当前位置:网站首页>MapReduce programming basics
MapReduce programming basics
2022-07-01 09:23:00 【Half haochunshui】
( One ) Basic for word frequency statistics
MapReduceProgramming .① stay
/user/hadoop/inputFolder ( The folder is empty ), create a filewordfile1.txtandwordfile2.txtUpload toHDFSMediuminputUnder the folder .
filewordfile1.txtIs as follows :I love SparkI love Hadoop
filewordfile2.txtIs as follows :Hadoop is goodSpark is fast
② start-upEclipse, After startup, the interface shown in the figure below will pop up , Prompt to set up workspace (workspace). You can directly use the default settings “/home/hadoop/workspace”, Click on “OK” Button . It can be seen that , Due to the current use ofhadoopThe user logged inLinuxSystem , therefore , The default workspace directory is located inhadoopUser directory “/home/hadoop” Next .
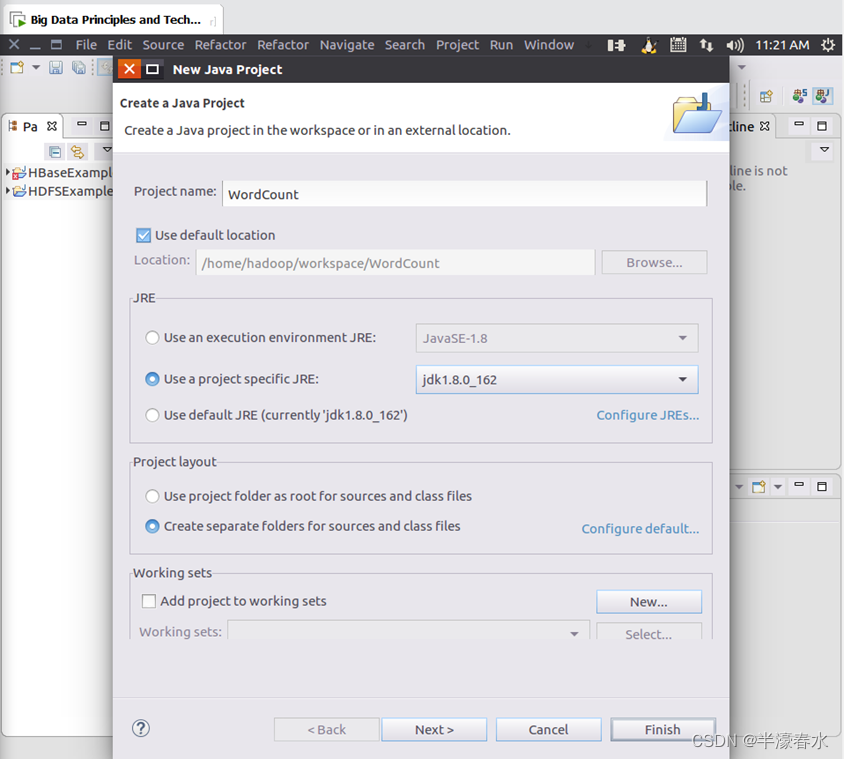
③EclipseAfter the start , choice “File–>New–>Java Project” menu , Start creating aJavaengineering .
④ stay “Project name” Enter the project name later “WordCount”, Choose “Use default location”, Let thisJavaAll files of the project are saved to “/home/hadoop/workspace/WordCount” Under the table of contents . stay “JRE” In this tab , You can select the currentLinuxInstalled in the systemJDK, such as jdk1.8.0_162. then , Click... At the bottom of the interface “Next>” Button , Go to the next setting .
⑤ After entering the next step of setting , You need to load this... In this interfaceJavaRequired for the projectJARpackage , theseJARThe package contains andHadoopdependentJava API. theseJARThe bags are all located inLinuxSystematicHadoopInstallation directory , For this tutorial , Namely “/usr/local/hadoop/share/hadoop” Under the table of contents . Click on the “Libraries” tab , then , Click... On the right side of the interface “Add External JARs…” Button , The interface as shown in the figure below pops up .
⑥ In this interface , There is a row of directory buttons on it ( namely “usr”、“local”、“hadoop”、“share”、“hadoop”、“mapreduce” and “lib”), When you click a directory button , The contents of the directory will be listed below .
