当前位置:网站首页>Machine learning concept drift detection method (Apria)
Machine learning concept drift detection method (Apria)
2022-07-04 18:16:00 【Li Guodong】
at present , There are many techniques that can be used in machine learning to detect concept drift . Familiarity with these detection methods is the key to using the correct metrics for each drift and model .
In this article , Four types of detection methods are reviewed : Statistics 、 Statistical process control 、 Based on time window and Context method .
If you are looking for an introduction to concept drift , I suggest you check Concept drift in machine learning One article .
Statistical methods
Statistical methods are used for Compare the differences between distributions .
In some cases , Can use divergence , This is a measure of distance between distributions . In other cases , Run tests to get scores .
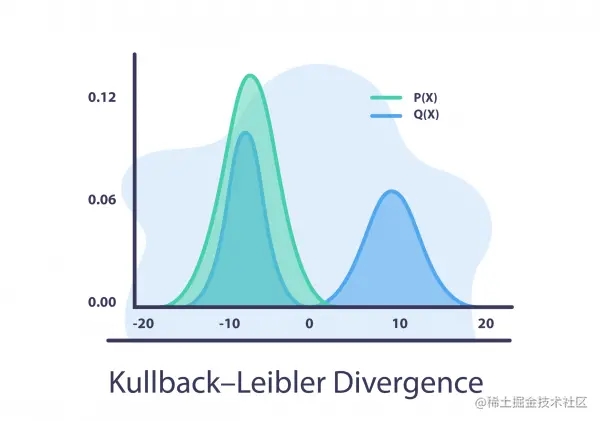
Kullback-Leibler The divergence
Kullback-Leibler Divergence is sometimes called relative entropy .
KL Divergence attempts to quantify how different one probability distribution is from another , therefore , If we have distribution Q and P, among ,Q Distribution is the distribution of old data ,P Is the distribution of new data we want to calculate :
K L ( Q ∣ ∣ P ) = − ∑ x P ( x ) ∗ l o g ( Q ( x ) P ( x ) ) KL(Q||P) = - \displaystyle\sum_x{P(x)}*log(\frac{Q(x)}{P(x)}) KL(Q∣∣P)=−x∑P(x)∗log(P(x)Q(x))
among ,“||” Represents divergence .
We can see ,
- If P(x) High and high Q(x) low , Then the divergence will be very high .
- If P(x) Low and Q(x) high , Then the divergence will also be very high , But not so big .
- If P(x) and Q(x) be similar , Then the divergence will be very low .
JS The divergence
Jensen-Shannon Divergence use KL The divergence
J S ( Q ∣ ∣ P ) = 1 2 ( K L ( Q ∣ ∣ M ) + K L ( P ∣ ∣ M ) ) JS(Q||P) = \frac{1}{2}(KL(Q||M) +KL(P||M)) JS(Q∣∣P)=21(KL(Q∣∣M)+KL(P∣∣M))
among , M = Q + P 2 M = \frac{Q+P}{2} M=2Q+P yes P and Q Average between .
JS Divergence and KL The main difference in divergence is JS It's symmetrical , It always has a finite value .
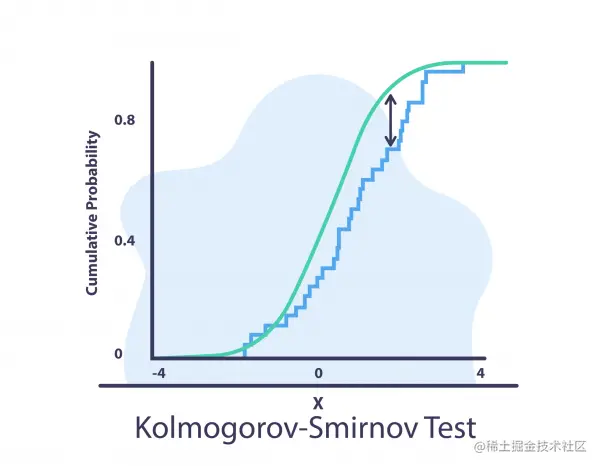
Kolmogorov-Smirnov test (K-S test )
Two samples KS Test is a useful and general nonparametric method for comparing two samples . stay KS In the test , We calculated :
D n , m = s u p x ∣ F 1 , n ( x ) − F 2 , m ( x ) ∣ D_{n,m}=sup_{x}|F_{1,n}(x) - F_{2,m}(x)| Dn,m=supx∣F1,n(x)−F2,m(x)∣
among , F 1 , n ( x ) F_{1,n}(x) F1,n(x) Is the previous data and n n n The empirical distribution function of the sample , F 2 , m ( x ) F_{2,m}(x) F2,m(x) It's new data and m m m Samples and F n ( x ) = 1 n ∑ i = 1 n I [ − ∞ , x ] ( X i ) F_{n}(x) = \frac{1}{n} \displaystyle\sum_{i=1}^n I_{[- \infty,x]}(X_{i}) Fn(x)=n1i=1∑nI[−∞,x](Xi) Empirical distribution function of , s u p x sup_{x} supx Is to make ∣ F 1 , n ( x ) − F 2 , m ( x ) ∣ |F_{1,n}(x) - F_{2,m}(x)| ∣F1,n(x)−F2,m(x)∣ Maximize the sample x x x Subset .
