当前位置:网站首页>[paper translation] recent advances in open set recognition: a survey
[paper translation] recent advances in open set recognition: a survey
2022-06-11 01:11:00 【xiongxyowo】
[ Address of thesis ][TPAMI 21]
The chart part of the paper is omitted
Recent Advances in Open Set Recognition: A Survey
Abstract
Recognition in the real world / In the classification task , Limited by various objective factors , When training a recognizer or classifier , It is often difficult to collect training samples to exhaust all categories . A more realistic situation is open set recognition (OSR), There is an incomplete understanding of the world during training , Classes unknown during testing can be submitted to the algorithm , This requires the classifier not only to accurately classify the classes seen , Also effectively handle classes that you don't see . This paper makes a comprehensive investigation on the existing open set recognition technology , Covered from relevant definitions 、 The representation of the model 、 Data sets 、 Evaluation criteria and algorithm comparison . Besides , We briefly analyzed OSR And its related tasks , Include Zero-Shot、One-Shot(Few-Shot) distinguish / Learning technology 、 Categories with reject options, etc . Besides , We also reviewed the identification of the open world , It can be seen as OSR The natural extension of . It is important to , We emphasize the limitations of the existing methods , Some promising future research directions in this field are pointed out .
I. Introduction
In a common closed set ( Or static environment ) Under assumption : Training and test data come from the same label and feature space , Traditional identification / Classification algorithms have been used in various machine learning (ML) Great success in the mission . However , More realistic scenarios are usually open 、 Unstable , Like driverless 、 fault / Medical diagnosis, etc , Things you haven't seen will happen unexpectedly , This greatly weakens the robustness of these existing methods . To meet this challenge , People have explored some related research topics , Including lifelong learning 、 The migration study 、 Domain adaptation 、Zero-Shot、One-Shot, Open set recognition / classification , wait .
be based on Donald Rumsfeld The famous "There are known knowns" That's what I'm saying , We further expanded [22] The basic identification class asserted , We reiterate , Identify categories that should consider the following four basic categories :
- 1)Known Known Classes (KKC). That is, positive training samples with explicit markers ( Also as other KKC A negative sample of ) Class , It even has corresponding side information , Such as semantics / Attribute information, etc .
- 2)Known Unknown Classes (KUC). Negative samples with labels , Not necessarily classified as a meaningful class , Such as background class ,universum Class, etc. .
- 3)Unknown Known Classes (UKC). That is, there are no classes with available samples in the training , But their profile information can be obtained in training ( Such as semantics / Attribute information ).
- 4)Unknown Unknown Classes (UUC). That is, the class without any relevant information during the training : Not only haven't you seen , And there is no profile information during training ( for example , semantics / Attribute information, etc ).
chart 1 An example using t-SNE Visualize from real data distribution KKC、KUC and UUC Example . Please note that , because UKC and UUC The main difference between them is whether their profile information is available , We are here only for UUC Visualizing . The traditional classification only considers KKC, Including KUC Will result in a clear " Other categories " Model of , Or a detector trained with unclassified negatives . Different from the traditional classification ,Zero-Shot Learning Pay more attention to UKC The identification of . It is said that : There are no assumptions about the relationship between the past and the future , Prediction is impossible .ZSL utilize KKC and UKC The semantic information shared between them to realize this recognition . in fact , Suppose the test sample is only from UKC Is quite restrictive , It's also unrealistic , Because we usually think about KKC or UKC Nothing . On the other hand , The frequency of objects in nature follows the long tail distribution , signify KKC Than UKC More common . therefore , Some researchers are beginning to focus on the wider Zero-Shot Learning, The test samples are from KKC and UKC. As one with ZSL Closely related issues , During training UKC When the number of samples is limited , A single / A few studies (Few-Shot Learning) Can be regarded as ZSL Natural expansion of . And G-ZSL similar , Consider both in the test KKC and UKC Of FSL More realistic settings for , In a broad sense FSL(G-FSL), And it's becoming more and more popular . And (G-)ZSL and (G-)FSL comparison , Open set recognition (OSR) May face more serious challenges , Because only KKC, No other profile information , Such as attributes or UUC A limited number of samples .
Open set recognition describes such a situation : New classes not seen in training (UUC) Appear in the test , The classifier is required not only to accurately correct KKC To classify , And deal effectively with UUC. therefore , When the test sample comes from a UUC when , The classifier needs to have a corresponding reject option . chart 2 The traditional classification and OSR A comparative demonstration of the problem . It should be pointed out that , There has been a lot of work in the literature on classifications with reject options . Although it is relevant in a sense , But this task should not be confused with open set recognition , Because it still works under the closed set assumption , The corresponding classifier refuses to recognize the input samples because of its low confidence , Avoid classifying samples from one category as members of another category .
Besides , The single class classifier usually used for anomaly detection seems to be suitable for OSR problem , The empirical distribution of training data is modeled , So that it can be in all directions of the feature space and the surrounding open space ( Stay away from the known / Space for training data ) Separate . Popular single class classification methods include single class SVM And support vector data description (SVDD), Among them, single class SVM The training samples are separated from the origin of the feature space by the maximum margin , and SVDD Surround the training data with the smallest superball . Please note that , In single class settings , Will be multiple KKC Think of it as a , These are obviously ignored KKC Discrimination information between , Resulting in poor performance . Even if like [37] As proposed in , Every KKC It is modeled by a single single class classifier , Its novelty detection performance is also quite low . therefore , It is necessary to specialize in OSR problem , Especially multi class OSR problem , Rebuild an effective classifier .
As a summary , surface 1 Lists the differences between open set recognition and its related tasks mentioned above . in fact ,OSR Already in many frameworks 、 Hypotheses and names have been studied . In the research of evaluation methods of face recognition ,Phillips Et al. Proposed a typical open set identity recognition framework , and Li and Wechsler From the perspective of evaluation, open set face recognition , An open set transformation confidence machine is proposed -k a near neighbor (TCM-kNN) Method . yes Scheirer Et al. Formalized the open set identification problem for the first time , And put forward a preliminary solution -1- To the collector , Open space risk items are added to the modeling , To account for exceeding KKC Space for reasonable support . after , Open set recognition has attracted wide attention . Please note that , Recently about ZSL The survey mentioned OSR, However , It is not widely discussed . And [10] The difference is , We are here to provide an introduction to OSR Comprehensive review of .
The rest of this article is organized as follows . In the next three sections , We first give the basic symbols and related definitions ( The first 2 section ). then , From the point of view of modeling, we analyze the existing OSR Technology , For each category , We reviewed the table in detail 2 The different methods given in ( The first 3 section ). Last , In Section 4, we review open world recognition (OWR), It can be seen as OSR The natural extension of . Besides , The first 5 Section reports on commonly used data sets 、 Evaluation criteria and algorithm comparison , And the first 6 Section highlights the limitations of existing methods , Some promising research directions in this field are pointed out . Last , The first 7 Section gives a conclusion .
II. Basic Notation and Related Definition
This section briefly reviews [21] Formalized as described in OSR problem . just as [21] As discussed in , Space away from known data ( Include KKC and KUC) It is usually considered an open space O \mathcal {O} O. So mark any sample in this space as an arbitrary KKC There will inevitably be risks , This is called open space risk R O R_\mathcal {O} RO. because UUC Is unknowable in training , Therefore, it is often difficult to make quantitative analysis on the risk of open space . in addition ,[21] given R O R_\mathcal {O} RO Qualitative description of , It is formalized as an open space O \mathcal {O} O With the overall measurement space S o S_o So The relative measure of comparison . R O ( f ) = ∫ O f ( x ) d x ∫ S o f ( x ) d x R_\mathcal {O}(f) = \frac{\int _\mathcal {O}f(x)dx}{\int _{S_o}f(x)dx} RO(f)=∫Sof(x)dx∫Of(x)dx among f f f Represents a measurable identification function . f ( x ) = 1 f(x)=1 f(x)=1 Express KKC A category in is identified , otherwise f ( x ) = 0 f(x)=0 f(x)=0. In this formalization , The more we mark the samples in the open space as KKC, R O R_\mathcal {O} RO The greater the .
Besides , The author in [21] It also formally introduces the concept of openness to a particular problem or data universe .
Definition 1( It's defined in [21] Openness in ) Give Way C T A C_{TA} CTA、 C T R C_{TR} CTR and C T E C_{TE} CTE Respectively represent the class set to be identified 、 The class set used in training and the class set used in testing . Then the corresponding identification task O O O The openness of is : O = 1 − 2 × ∣ C TR ∣ ∣ C TA ∣ + ∣ C TE ∣ O = 1 - \sqrt{\frac{2\times |C_{\text{TR}}|}{|C_{\text{TA}}| + |C_{\text{TE}}|}} O=1−∣CTA∣+∣CTE∣2×∣CTR∣
among ∣ ⋅ ∣ |\cdot| ∣⋅∣ Represents the number of classes in the corresponding collection .