In order to write aMapReduceProgram , It is generally necessary toJavaAdd the following... To the projectJARpackage :
a.“/usr/local/hadoop/share/hadoop/common” In the cataloghadoop-common-3.1.3.jarandhaoop-nfs-3.1.3.jar;
b.“/usr/local/hadoop/share/hadoop/common/lib” All under directoryJARpackage ;
c.“/usr/local/hadoop/share/hadoop/mapreduce” All under directoryJARpackage , however , barringjdiff、lib、lib-examplesandsourcesCatalog .
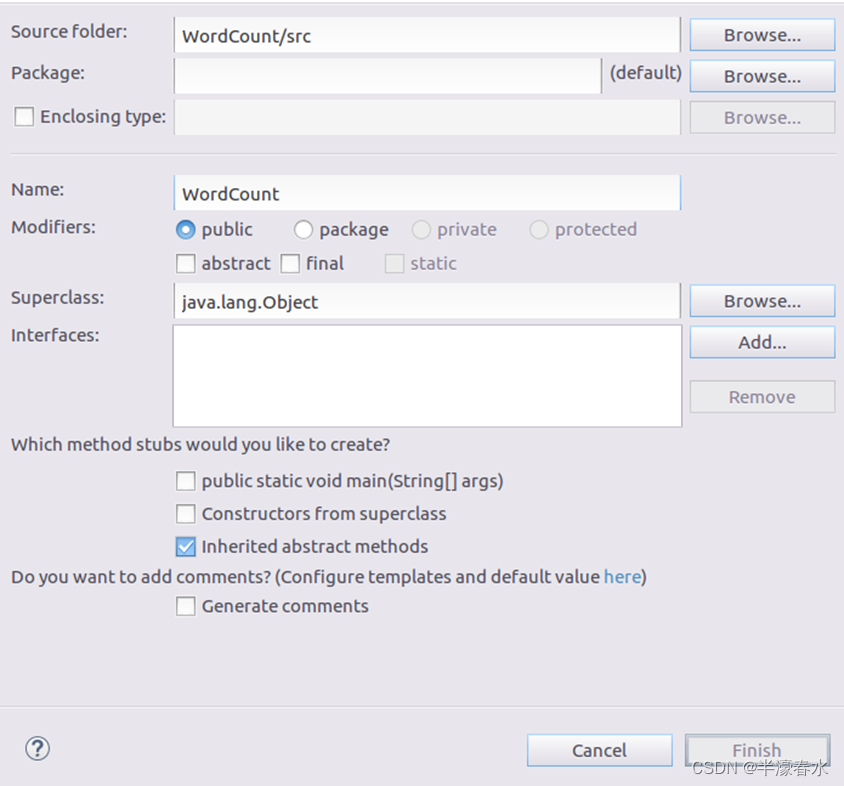
⑦ Write aJavaApplications , namelyWordCount.java. stayEclipseOn the left side of the work interface “Package Explorer” The palette ( As shown in the figure below ), Find the project name just created “WordCount”, Then right click the project name , Select from the pop-up menu “New–>Class” menu .
⑧ choice “New–>Class” After the menu, the interface shown in the figure below will appear , In this interface, you only need to “Name” Then enter the newJavaThe name of the class file , The name is used here “WordCount”, Others can use the default settings , then , Click the bottom right corner of the interface “Finish” Button .
