当前位置:网站首页>机器学习之数据类型案例——基于朴素贝叶斯法,用数据辩男女
机器学习之数据类型案例——基于朴素贝叶斯法,用数据辩男女
2022-07-02 06:33:00 【七归】
作者简介:整个建筑最重要的是地基,地基不稳,地动山摇。而学技术更要扎稳基础,关注我,带你稳扎每一板块邻域的基础。
博客主页:七归的博客
收录专栏:《统计学习方法》第二版——个人笔记
南来的北往的,走过路过千万别错过,错过本篇,“精彩”可能与您失之交臂 la
Triple attack(三连击):Comment,Like and Collect—>Attention
写在前面
在《统计学习方法》的第四章当中,笔者仅仅是粗略了描述朴素贝叶斯法,因为理论实在是太难懂了,还拖带着概率!不过没关系的,理论嘛,笔者认为看第一遍不懂没事,看第二遍还是不懂,也没事,第三遍还是还是不懂,更没事拉。。。也许你会以为我在逗你完呢?确实,,当然不是的。笔者建议记住公式。届时,你肯定又在问:这么多公式,怎么记得住?该记哪几条?那笔者只能告诉你:佛系。废话少说,看实战吧!
朴素贝叶斯
朴素贝叶斯是一种简单但是极为强大的预测建模算法,朴素在于假设每个特征之间是独立的。
朴素贝叶斯模型由两种类型的概率组成:
- 1、每个类别的概率—— P ( C j ) P(C_{j}) P(Cj)
- 2、每个属性的条件概率—— P ( A i ∣ C j ) P(A_{i}|C_{j}) P(Ai∣Cj)
贝叶斯公式:
- P ( C j ∣ A i ) = P ( A i ∣ C j ) P ( C j ) P ( A i ) P(C_{j}|A_{i})=\frac {P(A_{i}|C_{j})P(C_{j})}{P(A_{i})} P(Cj∣Ai)=P(Ai)P(Ai∣Cj)P(Cj)
朴素贝叶斯分类器:
- y = f ( x ) = a r g m a x P ( C j ) ∏ i P ( A i ∣ C j ) ∑ j P ( C j ) ∏ i P ( A i ∣ C j ) y=f(x)=argmax\frac{P(C_{j})\prod_{i}^{}P(A_{i}|C_{j})}{\sum_{j}^{}P(C_{j})\prod_{i}^{}P(A_{i}|C_{j})} y=f(x)=argmax∑jP(Cj)∏iP(Ai∣Cj)P(Cj)∏iP(Ai∣Cj)
- 其中,全概率公式为:
- P ( A i ) = ∑ j P ( C j ) ∏ i P ( A i ∣ C j ) P(A_{i})={\sum_{j}^{}P(C_{j})\prod_{i}^{}P(A_{i}|C_{j})} P(Ai)=∑jP(Cj)∏iP(Ai∣Cj)
分母对所有 C j C_{j} Cj都相同:
- y = a r g m a x P ( C j ) ∏ i P ( A i ∣ C j ) y=arg maxP(C_{j})\prod_{i}^{}P(A_{i}|C_{j}) y=argmaxP(Cj)∏iP(Ai∣Cj)
朴素贝叶斯分类工作原理
离散型数据案例
- 数据如下:
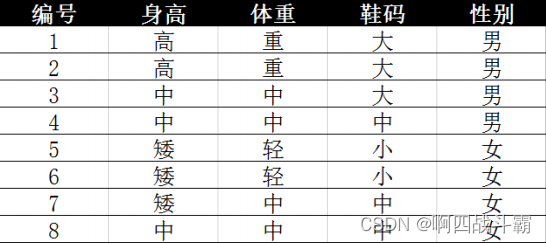
接着,确定特征如下:
- 身高
- 体重
- 鞋码
再者,确定目标如下:
- 性别
- C1:男
- C2:女
- Cj:未知
需求:
- 求解以下特征数据的性别是男性还是女性
- A1:身高=高
- A2:体重=中
- A3:鞋码=中
实现:
- 简单来说,我们仅需求解在该特征下是男性的概率,再求解在该特征下是女性的概率,然后进行比较,选择可能性大的作为结果
P ( C j ∣ A 1 A 2 A 3 ) = P ( A 1 A 2 A 3 ∣ C j ) P ( C j ) P ( A 1 A 2 A 3 ) P(C_{j}|A_{1}A_{2}A_{3})=\frac {P(A_{1}A_{2}A_{3}|C_{j})P(C_{j})}{P(A_{1}A_{2}A_{3})} P(Cj∣A1A2A3)=P(A1A2A3)P(A1A2A3∣Cj)P(Cj)
- 又因为 A i A_{i} Ai之间相互独立,所以则可以转换为如下:
P ( A 1 A 2 A 3 ∣ C j ) = P ( A 1 ∣ C j ) P ( A 2 ∣ C j ) P ( A 3 ∣ C j ) P(A_{1}A_{2}A_{3}|C_{j})=P(A_{1}|C_{j})P(A_{2}|C_{j})P(A_{3}|C_{j}) P(A1A2A3∣Cj)=P(A1∣Cj)P(A2∣Cj)P(A3∣Cj)
- P(Cj|A1A2A3) = (P(A1A2A3|Cj) * P(Cj)) / P(A1A2A3)
- P(A1A2A3|Cj) = P(A1|Cj) * P(A2|Cj) *P(A3|Cj)
- C1类别条件下的属性概率:
- P(A1|C1) = 2/4 = 1/2
- P(A2|C1) = 1/2
- P(A3|C1) = 1/4
- C2类别条件下的属性概率:
- P(A1|C2) = 0
- P(A2|C2) =1/2
- P(A3|C2) = 1/2
- P(A1A2A3|C1) = 1/16
- P(A1A2A3|C2) = 0
因此,算得 P(A1A2A3|C1) > P(A1A2A3|C2),应该是C1类别,为男性。
连续型数据案例
- 数据如下:
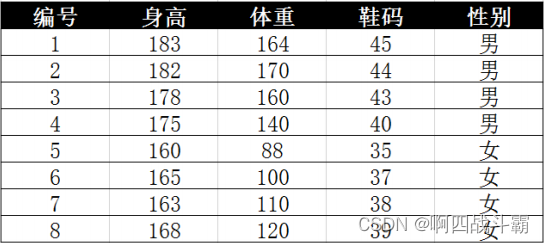
需求:
求解以下特征数据的性别是男性还是女性
- 身高:180
- 体重:120
- 鞋码:41
公式还是上面的公式,这里的困难在于,由于身高、体重、鞋码都是连续变量,不能采用离散变量的方法计算概率。而且由于样本太少,所以也无法分成区间计算。
怎么办呢?这时,可以假设男性和女性的身高、体重、鞋码都是正态分布,通过样本计算出均值和方差
也就是得到正态分布的密度函数。有了密度函数,就可以把值代入,算出某一点的密度函数的值
比如,男性的身高是均值 179.5、标准差为 3.697 的正态分布。所以男性的身高为 180 的概率为 0.1069。怎么计算得出的呢?
from scipy import stats
male_high = stats.norm.pdf(180,male_high_mean,male_high _var)
male_weight = stats.norm.pdf(120, male_weight_mean, male_weight_var)
male_code = stats.norm.pdf(41, male_code_mean, male_code_var)
实现:
- 假设男性和女性的身高、体重、鞋码都是正态分布
- 通过样本计算出均值和方差,也就是得到正态分布的密度函数
- 有了密度函数,就可以把值代入,算出某一点的密度函数的值
import numpy as np
import pandas as pd
# 导入数据
df = pd.read_excel('table_data.xlsx', sheet_name="Sheet3", index_col=0)
df2 = df.groupby("性别").agg([np.mean, np.var])
# 男性 各个特征的 均值 与 方差
male_high_mean = df2.loc["男", "身高"]["mean"]
male_high_var = df2.loc["男", "身高"]["var"]
male_weight_mean = df2.loc["男", "体重"]["mean"]
male_weight_var = df2.loc["男", "体重"]["var"]
male_code_mean = df2.loc["男", "鞋码"]["mean"]
male_code_var = df2.loc["男", "鞋码"]["var"]
from scipy import stats
male_high_p = stats.norm.pdf(180, male_high_mean, male_high_var)
male_weight_p = stats.norm.pdf(120, male_weight_mean, male_weight_var)
male_code_p = stats.norm.pdf(41, male_code_mean, male_code_var)
print('男性:', male_high_p * male_weight_p * male_code_p)
# 女性 各个特征的 均值 与 方差
female_high_mean = df2.loc["女", "身高"]["mean"]
female_high_var = df2.loc["女", "身高"]["var"]
female_weight_mean = df2.loc["女", "体重"]["mean"]
female_weight_var = df2.loc["女", "体重"]["var"]
female_code_mean = df2.loc["女", "鞋码"]["mean"]
female_code_var = df2.loc["女", "鞋码"]["var"]
from scipy import stats
female_high_p = stats.norm.pdf(180, female_high_mean, female_high_var)
female_weight_p = stats.norm.pdf(120, female_weight_mean, female_weight_var)
female_code_p = stats.norm.pdf(41, female_code_mean, female_code_var)
print('女性:', female_high_p * female_weight_p * female_code_p)
print(male_high_p*male_weight_p*male_code_p > female_high_p*female_weight_p*female_code_p)
写在后面
这是一个较为简单的案例,理解朴素贝叶斯是一个生成模型,它是一个学习的过程,不断调整认知概率。(生成模型就是:给的结果不是类型,而是概率)进一步理解贝叶斯公式,有助于较好地理解朴素贝叶斯模型。
边栏推荐
猜你喜欢