Greater openness corresponds to more open issues , And when openness equals 0 when , The problem is completely closed . Be careful [21] It's not clear that C T A C_{TA} CTA、 C T R C_{TR} CTR and C T E C_{TE} CTE The relationship between . In most existing work , C T A = C T R ⊆ C T E C_{TA}=C_{TR} \subseteq C_{TE} CTA=CTR⊆CTE This relationship is established by default . Besides ,[82] In particular, the author gives the following relationship . C T A ⊆ C T R ⊆ C T E C_{TA} \subseteq C_{TR} \subseteq C_{TE} CTA⊆CTR⊆CTE, It includes the former case . However , Such a relationship defines 1 There's a problem with it . Consider this simple case . C T A ⊆ C T R ⊆ C T E C_{TA} \subseteq C_{TR} \subseteq C_{TE} CTA⊆CTR⊆CTE, also ∣ C T A ∣ = 3 |C_{TA}|=3 ∣CTA∣=3, ∣ C T R ∣ = 10 |C_{TR}|=10 ∣CTR∣=10, C T E = 15 C_{TE}=15 CTE=15. Then we will have O < 0 O<0 O<0, This is clearly unreasonable . in fact , C T A C_{TA} CTA Should be C T R C_{TR} CTR A subset of , Otherwise, it's meaningless , Because people usually don't use it in C T R C_{TR} CTR A classifier trained on the C T R C_{TR} CTR Other classes in . Intuitively speaking , The openness of a particular issue should only depend on KKC stay C T R C_{TR} CTR Knowledge and UUC stay C T E C_{TE} CTE Knowledge in , instead of C T A C_{TA} CTA、 C T R C_{TR} CTR and C T E C_{TE} CTE Three of them . therefore , In this paper , We recalibrated the open formula : O ∗ = 1 − 2 × ∣ C TR ∣ ∣ C TR ∣ + ∣ C TE ∣ O^\ast = 1 - \sqrt{\frac{2\times |C_{\text{TR}}|}{|C_{\text{TR}}| + |C_{\text{TE}}|}} O∗=1−∣CTR∣+∣CTE∣2×∣CTR∣ And formula (2) comparison , The formula (3) It is only a relatively more reasonable form to estimate openness . Other definitions can also capture this concept , And some definitions may be more precise , Therefore, it is worth further discussion . Considering the concept of open space risk and openness ,OSR The definition of the problem can be given as follows .
Definition 2( Open set identification problem ) set up V For training data , Give Way R O R_\mathcal {O} RO、 R ε R_{\varepsilon } Rε Open space risk and experience risk respectively . that , The goal of open set recognition is to find a measurable recognition function f ∈ H f\in \mathcal {H} f∈H, among f ( x ) > 0 f(x)>0 f(x)>0 It means correct identification , also f f f Is defined by minimizing the following open set risks : arg min f ∈ H { R O ( f ) + λ r R ε ( f ( V ) ) } \arg \min_{f\in \mathcal {H}}\left\lbrace R_\mathcal {O}(f) + \lambda _rR_{\varepsilon }(f(V))\right\rbrace argf∈Hmin{ RO(f)+λrRε(f(V))} among λ r \lambda _r λr Is a regularization constant . The formula (4) The open set risk represented in balances empirical risk and open space risk on function space . Although the initial definition mentioned above is more theoretical , But it's a follow-up OSR Modeling provides important guidance , Led to a series of OSR Algorithm , These algorithms are described in detail in the next section .
III. A Categorization of OSR Techniques
Even though Scheirer People will OSR Problem formalization , But an important question is how to put the formula (1) Incorporate modeling . There is an ongoing debate between the use of generative and discriminant models in statistical learning , There are arguments about the value of each model . However , As in [22] As discussed in , Open set recognition introduces such a new problem , Unless some constraints are imposed , Otherwise, neither discriminant model nor generative model can directly solve the problems existing in open space UUC. therefore , Under some constraints , The researchers studied from the perspective of discriminant and generative OSR The modeling of . Next , We mainly review the existing OSR Model .
According to the modeling form , These models can be further divided into four categories ( surface 2). From the perspective of discriminant model , Based on tradition ML(TML) And based on deep neural network (DNN) Methods ; From the perspective of generating models , Instance based and non instance based methods . For each category , We review different approaches by focusing on their corresponding representative works . Besides , chart 3 The whole picture of the relationship between these methods is given , It also lists links to several available packages ( surface 3), So as to facilitate the follow-up research of relevant researchers . Next , We first review from the perspective of discriminant models , Most of the existing OSR Algorithms are modeled from this point of view .
A. Discriminative Model for OSR
Traditional ML Methods-Based OSR Models
As mentioned above , Traditional machine learning methods ( Such as SVM、 Sparse representation 、 Nearest neighbor, etc ) It is often assumed that training and test data come from the same distribution . However , This assumption is in OSR Is no longer established . To adapt these methods to OSR The situation of , People have made a lot of efforts .
SVM-Based Support vector machine (SVM) It has been successfully applied to traditional classification / Identify the tasks . However , When UUC When it occurs during the test , Its classification performance will be significantly reduced , Because it is usually assumed to be a closed set KKC Divide over occupied space . Pictured 2b Shown , once UUC Of the samples fall into certain KKC Divided space , These samples will never be correctly classified . To overcome this problem , Many are based on SVM Of OSR Methods have been proposed .
Using definitions 2,Scheirer And so forth 1-versus-Set machine , It adds an open space risk item to the modeling , To illustrate KKC Space beyond reasonable support . say concretely , They added another hyperplane , And SVM The separated hyperplane obtained in the fractional space is parallel , This leads to a plate in the feature space . The open space risk of the linear kernel plate model is defined as follows : R O = δ Ω − δ A δ + + δ + δ Ω − δ A + p A ω A + p Ω ω Ω R_{\mathcal {O}} = \frac{\delta _{\Omega } - \delta _A}{\delta ^{+}} + \frac{\delta ^{+}}{\delta _{\Omega } - \delta _A} + p_A\omega _A + p_{\Omega }\omega _{\Omega } RO=δ+δΩ−δA+δΩ−δAδ++pAωA+pΩωΩ among δ A \delta _A δA and δ Ω \delta _{\Omega } δΩ Represents the marginal distance of the corresponding hyperplane , δ + \delta ^{+} δ+ Is the degree of separation required to consider all positive data . Besides , User specified parameters p A p_A pA and p Ω p_{\Omega } pΩ It is used to weigh the marginal space ω A \omega _A ωA and ω Ω \omega _{\Omega } ωΩ The importance of . under these circumstances , The test samples that appear between the two hyperplanes will be marked as appropriate categories . otherwise , It will be treated as non target class or rejected , It depends on which side of the plate it is on . And 1-vs-Set The machine is similar to ,Cevikalp In tradition SVM On the basis of / The sample of the target class adds another constraint , A best fit hyperplane classifier is proposed (BFHC) Model , Directly form plates in the feature space . Besides ,BFHC It can also be extended to non-linear cases by using kernel techniques , For more details, please refer to [63].
Although the plate model mentioned above reduces each binary SVM Of KKC Area , But every KKC The space occupied is still unbounded . therefore , The risks of open space still exist . To overcome this challenge , Researchers are looking for new ways to control this risk .
Scheirer Et al. Incorporated the nonlinear kernel into a solution , By positively marking only sets of finite metrics , Further limit the risk of open space . They formulated a compact reduction probability (CAP) Model , The probability of class members decreases as the point moves from the known data to the open space . say concretely , They put forward a Weibull Calibrated SVM(W-SVM) Model , The model combines the statistical extreme value theory for fractional calibration (EVT) And two separate SVM. first SVM Is a single class used as a conditioner SVM CAP Model : If by a single class SVM Input samples for prediction x A posteriori estimate of P O ( y ∣ x ) P_O(y|x) PO(y∣x) Less than threshold δ r \delta _r δr, The sample will be rejected directly . otherwise , It will be passed to the second SVM. The second is by fitting Weibull Bivariate of cumulative distribution function SVM CAP Model , Generate corresponding positive KKC A posteriori estimate of P η ( y ∣ x ) P_ \eta(y|x) Pη(y∣x). Besides , It also works by reversing Weibull The corresponding negative KKC A posteriori estimate of P ψ ( y ∣ x ) P_ \psi(y|x) Pψ(y∣x). An indicator variable is defined : If P O ( y ∣ x ) > δ r P_O(y|x)>\delta_ r PO(y∣x)>δr, be ι y = 1 \iota _y = 1 ιy=1, otherwise ι y = 0 \iota _y = 0 ιy=0, all KKC Y Of W-SVM Recognition is : y ∗ = arg max y ∈ Y P η ( y ∣ x ) × P ψ ( y ∣ x ) × ι y subject to P η ( y ∗ ∣ x ) × P ψ ( y ∗ ∣ x ) ≥ δ R \begin{aligned} &y^{*}=\arg \max _{y \in \mathcal{Y}} P_{\eta}(y \mid x) \times P_{\psi}(y \mid x) \times \iota_{y} \\ &\text { subject to } P_{\eta}\left(y^{*} \mid x\right) \times P_{\psi}\left(y^{*} \mid x\right) \geq \delta_{R} \end{aligned} y∗=argy∈YmaxPη(y∣x)×Pψ(y∣x)×ιy subject to Pη(y∗∣x)×Pψ(y∗∣x)≥δR among δ R \delta _R δR It's the second one. SVM CAP Threshold of the model . threshold δ r \delta _r δr and δ R \delta _R δR It's based on experience , for example , δ r \delta _r δr Fixed as specified by the author 0.001, and δ R \delta _R δR It is suggested to set according to the openness of specific problems : δ R = 0.5 × openness \delta_{R}=0.5 \times \text { openness } δR=0.5× openness Besides ,W-SVM Be further used in KDDCUP’99 Open set intrusion detection of data sets . More information about Intrusion Detection in open set scenarios can be found in [97] Find . Intuitively speaking , If anything KKC All the positive data were accurately modeled without over fitting , We can turn down a large group UUC( Even under the assumption of incomplete class knowledge ). Based on this intuition ,Jain Et al EVT Modeling the positive training samples of decision boundary , And put forward PI-SVM Algorithm .PI-SVM A threshold based classification scheme is also used , The selection of the corresponding threshold is W-SVM The same strategy in .