⑨ It can be seen thatEclipseAutomatically created a named “WordCount.java” Source code file for , And contains code “public class WordCount{}”, Clear the code in the file , Then input the complete word frequency statistics program code in the file .( Two ) To configure
eclipseEnvironmental Science , Run the program of word frequency statistics .(1) Compile the packer
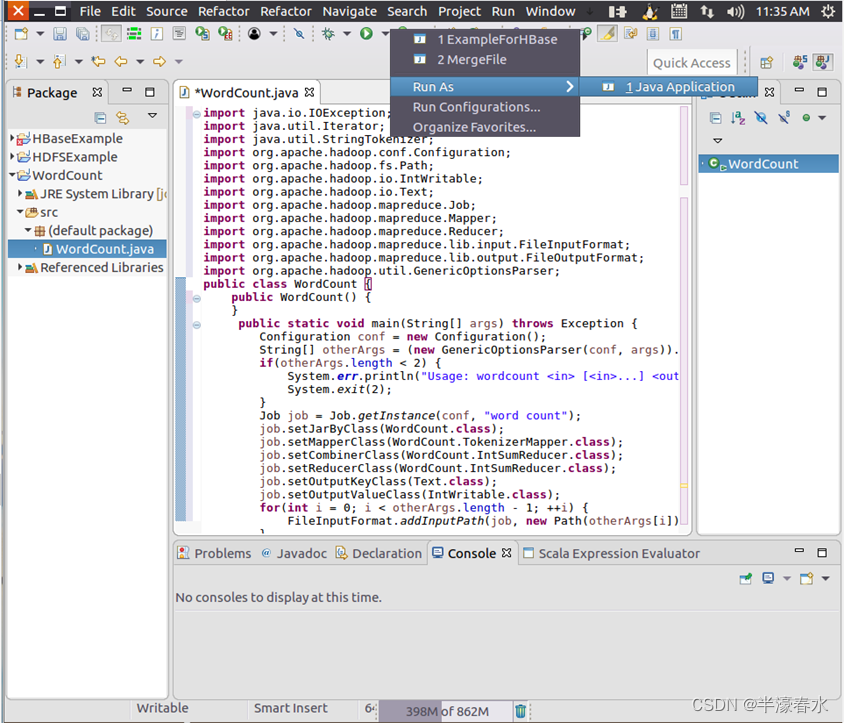
① Compile the code written above , Just clickEclipseThe shortcut button for running the program on the upper part of the work interface , When you move the mouse over the button , Select from the pop-up menu “Run as”, Continue to select... From the pop-up menu “Java Application”, As shown in the figure below .② then , The interface shown in the figure below will pop up , Click... In the lower right corner of the interface “
OK” Button , Start running program .
③ After program running , It'll be at the bottom “Console” The operation result information is displayed in the panel ( As shown in the figure below ).
④ Now we can putJavaApplication package generationJARpackage , Deploy toHadoopRun on the platform . Now you can put the word frequency statistics program in “/usr/local/hadoop/myapp” Under the table of contents . If the directory does not exist , You can use the following command to create .cd /usr/local/hadoopmkdir myapp
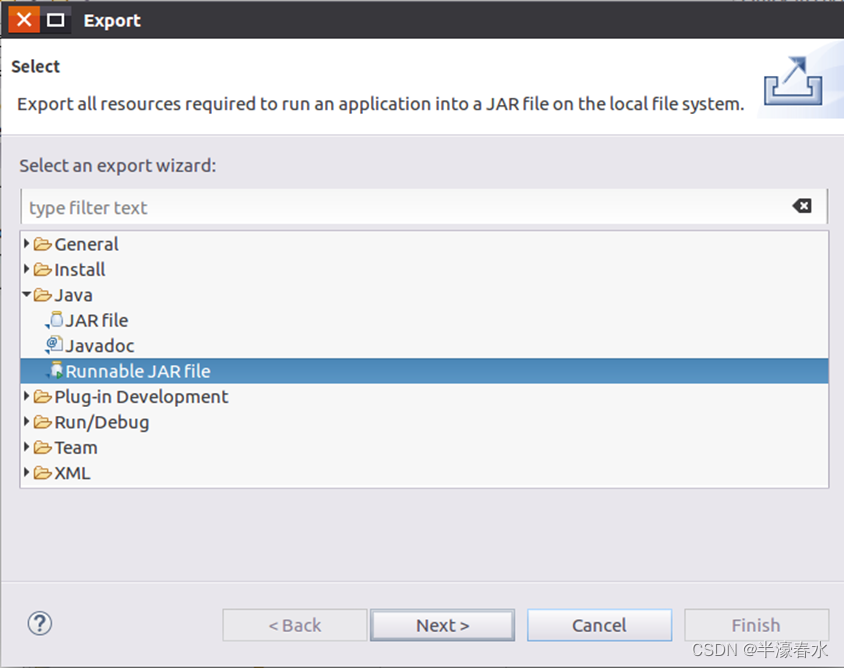
⑤ stayEclipseOn the left side of the work interface “Package Explorer” The palette , In the project name “WordCount” Right click , Select from the pop-up menu “Export”, As shown in the figure below .
⑥ Then the interface as shown in the figure below will pop up , Select... In this interface “Runnable JAR file”.
⑦ then , Click on “Next>” Button , The interface as shown in the figure below pops up . In this interface ,“Launch configuration” Used to set the generatedJARThe package is deployed to the main class running at startup , You need to select the class just configured from the drop-down list “WordCount-WordCount”. stay “Export destination” Need to be set inJARWhich directory do you want to save the package output to , For example, this is set to “/usr/local/hadoop/myapp/WordCount.jar”. stay “Library handling” Next choice “Extract required libraries into generated JAR”.
