Actor-Critic It is the combination of value learning and strategy learning .Actor It's a strategic network , Used to control agent motion , It can be regarded as an athlete .Critic It's a value network , Used to score actions , Like a referee .
4. Actor-Critic
4.1 Value network and strategy network construction
a. Principle introduction
State value function :
$ V_\pi(s)=\sum_{{a}}\pi({a}|{s})\cdot Q_\pi({s},{a})$ ( Discrete situation , If it is continuous, it needs to be replaced by definite integral )
V Is the action value function \(Q_\pi\) The expectations of the ,\(\pi({s}|{a})\) Policy function control agent take exercises ,\(Q_\pi({s},{a})\) The value function evaluates whether the action is good or bad . But we don't know these two functions , But we can use a neural network to approximate these two functions , And then use Actor-Critic Methods to learn these two networks at the same time .
Policy network (actor): With the Internet \(\pi({s}|{a};\theta)\) To approximate \(\pi({s}|{a})\),\(\theta\) It's network parameters
Value network (critic): With the Internet \(q({s},{a};w)\) To approximate \(Q_\pi({s},{a})\),\(w\) It's network parameters
actor Is a gymnast , You can do it yourself , and agent Want to do better , But I don't know how to improve , This requires the referee to score her , In this way, athletes will know what kind of action has a high score , What kind of action has a low score , In this way, you can improve yourself , Let the score get higher and higher .
such :$ V_\pi({s})=\sum_{{a}}\pi({a}|{s})\cdot Q_\pi({s},{a})\approx\sum_a\pi(a|s;\theta)\cdot q(s,a;w)$$
b. Actor build
Policy network .
- Input : state s
- Output : Probability distribution of possible actions
- \(\mathcal{A}\) It's an action set , Such as \(\mathcal{A}\) ={ "left","right","up"}
- \(\sum_{a\in\mathcal{A}}\pi(a|s,\theta)=1\)
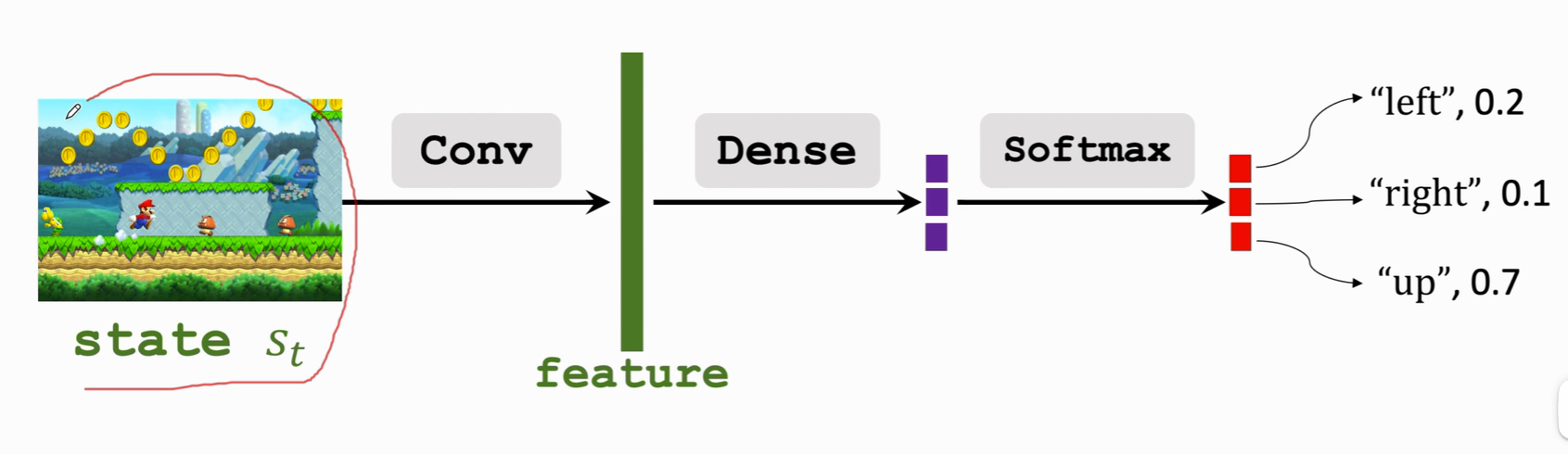
Convolution layer Conv hold state become An eigenvector feature , Use one or more full connection layers Dense Put the eigenvector Map to purple , After normalization, the probability of each action is obtained .
