当前位置:网站首页>Flink jdbc connector 源码改造sink之 clickhouse多节点轮询写与性能分析
Flink jdbc connector 源码改造sink之 clickhouse多节点轮询写与性能分析
2022-08-04 01:06:00 【学到的心态】
Flink 写clickhouse集群失败分析
文章目录
一. 情况说明
消费kafka的数据然后写到clickhouse集群,写的方式是ck每个节点轮询写
1. flink sql
CREATE TABLE `kafka_01` (
`id` BIGINT,
`oRDER_ID` STRING,
`num_dou` DOUBLE,
`num_int` BIGINT,
`cloud_wise_proc_time` AS `proctime`()
) WITH (
'connector' = 'kafka',
'properties.group.id' = 'dodp_1659060265587',
'scan.startup.mode' = 'latest-offset',
'value.format' = 'json',
'value.fields-include' = 'ALL',
'value.json.ignore-parse-errors' = 'true',
'value.json.fail-on-missing-field' = 'false',
'properties.max.poll.records' = '5000',
'topic' = 'source_76',
'properties.bootstrap.servers' = 'xxx:18108'
);
INSERT INTO `sink_ck2`
(SELECT `id`, `oRDER_ID` AS `name1`, `num_dou`, `num_int`
FROM `kafka_01`);
CREATE TABLE `sink_ck2` (
`id` BIGINT,
`name1` STRING,
`num_dou` DOUBLE,
`num_int` BIGINT
) WITH (
'connector' = 'jdbc',
'driver' = 'ru.yandex.clickhouse.ClickHouseDriver',
'url' = 'jdbc:clickhouse://***.127:18100/shard_3?socket_timeout=900000,jdbc:clickhouse://***.126:18100/shard_2?socket_timeout=900000,jdbc:clickhouse://***.125:18100/shard_1?socket_timeout=900000',
'sink.buffer-flush.max-rows' = '10000',
'sink.buffer-flush.interval' = '10s',
'sink.max-retries' = '3',
'username' = '****',
'pd' = '****',
'table-name' = 'ellie_sink_ck_replica'
);
2. 报错信息:
2022-08-02 14:13:29,423 INFO org.apache.kafka.clients.consumer.internals.SubscriptionState [] - [Consumer clientId=consumer-dodp_1659060265587-2, groupId=dodp_1659060265587] Resetting offset for partition source_76-0 to offset 1335.
2022-08-02 14:13:29,424 INFO org.apache.kafka.clients.consumer.internals.SubscriptionState [] - [Consumer clientId=consumer-dodp_1659060265587-2, groupId=dodp_1659060265587] Seeking to LATEST offset of partition source_76-1
2022-08-02 14:13:29,513 INFO org.apache.kafka.clients.consumer.internals.SubscriptionState [] - [Consumer clientId=consumer-dodp_1659060265587-2, groupId=dodp_1659060265587] Resetting offset for partition source_76-1 to offset 1332.
2022-08-02 14:13:29,513 INFO org.apache.kafka.clients.consumer.internals.SubscriptionState [] - [Consumer clientId=consumer-dodp_1659060265587-2, groupId=dodp_1659060265587] Seeking to LATEST offset of partition source_76-2
2022-08-02 14:13:29,595 INFO org.apache.kafka.clients.consumer.internals.SubscriptionState [] - [Consumer clientId=consumer-dodp_1659060265587-2, groupId=dodp_1659060265587] Resetting offset for partition source_76-2 to offset 1469.
2022-08-02 14:13:29,952 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - JDBC executeBatch error, retry times = 0
java.sql.SQLException: Please call addBatch method at least once before batch execution
at com.clickhouse.jdbc.SqlExceptionUtils.clientError(SqlExceptionUtils.java:43) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.SqlExceptionUtils.emptyBatchError(SqlExceptionUtils.java:111) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.InputBasedPreparedStatement.executeAny(InputBasedPreparedStatement.java:97) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.AbstractPreparedStatement.executeLargeBatch(AbstractPreparedStatement.java:85) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.ClickHouseStatementImpl.executeBatch(ClickHouseStatementImpl.java:577) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at org.apache.flink.connector.jdbc.statement.FieldNamedPreparedStatementImpl.executeBatch(FieldNamedPreparedStatementImpl.java:120) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableSimpleStatementExecutor.executeBatch(TableSimpleStatementExecutor.java:64) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableBufferedStatementExecutor.executeBatch(TableBufferedStatementExecutor.java:64) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.attemptFlush(JdbcBatchingOutputFormat.java:236) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.flush(JdbcBatchingOutputFormat.java:182) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.lambda$open$0(JdbcBatchingOutputFormat.java:126) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_271]
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_271]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_271]
...