Please note that , although W-SVM and PI-SVM The risk of open space is effectively limited by the threshold based classification scheme , But their threshold selection also gives some considerations . First , They assume that all KKC All have the same threshold , This may be unreasonable , Because the distribution of categories in feature space is usually unknown . secondly , It is recommended to set the rejection threshold according to the openness of the problem . However , The openness of the corresponding problem is often unknown .
To solve these problems ,Scherreik Et al. Introduced probabilistic open sets SVM(POS-SVM) classifier , It can be defined empirically 2 Under each KKC Unique rejection threshold for .POS-SVM Not will RO Define relative metrics for open spaces and class defined spaces , They are open space risks R O R_O RO And experience risk R ε R_{\varepsilon} Rε Choose probability to represent ( For details, see [64]). Besides , The author also adopts a new OSR The evaluation index , namely Youden Index , It combines the true negative rate with the recall rate , In the fourth 5.2 Section details . lately , In order to solve the task of sliding window visual object detection and open set recognition ,Cevikalp and Triggs Used [98] Quasilinearity of " Polyhedral cone " Function series to define positive KKC The receiving area of . This choice provides a convenient series of compact and convex area shapes , Used to distinguish relatively good local positive KKC And the wider negative KKC, Including negative KKC and UUC.
Sparse Representation-Based. In recent years , The technology based on sparse representation has been widely used in the field of computer vision and image processing . especially , The classifier based on sparse representation has received a lot of attention , It identifies the correct category by seeking the most sparse representation of the test sample in terms of training .SRC And its variants are basically under the assumption of closed sets , So in order to make SRC Adapt to the open environment ,Zhang and Patel An open set recognition model based on sparse representation is proposed , Briefly called SROSR.
SROSR Use EVT The tail of the matching and non matching reconstruction error distribution is modeled , This is because OSR Most of the discriminant information is hidden in the tail of the two error distributions . This model consists of two main stages . A phase through the use of EVT The tail of the error distribution is modeled , take OSR The problem is simplified to a hypothesis test problem , The other stage is to calculate the reconstruction error of the test sample , Then the identity is determined according to the fusion confidence scores of the two tail parts .
just as [67] As reported in , Even though SROSR Is better than many competitive OSR Algorithm , But it also contains some limitations . for example , In the face recognition task ,SROSR Will include poses in the dataset 、 Failure in case of extreme changes in illumination or resolution , under these circumstances ,SRC The required self-expression characteristic no longer holds . Besides , In order to obtain good recognition performance , The training set needs to be broad enough , To cross the test set's possible conditions . Please note that , Although at present only SROSR It is based on sparse representation , But the development based on sparse representation OSR Algorithms are still an interesting topic for future work .
Distance-Based And other traditions mentioned above ML The method is similar to , Distance based classifiers are usually no longer effective in the case of open sets . To meet this challenge ,Bendale and Boult By the mean of the nearest class (NCM) Based on the classifier , This paper establishes a nearest non - error method for open set recognition (NNO) Algorithm .NNO According to the test sample and KKC The distance between the average values of , When all classifiers reject an input sample , It rejects the sample . It's important to note that , This algorithm can dynamically add new categories according to the manually labeled data . Besides , The author also introduces the concept of open world recognition , See section 4 .
Besides , Based on the traditional nearest neighbor classifier ,Ju´nior Et al. Introduced an open set version of the nearest neighbor classifier (OSNN) To deal with it OSR problem . It is different from those that directly use the threshold of the similarity score of the most similar class ,OSNN A threshold is applied to the ratio of the similarity scores of the two most similar classes , This is called the nearest neighbor distance ratio (NNDR) technology . say concretely , It first finds the test sample s My nearest neighbor t and u, among t and u From different classes , Then calculate the ratio : Ratio = d ( s , t ) / d ( s , u ) \text{Ratio} = d(s,t)/d(s,u) Ratio=d(s,t)/d(s,u) among d ( x , x ′ ) d(x,x′) d(x,x′) Presentation sample x and x′ Euclidean distance in feature space . If the ratio is less than or equal to the preset threshold ,s Will be classified as related to t The same label , Otherwise it's considered to be UUC.
OSNN It is essentially multi class , This means that its efficiency will not be affected as the number of classes available for training increases . Besides ,NNDR The technique can also be easily applied to other classifiers based on similarity scores , for example , Optimal path forest (OPF) classifier . Other indicators can also be used to replace the Euclidean indicators , Even the feature space under consideration can be a transformed space , As the author suggests . It should be noted that ,OSNN One limitation of is , Only two reference samples from different categories are selected for comparison , bring OSNN Vulnerable to outliers .
Margin Distribution-Based Considering most of the existing OSR The method hardly takes into account the distribution information of the data , And lack of a strong theoretical basis ,Rudd Et al. Proposed a theoretically reasonable classifier – Extremum machine (EVM), It comes from the concept of marginal distribution . Various definitions and uses of marginal distribution have been explored , The technologies involved are : Maximize the average or median margin , Adopt weighted combination margin , Or optimize the marginal mean and variance . Using the marginal distribution itself can provide a soft margin SVM Better error margin provided , In some cases, this can be translated into reducing the experimental error .
As an extension of the marginal distribution theory , From the representation of each category to the representation of samples ,EVM The model is based on the sample half distance distribution relative to the reference point . say concretely , It obtains the following theorem .
T h e o r e m 1 Theorem 1 Theorem1 Suppose we get a positive sample x i x_i xi And enough negative samples x j x_j xj, These samples come from well-defined class distributions , A pair of marginal estimates are generated m i j m_{ij} mij. Suppose there is a continuous non regressive marginal distribution . that x i x_i xi The distribution of the minimum value of the marginal distance is determined by Weibull The distribution gives .
Because of the theorem 1 For any point x i x_i xi All set up , Each point can estimate its distance distribution from the edge , Thus it is concluded that :
C o r o l l a r y 1 ( Ψ D e n s i t y F u n c t i o n ) Corollary 1 (\Psi Density Function) Corollary1(ΨDensityFunction) In view of the theorem 1 Conditions , x ′ x′ x′ Be included in x i x_i xi The estimated probability within the boundary is : Ψ ( x i , x ′ , κ i , λ i ) = exp − ( ∥ x i − x ′ ∥ λ i ) κ i \Psi (x_i,x^{\prime },\kappa _i,\lambda _i) = \exp ^{-\left(\frac{\Vert x_i-x^{\prime }\Vert }{\lambda _i}\right)^{\kappa _i}} Ψ(xi,x′,κi,λi)=exp−(λi∥xi−x′∥)κi among ∥ x i − x ′ ∥ \left\|x_{i}-x^{\prime}\right\| ∥xi−x′∥ yes x ′ x′ x′ With samples x i x_i xi Distance of , κ i , λ i \kappa_{i}, \lambda_{i} κi,λi Respectively for the smallest m i j m_{ij} mij By fitting Weibull Shape and scale parameters .
P r e d i c t i o n Prediction Prediction once EVM Be trained , New samples x ′ x′ x′ And C l C_l Cl Class dependent probability , namely P ( C l ∣ x ′ ) P^(Cl|x′) P(Cl∣x′), You can use the formula (9) obtain , The following decision function is obtained : y ∗ = { arg max l ∈ { 1 , … , M } P ^ ( C l ∣ x ′ ) if P ^ ( C l ∣ x ′ ) ≥ δ "unknown" Otherwise y^{*}= \begin{cases}\operatorname{arg~max}_{l \in\{1, \ldots, M\}} \hat{P}\left(\mathcal{C}_{l} \mid x^{\prime}\right) & \text { if } \hat{P}\left(\mathcal{C}_{l} \mid x^{\prime}\right) \geq \delta \\ \text { "unknown" } & \text { Otherwise }\end{cases} y∗={ arg maxl∈{ 1,…,M}P^(Cl∣x′) "unknown" if P^(Cl∣x′)≥δ Otherwise among , M M M Indicates... In training KKC Number , d e l t a delta delta Represents the probability threshold , It defines the KKC And unsupported open spaces .