c. Critic build
Input : There are two , state s And the action a
Output : Approximate action value function (scalar)
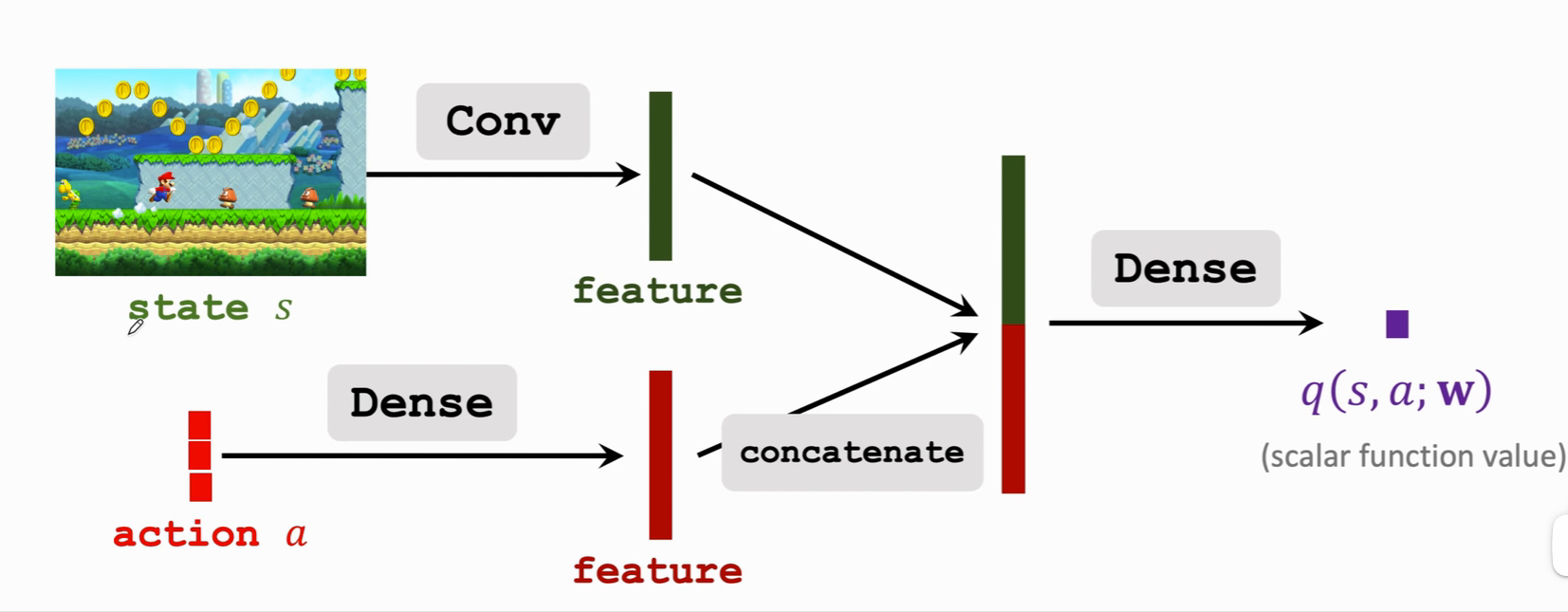
If action Is discrete , It can be used one-hot coding To express , For example, left is [1,0,0], To the right is [0,1,0] ······ Features are extracted from input using convolution layer and full connection layer respectively , Get two eigenvectors , Then join the two eigenvectors , Get a higher eigenvector , Finally, output a real number with a full connection layer , This real number is the score given by the referee to the athlete . This action shows , In state s Under the circumstances , Make an action a Good or bad . This value network can share convolution layer parameters with the policy network , It can also be completely independent of the strategic network .
