当前位置:网站首页>消息队列消息丢失和消息重复发送的处理策略
消息队列消息丢失和消息重复发送的处理策略
2022-07-03 16:21:00 【程序猿DD_】
来源:https://www.jianshu.com/p/533fc6fc0963
分布式事务
什么是分布式事务
我们的服务器从单机发展到拥有多台机器的分布式系统,各个系统之前需要借助于网络进行通信,原有单机中相对可靠的方法调用以及进程间通信方式已经没有办法使用,同时网络环境也是不稳定的,造成了我们多个机器之间的数据同步问题,这就是典型的分布式事务问题。
在分布式事务中事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。分布式事务就是要保证不同节点之间的数据一致性。
常见的分布式事务解决方案
1、2PC(二阶段提交)方案 - 强一致性
2、3PC(三阶段提交)方案
3、TCC (Try-Confirm-Cancel)事务 - 最终一致性
4、Saga事务 - 最终一致性
5、本地消息表 - 最终一致性
6、MQ事务 - 最终一致性
这里重点关注下使用消息队列实现分布式的一致性,上面几种的分布式设计方案的具体细节可参见文章最后的引用链接
基于 MQ 实现的分布式事务
本地消息表-最终一致性
消息的生产方,除了维护自己的业务逻辑之外,同时需要维护一个消息表。这个消息表里面记录的就是需要同步到别的服务的信息,当然这个消息表,每个消息都有一个状态值,来标识这个消息有没有被成功处理。
发送放的业务逻辑以及消息表中数据的插入将在一个事务中完成,这样避免了业务处理成功 + 事务消息发送失败,或业务处理失败 + 事务消息发送成功,这个问题。
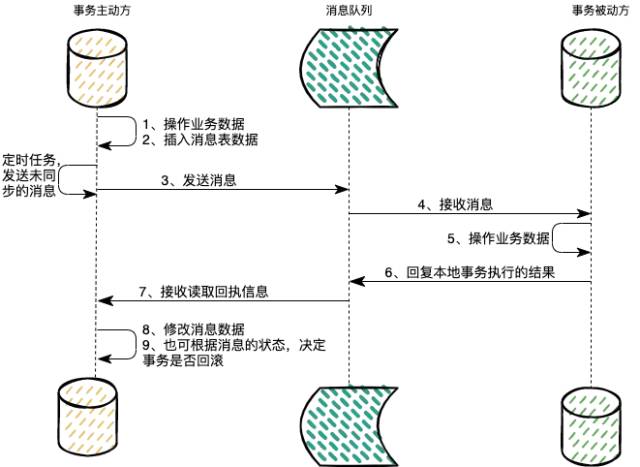
举个栗子:
我们假定目前有两个服务,订单服务,购物车服务,用户在购物车中对几个商品进行合并下单,之后需要清空购物车中刚刚已经下单的商品信息。
1、消息的生产方也就是订单服务,完成了自己的逻辑(对商品进行下单操作)然后把这个消息通过 mq 发送到需要进行数据同步的其他服务中,也就是我们栗子中的购物车服务。
2、其他服务(购物车服务)会监听这个队列;
1、如果收到这个消息,并且数据同步执行成功了,当然这也是一个本地事务,就通过 mq 回复消息的生产方(订单服务)消息已经处理了,然后生产方就能标识本次事务已经结束。如果是一个业务上的错误,就回复消息的生产方,需要进行数据回滚了。
2、很久没收到这个消息,这种情况是不会发生的,消息的发送方会有一个定时的任务,会定时重试发送消息表中还没有处理的消息;
3、消息的生产方(订单服务)如果收到消息回执;
1、成功的话就修改本次消息已经处理完,也就是本次分布式事务的同步已经完成;
2、如果消息的结果是执行失败,同时在本地回滚本次事务,标识消息已经处理完成;