EVM From marginal distribution and extreme value theory , There's a good explanation , It can perform nonlinear kernel free variable bandwidth incremental learning , And further use it to explore open set face recognition and intrusion detection . It should be noted that , It also has some limitations , Such as [71] Reported in , One obvious limitation is , When KKC and UUC When the geometry of , Use KKC The geometry of is risky . To address these limitations ,Vignotto and Engelke Further put forward to rely on EVT The approximate value of GPD and GEV classifier .
O t h e r T r a d i t i o n a l M L M e t h o d s − B a s e d Other Traditional ML Methods-Based OtherTraditionalMLMethods−BasedFei and Liu Take advantage of center based similarity (CBS) Space learning , by OSR This paper proposes a new solution for text classification in scene , and Vareto By combining hash functions 、 Partial least squares and fully connected networks , Open set face recognition is explored and HPLS and HFCN Algorithm .Neira Et al. Adopted a comprehensive idea , Combine different classifiers and features , solve OSR problem . We ask readers to refer to [72]、[73]、[74] For more details . At present, most traditional machine learning classification methods are based on the hypothesis of closed set , therefore , It is attractive to adapt them to open and non-stationary environments .
Deep Neural Network-Based OSR Models
Because of the strong learning expression ability , Deep neural network (DNN) In visual recognition 、 natural language processing 、 Text classification and other tasks have gained great benefits .DNN Usually follow the typical SoftMax Cross entropy classification loss , This inevitably leads to normalization problems , Make it have the property of closed set . therefore ,DNN Processing UUC The sample of , Often make wrong predictions , Even overconfidence .[112], [113] The work in shows that ,DNN It's easy to get " to fool " and " The garbage " The influence of image , These images are visually far from the desired category , But it produces a high confidence score . To solve these problems , Researchers have studied different approaches .
Bendale and Boult use OpenMax Layers replace DNN Medium SoftMax layer , Put forward OpenMax Model as the first solution to realize open set deep network . say concretely , First use the normal SoftMax Layer trains a deep neural network , Minimize cross entropy loss . Using the concept of the nearest class mean , Each class is then represented as an average activation vector , The average value of the activation vector ( Only for correctly classified training samples ) At the penultimate layer of the network . Next , Calculate training samples and corresponding categories MAV Distance of , It is also used to fit the independence of each category Weibull Distribution . Besides , The value of the activation vector depends on Weibull The fitting score of the distribution is redistributed , Then used to calculate UUC Pseudo activation value of . Last , By using these new redistributed activation vectors again SoftMax Calculation KKC and ( false )UUC Class probability of .
As in [75] As discussed in ,OpenMax It effectively solves the problem of fooling / The challenge of identifying garbage and uncorrelated open set images , But it does not recognize adversarial images , These images are visually indistinguishable from the training samples , But it is designed to make the deep network produce high confidence but incorrect answers .Rozsa Et al. Also analyzed and compared the use of SoftMax Layer of DNN And OpenMax The antagonism and robustness of : Even though OpenMax The system provided is better than SoftMax Less vulnerable to traditional attacks , But it is also susceptible to more complex adversary generation techniques that directly act on depth characterization . therefore , Adversarial samples are still a serious challenge in open set recognition . Besides , Use with MAV Distance of ,OpenMax The cross entropy loss function in is not directly excited in MAV Surrounding projection class samples . besides , The distance function used in the test is not used in the training , It may lead to inaccurate measurement of the space . To address this limitation ,Hassen and Chan Learning an open set recognition representation based on neural network . In this representation , Samples from the same category are closed to each other , Samples from different categories are far apart , This leads to UUC The sample is in KKC Takes up a large space .
Besides ,Prakhya And so on OpenMax Technical route of , Explore open set text categorization , and Shu For others 1 Than 1 The last floor of sigmoids To replace the SoftMax layer , A deep open classifier is proposed (DOC) Model .Kardan and Stanley A competitive ultra complete output layer is proposed (COOL) neural network , To avoid the over generalization of neural network in the region far away from the training data . Based on the carefully designed similar distance calculation provided by weightless neural network ,Cardoso Et al. Proposed a method for open set recognition tWiSARD Algorithm , The algorithm [82] Further development in . lately , Consider the available background classes (KUC),Dhamija People will SoftMax And novel Entropic Open-Set and Objectosphere Combined with loss , solve OSR problem .Yoshihashi Et al. Proposed classification for open set recognition - Rebuild learning algorithm (CROSR), The algorithm uses potential representation for reconstruction , And without harming KKCs Achieve robust classification accuracy UUCs testing .Oza and Patel A condition like automatic encoder with novel training and testing methods is used , Proposed for OSR Of C2AE Model . Compared with the above work ,Shu Et al. Pay more attention to finding hidden in rejected samples UUCs. Accordingly , They proposed a joint open classification model , A sub model is used to classify whether a pair of instances belong to the same category , The sub model can be used as the distance function of clustering to find hidden categories in rejected samples .
Remark
From the perspective of discriminant model , Almost all existing OSR All the methods adopt the classification scheme based on threshold , The recognizer either refuses to input samples when making decisions , Or use the threshold set by experience to classify the input samples into a certain KKC. therefore , The threshold plays a key role . However , at present , The choice of it usually depends on what comes from KKC Knowledge , Due to lack of resources from UUC Available information , This inevitably creates risks . in fact , because KUCs Data is often readily available , We can make full use of them to reduce this risk , And further improve these methods on UUCs The soundness of . Besides , Effectively model the tail of data distribution , bring EVT In the existing OSR Methods are widely used . However , unfortunately , It does not provide a principled method for selecting the fitting tail size . Besides , Because the frequency of objects in the visual category usually follows the long tail distribution , once KKC and UUC The rare classes in the test appear at the same time , This distribution fitting will face challenges .
B. Generative Model for Open Set Recognition
In this section , We will review from the perspective of generating models OSR Method , These methods can be further divided into instance based methods and non instance based methods according to their modeling forms .
Instance Generation-Based OSR Models
Antagonistic learning (AL) As a new technology, it has achieved amazing success , It uses a generative model and a discriminant model , The generated model learning generation can fool the samples of the discriminant model as non generated samples . because AL Characteristics of , Some researchers also try to use AL Technology generated UUC To illustrate the open space .
Ge Et al. Use conditions to generate countermeasure networks (GAN) To synthesize UUC A mixture of , Generation is proposed OpenMax(G-OpenMax) Algorithm , This algorithm can be used to generate UUC Provide clear probability estimates , Enable the classifier to be based on KKC And generated UUC Knowledge to locate the decision margin . obviously , In their settings , such UUC Limited to the original KKC In a subspace of space . Besides , Just like the literature [86] Reported , Even though G-OpenMax In the monochromatic digital data set, the UUCs, But it has no obvious performance improvement in natural images .
And G-OpenMax Different ,Neal Et al. Introduced a new data set enhancement technique , It is called counterfactual image generation (OSRCI).OSRCI Using encoders - decoder GAN framework , Generation is close to KKC But it doesn't belong to any KKC Composite open set instance of . They will go further OSR The problem is reformulated as a classification with an additional category containing these newly generated samples . And [87] Similar in spirit ,Jo And so on GAN Technology generates fake data as UUC The data of , To further improve UUC The robustness of the classifier .Yu Et al OSR Adversarial sample generation for (ASG) frame .ASG It can be applied to all kinds of learning models except neural networks , At the same time, it can not only generate UUC data , And if necessary, it can generate KKCs data . Besides ,Yang They borrowed the typical GAN A generator in the network generates synthetic samples that are highly similar to the target samples as automatic negative sets , At the same time, the discriminator is redesigned , So as to meet with UUC Output multiple categories together . Then they explored open set human activity recognition based on micro Doppler signals .
Remark Because most instance - based OSR Methods often rely on deep neural networks , They also seem to be based on DNN Methods . But notice , The essential difference between these two methods is UUC Whether the sample of is generated in learning . Besides ,AL Technology does not just rely on deep Neural Networks , Such as ASG.
Non-Instance Generation-Based OSR Models
Dirichlet The process (DP) Be regarded as a distribution on a distribution , It's a random process , As a nonparametric a priori defined in the number of components of the mixture , It is widely used in clustering and density estimation . This model does not rely too much on training samples , And can realize adaptive change with the change of data , Make it fit naturally OSR The situation of .
