy数组的转换和尺寸resize变化
- sublime text没关闭其他运行就使用CTRL+b运行另外的程序问题
- After PCD is converted to ply, it cannot be opened in meshlab, prompting error details: ignored EOF
猜你喜欢

Let the bullets fly for a while
2022.02.13 - 238. Maximum number of "balloons"
2022 Inner Mongolia latest construction tower crane (construction special operation) simulation examination question bank and answers
View computer devices in LAN
Problems in loading and saving pytorch trained models
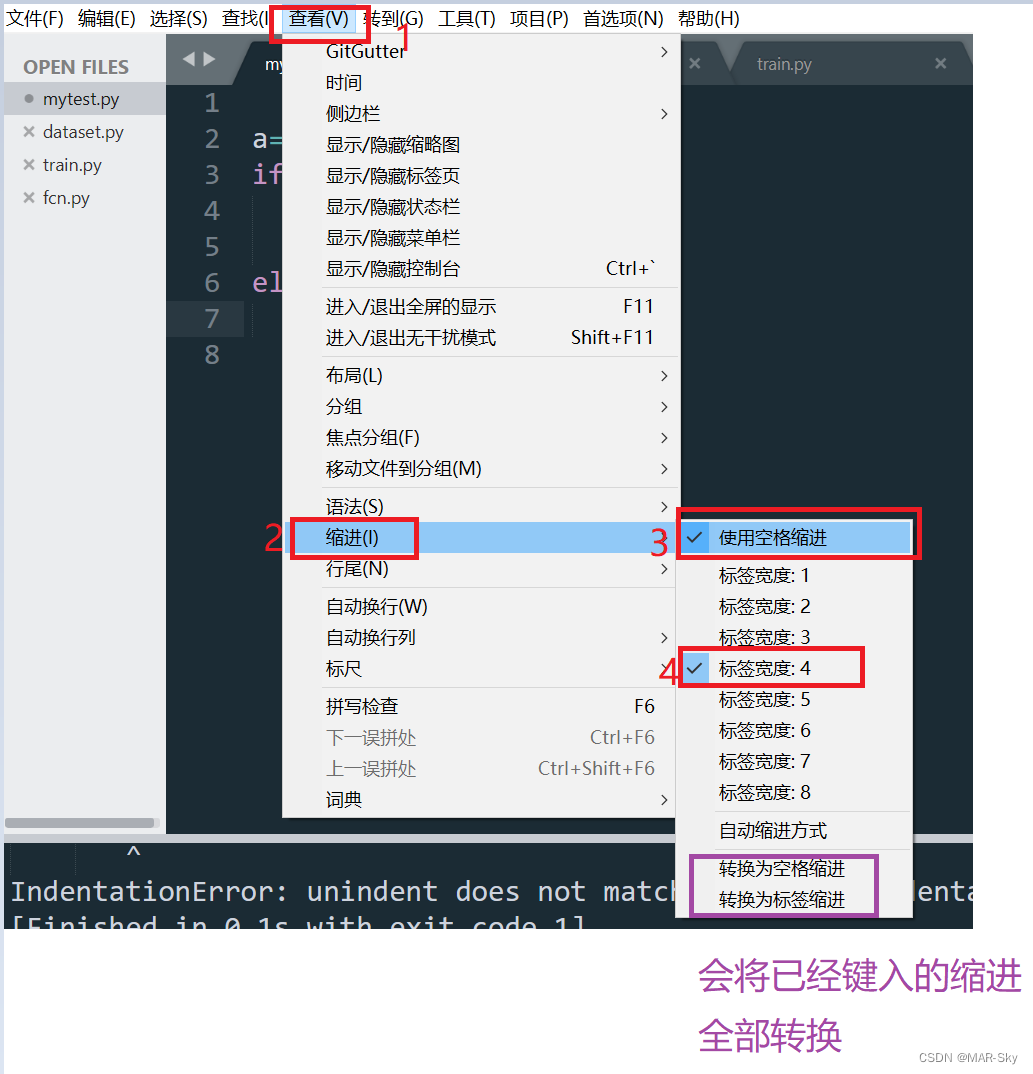
sublime text的编写程序时的Tab和空格缩进问题
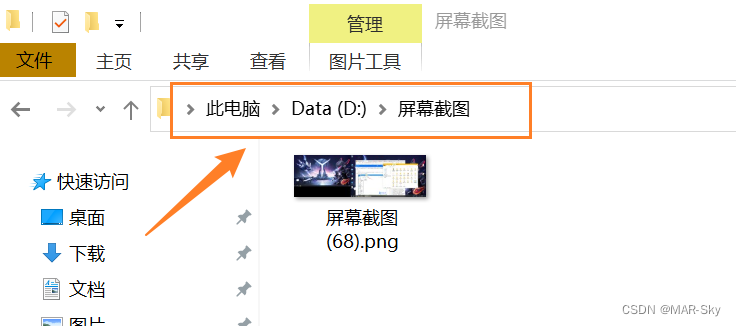
Screenshot in win10 system, win+prtsc save location
![Verrouillage [MySQL]](/img/ce/9f8089da60d9b3a3f92a5e4eebfc13.png)
Verrouillage [MySQL]
查看局域网中电脑设备
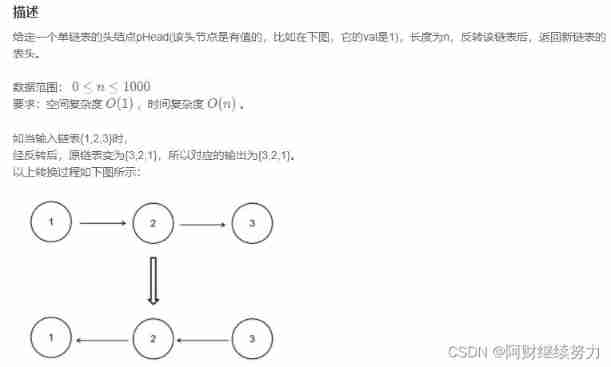
2022.02.13 - NC001. Reverse linked list
随机推荐
软件卸载时遇到trying to use is on a network resource that is unavailable
Introduction to the differences between compiler options of GCC dynamic library FPIC and FPIC
MySQL learning record 07 index (simple understanding)
如何进行接口测试测?有哪些注意事项?保姆级解读
3. File operation 3-with
C语言双指针——经典题型
角色动画(Character Animation)的现状与趋势
China Light conveyor belt in-depth research and investment strategy report (2022 Edition)
JS inheritance method
【Nvidia开发板】常见问题集 (不定时更新)
2022.02.13 - NC001. Reverse linked list
The problem and possible causes of the robot's instantaneous return to the origin of the world coordinate during rviz simulation
China polyether amine Market Forecast and investment strategy report (2022 Edition)
Research Report on Market Research and investment strategy of microcrystalline graphite materials in China (2022 Edition)
电脑F1-F12用途
MySQL learning records 12jdbc operation transactions
Zhong Xuegao, who cannot be melted, cannot escape the life cycle of online celebrity products
Sublime text in CONDA environment plt Show cannot pop up the problem of displaying pictures
sys.argv
Shift Operators