当前位置:网站首页>神经网络的设计过程
神经网络的设计过程
2022-08-02 14:08:00 【伏月三十】
神经网络的设计过程
eg鸢尾花的分类
基础知识
神经网络:采集大量数据对构成数据集
花萼长、花萼宽、花瓣长、花瓣宽(输入特征)---->对应的类别(标签,需要人工标定)
把数据集喂入搭建好的神经网络结构,网络通过反向传播优化参数得到模型,模型读入新输入特征,输出识别结果。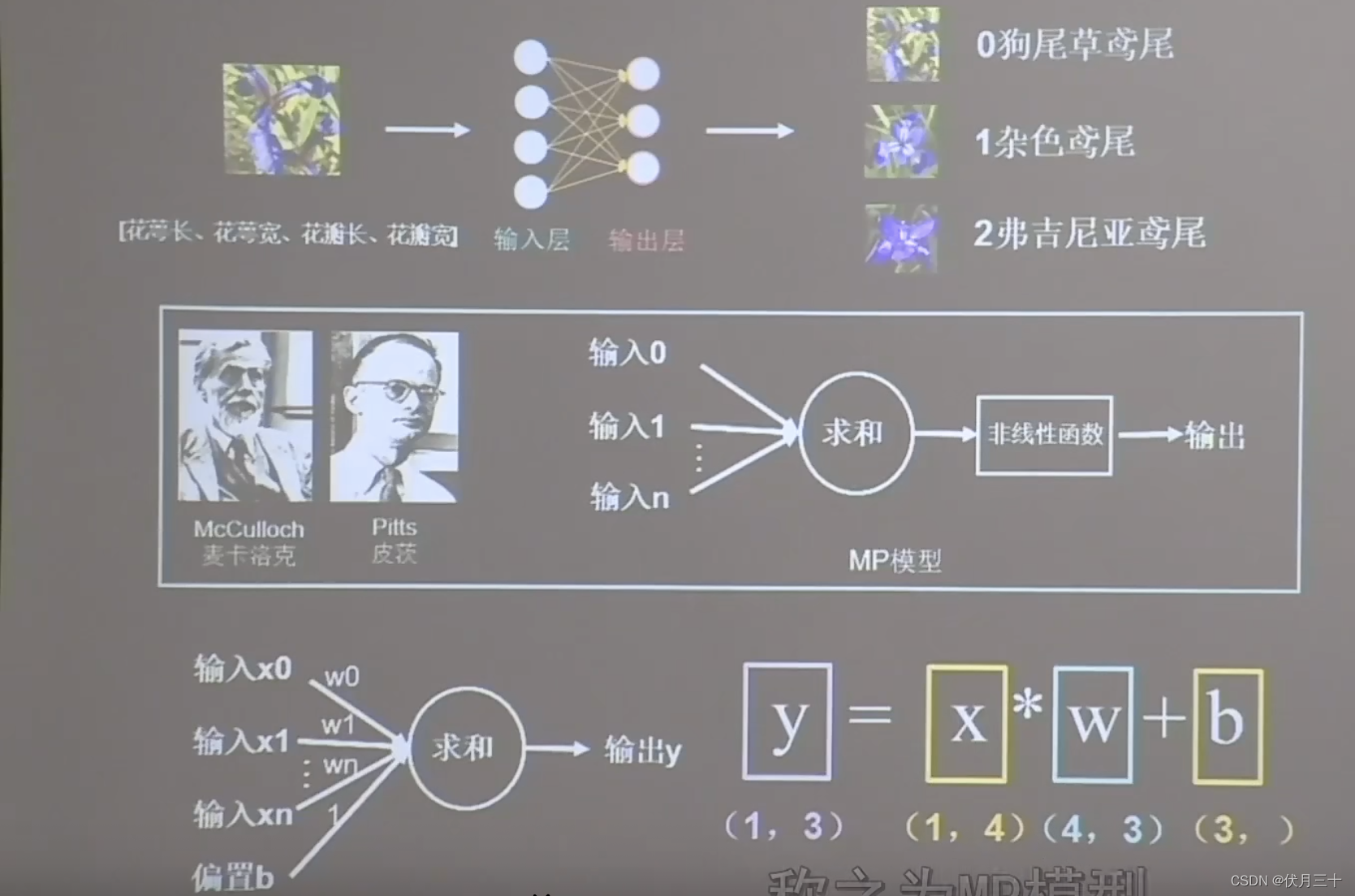
输入数据:一行四列
输出数据:一行三列
权重w:四行三列
偏置b:三个
神经元:输出层的每一个小球
搭建网络
搭建网络:全连接网络(里面的每一个神经元y0、y1、y2和前面一层 的每一个节点x0、x1、x2、x3都有连接)
网络搭建好后,线上的w、b会被随机初始化一些随机数。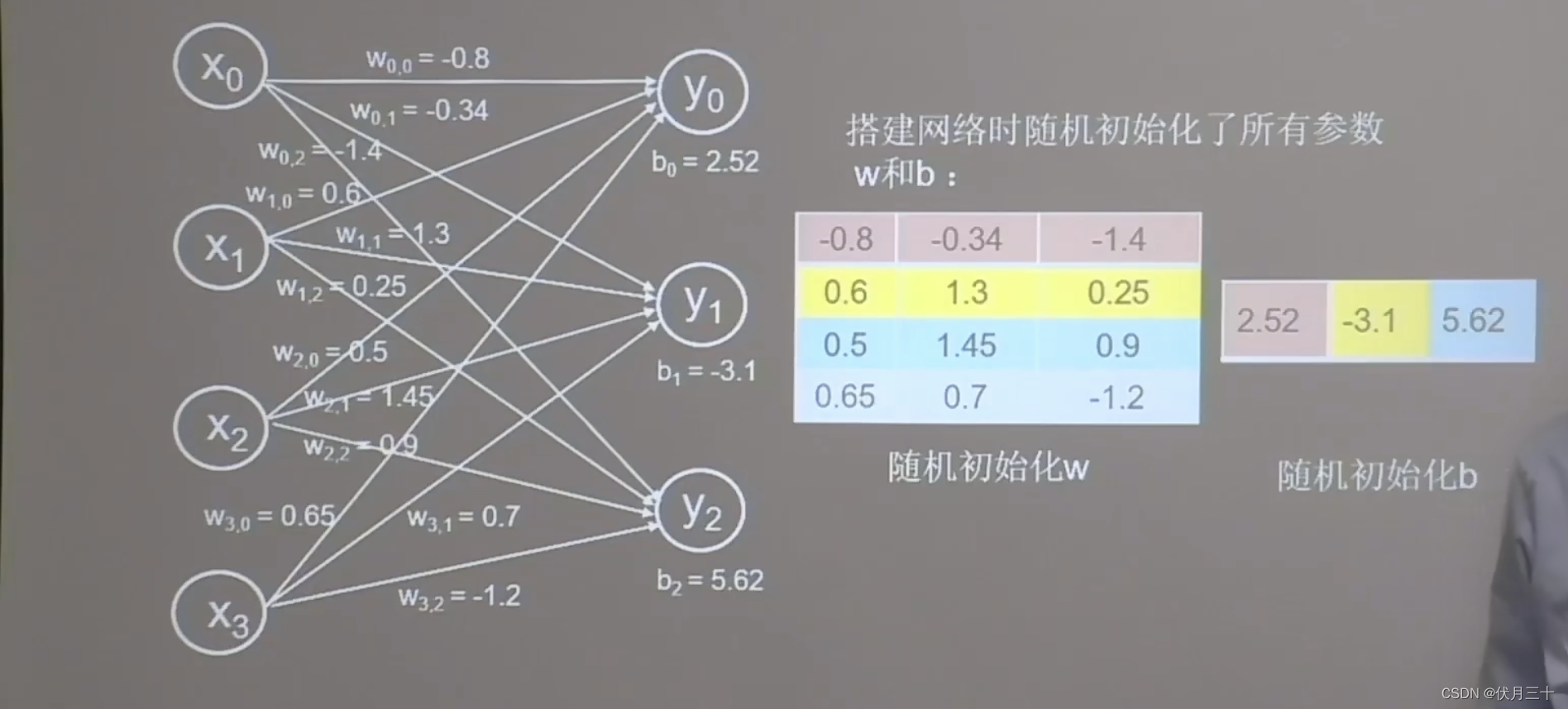
前向传播
喂入一组输入特征5.8、4.0、1.2、0.2,和它们对应的标签:0狗尾草鸢尾;