JDBC executeBatch error, retry times = 1,2,3
...
报错的关键信息就是:
java.sql.SQLException: Please call addBatch method at least once before batch execution。
直观的理解就是在没有调用addBatch就执行了executeBatch
3. clickhouse多节点轮询写 在Flink jdbc connector 的源码改造逻辑
flink官方并未支持clickhouse的connector,所以我们在支持clickhouse connector,读写逻辑上对Flink jdbc connector 做了改造。对于Flink jdbc connector 写clickhouse分布式表的基本逻辑是:
配置一个分布式表下所有本地表的url,通过轮询的方式写数据,不造成单点的写压力。同时借助Flink jdbc connector 本身sink-retry的逻辑,天然支持了单点故障问题。具体代码稍后分析。
Flink jdbc connector 对于sink的操作,只是实现了单节点的逻辑,目前看报错,我们在某些运行场景下并没有将clickhouse多节点轮询适配的很好。
二. 问题分析与源码解读
1. 问题表象
先看下关键的堆栈信息
at org.apache.flink.connector.jdbc.statement.FieldNamedPreparedStatementImpl.executeBatch(FieldNamedPreparedStatementImpl.java:120) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableSimpleStatementExecutor.executeBatch(TableSimpleStatementExecutor.java:64) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableBufferedStatementExecutor.executeBatch(TableBufferedStatementExecutor.java:64) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.attemptFlush(JdbcBatchingOutputFormat.java:236) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.flush(JdbcBatchingOutputFormat.java:182) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.lambda$open$0(JdbcBatchingOutputFormat.java:126) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_271]
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_271]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_271]
根据以上堆栈报错,基本可以定位到,报错的代码位置在:
TableBufferedStatementExecutor.executeBatch()
@Override
public void executeBatch() throws SQLException {
for (RowData value : buffer) {
statementExecutor.addToBatch(value);
}
statementExecutor.executeBatch();
buffer.clear();
}
报错的逻辑也可以根据堆栈信息知道:
在ScheduledThreadPoolExecutor执行定时任务,执行上述代码时因为没有执行“addToBatch”,执行executeBatch而报错。
2. flink sql sink时的代码逻辑
知道报错的位置,我们还需要了解flink sql是如何写数据的:
2.1. sink大体的逻辑:
Planing阶段通过Metadata,将sql的(table schema 、sink方式等)参数代码化,然后sink数据时按照metadata的参数规则写数据到具体的数据库(本文是clickhouse)。
planning:
JdbcDynamicTableFactory.createDynamicTableSink 和JdbcDynamicTableSink.getSinkRuntimeProvider 将元数据进行“代码化”,以便安装一定的逻辑sink数据。
runtime:
JdbcBatchingOutputFormat. open /writeRecord :建立连接,写数据。
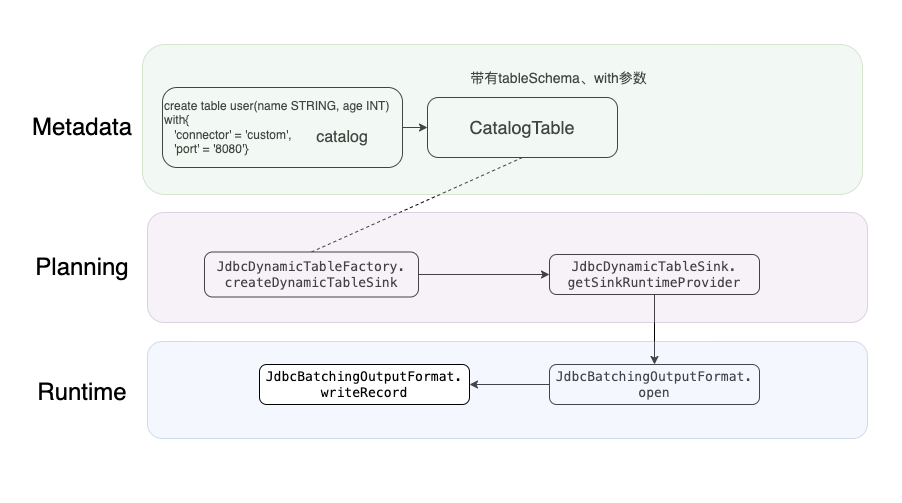
上图展示了sink的大致逻辑,可以猜测一下具体的runtime的过程:
当上游算子有数据输出到sink时,sink 先open(建立jdbc连接),然后再writeRecord。
2.2. with参数下sink的周边逻辑
'sink.buffer-flush.max-rows' = '10000',
'sink.buffer-flush.interval' = '3s',
'sink.max-retries' = '3',
sink刷新到数据库每次最多10000行,(如果在3秒内没有消费10000条则)刷新间隔为3秒,如果写库失败则最多重试3次写数据。
2.3. 源码分析与问题复现
有了上面的基础,我们大概知道flink是怎么sink数据的,以及按照什么规律sink数据的逻辑,接下来我们具体看一下源码的细节。
上面我们定位到flink在runtime时,主要是JdbcBatchingOutputFormat类,完成了数据的读取和写入。其中open(int taskNumber, int numTasks) 和 writeRecord(In record) 是主要的逻辑。那我们就从这两个方法入手去分析根本问题。
对于open(int taskNumber, int numTasks) 主要做了两件事:
一个是创建JDBC连接,另一个是根据
sink.buffer-flush.interval创建了scheduleWithFixedDelay定时任务。
/** * 上游来数据时会open一次 之后就会不了调用这个方法了 * <p> * 连接目标数据库 以及初始化prepared statement。 * Connects to the target database and initializes the prepared statement. * * @param taskNumber The number of the parallel instance. */
@Override
public void open(int taskNumber, int numTasks) throws IOException {
super.open(taskNumber, numTasks);
jdbcStatementExecutor = createAndOpenStatementExecutor(statementExecutorFactory);
if (executionOptions.getBatchIntervalMs() != 0 //sink.buffer-flush.interval 刷新间隔,默认为1s
&& executionOptions.getBatchSize() != 1) {
//sink.buffer-flush.max-rows 单批写入最大数据量,默认为100条
this.scheduler =
Executors.newScheduledThreadPool(
1, new ExecutorThreadFactory("jdbc-upsert-output-format"));
//按照一定周期去写批数据。
this.scheduledFuture =
this.scheduler.scheduleWithFixedDelay(
() -> {
synchronized (JdbcBatchingOutputFormat.this) {
if (!closed) {
try {
flush();
} catch (Exception e) {
flushException = e;
}
}
}
},
executionOptions.getBatchIntervalMs(),
executionOptions.getBatchIntervalMs(),
TimeUnit.MILLISECONDS);
}
}
//super.open(taskNumber, numTasks) => AbstractJdbcOutputFormat.open