Geng and Chen To hierarchy Dirichlet The process (HDP) Minor modifications , take HDP rearrange OSR, And put forward a new method based on collective decision OSR Model (CD-OSR), It can solve the problems of batch and single sample .CD-OSR First, a common clustering process is performed in the training phase , To get the appropriate parameters . In the test phase , It uses a Gaussian mixture model (GMM) Each one KKC The data is modeled as a set of CD-OSR, Its ingredients / The number of subclasses is unknown , And the entire test set as a collective / batch , Handle in the same way . And then in HDP All groups are copolymerized under the framework . After copolymerization , You can get one or more subclasses representing the corresponding category . therefore , For a test sample , It will be marked as appropriate KKC or UUC, It depends on whether the subclass it is assigned corresponds to KKC of .
It is worth noting that , And previous OSR The method is different ,CD-OSR There is no need to define a threshold to determine KKC and UUC Decision boundaries between . contrary , It introduces some thresholds to control the number of subclasses in the corresponding class , Moreover, the selection of this threshold has shown greater versatility in experiments ( For details, see [91]). Besides ,CD-OSR It can be used for UUC Provide explicit modeling , Naturally, a new class discovery function will be generated . Please note that , This new discovery is only at the subclass level . Besides , Adopt collective / Batch decision strategy makes CD-OSR Correlations between test samples that are obviously ignored by other existing methods are considered . Besides , Just like the literature [91] As reported ,CD-OSR At present, it is only a conceptual proof of open set recognition , There are still many limitations in collective decision-making . for example ,CD-OSR To some extent, the recognition process seems to have the flavor of lazy learning , When the test data of other batches come , The common clustering process will be repeated , Resulting in higher computational overhead .
Remark Generated based on instances OSR The key to the model is to generate effective UUC sample . Although these existing methods have achieved some results , But generate more effective UUC The sample still needs further study . Besides , The data adaptive characteristic makes ( layered )Dirichlet The process is naturally suitable for handling OSR Mission . Because there are only [91] Use HDP Made a preliminary exploration , Therefore, this research idea is also worthy of further discussion . Besides ,OSR The collective decision-making strategy is also a promising direction , Because it not only considers the correlation between test samples , It also provides the possibility of discovering new categories , Other existing OSR The single sample decision-making strategy used in this method can not do such work , Because it cannot directly tell whether the rejected individual sample is an outlier or from a new category .
IV. Beyond Open Set Recognition
Please note that , The existing open set recognition is really in the open case , But not incremental , And it cannot be extended gracefully with the number of classes . On the other hand , Although in class incremental learning (C-IL) Assume that the new class (UUC) Is incremental , These studies mainly focus on how to make the system can be incorporated into the training samples of later new classes , Instead of dealing with identification UUC The problem of . For mutual consideration OSR and CIL Mission ,Bendale and Boult Identify existing open sets ( Definition 2) Expand to open world recognition (OWR), One of the identification systems should perform four tasks : testing UUC, Select which samples to tag to add to the model , Mark these samples , And update the classifier . say concretely , The author gives the following definitions :
Definition 3( Open world recognition ) Give Way K T ∈ N + \mathcal{K}_{T} \in \mathbb{N}^{+} KT∈N+ Is time T T T Of KKC Tag set , Let zero label (0) by ( temporary ) Mark data as unknown and keep . therefore , N \mathbb{N} N Include KKC and UUC The label of . Based on definition 2, The solution of open world recognition is a tuple [ F , φ , ν , L , I ] [F, \varphi, \nu, \mathcal{L}, I] [F,φ,ν,L,I], These include :
1. A multi class open set recognition function F ( x ) : R d ↦ N F(x): \mathbb{R}^{d} \mapsto \mathbb{N} F(x):Rd↦N Use i i i A measurable identification function for each class f i ( x ) f_i(x) fi(x) Vector function of φ ( x ) \varphi(x) φ(x), Also use a novelty detector ν ( φ ) : R i ↦ [ 0 , 1 ] \nu(\varphi): \mathbb{R}_{i} \mapsto[0,1] ν(φ):Ri↦[0,1]. We demand i ∈ K T i \in \mathcal{K}_{T} i∈KT For each class of recognition functions f i ( x ) ∈ H : R d ↦ R f_{i}(x) \in \mathcal{H}: \mathbb{R}^{d} \mapsto \mathbb{R} fi(x)∈H:Rd↦R Is an open set function for managing open space risk , As formula (1). Novelty detector ν ( φ ) : R i ↦ [ 0 , 1 ] \nu(\varphi): \mathbb{R}^{i} \mapsto[0,1] ν(φ):Ri↦[0,1] Determine whether the result of identifying the function vector comes from UUC.
2. A marking process L ( x ) : R d ↦ N + \mathcal{L}(x): \mathbb{R}^{d} \mapsto \mathbb{N}^{+} L(x):Rd↦N+ Apply to time T New unknown data U T U_T UT, Generate tag data D T = { ( y j , x j ) } D_{T}=\left\{\left(y_{j}, x_{j}\right)\right\} DT={ (yj,xj)}, among y j = L ( x j ) , ∨ x j ∈ U T y_{j}=\mathcal{L}\left(x_{j}\right), \vee x_{j} \in U_{T} yj=L(xj),∨xj∈UT. Suppose the annotation finds m A new class , that KKC The set of becomes K T + 1 = K T ∪ { i + 1 , … , i + m } \mathcal{K}_{T+1}=\mathcal{K}_{T} \cup\{i+1, \ldots, i+m\} KT+1=KT∪{ i+1,…,i+m}.
3. An incremental learning function I T ( φ ; D T ) : H i ↦ H i + m I_{T}\left(\varphi ; D_{T}\right): \mathcal{H}^{i} \mapsto \mathcal{H}^{i+m} IT(φ;DT):Hi↦Hi+m To extensibly learn and add new measurable functions f i + 1 ( x ) … f i + m ( x ) f_{i+1}(x) \ldots f_{i+m}(x) fi+1(x)…fi+m(x), Each function manages open space risk , Vector to measurable recognition function φ \varphi φ.
About more details , We ask readers to refer to [68]. Ideally , All these steps should be automated . However ,[68] At present, only supervised learning of tags obtained from human tags has been speculated , And put forward NNO Algorithm , This algorithm has been used in 3.1.1 This section discusses .
Remark As OSR The natural extension of ,OWR Facing more severe challenges , This requires that it not only have to deal with OSR The ability of the task , And minimum downtime , Even keep learning , This seems to have the flavor of lifelong learning to some extent . Besides , Although about OWR Some progress has been made , But there is still a long way to go .
V. Datasets, Evaluation Criteria, and Experiments
A. Datasets
In open set recognition , At present, most of the existing experiments are usually carried out on various recast multi class benchmark data sets , In the corresponding data set , Some different tags are randomly selected as KKC, The rest are UUC. Here we list some common benchmark datasets and their combinations .
L E T T E R LETTER LETTER From 26 Total of classes 20,000 Samples , Each of these classes has about 769 Samples , Yes 16 Features . In order to reuse it for open set recognition , Randomly selected 10 There are different classes for training KKC, And the rest as UUC.
P E N D I G I T S PENDIGITS PENDIGITS All come from 10 Category 10,992 Samples , Each of these classes has about 1,099 Samples , Yes 16 Features . similarly ,5 Three different classes were randomly selected as KKC, The rest of the for UUC.
C O I L 20 COIL20 COIL20 All come from 20 Of an object 1,440 A gray image ( Every object 72 picture ). Each image is down sampled as 16×16, That is, the feature dimension is 256. according to [91], We use principal component analysis (PCA) Technology further reduces the dimension to 55, Retain the 95% Sample information for . Random selection 10 Different objects as KKC, And the rest of it UUC.
Y A L E B YALEB YALEB The expanded Yale University B(YALEB) Data sets are all from 38 Individual 2,414 Front image . Everyone has about 64 Zhang image . These images are cropped and normalized to 32×32. according to [91], We also use PCA Reduce its feature dimension to 69. And COIL20 similar , We chose... At random 10 There are different classes as KKCs, And the rest as UUCs.
M N I S T MNIST MNIST from 10 Number classes , Each class contains 6,313 To 7,877 A monochrome image , The characteristic dimension is 28×28. according to [87], Random selection 6 There are different classes as KKC, And the rest 4 Class as UUC.
S V H N SVHN SVHN Yes 10 Number classes , Each class contains 9,981 To 11,379 A color image , The characteristic dimension is 32×32. according to [87], Random selection 6 There are different classes as KKC, And the rest 4 Class as UUC.
C I F A R 10 CIFAR10 CIFAR10 share 6,000 The picture comes from 10 Color images of natural image categories . Each image has 32×32 The characteristic dimension of . According to the literature [87], Random selection 6 There are different classes as KKC, And the rest 4 Class as UUC. To extend this data set to greater openness ,[87] Further put forward CIFAR+10、CIFAR+50 Data sets , take CIFAR10 Medium 4 Non animal species as KKC, And from CIFAR1005 Select separately from 10 and 50 Animals as UUC.