Minecraft空岛服开服

Tcp/ip - transport layer
Redis zadd导致的一次线上问题排查和处理
Installing Oracle database 19C for Linux

Synchronize files using unison
MYSQL安装出现问题(The service already exists)
Mysql安装时mysqld.exe报`应用程序无法正常启动(0xc000007b)`

Application of kotlin - higher order function

Web技术发展史
Luogu greedy part of the backpack line segment covers the queue to receive water
随机推荐
【Go实战基础】gin 如何验证请求参数
Aneng logistics' share price hit a new low: the market value evaporated by nearly 10 billion yuan, and it's useless for chairman Wang Yongjun to increase his holdings
判断是否是数独
Gocv boundary fill
Mirror protocol of synthetic asset track
Linux binary installation Oracle database 19C
Minecraft group service opening
Nacos download, start and configure MySQL database
Minecraft模组服开服
2022/2/13 summary
Function ‘ngram‘ is not defined
小米电视不能访问电脑共享文件的解决方案
Openfeign facile à utiliser
Tcp/ip - transport layer
Linux安装Oracle Database 19c
Hengyuan cloud_ Can aiphacode replace programmers?
Tensorflow2 keras classification model
Kubesphere virtualization KSV installation experience
Sqli labs Level 2
C4D quick start tutorial - Chamfer