@Override
public void open(int taskNumber, int numTasks) throws IOException {
try {
establishConnection();
} catch (Exception e) {
throw new IOException("unable to open JDBC writer", e);
}
}
protected void establishConnection() throws Exception {
connection = connectionProvider.getConnection();
}
/** * 建立JDBC连接: * 适配clickhouse多节点轮询写逻辑 */
@Override
public Connection getConnection() throws SQLException, ClassNotFoundException {
if (connection == null) {
//双重检测提高性能
synchronized (this) {
if (connection == null) {
Class.forName(jdbcOptions.getDriverName());
/** * 不再使用此逻辑建立连接写表 * jdbc:clickhouse://10.0.1.127,10.0.1.128,10.0.1.129:18100 * 而是通过通过轮询的方式写: * dbc:clickhouse://10.0.1.127:18100/shard_3,jdbc:clickhouse://10.0.1.126:18100/shard_2,jdbc:clickhouse://10.0.1.125:18100/shard_1 * */
if (!isWriteLocalClickhouse() && jdbcOptions.getDbURL().contains("clickhouse")) {
ClickHouseProperties properties = new ClickHouseProperties();
properties.setUser(jdbcOptions.getUsername().isPresent() ? jdbcOptions.getUsername().get() : null);
properties.setPassword(jdbcOptions.getPassword().isPresent() ? jdbcOptions.getPassword().get() : null);
BalancedClickhouseDataSource dataSource = new BalancedClickhouseDataSource(jdbcOptions.getDbURL(), properties);
connection = dataSource.getConnection();
} else {
if (jdbcOptions.getUsername().isPresent()) {
connection =
DriverManager.getConnection(
dbUrls[round++ % dbUrls.length],
jdbcOptions.getUsername().get(),
jdbcOptions.getPassword().orElse(null));
} else {
connection = DriverManager.getConnection(dbUrls[round++ % dbUrls.length]);
}
if (round >= 4096) {
round = 0;
}
}
}
}
}
return connection;
}
writeRecord(In record) 的逻辑:
先将消费的数据攒批,如果达到
sink.buffer-flush.max-rows就直接flush到库中,如果没有达到就按照设定的sink.buffer-flush.interval定时写批。
/** * 写数据到数据库 * 来一条数据执行一次addBatch */
@Override
public final synchronized void writeRecord(In record) throws IOException {
//抛出异常 kill 掉job 以免定时任务浪费资源,或上游数据积压太多
checkFlushException();
try {
//如果没有大于batchsize就让定时任务执行
addToBatch(record, jdbcRecordExtractor.apply(record));
batchCount++;
LOG.error("writeRecord addToBatch batchCount {}", batchCount);
//如果数据大于batchsize 就直接刷新
if (executionOptions.getBatchSize() > 0
&& batchCount >= executionOptions.getBatchSize()) {
flush();
}
} catch (Exception e) {
throw new IOException("Writing records to JDBC failed.", e);
}
}
synchronized void flush() 逻辑:
flush数据到库,包括直接flush或者线程定时的flush。
如果flush失败则进行重试,重试超过一定次数,flink则认为数据库的连接有问题,为了避免大量的连接以及上游数据堆积浪费资源,所以此时写数据就失效了。
对于clickhouse:如果失败然后重连下一个节点,继续尝试flush,如果成功则说明起到了故障转移的效果,如果重试都没成功,那直接让写失效。 具体表现就是 job 被kill:被kill的逻辑大体是checkFlushException();抛出异常传递给上游算子。
/** * flush操作 * 直接flush或者线程定时的flush * * @throws IOException */
@Override
public synchronized void flush() throws IOException {
checkFlushException();
//写数据重试
for (int i = 0; i <= executionOptions.getMaxRetries(); i++) {
try {
attemptFlush();
batchCount = 0;
break;
} catch (SQLException e) {
LOG.error("JDBC executeBatch error, retry times = {}", i, e);
//等于3次时就直接报异常 不再让addbatch操作 job直接报错停掉
//包括clickhouse也是如果试了多个节点都不行,则说明sink端故障,直接停到job
if (i >= executionOptions.getMaxRetries()) {
throw new IOException(e);
}
try {
reestablishConnection(true);
} catch (Exception excpetion) {
LOG.error(
"JDBC connection is not valid, and reestablish connection failed.",
excpetion);
throw new IOException("Reestablish JDBC connection failed", excpetion);
}
try {
Thread.sleep(1000 * i);
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
throw new IOException(
"unable to flush; interrupted while doing another attempt", e);
}
}
}
//每写完一批数据都重新建立连接
try {
reestablishConnection(false);
} catch (Exception e) {
throw new IOException("Reestablish JDBC connection failed", e);
}
}
reestablishConnection(boolean hasException):
一般地,如果在flush时出现了异常,则重新创建连接重试写数据
对于clickhouse 则每次写完批之后,都重新建立一次连接,给下一个节点写做准备
//todo:性能问题:对于clickhouse 每批次的数据可能比较少可能会造成频繁切换数据库连接的问题
private void reestablishConnection(boolean hasException) throws Exception {