⑧ And then click “Finish” Button , The interface shown in the figure below will appear .
⑨ You can ignore the information in this interface , Directly click... In the lower right corner of the interface “OK” Button , Start the packaging process . After the packaging process , A warning message screen will appear , As shown in the figure below .
⑩ You can ignore the information in this interface , Directly click... In the lower right corner of the interface “OK” Button . thus , Have successfully putWordCountThe project package generatesWordCount.jar. You can go toLinuxCheck the generated... In the systemWordCount.jarfile , Can be inLinuxExecute the following command in the terminal , You can see ,“/usr/local/hadoop/myapp” A... Already exists in the directoryWordCount.jarfile .
(2) Run the program
① Before running the program , Need to start theHadoop.
② Start upHadoopafter , You need to delete... FirstHDFSChina and the presentLinuxuserhadoopCorrespondinginputandoutputCatalog ( namelyHDFSMedium “/user/hadoop/input” and “/user/hadoop/output” Catalog ), This ensures that there will be no problems in the later program .
③ then , And thenHDFSNew and currentLinuxuserhadoopCorrespondinginputCatalog , namely “/user/hadoop/input” Catalog .
④ Then put the previous inLinuxTwo new files in the local file systemwordfile1.txtandwordfile2.txt( Two files are located in “/usr/local/hadoop” Under the table of contents , And it contains some English sentences ), Upload toHDFSMedium “/user/hadoop/input” Under the table of contents .
⑤ IfHDFSDirectory already exists in “/user/hadoop/output”, Then use the following command to delete the directory .
⑥ Now it can be inLinuxThe system useshadoop jarCommand run program . After the order is executed , When the operation ends smoothly , A message similar to the following will be displayed on the screen .
⑦ At this time, the word frequency statistics results have been writtenHDFSOf “/user/hadoop/output” Directory , Executing the following commands will display the following word frequency statistics results on the screen .
thus , The word frequency statistics program runs smoothly and ends . It should be noted that , If you want to run againWordCount.jar, You need to delete... FirstHDFSMediumoutputCatalog , Otherwise, an error will be reported .( 3、 ... and ) To write MapReduce Program , The program to calculate the average score .




















import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Score {
public static class Map extends
Mapper<LongWritable, Text, Text, IntWritable> {
// Realization map function
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// Convert the data of the input plain text file into String
String line = value.toString();
// The input data is first divided into rows
StringTokenizer tokenizerArticle = new StringTokenizer(line, "\n");
// Process each row separately
while (tokenizerArticle.hasMoreElements()) {
// Divide each line by
StringTokenizer tokenizerLine = new StringTokenizer(tokenizerArticle.nextToken());
String strName = tokenizerLine.nextToken();// Student name section
String strScore = tokenizerLine.nextToken();// Results section
Text name = new Text(strName);
int scoreInt = Integer.parseInt(strScore);
// Output name and grade
context.write(name, new IntWritable(scoreInt));
}
}
}
public static class Reduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
// Realization reduce function
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
sum += iterator.next().get();// Calculate the total score
count++;// Count the total number of subjects
}
int average = (int) sum / count;// Calculate average
context.write(key, new IntWritable(average));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// "localhost:9000" It needs to be set according to the actual situation
conf.set("mapred.job.tracker", "localhost:9000");
// One hdfs In the file system Enter Directory And The output directory
String[] ioArgs = new String[] {
"input/score", "output" };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Score Average <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "Score Average");
job.setJarByClass(Score.class);
// Set up Map、Combine and Reduce Processing class
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
// Set output type
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// Divide the input data set into small data blocks splites, Provide a RecordReder The implementation of the
job.setInputFormatClass(TextInputFormat.class);
// Provide a RecordWriter The implementation of the , Responsible for data output
job.setOutputFormatClass(TextOutputFormat.class);
// Set input and output directories
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
( Four )MapReduce What is the working principle of ?
adopt
Client、JobTrackerandTaskTrackerFrom the perspective ofMapReduceHow it works .