3、如果消息丢失,也就是回执消息没有收到,这种情况也不太会发生,消息的发送方(订单服务)会有一个定时的任务,定时重试发送消息表中还没有处理的消息,下游的服务需要做幂等,可能会收到多次重复的消息,如果一个回复消息生产方中的某个回执信息丢失了,后面持续收到生产方的 mq 消息,然后再次回复消息的生产方回执信息,这样总能保证发送者能成功收到回执,消息的生产方在接收回执消息的时候也要做到幂等性。
这里有两个很重要的操作:
1、服务器处理消息需要是幂等的,消息的生产方和接收方都需要做到幂等性;
2、发送放需要添加一个定时器来遍历重推未处理的消息,避免消息丢失,造成的事务执行断裂。
该方案的优缺点
优点:
1、在设计层面上实现了消息数据的可靠性,不依赖消息中间件,弱化了对 mq 特性的依赖。
2、简单,易于实现。
缺点:
主要是需要和业务数据绑定到一起,耦合性比较高,使用相同的数据库,会占用业务数据库的一些资源。
MQ事务-最终一致性
下面分析下几种消息队列对事务的支持
RocketMQ中如何处理事务
RocketMQ 中的事务,它解决的问题是,确保执行本地事务和发消息这两个操作,要么都成功,要么都失败。并且,RocketMQ 增加了一个事务反查的机制,来尽量提高事务执行的成功率和数据一致性。
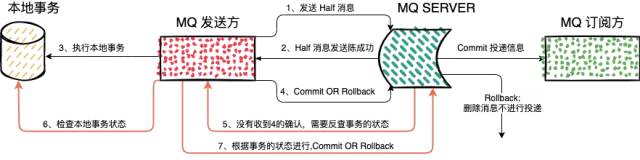
主要是两个方面,正常的事务提交和事务消息补偿
正常的事务提交
1、发送消息(half消息),这个 half 消息和普通消息的区别,在事务提交 之前,对于消费者来说,这个消息是不可见的。
2、MQ SERVER写入信息,并且返回响应的结果;
3、根据MQ SERVER响应的结果,决定是否执行本地事务,如果MQ SERVER写入信息成功执行本地事务,否则不执行;
4、根据本地事务执行的状态,决定是否对事务进行 Commit 或者 Rollback。MQ SERVER收到 Commit,之后就会投递该消息到下游的订阅服务,下游的订阅服务就能进行数据同步,如果是 Rollback 则该消息就会被丢失;
如果MQ SERVER没有收到 Commit 或者 Rollback 的消息,这种情况就需要进行补偿流程了
补偿流程
1、MQ SERVER如果没有收到来自消息发送方的 Commit 或者 Rollback 消息,就会向消息发送端也就是我们的服务器发起一次查询,查询当前消息的状态;
2、消息发送方收到对应的查询请求,查询事务的状态,然后把状态重新推送给MQ SERVER,MQ SERVER就能之后后续的流程了。
相比于本地消息表来处理分布式事务,MQ 事务是把原本应该在本地消息表中处理的逻辑放到了 MQ 中来完成。
Kafka中如何处理事务
Kafka 中的事务解决问题,确保在一个事务中发送的多条信息,要么都成功,要么都失败。也就是保证对多个分区写入操作的原子性。
通过配合 Kafka 的幂等机制来实现 Kafka 的 Exactly Once,满足了读取-处理-写入这种模式的应用程序。当然 Kafka 中的事务主要也是来处理这种模式的。
什么是读取-处理-写入模式呢?