KS The test is sensitive to the difference in the position and shape of the empirical cumulative distribution function of the two samples . It is very suitable for numerical data .
When to use statistical methods
The idea of the statistical method part is to evaluate the distribution between two data sets .
We can use these tools to find the differences between data in different time ranges , And measure the differences in data behavior over time .
For these methods , There is no need for labels , No additional memory is required , We can quickly obtain the input characteristics of the model / Indicators of output changes . This will help us to investigate this situation even before there is any potential decline in the performance indicators of the model . On the other hand , If not handled correctly , Lack of labels and neglect of memory of past events and other characteristics may lead to false positives .
Statistical process control
The idea of statistical process control is Verify whether the error of our model is within the controllable range . This is especially important when running in production , Because performance changes over time . therefore , We hope to have a system , If the model reaches a certain error rate , It will send an alert . Please note that , Some models have “ traffic lights ” System , There are also warnings .
Drift detection method / Early drift detection method (DDM/EDDM)
The idea is to model errors as binomial variables . This means that we can calculate our expected error value . When we use binomial distribution , We can mark = n p t =npt =npt, therefore , σ = p t ( 1 − p t ) n \sigma = \sqrt{\frac{p_{t}(1-p_{t})}{n}} σ=npt(1−pt).
DDM
Here we can propose :
- When p t + σ t ≥ p m i n + 2 σ m i n p_{t}+\sigma_{t}\ge p_{min} +2\sigma_{min} pt+σt≥pmin+2σmin Give a warning
- When p t + σ t ≥ p m i n + 3 σ m i n p_{t}+\sigma_{t}\ge p_{min} +3\sigma_{min} pt+σt≥pmin+3σmin Call the police
advantage :DDM Gradually change in detection ( If they are not very slow ) And sudden changes ( Increment and sudden drift ) It shows good performance .
shortcoming : When the change is slow ,DDM Difficult to detect drift . Many samples may have been stored for a long time before the drift level is activated , There is a risk of sample storage overflow .
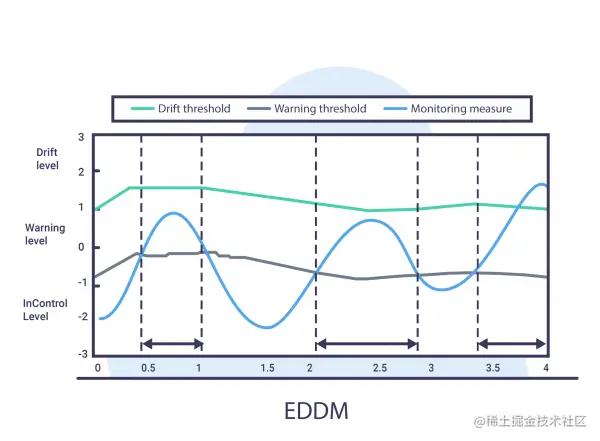
EDDM
ad locum , By measuring 2 A continuous wrong distance , We can propose :
- When p t + 2 σ t p m a x + 2 σ m a x < α \frac{p_{t}+2{\large \sigma}_{t}}{p_{max}+2{\large \sigma}_{max}}<{\Large \alpha} pmax+2σmaxpt+2σt<α Give a warning
- When p t + 2 σ t p m a x + 2 σ m a x < β \frac{p_{t}+2{\large \sigma}_{t}}{p_{max}+2{\large \sigma}_{max}}<{\Large \beta} pmax+2σmaxpt+2σt<β Give an alarm when , among ${\Large \beta} $ Usually it is 0.9
EDDM The method is DDM Modified version of , Its focus is to identify gradual drift .
CUMSUM and Page-Hinckley (PH)
CUSUM And its variants Page-Hinckley (PH) It is one of the development methods in the community . The idea of this method is to provide a sequence analysis technology , This technology is usually used to monitor the change of the average value of Gaussian signal .
