当前位置:网站首页>[data mining] task 4:20newsgroups clustering
[data mining] task 4:20newsgroups clustering
2022-07-03 01:38:00 【zstar-_】
requirement
according to 20Newsgroups Data sets are clustered , Display the clustering results to the user , Users can choose one of these classes , Mark as concerned , Class keywords as topics , Users can track this topic 、 Understand the content of the article on the topic .
Import related libraries
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
import numpy as np
import re
import string
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
from wordcloud import WordCloud
%matplotlib inline
Data acquisition
Use sklearn Of fetch_20newsgroups Download data
dataset = fetch_20newsgroups(
download_if_missing=True, remove=('headers', 'footers', 'quotes'))
Data preview
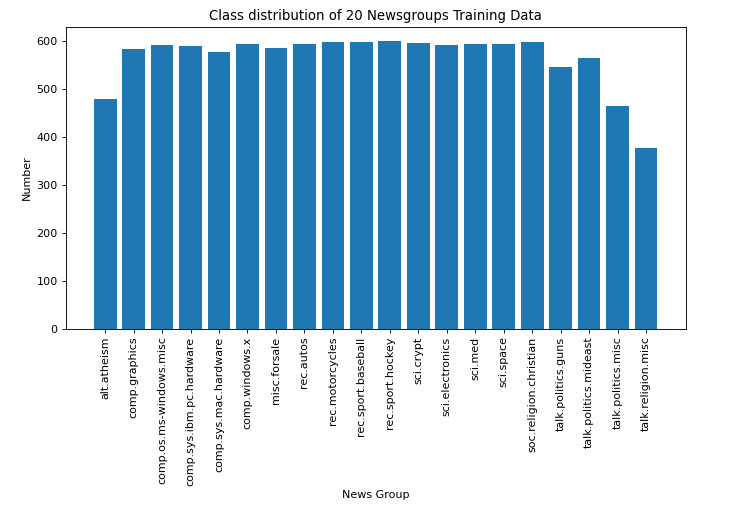
You can see , News data share 20 A classification
Visualize the quantity of each category
dataset.target_names
['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']
# Visualize the number of categories
targets, frequency = np.unique(dataset.target, return_counts=True)
targets_str = np.array(dataset.target_names)
fig = plt.figure(figsize=(10, 5), dpi=80, facecolor='w', edgecolor='k')
plt.bar(targets_str, frequency)
plt.xticks(rotation=90)
plt.title('Class distribution of 20 Newsgroups Training Data')
plt.xlabel('News Group')
plt.ylabel('Number')
plt.show()
Data preprocessing
In order to improve the accuracy of clustering , Preprocess the data before clustering , Eliminate numbers and punctuation in the data , And convert uppercase letters to lowercase
dataset_df = pd.DataFrame({
'data': dataset.data, 'target': dataset.target})
# Use regular expressions for data processing
def alphanumeric(x):
return re.sub(r"""\w*\d\w*""", ' ', x)
def punc_lower(x):
return re.sub('[%s]' % re.escape(string.punctuation), ' ', x.lower())
dataset_df['data'] = dataset_df.data.map(alphanumeric).map(punc_lower)
The processed data is displayed
dataset_df.data
0 i was wondering if anyone out there could enli...
1 a fair number of brave souls who upgraded thei...
2 well folks my mac plus finally gave up the gh...
3 \ndo you have weitek s address phone number ...
4 from article world std com by tombaker ...
...
11309 dn from nyeda cnsvax uwec edu david nye \nd...
11310 i have a very old mac and a mac plus both...
11311 i just installed a cpu in a clone motherbo...
11312 \nwouldn t this require a hyper sphere in ...
11313 stolen from pasadena between and pm on...
Name: data, Length: 11314, dtype: object
K-means clustering
Use K-means Clustering method , Aggregate data into 20 class
texts = dataset.data
target = dataset.target
vectorizer = TfidfVectorizer(stop_words='english')
X = vectorizer.fit_transform(texts)
number_of_clusters = 20
model = KMeans(n_clusters=number_of_clusters,
init='k-means++',
max_iter=100,
n_init=1)
model.fit(X)
KMeans(max_iter=100, n_clusters=20, n_init=1)
View the keywords in each category after clustering , Each category shows 20 individual
dict_list = []
order_centroids = model.cluster_centers_.argsort()[:, ::-1]
terms = vectorizer.get_feature_names()
for i in range(number_of_clusters):
dict = {
}
print("Cluster %d:" % i),
for ind in order_centroids[i, :20]:
print(' %s' % terms[ind])
dict[terms[ind]] = model.cluster_centers_[i][ind]
dict_list.append(dict)
Category forecast
Classify the test set according to the model
# Classify individual words
X = vectorizer.transform([texts[400]])
cluster = model.predict(X)[0]
# print(" This word belongs to the {0} class ".format(cluster))
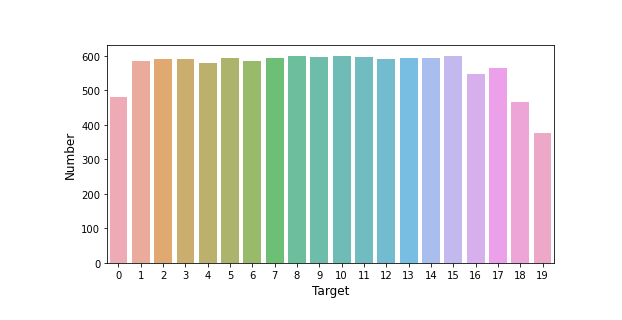
# Visualization of test set prediction results
count_target = dataset_df['target'].value_counts()
plt.figure(figsize=(8, 4))
sns.barplot(count_target.index, count_target.values, alpha=0.8)
plt.ylabel('Number', fontsize=12)
plt.xlabel('Target', fontsize=12)
Word cloud display
Show the word cloud diagram of each category
for i in range(20):
wordcloud = WordCloud(background_color="white", relative_scaling=0.5,
normalize_plurals=False).generate_from_frequencies(dict_list[i])
fig = plt.figure(figsize=(8, 6))
plt.axis('off')
plt.title('Cluster %d:' % i, fontsize='15')
plt.imshow(wordcloud)
plt.show()
Here are only two categories of pictures to show .