栗如:在流计算中,用 Kafka 作为数据源,并且将计算结果保存到 Kafka 这种场景下,数据从 Kafka 的某个主题中消费,在计算集群中计算,再把计算结果保存在 Kafka 的其他主题中。这个过程中,要保证每条消息只被处理一次,这样才能保证最终结果的成功。Kafka 事务的原子性就保证了,读取和写入的原子性,两者要不一起成功,要不就一起失败回滚。
这里来分析下 Kafka 的事务是如何实现的
它的实现原理和 RocketMQ 的事务是差不多的,都是基于两阶段提交来实现的,在实现上可能更麻烦
先来介绍下事务协调者,为了解决分布式事务问题,Kafka 引入了事务协调者这个角色,负责在服务端协调整个事务。这个协调者并不是一个独立的进程,而是 Broker 进程的一部分,协调者和分区一样通过选举来保证自身的可用性。
Kafka 集群中也有一个特殊的用于记录事务日志的主题,里面记录的都是事务的日志。同时会有多个协调者的存在,每个协调者负责管理和使用事务日志中的几个分区。这样能够并行的执行事务,提高性能。
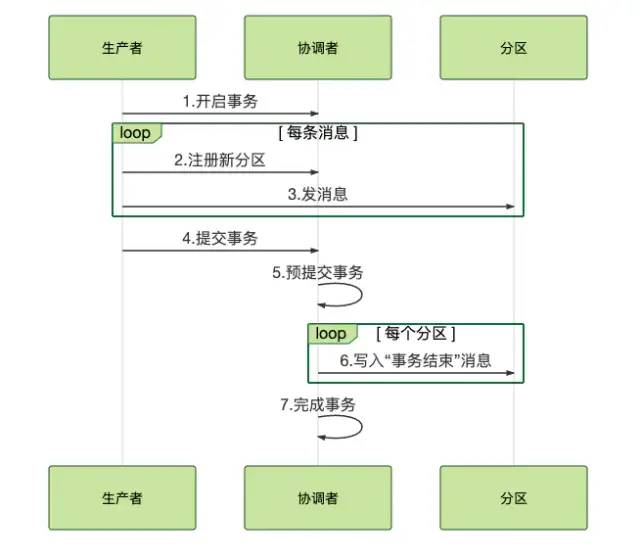
下面看下具体的流程
1、首先在开启事务的时候,生产者会给协调者发送一个开启事务的请求,协调者在事务日志中记录下事务ID;
2、然后生产者开始发送事务消息给协调者,不过需要先发送消息告知协调者在哪个主题和分区,之后就正常的发送事务消息,这些事务消息不像 RocketMQ 会保存在特殊的队列中,Kafka 未提交的事务消息和普通的消息一样,只是在消费的时候依赖客户端进行过滤。
3、消息发送完成,生产者根据自己的执行的状态对协调者进行事务的提交或者回滚;
事务的提交
1、协调者设置事务的状态为PrepareCommit,写入到事务日志中;
2、协调者在每个分区中写入事务结束的标识,然后客户端就能把之前过滤的未提交的事务消息放行给消费端进行消费了;
事务的回滚
1、协调者设置事务的状态为PrepareAbort,写入到事务日志中;
2、协调者在每个分区中写入事务回滚的标识,然后之前未提交的事务消息就能被丢弃了;
这里引用一下【消息队列高手课中的图片】
RabbitMQ中的事务
RabbitMQ 中事务解决的问题是确保生产者的消息到达MQ SERVER,这和其他 MQ 事务还是有点差别的,这里也不展开讨论了。
消息防丢失
先来分析下一条消息在 MQ 中流转所经历的阶段。

生产阶段:生产者产生消息,通过网络发送到 Broker 端。
存储阶段:Broker 拿到消息,需要进行落盘,如果是集群版的 MQ 还需要同步数据到其他节点。
消费阶段:消费者在 Broker 端拉数据,通过网络传输到达消费者端。
生产阶段防止消息丢失
发生网络丢包、网络故障等这些会导致消息的丢失
RabbitMQ 中的防丢失措施
1、对于可以感知的错误,我们捕获错误,然后重新投递;
2、通过 RabbitMQ 中的事务解决,RabbitMQ 中的事务解决的就是生产阶段消息丢失的问题;
在生产者发送消息之前,通过channel.txSelect开启一个事务,接着发送消息, 如果消息投递 server 失败,进行事务回滚channel.txRollback,然后重新发送, 如果 server 收到消息,就提交事务channel.txCommit
不过使用事务性能不好,这是同步操作,一条消息发送之后会使发送端阻塞,以等待RabbitMQ Server的回应,之后才能继续发送下一条消息,生产者生产消息的吞吐量和性能都会大大降低。
3、使用发送确认机制。
