当前位置:网站首页>Deep learning | rnn/lstm of naturallanguageprocessing
Deep learning | rnn/lstm of naturallanguageprocessing
2022-07-01 03:49:00 【RichardsZ_】
Cyclic neural network RNN
Tips : This article assumes that readers have basic in-depth learning knowledge , Such as weighted activation , Chain derivative , Weight matrix and other information .
List of articles
Preface
RNN Very suitable " Have Sequence properties Characteristics of ", Therefore, it can mine temporal information and semantic information in features . Take advantage of RNN This ability , Make the deep learning model solve speech recognition 、 Language model 、 Machinetranslation and time series analysis NLP Some breakthroughs have been made in the field .
Sequence properties , That is, in chronological order , Logical order , Or other sequences are called sequence properties , Take a few examples :
- Take a human sentence , That is, human natural language , Is it a combination of words that conform to a certain logic or rule , This is consistent with the sequence characteristics .
- voice , The sound we make , Every frame, every frame , That's what we heard , This also has sequence characteristics 、
- Stocks , as time goes on , A series of numbers with sequence will be generated , These numbers also have sequence characteristics .
One 、 Cyclic neural network structure
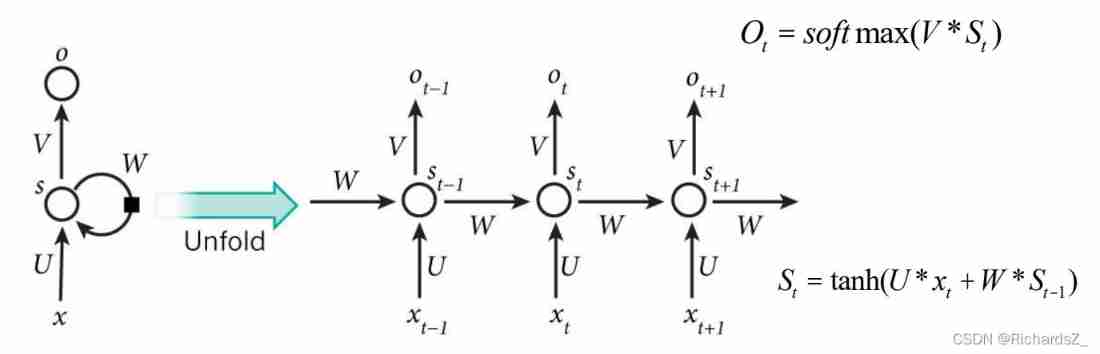
among ,
x: Feature input vector , x t − 1 , x t , x t + 1 x_{t-1}, x_t, x_{t+1} xt−1,xt,xt+1 Represent the t-1, t, t+1 Characteristic input vector at time .
U: Weight matrix from input layer to hidden layer , For fully connected neural networks , The state of the hidden layer = U ∗ x U*x U∗x
W: The value of the hidden layer at the previous time , The weight matrix as one of this input
s t = f ( U ∗ x t + W ∗ s t − 1 ) s_t = f(U* x_t+W*s_{t-1}) st=f(U∗xt+W∗st−1)
Now it looks clearer , This network is in t Always receive input x t x_t xt after , The value of the hidden layer is s t s_t st, The output value is o t o_t ot .
The key point is , s t s_t st It's not just about x t x_t xt, It also depends on s t − 1 s_{t-1} st−1.
Two deformations

Elman Network
The output of the hidden layer is used as the input of the hidden layer at the next time , That is, the most rustic RNN
Jordan Network
difference : Output layer output ( namely o Output ) As the input of the next hidden layer , This contains the information of the weight matrix from the hidden layer to the output layer
As for two kinds RNN Which is better or worse , There is little difference , No conclusion , It depends on whether the business itself needs information from the hidden layer to the output layer , As a try . But actually , These two kinds of RNN It is no longer used by industry , While using LSTM or Attention Mechanism , This is the later story. !
shortcoming
for instance , The machine translation scenario shown in the figure below . When the last moment , namely RNN The input is French This word , The output of the hidden layer on the network at one time is "fluent" even to the extent that "speak" The two words are related , But with "France" Basically irrelevant , Obviously, this does not meet our expectations .
On the other hand , The network structure is shown in the figure below ,t+1 The hidden layer of time and t 0 , t 1 t_0, t_1 t0,t1 The state of is basically irrelevant , therefore RNN For sequence data , The mutual information with long sequence spacing is lost , This is also RNN The fatal flaw of 
One sentence summary
RNN: One that can cope with Sequence properties Changing neural network structure , The input of hidden neurons comes from the input of this moment , It also includes the output of the hidden layer at the previous time .
shortcoming : The information with long middle distance of sequence data will cause loss , That is, the network only saves short-term memory , Lost long-term associative memory
Two 、LSTM- Long and short memory network
In order to solve RNN It can't be solved by itself “ Long term related information ”,1997 German scientists introduced LSTM The Internet , It's a special RNN The Internet , Used for processing “ Long term related information ”,
The core idea : door
Oblivion gate
Output :0-1 Probability 
Input gate

