当前位置:网站首页>Spark学习(2)-Spark环境搭建-Local
Spark学习(2)-Spark环境搭建-Local
2022-07-31 14:06:00 【-------江湖-------】
1 基本原理
本质:启动一个JVM Process进程(一个进程里面有多个线程),执行任务Task。
- Local模式可以限制模拟Spark集群环境的线程数量, 即
Local[N]或Local[*]。 - 其中N代表可以使用N个线程,每个线程拥有一个cpu core。如果不指定N,则默认是1个线程(该线程有1个core)。 通常Cpu有几个Core,就指定几个线程,最大化利用计算能力。
- 如果是local[*],则代表按照Cpu最多的Cores设置线程数。
Local 下的角色分布:
- 资源管理:
Master:Local进程本身
Worker:Local进程本身 - 任务执行:
Driver:Local进程本身
Executor:不存在,没有独立的Executor角色, 由Local进程(也就是Driver)内的线程提供计算能力
PS: Driver也算一种特殊的Executor, 只不过多数时候, 我们将Executor当做纯Worker对待, 这样和Driver好区分(一类是管理 一类是工人)。
注意: Local模式只能运行一个Spark程序, 如果执行多个Spark程序, 那就是由多个相互独立的Local进程在执行。
2 搭建
2.1 下载地址
2.2 条件
- Python推荐3.8
- JDK 1.8
2.3 Anaconda On Linux 安装
2.4 解压
解压下载的Spark安装包
`tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /export/server/`
2.5 环境变量
配置Spark由如下5个环境变量需要设置:
SPARK_HOME: 表示Spark安装路径在哪里PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器JAVA_HOME: 告知Spark Java在哪里HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里HADOOP_HOME: 告知Spark Hadoop安装在哪里
这5个环境变量 都需要配置在: /etc/profile中:
PYSPARK_PYTHON和 JAVA_HOME 需要同样配置在: /root/.bashrc中:
2.6 设置软链接
ln -s /export/server/spark-3.2.0-bin-hadoop3.2 /export/server/spark