T i n y − I m a g e n e t Tiny-Imagenet Tiny−Imagenet share 200 Classes , Each class has 500 Images for training ,50 Zhang for testing , These images come from Imagenet ILSVRC 2012 Data sets [144], And sample down to 32×32. according to [87], Random selection 20 There are different classes as KKC, And the rest 180 Class as UUC.
B. Evaluation Criteria
In this section , We summarize some commonly used evaluation indexes of open set recognition . For evaluation OSR Classifier in case , A key factor is to UUC The identification of . Give Way T P i TP_i TPi、 T N i TN_i TNi、 F P i FP_i FPi and F N i FN_i FNi Separate indication control i i i individual KKC The real 、 True negative 、 False positive and false negative , among i ∈ { 1 , 2 , . . . , C } i\in\{1,2,...,C\} i∈{ 1,2,...,C}, C C C Express KKC The number of . Besides , Give Way T U TU TU and F U FU FU respectively UUC Right and wrong reject . Then we can get the following evaluation indicators .
Accuracy for OSR As a common choice to evaluate classifiers under closed set Hypothesis , Accuracy A \mathcal {A} A It is usually defined as : A = ∑ i = 1 C ( T P i + T N i ) ∑ i = 1 C ( T P i + T N i + F P i + F N i ) \mathcal {A} = \frac{\sum _{i=1}^C(TP_i + TN_i)}{\sum _{i=1}^C(TP_i + TN_i + FP_i + FN_i)} A=∑i=1C(TPi+TNi+FPi+FNi)∑i=1C(TPi+TNi) Yes OSR scene A O \mathcal {A} _{O} AO A trivial extension of the accuracy of is , The correct response should include a response to KKC The correct classification of UUC Correct rejection of : A O = ∑ i = 1 C ( T P i + T N i ) + T U ∑ i = 1 C ( T P i + T N i + F P i + F N i ) + ( T U + F U ) \mathcal {A}_{\text{O}} = \frac{\sum _{i=1}^C(TP_i + TN_i) + TU}{\sum _{i=1}^C(TP_i + TN_i + FP_i + FN_i) + (TU + FU)} AO=∑i=1C(TPi+TNi+FPi+FNi)+(TU+FU)∑i=1C(TPi+TNi)+TU However , because A O \mathcal {A} _{O} AO It means KKC The correct classification and UUC The sum of correct refusals , It cannot objectively evaluate OSR Model . Consider the following : When rejection performance is dominant , The test set contains a large number of UUC sample , And only a few KKC sample , A O \mathcal {A} _{O} AO It can still reach a high value , Despite the fact that the recognizer is right KKC The classification performance of is really low , vice versa . Besides ,[69] A new OSR Accuracy index , It is called normalized accuracy (NA), It will KKC The accuracy of (AKS_ and UUC The accuracy of (AUS) Weighted calculation : NA = λ r AKS + ( 1 − λ r ) AUS \text{NA}=\lambda _r\text{AKS} + (1-\lambda _r)\text{AUS} NA=λrAKS+(1−λr)AUS among AKS = ∑ i = 1 C ( T P i + T N i ) ∑ i = 1 C ( T P i + T N i + F P i + F N i ) , AUS = T U T U + F U \text{AKS} = \frac{\sum _{i=1}^C(TP_i + TN_i)}{\sum _{i=1}^C(TP_i + TN_i + FP_i + FN_i)}, \ \text{AUS} = \frac{TU}{TU+FU} AKS=∑i=1C(TPi+TNi+FPi+FNi)∑i=1C(TPi+TNi), AUS=TU+FUTU λ r , 0 < λ r < 1 \lambda _r, 0<\lambda _r<1 λr,0<λr<1 It's a constant .
F-Measure for OSR Widely used in information retrieval and machine learning F value , Is defined as precision P And recall rate R Harmonic average of : F = 2 × P × R P + R F = 2 \times \frac{P\times R}{P + R} F=2×P+RP×R Please note that , When using F Value to evaluate OSR When classifiers , You shouldn't put all the things that appear in the test UUC As an additional simple class , And in the same way as in the case of multi class closed sets F. Because once you do this ,UUC The correct classification of the sample will be considered as the true positive classification . However , Such a true positive classification is meaningless , Because we didn't UUC To train the corresponding classifier . The modification is only for KKC Calculation of accuracy and recall rate ,[69] A relatively reasonable OSR Of F-measure. The following formula details these modifications , And the formula is (14) and (15) Respectively used to calculate macro F-measure And micro F-measure, By formula (13) Calculation : P m a = 1 C ∑ i = 1 C T P i T P i + F P i , R m a = 1 C ∑ i = 1 C T P i T P i + F N i P_{ma}=\frac{1}{C}\sum _{i=1}^C\frac{TP_i}{TP_i+FP_i}, R_{ma}=\frac{1}{C}\sum _{i=1}^C\frac{TP_i}{TP_i+FN_i} Pma=C1i=1∑CTPi+FPiTPi,Rma=C1i=1∑CTPi+FNiTPi P m i = ∑ i = 1 C T P i ∑ i = 1 C ( T P i + F P i ) , R m i = ∑ i = 1 C T P i ∑ i = 1 C ( T P i + F N i ) P_{mi}=\frac{\sum _{i=1}^CTP_i}{\sum _{i=1}^C(TP_i+FP_i)}, R_{mi}=\frac{\sum _{i=1}^CTP_i}{\sum _{i=1}^C(TP_i+FN_i)} Pmi=∑i=1C(TPi+FPi)∑i=1CTPi,Rmi=∑i=1C(TPi+FNi)∑i=1CTPi Please note that , Although in the formula (14) and (15) Medium precision and recall rate only consider KKC, but F N i FN_i FNi and F P i FP_i FPi Also considered false UUC And fake KKC, Take into account false negatives and false positives ( See [69]).
Youden’s Index for OSR because F It's worth it TN The change of is invariable , and TN yes OSR An important factor in performance ,Scherreik and Rigling Turn to the Youden index J J J, The definition is as follows : J = R + S − 1 J = R + S - 1 J=R+S−1 among S = T N / ( T N + F P ) S=TN/(TN+FP) S=TN/(TN+FP) Represents the true negative rate . The Youden exponent can express the ability of an algorithm to avoid failure , It's in [ − 1 , 1 ] [-1,1] [−1,1] Is bounded , A higher value indicates that an algorithm is more resistant to failure . Besides , When J = 0 J=0 J=0 when , The classifier is uninformative , And when J < 0 J<0 J<0 when , It tends to provide more error information than correct information .
Besides , In order to overcome the influence on model parameters and threshold sensitivity ,[87] Adopted ROC The area under the curve (AUROC) And the accuracy of the closed set , This indicator will OSR The task is regarded as a combination of novelty detection and multi class recognition . It should be noted that , although AUROC It has a good effect on the evaluation model , But for the OSR problem , We finally need to make a decision ( Which one sample belongs to KKC or UUC), So this threshold seems to have to be determined .
Remark at present ,F-measure and AUROC Is the most commonly used evaluation index . because OSR The problem is faced with new circumstances , The new evaluation method is worthy of further exploration .
C. Experiments
This subsection is in section 5.1 The popular benchmark datasets mentioned in the section quantitatively evaluate some representative OSR Method . Besides , These methods are compared in the classification of non depth and depth features .
OSR Methods Using Non-Depth Feature Using non depth features OSR The method is usually in LETTER、PENDIGITS、COIL20、YALEB Evaluate on dataset . Most of them adopt threshold based strategies , It is recommended to set the threshold according to the openness of the specific problem . However , We usually OSR In the scene UUC Without knowing in advance . therefore , Such a setting seems unreasonable , This paper recalibrates this , That is, only according to the KKC To determine the decision threshold , Once identified during training , Its value will not change during the test . In order to effectively determine the threshold and parameters of the corresponding model , We refer to [69]、[91] Introduce an evaluation protocol , As follows .
E v a l u a t i o n P r o t o c o l Evaluation Protocol EvaluationProtocol Pictured 4 Shown , Data sets are first divided into owning KKC Training set and contains KKC and UUC Test set of . In the training set 2/3 Of KKC Be selected as "KKC" simulation , And the rest is "UUC" simulation . therefore , The training set is divided into one that contains only "KKC" The fitting set of F And one that includes " Closed sets “ Simulation and " Open set " Simulated validation set V. Closed sets " Simulation only has KKCs, and " Open set " The simulation contains "KKCs" and "UUCs”. Please note that , In the training phase , All the methods are using F Training , And in V On the assessment . say concretely , For each experiment , We :
- 1. Select randomly from the corresponding data set Ω \Omega Ω Different classes as KKC Training .
- 2. Select each at random KKC in 60% As a training set .
- 3. Select steps 2 In the rest of the 40% And other categories of samples ( barring Ω \Omega ΩKKC) As test set .