神经网络执行前向传播x*w+b计算出y。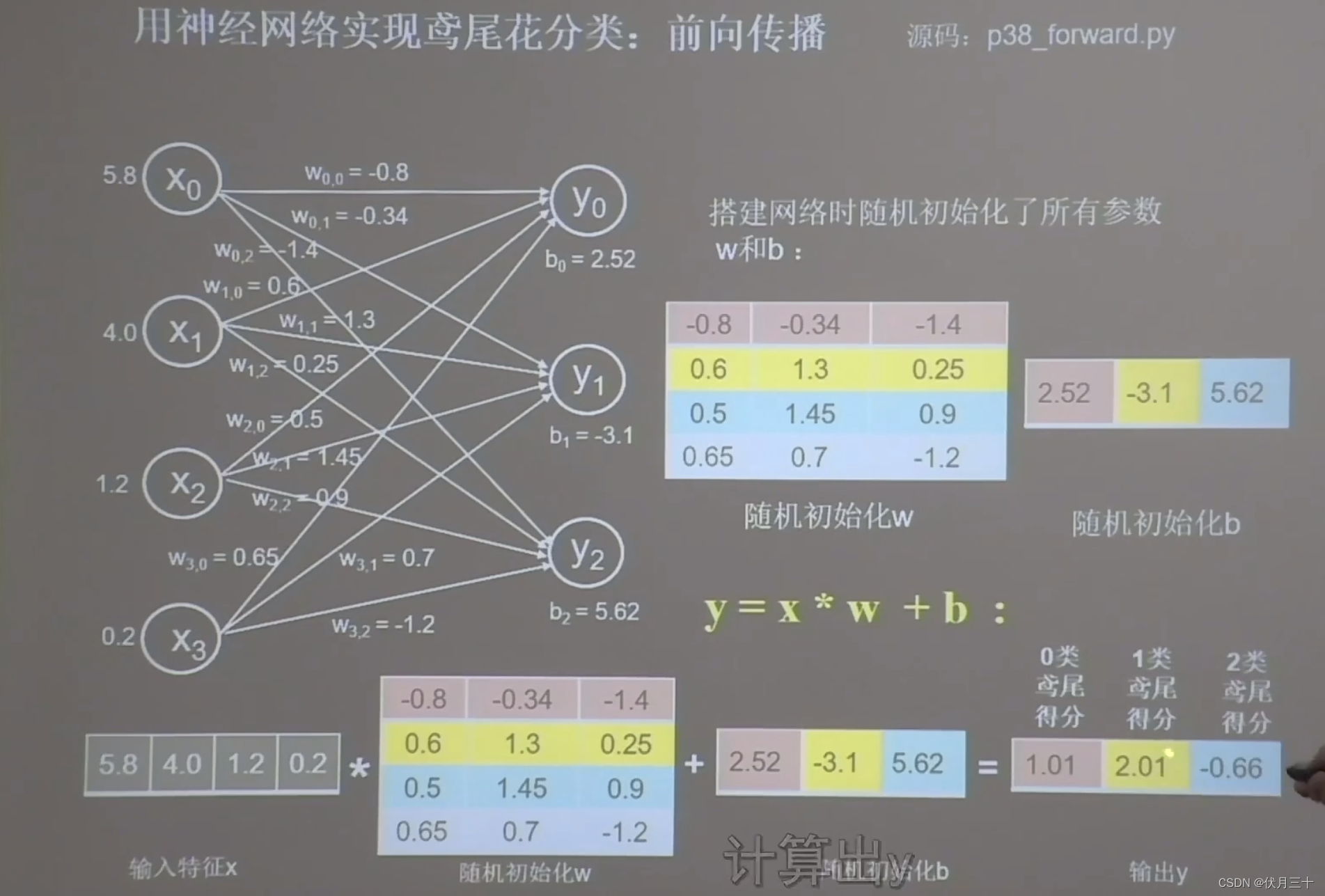
损失函数
输出y,数据最大的就是可能性最高的,是1,而不是标签0。因为w、b是随机生成的。
用到损失函数(预测值和标准值之间的差距,越小越好)
均方误差是一种常用的损失函数。它计算每个前向传播输出y和标准答案y_的差,求平方,再求和,再除以n求平均值,表征了网络前向传播推理(结果)和标准答案之间的差距。
梯度下降
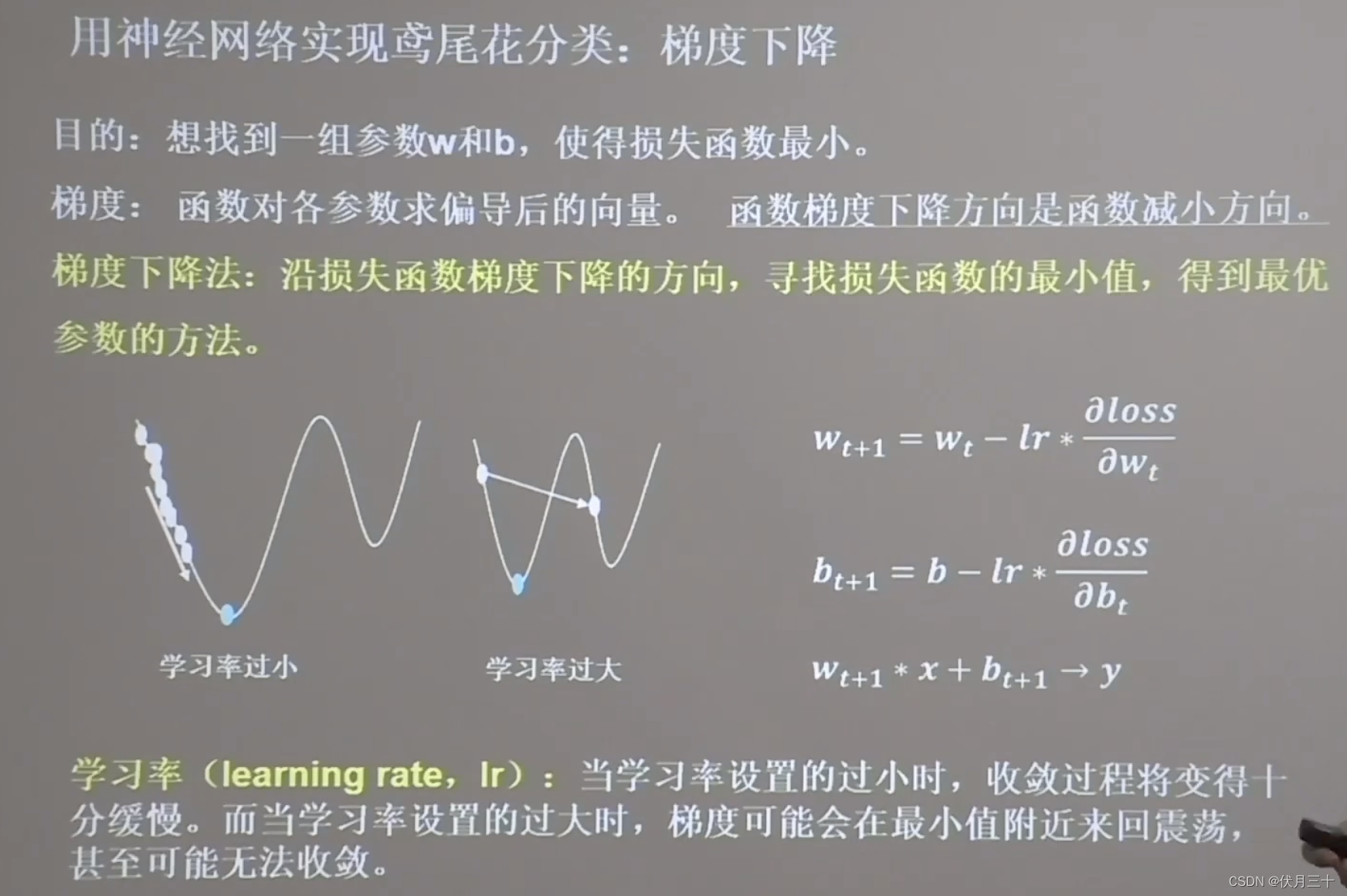
反向传播

代码
import tensorflow as tf
#设置w的随机初始值为5,设定为可训练
w = tf.Variable(tf.constant(5,dtype=tf.float32))
#学习率为0.2
lr = 0.2
#循环迭代40次
epoch = 40
for epoch in range(epoch):#定义顶层循环,表示对数据集循环epoch次