//轮询写clickhouse本地表单独适配
//如果发生了单点故障,即有数据没有落库,缓存到了flink 此时要换一个节点
if (connectionProvider.isWriteLocalClickhouse()) {
for (int i = 0; i <= executionOptions.getMaxRetries(); i++) {
try {
connection = connectionProvider.reestablishConnection();
jdbcStatementExecutor.closeStatements();
jdbcStatementExecutor.prepareStatements(connection);
return;
} catch (Exception e) {
e.printStackTrace();
LOG.warn("Clickhouse connection is not valid, reestablish next connection, try times " + i + "/" + executionOptions.getMaxRetries() + ", err: " + e.getMessage());
}
}
throw new IOException("Reestablish Clickhouse connection failed.");
} else if (hasException && !connection.isValid(CONNECTION_CHECK_TIMEOUT_SECONDS)) {
connection = connectionProvider.reestablishConnection();
jdbcStatementExecutor.closeStatements();
jdbcStatementExecutor.prepareStatements(connection);
}
}
/** * todo learned:flink官方的本意是如果flush数据到数据库报错,就重试三次: * 具体的,重新建立连接然后再重试flush,如果建立连接失败,则直接(记录)抛异常让addbatch(抛出异常)等操作停止,表现会将job kill掉 * 因为此时flink会认为数据库的连接有问题,为了避免大量的连接以及上游数据堆积浪费资源,所以此时写数据就失效了。 * <p> * ck也遵循flink的逻辑:多个节点轮询写,如果连接建立失败(单点故障假设),那选择另外一个节点继续flush写数据, * 如果重试遍历了所有的节点都不能写,已经表明sink端故障,那就kill 掉 job。 */
private void checkFlushException() {
if (flushException != null) {
throw new RuntimeException("Writing records to JDBC failed.", flushException);
}
}
加一些日志,我们看一下clickhouse对于轮询写是如何触发异常,导致job失败的:
2022-08-03 16:25:46,782 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 13
2022-08-03 16:25:47,785 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:47,786 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 14
2022-08-03 16:25:48,975 INFO org.apache.flink.connector.jdbc.internal.connection.SimpleJdbcConnectionProvider [] - getConnection get dbUrls jdbc:clickhouse://10.0.1.127:18100/shard_3?socket_timeout=900000
2022-08-03 16:25:49,085 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:49,085 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 0
2022-08-03 16:25:49,794 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:49,795 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 1
2022-08-03 16:25:50,795 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:50,795 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 2
2022-08-03 16:25:51,800 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:51,800 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 3
2022-08-03 16:25:52,804 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:52,804 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 4
2022-08-03 16:25:53,810 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:53,810 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 5
2022-08-03 16:25:54,814 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:54,814 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 6
2022-08-03 16:25:55,817 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:55,818 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 7
2022-08-03 16:25:56,822 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:56,822 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 8
2022-08-03 16:25:57,826 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:57,827 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 9
2022-08-03 16:25:58,832 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:58,833 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 10
2022-08-03 16:25:59,285 INFO org.apache.flink.connector.jdbc.internal.connection.SimpleJdbcConnectionProvider [] - getConnection get dbUrls jdbc:clickhouse://10.0.1.125:18100/shard_1?socket_timeout=900000
2022-08-03 16:25:59,836 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:25:59,836 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 0
2022-08-03 16:26:00,838 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:00,838 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 1
2022-08-03 16:26:01,844 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:01,844 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 2