CUSUM and Page-Hinckley (PH) Concept drift is detected by calculating the difference between the observed value and the average value , And set the drift alarm when the value is greater than the user-defined threshold . These algorithms are sensitive to parameter values , This leads to a trade-off between false positives and detection of true drift .
because CUMSUM and Page-Hinckley (PH) Used to process data streams , So each event is used to calculate the next result :
CUMSUM:
- g 0 = 0 , g t = m a x ( 0 , g t − 1 + ε t − v ) {\large g}_{0}=0, {\large g}_{t}= max(0, {\large g}_{t-1}+{\large \varepsilon}_{t}-{\large v}) g0=0,gt=max(0,gt−1+εt−v) among , g On behalf of the event , Or for the purpose of drift , Model input / Output
- When g t > h {\large g}_{t}>h gt>h sound the alarm , And set up g t = 0 {\large g}_{t}=0 gt=0
- h , v h,v h,v Is an adjustable parameter
Be careful :CUMSUM It's memoryless 、 Unilateral or asymmetrical , Therefore, it can only detect the increase of value .
Page-Hinckley (PH) :
- g 0 = 0 , g t = g t − 1 + ( ε t − v ) {\large g}_{0}=0, {\large g}_{t}= {\large g}_{t-1}+({\large \varepsilon}_{t}-v) g0=0,gt=gt−1+(εt−v)
- G t = m i n ( g t , G t − 1 ) G_{t}=min({\large g}_{t},G_{t-1}) Gt=min(gt,Gt−1)
When g t − G t > h g_{t}-G_{t}>h gt−Gt>h sound the alarm , And set up g t = 0 g_{t}=0 gt=0.
When to use statistical process control methods
Use the statistical process control method introduced , We need to provide the label of the sample . in many instances , It could be a challenge , Because the delay may be high , And it's hard to extract it , Especially when it is used in large organizations . On the other hand , Once these data are obtained , We will get a relatively fast system to cover 3 There are three types of drift : Sudden drift 、 Progressive drift and incremental drift .
The system also allows us to track degradation with the Department ( If any ), To give warnings and alarms .
Time window distribution
Time window distribution model Watch for timestamps and events .
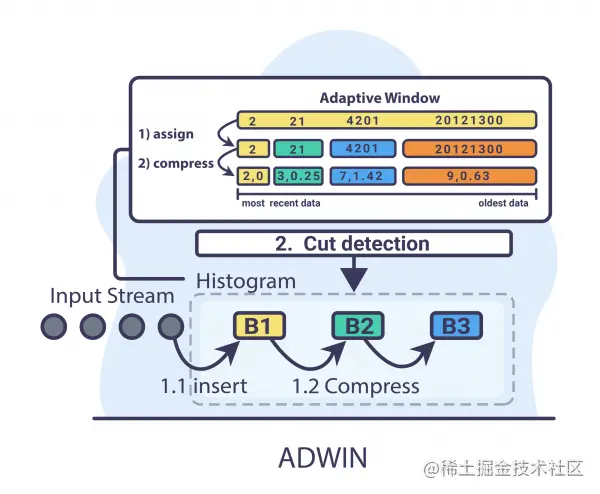
ADWIN
ADWIN The thought is from the time window W W W Start , Dynamically enlarge the window when the context does not change significantly W W W, And shrink it when changes are detected . The algorithm tries to find the W − w 0 W - w_{0} W−w0 and w 1 w_{1} w1 Two sub windows of . This means the old part of the window − w 0 - w_{0} −w0 It is based on data distribution different from the actual , So it's deleted .
Paired Learners
Suppose for a given problem , We have a large stable model trained with a large amount of data , Let's mark it as a model A.
We will also design another model , A more lightweight model , Train on smaller and newer data ( It can have the same type ). We call it a model B.
idea : Find the model B Better than the model A Time window of . Due to the model A Compared to the model B Stabilize and encapsulate more data , We expect it to outperform it . however , If the model B Better than the model A, It may indicate a conceptual drift .