with tf.GradientTape() as tape:#11-13梯度的计算过程
loss = tf.square(w + 1)#损失函数定义为(w+1)^2
grads = tape.gradient(loss,w)#.gradient函数告知对谁求导 loss对w的导数 损失函数对偏置的导数
w.assign_sub(lr * grads)#.assign_sub对变量做自减 w(t+1)=w(t)-lr*偏导数
print("After %s epoch,w is %f,loss is %f" % (epoch,w.numpy(),loss))
#lr初始值:0.2 修改学习率 0.001(太小) 0.999(太大) 看收敛过程
#最终目的:找到loss最小 即w=-1的最优参数w
边栏推荐
猜你喜欢


随机推荐
统计偏科最严重的前100名学生
拥抱Jetpack之印象篇
AAPT: error: duplicate value for resource ‘attr/xxx‘ with config ‘‘, file failed to compile.
电商项目常见连续登录,消费,日期等问题
关于UDF
Kubernetes资源编排系列之三: Kustomize篇
6. How to use the CardView production card layout effect
ConstraintLayout从入门到放弃
Bert系列之 Transformer详解
LLVM系列第二十六章:理解LLVMContext
牛客刷题汇总(持续更新中)
【目标检测】YOLO v5 安全帽检测识别项目模型
Must-know knowledge about disassembly
mysql常用函数
spark资源调度和任务调度
checkPermissions Missing write access to /usr/local/lib
VS2017中安装visual assist X插件
每周招聘|PostgreSQL专家,年薪60+,高能力高薪资
关系代数、SQL与逻辑式语言
LLVM系列第三章:函数Function