- 4. Random selection [ ( 2 / 3 Ω + 0.5 ) ] [(2/3\Omega+0.5)] [(2/3Ω+0.5)] Class as a training set "KKC" Fit , The rest of the classes act as "UUC" To verify .
- 5. From each "KKC" Choose... At random 60% As a fitting set F.
- 6. Select steps 5 In the rest of the 40% As a sample of " Closed sets " simulation , And steps 5 In the rest of the 40% Samples and "UUCs" The sample in is taken as " Open set " simulation .
- 7. use F Training model and in V Verify them on , Then find the appropriate model parameters and thresholds .
- 8. Use micro-F-measure assessment 5 A random class partition model .
Please note that , The experimental scheme here is just an evaluation OSR A relatively reasonable form of the method . in fact , Other protocols can also be used to evaluate , And some may be more appropriate , Therefore, it is worth further discussion . Besides , Different papers often adopt different evaluation schemes before , Here we try our best to follow the principle of parameter adjustment in their paper . Besides , To encourage repeatable research , We invite readers to our github Understand the details of datasets and their corresponding class partitions .
In different degrees of openness O ∗ O* O∗ Next , surface 4 A comparison between these methods is reported , among 1-vs-Set、W-SVM(W-OSVM)、PI-SVM、SROSR、OSNN、EVM From tradition based ML Category ,CD-OSR From non instance based generation categories .
Our first observation is , With the improvement of openness , Although the threshold based approach ( Such as W-SVM、PI-SVM、SROSR、EVM) Performs well on some datasets , However, there is also a significant performance degradation on other data sets ( for example ,W-SVM stay LETTER Good performance on , And in the PENDIGITS The performance is obviously insufficient ). This is mainly because their decision thresholds are only based on KKC Knowledge to choose , once UUC Of the samples fell into some KKC Partition space of , It will produce OSR risk . by comparison , because HDP Data adaptation characteristics of ,CD-OSR Can effectively test the UUC Modeling , So it has achieved better performance on most data sets , Especially for LETTER and PENDIGITS.
Our second observation is . Compared with other methods ,OSNN Its performance fluctuates greatly in terms of standard deviation , Especially for LETTER, This may be because NNDR The strategy makes its performance depend heavily on the distribution characteristics of the corresponding data sets . Besides , because 1-vs-Set The open space is still unbounded , We can see that its performance drops sharply with the increase of openness . As a benchmark for a single class classifier ,W-OSVM Works well in the case of closed sets . However , Once the scene moves to the open set , Its performance will also be greatly reduced .
summary . in general , be based on HDP Data adaptation characteristics of ,CD-OSR At present, compared with other methods, the performance is relatively good . However ,CD-OSR Also received HDP Its own limitations , For example, it is difficult to apply to high-dimensional data , High computational complexity . As for other methods , They are also limited by the underlying model they use . for example , because SRC stay LETTER The effect is not good , therefore SROSR The performance achieved on this dataset is poor . Besides , Just like No 3.1 As mentioned in Section , For the use of EVT Methods , Such as W-SVM、PI-SVM、SROSR、EVM, once KKC and UUC The rare classes in the test appear at the same time , They may face challenges . Besides , It is also necessary to point out that , This part only gives the comparison of these algorithms on all commonly used data sets , To some extent, their behavior may not be fully described .
OSR Methods Using Depth Feature Using depth features OSR The method is usually in MNIST、SVHN、CIFAR10、CIFAR+10、CIFAR+50、Tiny-Imagenet On the assessment . Because most of them follow [87] Evaluation protocol defined in , And no source code is provided , And [3]、[148] similar , We only compare the results with those published by them . surface 5 The comparison between these methods is summarized , among SoftMax、OpenMax、CROSR and C2AE It belongs to the category based on deep neural network , and G-OpenMax and OSRCI It belongs to the category of instance based generation .
Our first observation is . First , All the ways in MNIST The performance is quite , This is mainly because MNIST The result on is almost saturated . second , And SoftMax、OpenMax、G-OpenMax and OSRCI Compared with earlier methods ,CROSR and C2AE At present, it has achieved better performance on the benchmark data set . The main reason for their success may be : about CROSR Come on , Training network for joint classification and reconstruction KKC, Make sth KKC The representation of learning is more discriminative and compact ( bring KKC Get a tighter distribution ); about C2AE Come on , take OSR It is divided into closed set classification and open set recognition , So that it can be avoided by SoftMax The score is modified under a single score , Perform these two subtasks simultaneously ( Finding such a single score measure is often challenging ).
Our second observation is . As the most advanced instance based OSR Method ,OSRCI At present, it has not won on almost all of the above data sets CROSR and C2AE( Two of the most advanced neural networks based on depth OSR Method ), This seems counterintuitive , because OSRCI from UUC Got additional information . But this just shows ( On the other hand ), There is still much room for improvement in the performance of instance based methods , It is worth exploring further , It also shows CROSR and C2AE The effectiveness of the strategy in .
Remark As mentioned earlier , Due to the use EVT,OpenMax、CROSR、C2AE and G-OpenMax Together in the test KKC and UUC It may also face challenges when it comes to rare classes in . Besides , It is also worth mentioning that , The method based on instance generation is orthogonal to the other three methods , in other words , It can be combined with these methods , To achieve the best effect .
VI. Future Research Directions
In this section , We briefly analyze and discuss the existing OSR Limitations of the model , At the same time, some promising research directions in this field are also pointed out , And the following aspects are described in detail .
A. About Modeling
First , Pictured 3 Shown , Although almost all existing OSR Methods are modeled from the perspective of discriminative or generative models , But a natural problem is : Whether it can be constructed from the perspective of hybrid generative discriminant model OSR Model ? Please note that , As far as we know , At present, there is no such thing as OSR Work , This deserves further discussion . secondly ,OSR The main challenge is , The traditional classifier will sneak into the closed scene KKC Over occupied space , So once UUC The sample of falls into KKC Divided space , They will never be properly classified . Look at it this way , The following two modeling perspectives will be promising research directions .
Modeling Known Known Classes In order to alleviate the problem of excessive space occupation , We usually expect that with the help of clustering methods , Get better resolution for each target class , At the same time, it is limited to a compact space . In order to achieve this goal , Clustering and classification learning can be unified , To achieve the best of both worlds : Clustering learning can help target classes to obtain more compact distribution areas ( That is, limited space ), Classification learning provides them with better discrimination . in fact , There has been some work to integrate clustering and classification functions into a unified learning framework . Unfortunately , These works are still under the assumption of a closed set . therefore , It takes some serious effort to adapt them to OSR The situation of , Or for OSR Specially designed for this type of classifier .
Modeling Unknown Unknown Classes Under the open set assumption , establish UUC The model is impossible , Because we only come from KKC Available knowledge . However , It will be possible to relax some restrictions , One method is to generate through confrontational learning techniques UUC data , To some extent, it shows that open space , The key is how to generate effective UUC data . Besides , because Dirichlet Data self adaptability of the process , be based on Dirichlet Process of OSR Method , Such as CD-OSR, It is also worth exploring further .
B. About Rejecting
up to now , Most of the existing OSR The main concern of the algorithm is to effectively reject UUC, However, only a few works focus on the subsequent processing of rejected samples , These works usually use an after the fact strategy . therefore , It will be an interesting research topic to extend the existing open set recognition and new class knowledge discovery . Besides , As far as we know , The explicability of the rejection option seems to have not been discussed , One of the rejection options may correspond to a low confidence target class 、 An outlier or a new class , This is also an interesting future research direction . Some related work in other research fields can be found in [116]、[151]、[152]、[153]、[154] Find .
C. About the Decision
Just like No 3.2.2 As discussed in section , Almost all existing OSR The techniques are specifically designed to identify individual samples , Even if these samples come collectively , Such as image set recognition . in fact , This decision does not take into account the correlation between the test samples . therefore , Collective decision-making seems to be a better choice , Because it can not only consider the correlation between test samples , And you can find new classes at the same time . therefore , We hope that the future direction is to expand the existing by adopting such collective decisions OSR Method .
D. Open Set + Other Research Areas
Due to the classification of open set scenes for the real world / It is a practical assumption for identification tasks , It can naturally relate to classification / The various areas of identification are combined , Such as semi supervised learning 、 Field adaptation 、 Active learning 、 Multi task learning 、 Multi view learning 、 Multi label image classification problem and so on . for example ,[156]、[157]、[158] Introduce this scheme into domain adaptation , and [159] Then it is introduced into the semantic instance segmentation task . lately ,[160] The open set classification of active learning is discussed . It is worth mentioning that , Data sets NUS-Wide and MS COCO It has been used to study multiple tags Zero-Shot Study , They are also suitable for studying multiple tags OSR problem . therefore , Many interesting jobs are worth looking forward to .
E. Generalized Open Set Recognition
OSR Assume that there are only KKC Knowledge is available , This means that we can also use information about KKC Various profile information of . However , Most of the existing OSR The method just uses KKC Feature level information , And ignore their other side information , Such as semantics / Attribute information 、 Knowledge map 、KUC The data of ( Such as universum data ) etc. , This information is also important to further improve their performance . therefore , We give the following promising research directions .