4.2 Actor-Critic Method
At the same time, the training strategy network and action network are called Actor-Critic Method.
Definition : Use neural networks to approximate Two value functions
Training : Update parameters \(\theta、w\)
- Update policy network \(\pi({s}|{a};\theta)\) It's to make \(V({s};\theta,w)\) The value of the increase
- The supervision signal is only Provided by the value network
- Athletes actor According to the referee critic To continuously improve their level
- Update the value network \(q({s},{a};w)\) To make the scoring more accurate
- The supervision signal is only Rewards from the environment
- At first, the referee scored randomly , But it will improve the scoring level according to the rewards given by the environment , Make it close to the real score .
Step summary :
- Observation status \(s_t\)
- \(s_t\) As input , According to the policy network \(\pi({\cdot}|{s_t};\theta_t)\) Randomly sample an action \(a_t\)
- Implement actions \(a_t\) And observe the new state \(s_{t+1}\) And rewards \(r_t\)
- Reward with \(r_t\) adopt TD Algorithm Update in the value network w, Make the referee more accurate
- Use Strategy gradient algorithm Update in the policy network \(\theta\), Make athletes better
a. TD Update the value network
Use the value network Q to action \(a_t、a_{t+1}\) Scoring , Computation \(q({s_t}, {a_t} ;w_t)\) And \(q({s_{t+1}},{a_{t+1}};w_t)\)
Calculation TD target:\(y_t = {r_t} + \gamma \cdot q({s_{t+1}},{a_{t+1}};w_t)\),
Compare the strategy learning in the previous note , Monte Carlo is needed to approximate \(q({s_t},{a_t} ;w_t)\), It is more realistic to use value network to approximate .
The loss function is the difference between the predicted value and some real values .
Loss value : \(L(w)=\frac{1}{2}[q({s_t},{a_t};w)-y_t]^2\)
gradient descent :\(W_{t+1} = w_t -\alpha \cdot \frac{\partial L(w)}{\partial w}|w=w_t\)
b. Policy gradient updates policy network
State value function V Equivalent to the average score of all athletes :
\(V({s};\theta,w)=\sum_a\pi({s}|{a};\theta)\cdot q({s},{a};w)\)
Policy gradient : function \(V({s};\theta,w)\) About parameters \(\theta\) The derivative of
- \(g({a},\theta)=\frac{\partial log \pi({a}|{s};\theta)}{\partial \theta} \cdot q({s},{a};w)\), here q Equivalent to the score of the referee
- \(\frac{\partial V(s;\theta;w_t)}{\partial \theta} = \mathbb{E}_{A}[g({A},\theta)]\) The strategy gradient is equivalent to a function g Expect , hold A It's gone , But it's hard to expect , Use Monte Carlo approximation to sample and solve .
Algorithm :
According to the random sampling of the strategy network, we get the action a :\({a} \sim \pi(\cdot|{s_t};\theta_t)\) .
about \(\pi\) Random sampling ensures \(g(a,\theta)\) It's an unbiased estimate
With random gradients g, You can do a gradient rise :\(\theta_{t+1} = \theta_t + \beta \cdot g({a},\theta_t)\), here \(\beta\) It's the learning rate .