2022-08-03 16:26:02,846 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:02,846 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 3
2022-08-03 16:26:03,851 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:03,852 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 4
2022-08-03 16:26:04,853 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:04,853 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 5
2022-08-03 16:26:05,857 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:05,857 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 6
2022-08-03 16:26:06,860 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:06,860 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 7
2022-08-03 16:26:07,867 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:07,867 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 8
2022-08-03 16:26:08,870 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:08,870 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 9
2022-08-03 16:26:10,576 INFO org.apache.flink.connector.jdbc.internal.connection.SimpleJdbcConnectionProvider [] - getConnection get dbUrls jdbc:clickhouse://10.0.1.126:18100/shard_2?socket_timeout=900000
2022-08-03 16:26:11,247 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:11,247 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 0
2022-08-03 16:26:11,251 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:11,251 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 1
2022-08-03 16:26:11,878 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:11,878 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 2
2022-08-03 16:26:12,883 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:12,883 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 3
2022-08-03 16:26:13,885 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:13,885 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 4
2022-08-03 16:26:14,889 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:14,889 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 5
2022-08-03 16:26:15,896 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:15,896 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 6
2022-08-03 16:26:16,899 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:16,900 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 7
2022-08-03 16:26:17,903 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:17,903 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 8
2022-08-03 16:26:18,915 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:18,916 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 9
2022-08-03 16:26:19,911 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:19,911 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 10
2022-08-03 16:26:20,911 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:20,911 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 11
2022-08-03 16:26:22,079 INFO org.apache.flink.connector.jdbc.internal.connection.SimpleJdbcConnectionProvider [] - getConnection get dbUrls jdbc:clickhouse://10.0.1.127:18100/shard_3?socket_timeout=900000
2022-08-03 16:26:22,641 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:22,641 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 0
2022-08-03 16:26:22,919 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:22,919 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 1
2022-08-03 16:26:23,923 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:23,923 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 2
2022-08-03 16:26:24,926 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:24,926 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 3
2022-08-03 16:26:25,930 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:25,930 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 4
2022-08-03 16:26:26,935 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - writeRecord prepare to addToBatch