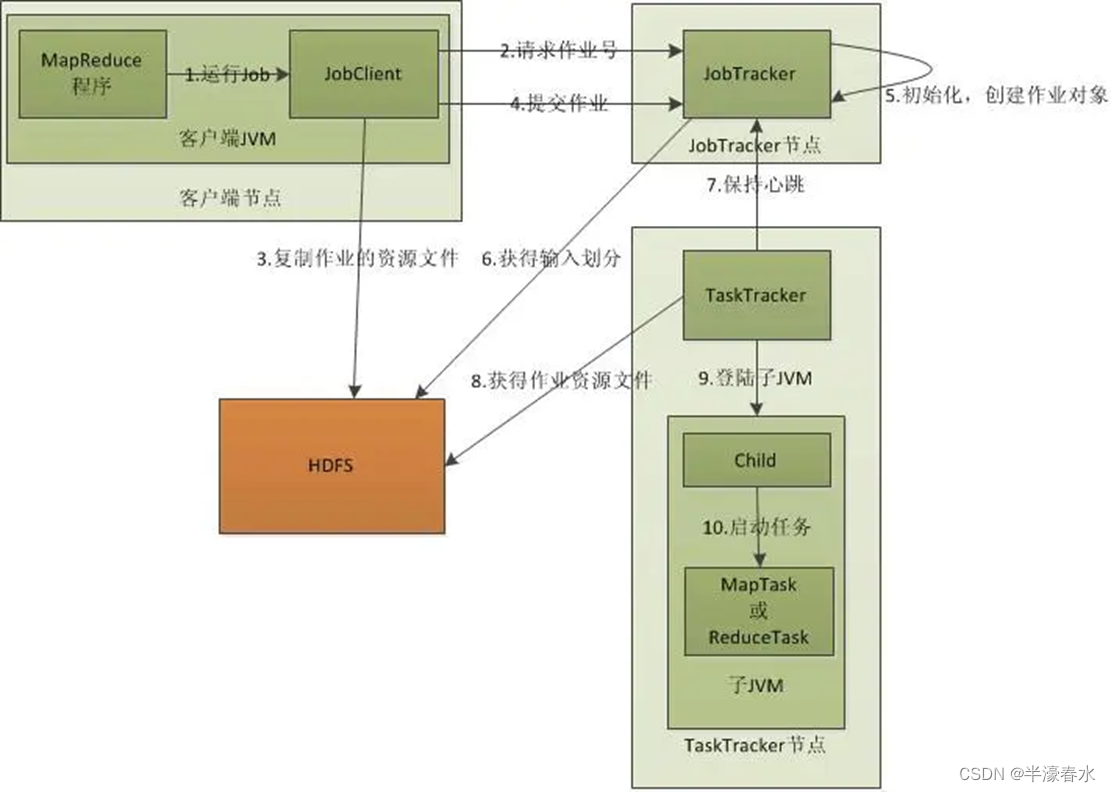
First, the client client Be prepared
mapreduceProgram , Good configurationmapreduceMy homework isjob, The next step is to startjob了 , start-upjobIs to informJobTrackerJob to run on , This is the timeJobTrackerWill return to the client a newjobMissionIDvalue , And then it does the check operation , This check is to determine whether the output directory exists , If there is, thenjobIt won't work properly ,JobTrackerWill throw an error to the client , Next, check whether the input directory exists , If not, throw the same error , If there isJobTrackerWill calculate input slice based on input (Input Split), If the partition can't be calculated, an error will be thrown , It's all doneJobTrackerIt will be configuredJobWe need more resources . GetjobIDafter , Copy the resource files needed to run the job toHDFSOn , IncludeMapReduceIt's packagedJARfile 、 Configuration file and calculated input fragment information . These documents are stored injobTrackerIn a folder created specifically for this job , The folder name is... For this jobJob ID.JARBy default, the file will have 10 Copies (mapred.submit.replicationAttribute control ); Input partition information to tellJobTrackerHow many should be started for this jobmapMission information . When the resource folder is created , The client will submitjobinformjobTrackerI have written the required resources intohdfsOn , Next, please help me to really implementjob.