So given a C t C_t Ct after , And multiply by a factor i t i_t it, For input data C t C_t Ct When flowing to the next moment , How much information is retained . What is really controlled is a few parameters , In the original training , Adjust through data W and b Make the result meet the maximum likelihood value in the training data .
Update door

therefore LSTM The core is to control the weight W And offset b, To control the forgetting door , Update the status of the door , It is decided that in the information at this time “ Proportion of forgotten information ” and “ Proportion of new input information ”, When there is a long-term relationship in the sequence data , Maybe in the middle of time cells in i t i_t it The share is relatively small , f t f_t ft It's a big part , Long term relationship has been realized
( Optional )LSTM/GRU Optimize
In order to reduce the coefficient of calculation , Directly change the coefficient of the update door to 1 − f t 1-f_t 1−ft, And forgetting gate are mutually exclusive , The network structure is more concise 
Given a corpus information , Through the maximum likelihood value of the training set , To train W Equal weight , after softmax, Predict the words most likely to appear in the next moment
边栏推荐
- The difference between MFC for static libraries and MFC for shared libraries
- 242. valid Letter heteronyms
- torch. histc
- 整合阿里云短信的问题:无法从静态上下文中引用非静态方法
- Inventory the six second level capabilities of Huawei cloud gaussdb (for redis)
- 409. longest palindrome
- Leetcode: offer 59 - I. maximum value of sliding window
- Bilinear upsampling and f.upsample in pytorch_ bilinear
- [reach out to Party welfare] developer reload system sequence
- Complete knapsack problem
猜你喜欢
LeetCode 128最长连续序列(哈希set)

Jeecgboot output log, how to use @slf4j

Unexpected token o in JSON at position 1 ,JSON解析问题
![Online public network security case nanny level tutorial [reaching out for Party welfare]](/img/66/d9c848a7888e547b7cb28d84aabc24.png)
Online public network security case nanny level tutorial [reaching out for Party welfare]

Idea plug-in backup table

复习专栏之---消息队列

报错:Plug-ins declaring extensions or extension points must set the singleton directive to true
Access denied for user ‘ODBC‘@‘localhost‘ (using password: NO)

431. 将 N 叉树编码为二叉树 DFS
在线公网安备案保姆级教程【伸手党福利】
随机推荐
242. valid Letter heteronyms
LeetCode 144二叉树的前序遍历、LeetCode 114二叉树展开为链表
Leetcode: offer 59 - I. maximum value of sliding window
318. Maximum word length product
Leetcode:剑指 Offer 59 - I. 滑动窗口的最大值
[ta - Frost Wolf May - 100 people plan] 1.2.1 base vectorielle
torch.histc
【TA-霜狼_may-《百人计划》】2.1 色彩空间
【EI会议】2022年第三届纳米材料与纳米技术国际会议(NanoMT 2022)
【TA-霜狼_may-《百人計劃》】1.2.1 向量基礎
[TA frost wolf \u may - "hundred people plan"] 2.1 color space
[EI search] important information conference of the 6th International Conference on materials engineering and advanced manufacturing technology (meamt 2022) in 2022 website: www.meamt Org meeting time
Unexpected token o in JSON at position 1 ,JSON解析问题
MFC窗口滚动条用法
Visit the image URL stored by Alibaba cloud to preview the thumbnail directly on the web page instead of downloading it directly
Appium automation test foundation -- supplement: c/s architecture and b/s architecture description
392. 判断子序列
[TA frost wolf \u may- hundred people plan] 1.3 secret of texture
Feature pyramid networks for object detection
【EI会议】2022年国际土木与海洋工程联合会议(JCCME 2022)