使用确认机制,生产者将信道设置成 confirm 确认模式,一旦信道进入 confirm 模式,所有在该信道上面发布的消息都会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后,RabbitMQ 就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一 deliveryTag 和 multiple 参数),这就使得生产者知晓消息已经正确到达了目的地了。
multiple 为 true 表示的是批量的消息确认,为 true 的时候,表示小于等于返回的 deliveryTag 的消息 id 都已经确认了,为 false 表示的是消息 id 为返回的 deliveryTag 的消息,已经确认了。
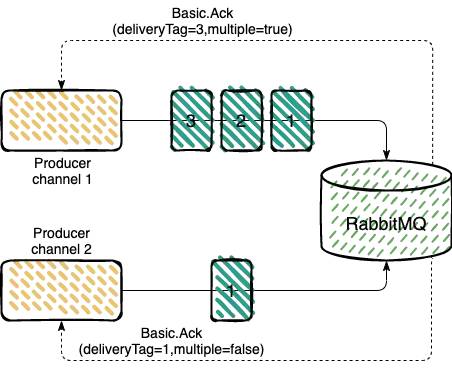
确认机制有三种类型
1、同步确认
2、批量确认
3、异步确认
同步模式的效率很低,因为每一条消息度都需要等待确认好之后,才能处理下一条;
批量确认模式相比同步模式效率是很高,不过有个致命的缺陷,一旦回复确认失败,当前确认批次的消息会全部重新发送,导致消息重复发送;
异步模式就是个很好的选择了,不会有同步模式的阻塞问题,同时效率也很高,是个不错的选择。
Kafka 中的防丢失措施
Kafaka 中引入了一个 broker。broker 会对生产者和消费者进行消息的确认,生产者发送消息到 broker,如果没有收到 broker 的确认就可以选择继续发送。
只要 Producer 收到了 Broker 的确认响应,就可以保证消息在生产阶段不会丢失。有些消息队列在长时间没收到发送确认响应后,会自动重试,如果重试再失败,就会以返回值或者异常的方式告知用户。
只要正确处理 Broker 的确认响应,就可以避免消息的丢失。
RocketMQ 中的防丢失措施
使用 SYNC 的发送消息方式,等待 broker 处理结果
RocketMQ 提供了3种发送消息方式,分别是:
同步发送:Producer 向 broker 发送消息,阻塞当前线程等待 broker 响应 发送结果。
异步发送:Producer 首先构建一个向 broker 发送消息的任务,把该任务提交给线程池,等执行完该任务时,回调用户自定义的回调函数,执行处理结果。
Oneway发送:Oneway 方式只负责发送请求,不等待应答,Producer 只负责把请求发出去,而不处理响应结果。
使用事务,RocketMQ 中的事务,它解决的问题是,确保执行本地事务和发消息这两个操作,要么都成功,要么都失败。
存储阶段
在存储阶段正常情况下,只要 Broker 在正常运行,就不会出现丢失消息的问题,但是如果 Broker 出现了故障,比如进程死掉了或者服务器宕机了,还是可能会丢失消息的。
RabbitMQ 中的防丢失措施
防止在存储阶段消息额丢失,可以做持久化,防止异常情况(重启,关闭,宕机)。。。
RabbitMQ 持久化中有三部分:
交换器的持久化
交换器的持久化,是通过在声明队列时将 durable 参数置为 true 实现的,不设置持久化的话,交换器的信息将会丢失。
队列持久化
队列的持久化,是通过在声明队列时将 durable 参数置为 true 实现的,队列的持久化能保证其本身的元数据不会因异常情况而丢失,但是并不能保证内部所存储的消息不会丢失。
消息的持久化