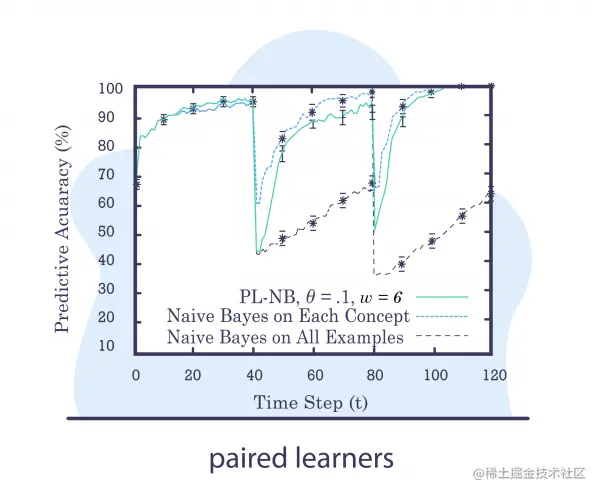
Context method (Contextual Approaches)
The idea of these methods is to evaluate the difference between the training set and the test set . When the difference is significant , It may indicate that there is a drift in the data .
Tree features
The idea of tree features is Train a relatively simple tree on data , And add the prediction timestamp as one of the features . Because the tree model can also be used for feature importance , We can know how time affects data and when . Besides , We can see the split created by timestamp , We can see the difference between the concepts before and after the split .
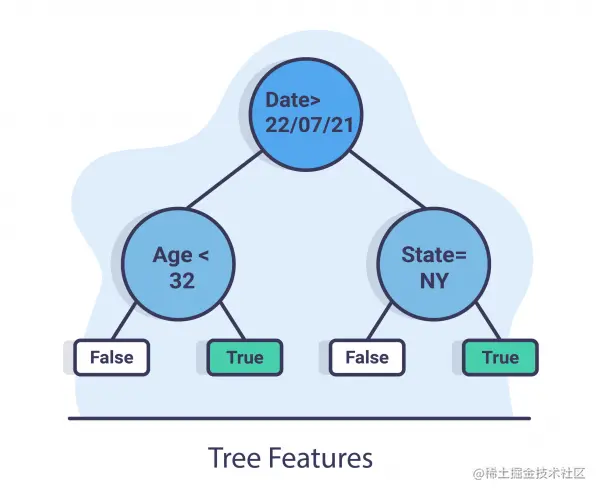
In the diagram above , We can see that the date feature is at the root , This means that this feature has the highest information gain , This means that 7 month 22 Japan , They may have drifted in the data .
Drift detection implementation
You can find related implementations that provide drift detection :
- Java Realization :MOA
- Python Realization :scikit-multiflow
Link to the original text :Concept Drift Detection Methods
边栏推荐
- Rainfall warning broadcast automatic data platform bwii broadcast warning monitor
- 比李嘉诚还有钱的币圈大佬,刚在沙特买了楼
- Superscalar processor design yaoyongbin Chapter 7 register rename excerpt
- 正则表达式
- You should know something about ci/cd
- regular expression
- ARTS_20220628
- With an estimated value of 90billion, the IPO of super chip is coming
- Superscalar processor design yaoyongbin Chapter 6 instruction decoding excerpt
- Set the transparent hidden taskbar and full screen display of the form
猜你喜欢
用于图数据库的开源 PostgreSQL 扩展 AGE被宣布为 Apache 软件基金会顶级项目
超标量处理器设计 姚永斌 第5章 指令集体系 摘录
Unity makes revolving door, sliding door, cabinet door drawer, click the effect of automatic door opening and closing, and automatically play the sound effect (with editor extension code)
Easy to use map visualization
TCP waves twice, have you seen it? What about four handshakes?
Blood spitting finishing nanny level series tutorial - play Fiddler bag grabbing tutorial (2) - first meet fiddler, let you have a rational understanding

Just today, four experts from HSBC gathered to discuss the problems of bank core system transformation, migration and reconstruction

7 RSA Cryptosystem

股价大跌、市值缩水,奈雪推出虚拟股票,深陷擦边球争议

【Hot100】32. Longest valid bracket

随机推荐
CocosCreator事件派發使用
Unity makes revolving door, sliding door, cabinet door drawer, click the effect of automatic door opening and closing, and automatically play the sound effect (with editor extension code)
Blue bridge: sympodial plant
[HCIA continuous update] WLAN overview and basic concepts
regular expression
Implementation of shell script replacement function
Pytorch深度学习之环境搭建
7 RSA Cryptosystem
Weima, which is going to be listed, still can't give Baidu confidence
Pytoch deep learning environment construction
Tutorial on the use of Huawei cloud modelarts (with detailed illustrations)
Initial experience of domestic database tidb: simple and easy to use, quick to start
如何提高开发质量
Set the transparent hidden taskbar and full screen display of the form
Introduction of time related knowledge in kernel
How to test MDM products
Russia arena data releases PostgreSQL based products
【Hot100】31. Next spread
Android uses sqliteopenhelper to flash back
设置窗体透明 隐藏任务栏 与全屏显示