2022-08-03 16:26:26,935 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - prepare to addToBatch batchCount= 5
//写了五条数据到flink缓存中,然后切换了ck的节点
2022-08-03 16:26:33,411 INFO org.apache.flink.connector.jdbc.internal.connection.SimpleJdbcConnectionProvider [] - getConnection get dbUrls jdbc:clickhouse://10.0.1.125:18100/shard_1?socket_timeout=900000
2022-08-03 16:26:44,614 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - JDBC executeBatch error, retry times = 0
java.sql.SQLException: Please call addBatch method at least once before batch execution
at com.clickhouse.jdbc.SqlExceptionUtils.clientError(SqlExceptionUtils.java:43) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.SqlExceptionUtils.emptyBatchError(SqlExceptionUtils.java:111) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.InputBasedPreparedStatement.executeAny(InputBasedPreparedStatement.java:97) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.AbstractPreparedStatement.executeLargeBatch(AbstractPreparedStatement.java:85) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.ClickHouseStatementImpl.executeBatch(ClickHouseStatementImpl.java:577) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at org.apache.flink.connector.jdbc.statement.FieldNamedPreparedStatementImpl.executeBatch(FieldNamedPreparedStatementImpl.java:122) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableSimpleStatementExecutor.executeBatch(TableSimpleStatementExecutor.java:64) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableBufferedStatementExecutor.executeBatch(TableBufferedStatementExecutor.java:67) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.attemptFlush(JdbcBatchingOutputFormat.java:258) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.flush(JdbcBatchingOutputFormat.java:202) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.lambda$open$0(JdbcBatchingOutputFormat.java:135) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_271]
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_271]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_271]
2022-08-03 16:26:44,624 INFO org.apache.flink.connector.jdbc.internal.connection.SimpleJdbcConnectionProvider [] - getConnection get dbUrls jdbc:clickhouse://10.0.1.126:18100/shard_2?socket_timeout=900000
2022-08-03 16:26:44,768 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - JDBC executeBatch error, retry times = 1
java.sql.SQLException: Please call addBatch method at least once before batch execution
at com.clickhouse.jdbc.SqlExceptionUtils.clientError(SqlExceptionUtils.java:43) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.SqlExceptionUtils.emptyBatchError(SqlExceptionUtils.java:111) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.InputBasedPreparedStatement.executeAny(InputBasedPreparedStatement.java:97) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.AbstractPreparedStatement.executeLargeBatch(AbstractPreparedStatement.java:85) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.ClickHouseStatementImpl.executeBatch(ClickHouseStatementImpl.java:577) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at org.apache.flink.connector.jdbc.statement.FieldNamedPreparedStatementImpl.executeBatch(FieldNamedPreparedStatementImpl.java:122) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableSimpleStatementExecutor.executeBatch(TableSimpleStatementExecutor.java:64) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableBufferedStatementExecutor.executeBatch(TableBufferedStatementExecutor.java:67) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.attemptFlush(JdbcBatchingOutputFormat.java:258) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.flush(JdbcBatchingOutputFormat.java:202) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.lambda$open$0(JdbcBatchingOutputFormat.java:135) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_271]