消息的持久化,在投递时指定 delivery_mode=2(1是非持久化),消息的持久化,需要配合队列的持久,只设置消息的持久化,重启之后队列消失,继而消息也会丢失。所以如果只设置消息持久化而不设置队列的持久化意义不大。
对于持久化,如果所有的消息都设置持久化,会影响写入的性能,所以可以选择对可靠性要求比较高的消息进行持久化处理。
不过消息持久化并不能百分之百避免消息的丢失
比如数据在落盘的过程中宕机了,消息还没及时同步到内存中,这也是会丢数据的,这种问题可以通过引入镜像队列来解决。
镜像队列的作用:引入镜像队列,可已将队列镜像到集群中的其他 Broker 节点之上,如果集群中的一个节点失效了,队列能够自动切换到镜像中的另一个节点上来保证服务的可用性。(更细节的这里不展开讨论了)
Kafka 中的防丢失措施
操作系统本身有一层缓存,叫做 Page Cache,当往磁盘文件写入的时候,系统会先将数据流写入缓存中。
Kafka 收到消息后也会先存储在也缓存中(Page Cache)中,之后由操作系统根据自己的策略进行刷盘或者通过 fsync 命令强制刷盘。如果系统挂掉,在 PageCache 中的数据就会丢失。也就是对应的 Broker 中的数据就会丢失了。
处理思路
1、控制竞选分区 leader 的 Broker。如果一个 Broker 落后原先的 Leader 太多,那么它一旦成为新的 Leader,必然会造成消息的丢失。
2、控制消息能够被写入到多个副本中才能提交,这样避免上面的问题1。
RocketMQ 中的防丢失措施
1、将刷盘方式改成同步刷盘;
2、对于多个节点的 Broker,需要将 Broker 集群配置成:至少将消息发送到 2 个以上的节点,再给客户端回复发送确认响应。这样当某个 Broker 宕机时,其他的 Broker 可以替代宕机的 Broker,也不会发生消息丢失。
消费阶段
消费阶段就很简单了,如果在网络传输中丢失,这个消息之后还会持续的推送给消费者,在消费阶段我们只需要控制在业务逻辑处理完成之后再去进行消费确认就行了。
总结:对于消息的丢失,也可以借助于本地消息表的思路,消息产生的时候进行消息的落盘,长时间未处理的消息,使用定时重推到队列中。
消息重复发送
消息在 MQ 中的传递,大致可以归类为下面三种:
1、At most once: 至多一次。消息在传递时,最多会被送达一次。是不安全的,可能会丢数据。
2、At least once: 至少一次。消息在传递时,至少会被送达一次。也就是说,不允许丢消息,但是允许有少量重复消息出现。
3、Exactly once:恰好一次。消息在传递时,只会被送达一次,不允许丢失也不允许重复,这个是最高的等级。
大部分消息队列满足的都是At least once,也就是可以允许重复的消息出现。
我们消费者需要满足幂等性,通常有下面几种处理方案
1、利用数据库的唯一性
根据业务情况,选定业务中能够判定唯一的值作为数据库的唯一键,新建一个流水表,然后执行业务操作和流水表数据的插入放在同一事务中,如果流水表数据已经存在,那么就执行失败,借此保证幂等性。也可先查询流水表的数据,没有数据然后执行业务,插入流水表数据。不过需要注意,数据库读写延迟的情况。
2、数据库的更新增加前置条件
3、给消息带上唯一ID
每条消息加上唯一ID,利用方法1中通过增加流水表,借助数据库的唯一性来处理重复消息的消费。
我们创建了一个高质量的技术交流群,与优秀的人在一起,自己也会优秀起来,赶紧点击加群,享受一起成长的快乐。另外,如果你最近想跳槽的话,年前我花了2周时间收集了一波大厂面经,节后准备跳槽的可以点击这里领取!