c. Process carding
Now let's sort out the process with the examples of athletes and referees :

First , Athletes ( The policy network on the left ) Observe the current state s , control agent Make an action a; Athletes want to improve , But it doesn't know how to get better ( Or there is no criterion ), Therefore, the referee is introduced to evaluate the athletes :
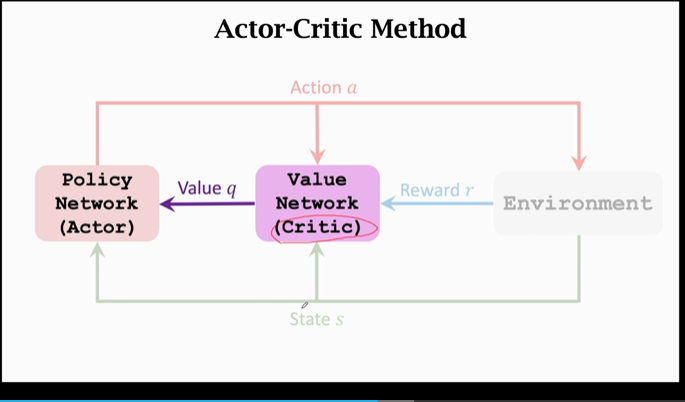
After the athlete makes the action , Referee ( Value network ) Will be based on a and s For athletes ( Policy network ) Give a score q, In this way, the athletes are based on q To improve yourself :

Athlete's “ technology ” refer to Parameters in the policy network , We previously believed that the better the parameters , The better our effect . In this model , Athletes get s、q as well as a To calculate Policy gradient , Update parameters through gradient rise . By improving the “ technology ”, Average score of athletes ( Namely value q) It's going to get higher and higher .
But here's the thing : thus , Athletes are always judged by the referee , His standard q The referee gave it . Average score of athletes q The higher the level, the higher the level . We also need to improve the level of referees .
Add an idea : I think actor-critic The idea of is two parts , First, let's The criterion is closer to God Ideas , Two is Under the given criteria Let the execution effect get greater scores .
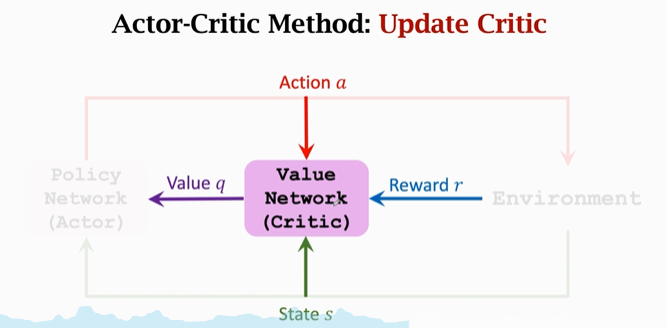
about Value network / The referee Come on The initial scoring is random . The referee depends on Reward r To improve the level of scoring , Here are rewards r Equivalent to God's judgment . The value network is based on a、s、r To give scores q , Through the scores of two adjacent times \(q_t、q_{t+1}\) as well as \(r_t\), Use TD Algorithm To update the parameters , Improve the effect
d. Algorithm is summarized
Let's make a little formal summary :
Observe the old state \(s_t\), According to the policy network \(\pi({\cdot}|{s_t};\theta_t)\) Randomly sample an action \(a_t\)
agent Executive action \(a_t\); The environment will tell us the new state \(s_{t+1}\) And rewards \(r_t\)
Get a new state \(s_{t+1}\) As input , Use the policy network \(\pi\) Calculate new probabilities and randomly sample new actions :\({\tilde{a}_{t+1}} \sim \pi({\cdot}|{s_{t+1}};\theta_t)\), This action is only an imaginary action ,agent Not execute , Just use it to calculate Q value .
Next, calculate the output of the value network twice :\(q_t=q({s_t},{a_t};w_t) and q_{t+1}=q({s_{t+1}},{\tilde{a}_{t+1}};w_t)\),\({\tilde{a}_{t+1}}\) It's gone , It doesn't really work ;
Calculation TD error:\(\delta_t = {q_t}-\underbrace{({r_t}+\gamma \cdot {q_{t+1}})}_{TD \\\ target}\)
Derivation of value network :\(d_{w,t} = \frac{\partial q({s_t},{a_t};w)}{\partial w}|w=w_t\)
This step torch and tensenflow Can be derived automatically .