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_271]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_271]
2022-08-03 16:26:44,769 INFO org.apache.flink.connector.jdbc.internal.connection.SimpleJdbcConnectionProvider [] - getConnection get dbUrls jdbc:clickhouse://10.0.1.127:18100/shard_3?socket_timeout=900000
2022-08-03 16:26:45,908 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - JDBC executeBatch error, retry times = 2
java.sql.SQLException: Please call addBatch method at least once before batch execution
at com.clickhouse.jdbc.SqlExceptionUtils.clientError(SqlExceptionUtils.java:43) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.SqlExceptionUtils.emptyBatchError(SqlExceptionUtils.java:111) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.InputBasedPreparedStatement.executeAny(InputBasedPreparedStatement.java:97) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.AbstractPreparedStatement.executeLargeBatch(AbstractPreparedStatement.java:85) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.ClickHouseStatementImpl.executeBatch(ClickHouseStatementImpl.java:577) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at org.apache.flink.connector.jdbc.statement.FieldNamedPreparedStatementImpl.executeBatch(FieldNamedPreparedStatementImpl.java:122) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableSimpleStatementExecutor.executeBatch(TableSimpleStatementExecutor.java:64) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableBufferedStatementExecutor.executeBatch(TableBufferedStatementExecutor.java:67) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.attemptFlush(JdbcBatchingOutputFormat.java:258) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.flush(JdbcBatchingOutputFormat.java:202) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.lambda$open$0(JdbcBatchingOutputFormat.java:135) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_271]
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_271]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_271]
2022-08-03 16:26:45,909 INFO org.apache.flink.connector.jdbc.internal.connection.SimpleJdbcConnectionProvider [] - getConnection get dbUrls jdbc:clickhouse://10.0.1.125:18100/shard_1?socket_timeout=900000
2022-08-03 16:26:48,248 ERROR org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat [] - JDBC executeBatch error, retry times = 3
java.sql.SQLException: Please call addBatch method at least once before batch execution
at com.clickhouse.jdbc.SqlExceptionUtils.clientError(SqlExceptionUtils.java:43) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.SqlExceptionUtils.emptyBatchError(SqlExceptionUtils.java:111) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.InputBasedPreparedStatement.executeAny(InputBasedPreparedStatement.java:97) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.AbstractPreparedStatement.executeLargeBatch(AbstractPreparedStatement.java:85) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at com.clickhouse.jdbc.internal.ClickHouseStatementImpl.executeBatch(ClickHouseStatementImpl.java:577) ~[clickhouse-jdbc-0.3.2-patch10.jar:clickhouse-jdbc 0.3.2-patch10 (revision: aebad16)]
at org.apache.flink.connector.jdbc.statement.FieldNamedPreparedStatementImpl.executeBatch(FieldNamedPreparedStatementImpl.java:122) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableSimpleStatementExecutor.executeBatch(TableSimpleStatementExecutor.java:64) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.executor.TableBufferedStatementExecutor.executeBatch(TableBufferedStatementExecutor.java:67) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.attemptFlush(JdbcBatchingOutputFormat.java:258) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.flush(JdbcBatchingOutputFormat.java:202) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at org.apache.flink.connector.jdbc.internal.JdbcBatchingOutputFormat.lambda$open$0(JdbcBatchingOutputFormat.java:135) ~[datalake-connector-jdbc_2.11-1.12.5.jar:5.4.1]