推荐阅读
··································
你好,我是程序猿DD,10年开发老司机、阿里云MVP、腾讯云TVP、出过书创过业、国企4年互联网6年。从普通开发到架构师、再到合伙人。一路过来,给我最深的感受就是一定要不断学习并关注前沿。只要你能坚持下来,多思考、少抱怨、勤动手,就很容易实现弯道超车!所以,不要问我现在干什么是否来得及。如果你看好一个事情,一定是坚持了才能看到希望,而不是看到希望才去坚持。相信我,只要坚持下来,你一定比现在更好!如果你还没什么方向,可以先关注我,这里会经常分享一些前沿资讯,帮你积累弯道超车的资本。
边栏推荐
- ASEMI整流桥UMB10F参数,UMB10F规格,UMB10F封装
- 手机注册股票开户安全吗 开户需要钱吗
- Mixlab编辑团队招募队友啦~~
- Stm32f103c8t6 firmware library lighting
- Visual SLAM algorithms: a survey from 2010 to 2016
- LeetCode1491. Average value of wages after removing the minimum wage and the maximum wage
- 8个酷炫可视化图表,快速写出老板爱看的可视化分析报告
- Qt插件之自定义插件构建和使用
- Mysql 单表字段重复数据取最新一条sql语句
- Expression of request header in different countries and languages
猜你喜欢

NFT新的契机,多媒体NFT聚合平台OKALEIDO即将上线
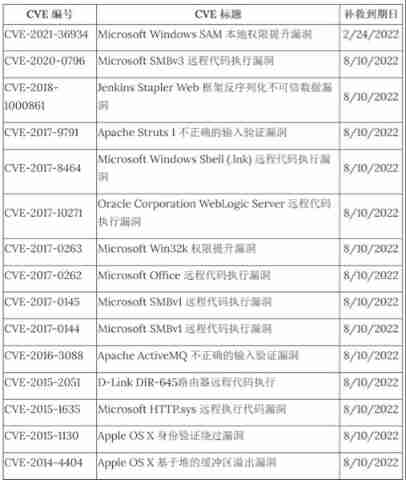
Famous blackmail software stops operation and releases decryption keys. Most hospital IOT devices have security vulnerabilities | global network security hotspot on February 14
【Proteus仿真】8×8LED点阵屏仿电梯数字滚动显示
Slam learning notes - build a complete gazebo multi machine simulation slam from scratch (I)
Explore Cassandra's decentralized distributed architecture

Unreal_DataTable 实现Id自增与设置RowName

Project -- high concurrency memory pool
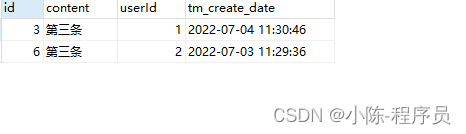
Mysql 单表字段重复数据取最新一条sql语句

0214-27100 a day with little fluctuation
Stm32f103c8t6 firmware library lighting
随机推荐
First knowledge of database
NFT新的契机,多媒体NFT聚合平台OKALEIDO即将上线
Nifi from introduction to practice (nanny level tutorial) - flow
The difference between calling by value and simulating calling by reference
Batch files: list all files in a directory with relative paths - batch files: list all files in a directory with relative paths
【Proteus仿真】74HC595+74LS154驱动显示16X16点阵
Leetcode binary search tree
记一次jar包冲突解决过程
Construction practice camp - graduation summary of phase 6
Pychart error updating package list: connect timed out
MongoDB 的安装和基本操作
Characteristic polynomial and constant coefficient homogeneous linear recurrence
Interviewer: how does the JVM allocate and recycle off heap memory
程序猿如何快速成长
为抵制 7-Zip,列出 “三宗罪” ?网友:“第3个才是重点吧?”
The accept attribute of the El upload upload component restricts the file type (detailed explanation of the case)
Nine ways to define methods in scala- Nine ways to define a method in Scala?
Using optimistic lock and pessimistic lock in MySQL to realize distributed lock
相同切入点的抽取
在ntpdate同步时间的时候出现“the NTP socket is in use, exiting”