Appending Semantic/Attribute Information Through to ZSL Exploration , We can find out , A lot of semantics / The attribute information is usually in KKC And unknown class data . therefore , This information can be used in OSR in " cognition "UUC, Or at least UUC The sample of provides a rough semantics / Property description , Instead of simply rejecting them . Please note that , This setting is similar to ZSL( or G-ZSL) The settings in are different , The latter assumes KKC and UUC The semantics of the / Attribute information is known in training . Besides , surface 1 The last line of shows the difference . Besides , Some related work can be done in [133]、[154]、[162]、[163] Find . There are also some similar topics in other research circles , Such as object retrieval with open vocabulary , Pedestrians in the open world re identify or search for targets , Scene analysis of open vocabulary .
Using Other Available Side-Information For the first 6.1 The problem of excessive occupancy of space mentioned in section , By using other side information such as KUC data ( Such as universum data ) To minimize its size , With these KKC The divided space is reduced , The risk of open space will also be reduced . Pictured 1 Shown , Take number recognition for example , Suppose the training set includes classes of interest ’1’、‘3’、‘4’、‘5’、‘9’; The test set includes all classes ’0’-‘9’. If we have any more universum data - English letter ’Z’、‘I’、‘J’、‘Q’、‘U’, We can make full use of them in modeling to extend the existing OSR Model , Further reduce the risk of open space . therefore , We can see , In the future, open set recognition will adopt more general settings .
F. Relative Open Set Recognition
Although open set scenarios are everywhere , But there are also some real-world scenarios that are not completely open in practice . Recognition in this scenario / Classification can be called relative open set recognition . Take medical diagnosis for example , The whole sample space can be divided into two subspaces: sick sample and healthy sample , On the level of detecting whether the sample is sick , It is indeed a closed set problem . However , When we need to further identify the type of disease , This will naturally become a complete OSR problem , Because new diseases not seen in training may appear in the test . at present , Few works explore this new hybrid scene together . Please note that , under these circumstances , The main goal is to limit the UUC The scope of the , At the same time KKCs Find the most specific category label of a new sample on the established taxonomy . Some related work can be done in [171] Find .
G. Knowledge Integration for Open Set Recognition
in fact , Incomplete knowledge of the world is universal , Especially for a single individual : Just because you know something doesn't mean I know . for example , Terrestrial species ( Sub knowledge set ) It is obviously an open set of classifiers trained for marine species . It is said that ,“ Two heads are not as good as one ”, therefore , How to integrate the classifiers trained on each sub knowledge set , To further reduce the risk of open space , It will be an interesting and challenging topic in the future work , Especially in such a case : We can only obtain the classifier trained on the corresponding sub knowledge set , But due to data privacy protection , These sub knowledge sets cannot be used . This seems to have, to some extent, multiple source domains and a target domain (mS1T) The field adapts to the taste .
VII. Conclusion
As mentioned above , Recognition in the real world / In the classification task , It is often not possible to model everything , therefore OSR The scene is everywhere . On the other hand , Although many related algorithms have been proposed for OSR, But it still faces serious challenges . As there is no systematic summary on this topic , In this paper, the existing OSR A comprehensive review of the technology , Covered from relevant definitions 、 The representation of the model 、 Data sets 、 Evaluation criteria and algorithm comparison . It should be noted that , For convenience , In this paper, the existing OSR The classification of technologies is only one possible way , And other methods can also effectively classify , Some may be more appropriate , But that's not the point here .
Besides , In order to avoid confusion and OSR Similar tasks , We also briefly analyzed OSR The relationship with its related tasks , Include Zero-Shot、One-Shot technology 、 Categories with reject options, etc . besides , As OSR The natural extension of , We also reviewed the identification of the open world . what's more , We analyze and discuss the limitations of these existing methods , Some promising future research directions in this field are pointed out .
边栏推荐
- [论文阅读] BoostMIS: Boosting Medical Image Semi-supervised Learning with Adaptive Pseudo Labeling
- Locks in sqlserver
- How to guarantee the quality of real-time data, the cornerstone of the 100 million level search system (Youku Video Search)? v2020
- OTA upgrade
- 一些有的没的闲话
- MySQL trigger
- Load balancing strategy graphic explanation
- Unity 容易被坑的点
- 嵌入式学习资料和项目汇总
- Optimization of startup under SYSTEMd, deleting useless SYSTEMd services
猜你喜欢
![[introduction to ROS] - 03 basic concepts and instructions of ROS](/img/d4/a9b49dddbe0be8b53acf71219d0959.png)
[introduction to ROS] - 03 basic concepts and instructions of ROS

招聘 | 南京 | TRIOSTUDIO 三厘社 – 室内设计师 / 施工图深化设计师 / 装置/产品设计师 / 实习生等
![[introduction to ROS] - 01 introduction to ROS](/img/6f/67ebb4336b6f7b3a1076b09d871b8e.png)
[introduction to ROS] - 01 introduction to ROS
Viewpager and dot of bottom wireless loop

logback日志框架

文件“Setup”不存在,怎么办?
【ROS入门教程】---- 02 ROS安装
AQS explanation of concurrent programming

Small project on log traffic monitoring and early warning | environment foundation 2
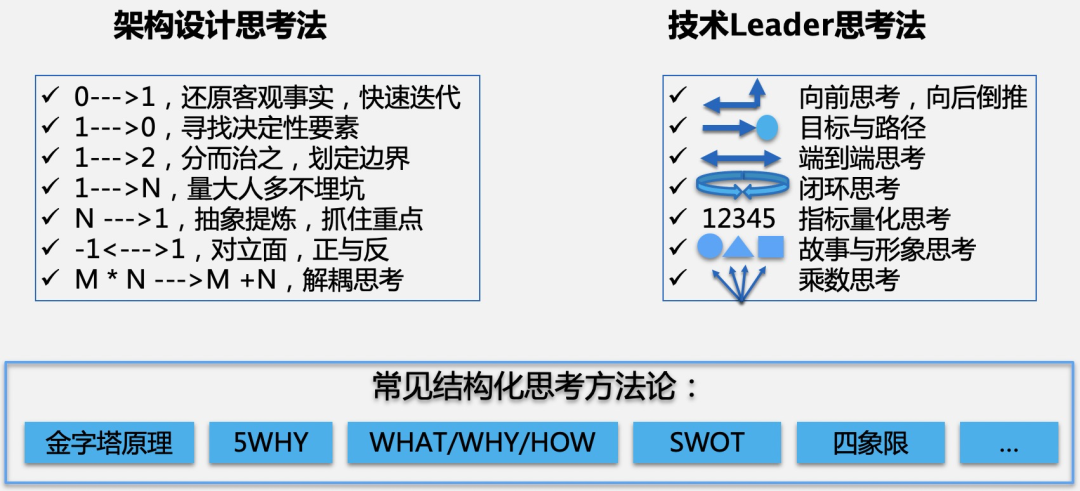
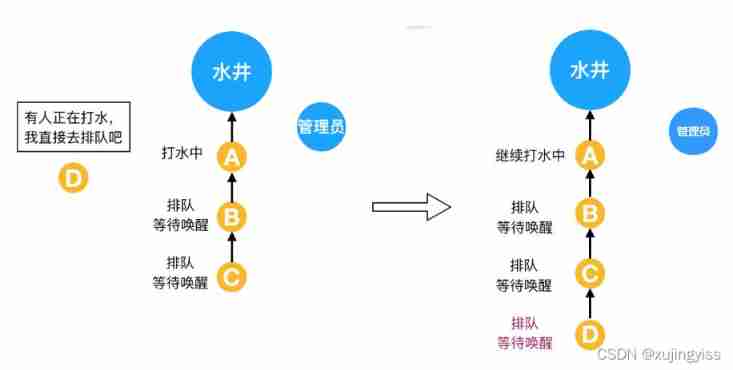
Team management | how to improve the thinking skills of technical leaders?

随机推荐
适配器模式
Idea setting background picture (simple)
adb循环输出内存信息到文件夹
[introduction to ROS] - 01 introduction to ROS
ion_dma_buf_begin_cpu_access
What is MYCAT? Get to know you quickly
循环结构语句
compiler explorer
About log traffic monitoring and early warning small project | flask
Kubernetes入门介绍与基础搭建
CentOS7 实战部署MySQL8(二进制方式)
如何保证消息的顺序性、消息不丢失、不被重复消费
How to ensure the sequence of messages, that messages are not lost or consumed repeatedly
Cosine similarity calculation summary
【ROS入门教程】---- 03 单片机、PC主机、ROS通信机制
day01
"Past and present" of permission management
【ROS入门教程】---- 02 ROS安装
Alicloud configures SLB (load balancing) instances
大厂是面对深度分页问题是如何解决的(通俗易懂)