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) ~[?:1.8.0_271]
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) ~[?:1.8.0_271]
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_271]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_271]
at java.lang.Thread.run(Thread.java:748) ~[?:1.8.0_271]
当上游算子(这里是kafka)有数据传输到下游时,ck sink 开始执行open,然后write写数据。
此时我停止kafka生产数据,此时ck sink开始报错:具体原因是因为没有数据写入(addBatch),但是执行了sink(executeBatch),导致报错:java.sql.SQLException: Please call addBatch method at least once before batch execution
但是job没有挂掉,继续运行,可以看到flink在切换节点开始重试,但是结果我们知道重试失败,且记录下了flushException,具体地,根据上面的分析(flink已经认定服务器有问题了),此时任务已经是名存实亡。
此时我再往kafka里写数据,当sink接收到数据,还没开始处理直接判断checkFlushException(), job直接失败。
分析到这里修改方案很简单,如下加入buffer判断:如果为空就不flush
//TableBufferedStatementExecutor.executeBatch
@Override
public void executeBatch() throws SQLException {
if (buffer.isEmpty()) {
return;
}
//遍历写 然后一条一条的加入到batch中
for (RowData value : buffer) {
statementExecutor.addToBatch(value);
}
statementExecutor.executeBatch();
buffer.clear();
}
三. 解决改造留下的性能问题
1. clickhouse轮询写“空转”问题
通过上面的分析,当ScheduledThreadPoolExecutor执行clickhouse写数据的定时任务时,假设没有缓存数据到flink此时数据是空的,然后开始执行定时任务,重试一定次数之后,虽然定时任务执行成功,但其实没有flush数据,且每次都会在另外的节点重新建立连接。
如果有一段时间就是没有数据的,那么这段时间会造成大量的重连操作,造成资源浪费。
所以还需要判断,如果没有缓存数据,那么直接跳过定时任务,具体代码见:
//JdbcBatchingOutputFormat.flush
@Override
public synchronized void flush() throws IOException {
//如果batchcount=0,则说明没有addbatch的数据
//也就不执行下面的操作 以免clickhouse创建过多的jdbc连接(每次定时执行都会执行三次,如果定时设置的很短则会创建大量的连接)
if (batchCount == 0) {
return;
}
checkFlushException();
。。。。
}
2. with参数与clickhouse轮询写
再回顾一下sink下的with参数,这次我们按照clickhouse轮询写的逻辑去看两个场景
'sink.buffer-flush.max-rows' = '10000',
'sink.buffer-flush.interval' = '3s',
'sink.max-retries' = '3',
场景1:
如果上游数据传输的很慢,比如 5 条/s,那出现的现象就是,每3秒刷新15条数据到ck,然后轮询下一个节点,继续刷新15条到下一个节点。。。也就是说:每15条数据轮询一个节点。。。太浪费性能了。
场景2:
假设一个分布式表对应有5个节点的shard,此时有四个节点突然都挂掉了,根据前面的分析以及上面的配置,我们知道flink会重试3次就行数据的flush,但是我们有5个节点,此时可能出现的情况就是,因为没有遍历到正常的节点,导致job直接挂掉了。
3. 小结
通过以上两个clickhouse写数据的场景分析,我们可以有以下调优思路:
对于场景1:
当上游数据传输慢时,我们可以调大
sink.buffer-flush.interval让数据多存一会儿,然后再轮询写节点
当上游数据传输快时,我们可以调大sink.buffer-flush.max-rows提高轮询效率。
对于场景2:
假设shard节点数为n,那么我们可以设置为:
sink.max-retries = n-1,即完全发挥出单点故障的能力。
边栏推荐
- typescript56 - generic interface
- Please refer to dump files (if any exist) [date].dump, [date]-jvmRun[N].dump and [date].dumpstream.
- Is there any jdbc link to Youxuan database documentation and examples?
- 【日志框架】
- 谁说程序员不懂浪漫,表白代码来啦~
- 观察者模式
- 动态内存二
- Apache DolphinScheduler新一代分布式工作流任务调度平台实战-中
- 咱们500万条数据测试一下,如何合理使用索引加速?
- typescript51 - basic use of generics
猜你喜欢

typescript51-泛型的基本使用
分析:Nomad Bridge黑客攻击的独特之处
Vant3—— 点击对应的name名称跳转到下一页对应的tab栏的name的位置
![Please refer to dump files (if any exist) [date].dump, [date]-jvmRun[N].dump and [date].dumpstream.](/img/10/87c0bedd49b5dce6fbcd28ac361145.png)
Please refer to dump files (if any exist) [date].dump, [date]-jvmRun[N].dump and [date].dumpstream.

阿里云技术专家邓青琳:云上跨可用区容灾和异地多活最佳实践
114. How to find the cause of Fiori Launchpad routing error by single-step debugging
Quickly build a website with static files
nodejs安装及环境配置

nodejs+express实现数据库mysql的访问,并展示数据到页面上

Demand analysis of MES management system in electronic assembly industry
随机推荐
手撕Gateway源码,今日撕工作流程、负载均衡源码
MongoDB数据接入实践
typescript54 - generic constraints
nodejs切换版本使用(不需要卸载重装)
dynamic memory two
pygame 中的transform模块
C# WPF设备监控软件(经典)-下篇
Is there any jdbc link to Youxuan database documentation and examples?
NLP resources that must be used for projects [Classified Edition]
MySQL回表指的是什么
typescript48-函数之间的类型兼容性
咱们500万条数据测试一下,如何合理使用索引加速?
哎,又跟HR在小群吵了一架!
What warehouse management problems can WMS warehouse management system solve in the electronics industry?
Sticker Spelling - Memory Search / Shape Pressure DP
如何用C语言代码实现商品管理系统开发
研究生新生培训第四周:MobileNetV1, V2, V3
GNSS【0】- 专题
C # WPF equipment monitoring software (classic) - the next
typescript50 - type specification between cross types and interfaces