边栏推荐
- Wireshark data analysis and forensics a.pacapng
- [fh-gfsk] fh-gfsk signal analysis and blind demodulation research
- Mathematical knowledge: divisible number inclusion exclusion principle
- Openresty cache
- QTableWidget懒加载剩内存,不卡!
- 【数据挖掘】任务6:DBSCAN聚类
- Soft exam information system project manager_ Real topic over the years_ Wrong question set in the second half of 2019_ Morning comprehensive knowledge question - Senior Information System Project Man
- leetcode刷题_两数之和 II - 输入有序数组
- [data mining] task 5: k-means/dbscan clustering: double square
- MySQL --- 数据库查询 - 条件查询
猜你喜欢

Smart management of Green Cities: Digital twin underground integrated pipe gallery platform

力扣 204. 计数质数
给你一个可能存在 重复 元素值的数组 numbers ,它原来是一个升序排列的数组,并按上述情形进行了一次旋转。请返回旋转数组的最小元素。【剑指Offer】
After reading this article, I will teach you to play with the penetration test target vulnhub - drivetingblues-9
![[principles of multithreading and high concurrency: 2. Solutions to cache consistency]](/img/ce/5c41550ed649ee7cada17b0160f739.jpg)
[principles of multithreading and high concurrency: 2. Solutions to cache consistency]

C#应用程序界面开发基础——窗体控制(2)——MDI窗体
软考信息系统项目管理师_历年真题_2019下半年错题集_上午综合知识题---软考高级之信息系统项目管理师053

简易分析fgui依赖关系工具
Qtablewidget lazy load remaining memory, no card!
Meituan dynamic thread pool practice ideas, open source
随机推荐
看完这篇 教你玩转渗透测试靶机Vulnhub——DriftingBlues-9
Wordinsert formula /endnote
Mathematical knowledge: divisible number inclusion exclusion principle
Using tensorboard to visualize the model, data and training process
C application interface development foundation - form control (4) - selection control
The latest analysis of tool fitter (technician) in 2022 and the test questions and analysis of tool fitter (technician)
[day 29] given an integer, please find its factor number
[C language] detailed explanation of pointer and array written test questions
[self management] time, energy and habit management
传输层 TCP主要特点和TCP连接
不登陆或者登录解决oracle数据库账号被锁定。
High resolution network (Part 1): Principle Analysis
View of MySQL
[technology development-23]: application of DSP in future converged networks
一比特苦逼程序員的找工作經曆
软考信息系统项目管理师_历年真题_2019下半年错题集_上午综合知识题---软考高级之信息系统项目管理师053
[QT] encapsulation of custom controls
电信客户流失预测挑战赛
Look at how clothing enterprises take advantage of the epidemic
What are the trading forms of spot gold and what are the profitable advantages?