TD Algorithm Update the value network , Let the referee score more accurately :\(w_{t+1}=w_t - \alpha \cdot \delta_t\cdot d_{w,t}\)
For Strategic Networks $$\pi$$ Derivation :\(d_{\theta,t}=\frac{\partial log \pi({a_t}|{s_t},\theta)}{\partial \theta}|\theta=\theta_t\)
Empathy , It can be derived automatically
Update the policy network with gradient rise , Let the average score of athletes be higher :\(\theta_{t+1} = \theta_t + \beta \cdot {q_t} \cdot d_{\theta,t}\), here \({q_t} \cdot d_{\theta,t}\) It's strategic gradient Monte Carlo approximation .
Do the above in each iteration 9 A step , And make an action , Observe a reward , Update the neural network parameters once .
According to the strategy gradient algorithm , The first algorithm 9 Step used \({q_t}\), It is the score given by the referee , Books and papers usually take \({\delta_t}\) To replace \({q_t}\).\({q_t}\) It's a standard algorithm ,\({\delta_t}\) yes Policy Gradient With Baseline( better ), Are all right , The calculated expectation is also equal .
Baseline What is it? ? near \(q_t\) The number of can be used as Baseline, But it can't be \(a_t\) Function of .
As for why baseline better , Because the variance can be calculated better , Faster convergence .
The equivalence here will be discussed later . Let's first understand .
4.3 summary
Our goal is : State value function :$ V_\pi({s})=\sum_{{a}}\pi({a}|{s})\cdot Q_\pi({s},{a})$, The bigger the better
- But learn directly \(\pi\) Functions are not easy , Using neural networks - Policy network \(\pi({s}|{a};\theta)\) To approximate
- Calculation Policy gradient There is a difficulty when I don't know the action value function \(Q_\pi\), So use neural networks - Value network \(q({s},{a};w)\) To approximate .
During the training :
- agent from Policy network (actor) Give the action \(a_t \sim \pi(\cdot|{s_t};\theta)\)
- Value network q Auxiliary training \(\pi\), Give a score
After training :
- Or by Policy network Give the action \(a_t \sim \pi(\cdot|{s_t};\theta)\)
- Value network q No longer use
How to train :
Update policy network with policy gradient :
- Maximize status value :$ V_\pi({s})=\sum_a\pi(a|s;\theta)\cdot q(s,a;w)$
- Calculate the strategy gradient , Calculate with Monte Carlo : \(\frac{\partial V(s;\theta;w_t)}{\partial \theta} = \mathbb{E}_{A}[\frac{\partial \\\ log \\\ \pi({a}|{s};\theta)}{\partial \theta} \cdot q({s},{a};w)]\)
- Perform gradient rise .
TD The algorithm updates the value network
\(q_t = q(s_t,a_t;w)\) Is the value network is an estimate of the expected return ;
TD target:\(y_t = r_t + \gamma \cdot \mathop{max}\limits_{a} q(s_{t+1},a_{t+1};w)\),\(y_t\) Also, the value network is an estimate of the expected return , But it uses real rewards , So it's more reliable , So take it as target, Equivalent to labels in machine learning .
hold \(q_t And y_t\) The square of the difference is used as the loss function to calculate the gradient :
\(\frac{\partial(q_t-y_t)^2/2}{\partial w} = (q_t-y_t)\cdot\frac{\partial q(s_t,a_t;w)}{\partial w}\)
gradient descent , narrow \(q_t And y_t\) disparity .
x. Reference tutorial
- Video Course : Deep reinforcement learning ( whole )_ Bili, Bili _bilibili
- Video original address :https://www.youtube.com/user/wsszju
- Courseware address :https://github.com/wangshusen/DeepLearning
- Note reference :