After allocating resources ,JobTrackerReceive submitjobThe job is initialized after the request , The main thing initialization does is toJobPut in an internal queue , Wait for the job scheduler to schedule it . When the job scheduler schedules the job according to its own scheduling algorithm , The job scheduler will create a runningjobobject ( Encapsulating tasks and recording information ), In order toJobTrackertrackjobThe state and process of . establishjobObject, the job scheduler will gethdfsInput fragment information in folder , According to the fragment information for eachinput splitCreate amapMission , And will map The task is assigned totasktrackerperform . aboutmapandreduceMission ,tasktrackerAccording to the number of host cores and the size of memory, there is a fixed number ofmapSlot andreduceSlot . What needs to be emphasized here is :mapTasks are not randomly assigned to someonetasktrackerOf , Here we will talk about data localization later .
And then there's the assignment , This is the timetasktrackerWill run a simple loop mechanism to send heartbeat tojobtracker, The heartbeat interval is 5 second , The programmer can configure this time , The heartbeat isjobtrackerandtasktrackerA bridge of communication , By heartbeat ,jobtrackerCan monitortasktrackerSurvival , Also availabletasktrackerThe status and problems of the process , meanwhiletasktrackerIt can also be obtained by the return value in the heartbeatjobtrackerThe instructions given to it .tasktrackerWill get the runjobResources needed , Such as code , Prepare for real implementation . After the task is assigned, it's time to perform the task . During the missionjobtrackerIt can be monitored by heartbeat mechanismtasktrackerStatus and progress of , You can also calculate the wholejobStatus and progress of , andtasktrackerYou can also monitor your status and progress locally .TaskTrackerEvery once in a whileJobTrackerSend a heartbeat , tellJobTrackerIt's still running , At the same time, the heartbeat also carries a lot of information , Such as the currentmapInformation about the progress of the task . WhenjobtrackerGot the last one to complete the assigned tasktasktrackerWhen the operation is successful ,jobtrackerWill take the wholejobSet status to success , And then when the client queriesjobWhen it's running ( Be careful : This is an asynchronous operation ), The client will findjobCompleted notification of . IfjobFailure in the middle ,mapreduceThere will also be corresponding mechanisms to deal with , Generally speaking, if it's not for the programmer, the program itself hasbug,mapreduceError handling mechanism can guarantee the submittedjobIt can be done normally .( 5、 ... and )
HadoopHow it worksMapReduceprogrammatic ?① Combine the compiled software with
hadoopConnected to a ( Such asEclipseTo linkhadoop), Run the program directly .
② takemapreduceThe program is packaged intojarfile .
边栏推荐
- pcl_ Viewer command
- 2.3 [pytorch] data preprocessing torchvision datasets. ImageFolder
- Reproduced Xray - cve-2017-7921 (unauthorized access by Hikvision)
- 微信小程序 webview 禁止页面滚动,同时又不影响业务内overflow的滚动的实现方式
- LeetCode 344. Reverse string
- The fixed assets management system enables enterprises to dynamically master assets
- nacos简易实现负载均衡
- Set the type of the input tag to number, and remove the up and down arrows
- Daily office consumables management solution
- Mise en œuvre simple de l'équilibrage de la charge par nacos
猜你喜欢

nacos简易实现负载均衡

【pytorch】nn.CrossEntropyLoss() 与 nn.NLLLoss()

How to manage fixed assets well? Easy to point and move to provide intelligent solutions

JS prototype chain

2.3 【kaggle数据集 - dog breed 举例】数据预处理、重写Dataset、DataLoader读取数据

Vsync+ triple cache mechanism +choreographer

Pain points and solutions of equipment management in large factories

NoSQL数据库的安装和使用
![[interview brush 101] linked list](/img/52/d159bc66c0dbc44c1282a96cf6b2fd.png)
[interview brush 101] linked list

How to solve the problem of fixed assets management and inventory?
随机推荐
Is it safe to dig up money and make new shares
JS use toString to distinguish between object and array
Leetcode daily question brushing record --540 A single element in an ordered array
Structure de l'arbre - - - arbre binaire 2 traversée non récursive
短路运算符惰性求值
Latex插入的eps图片模糊解决方法
类加载
Design and manufacture of simple digital display electronic scale
树结构---二叉树2非递归遍历
Shell script -select in loop
Preparing for the Blue Bridge Cup -- bit operation
Serialization, listening, custom annotation
pcl_ Viewer command
js 使用toString 区分Object、Array
ESP8266 FreeRTOS开发环境搭建
JS原型链
NoSQL数据库的安装和使用
3D printing Arduino four axis aircraft
【pytorch】nn.CrossEntropyLoss() 与 nn.NLLLoss()
韦东山板子编译内核问题解决