2.7 测试
bin/pyspark
bin/pyspark 程序, 可以提供一个 交互式的 Python解释器环境, 在这里面可以写普通python代码, 以及spark代码。
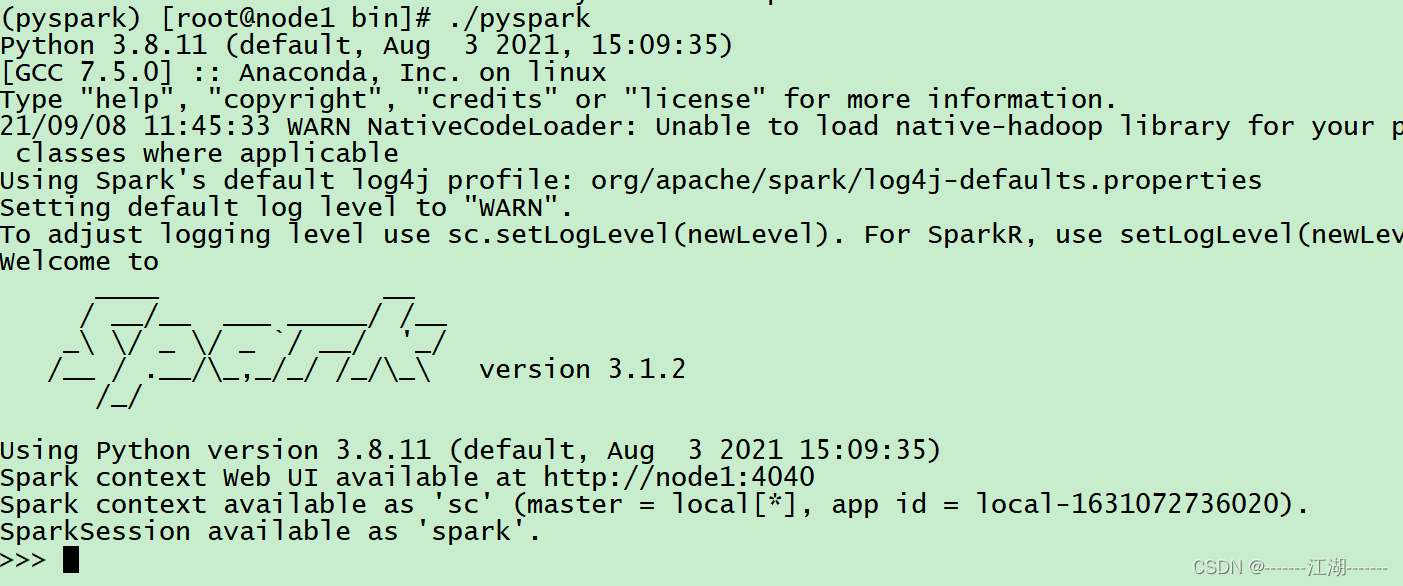
如图:
在这个环境内, 可以运行spark代码
图中的: parallelize 和 map 都是spark提供的APIsc.parallelize([1,2,3,4,5]).map(lambda x: x + 1).collect()
2.8 WEB UI (4040)
Spark程序在运行的时候, 会绑定到机器的4040端口上,如果4040端口被占用, 会顺延到4041 … 4042…
4040端口是一个WEBUI端口, 可以在浏览器内打开:
输入:服务器ip:4040 即可打开:
打开监控页面后, 可以发现 在程序内仅有一个Driver,因为我们是Local模式, Driver即管理 又 干活。
同时, 输入jps:
可以看到local模式下的唯一进程存在,这个进程 即是master也是worker。
2.9 bin/spark-shell
同样是一个解释器环境, 和bin/pyspark不同的是, 这个解释器环境 运行的不是python代码, 而是scala程序代码。
scala> sc.parallelize(Array(1,2,3,4,5)).map(x=> x + 1).collect()
res0: Array[Int] = Array(2, 3, 4, 5, 6)
这个是用于scala语言的解释器环境。
2.10 bin/spark-submit (PI)
作用: 提交指定的Spark代码到Spark环境中运行。
使用方法:
# 语法
bin/spark-submit [可选的一些选项] jar包或者python代码的路径 [代码的参数]
# 示例
bin/spark-submit /export/server/spark/examples/src/main/python/pi.py 10
# 此案例 运行Spark官方所提供的示例代码 来计算圆周率值. 后面的10 是主函数接受的参数, 数字越高, 计算圆周率越准确.
对比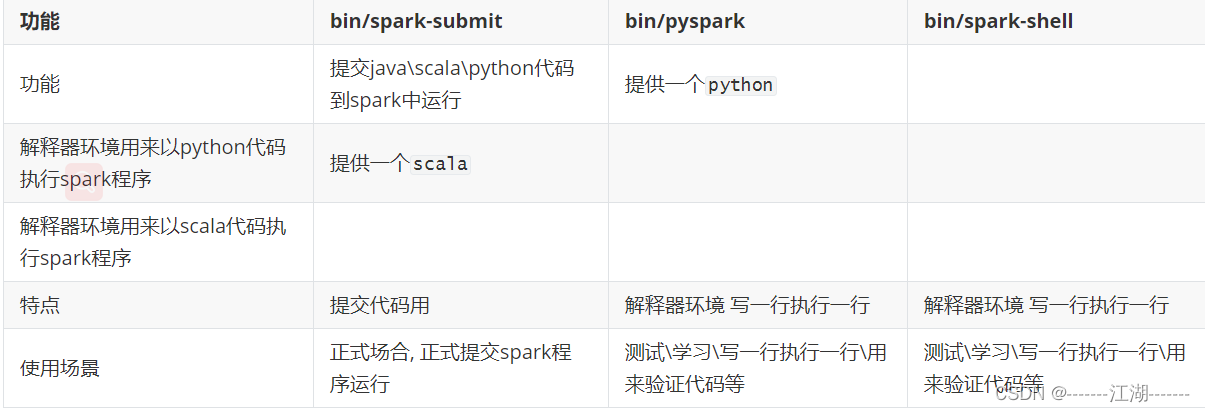
边栏推荐
- uniapp微信小程序引用标准版交易组件
- The 232-layer 3D flash memory chip is here: the single-chip capacity is 2TB, and the transmission speed is increased by 50%
- AWS实现定时任务-Lambda+EventBridge
- 【Pytorch】torch.argmax()用法
- 页面整屏滚动效果
- 一篇文章讲清楚!数据库和数据仓库到底有什么区别和联系?
- 线程池的使用二
- C# Get network card information NetworkInterface IPInterfaceProperties
- Shell script classic case: detecting whether a batch of hosts is alive
- Numbers that appear only once in LeetCode
猜你喜欢

C# control ListView usage
AI cocoa AI frontier introduction (7.31)
AWS implements scheduled tasks - Lambda+EventBridge

为什么要分库分表?

Five dimensions to start MySQL optimization

技能大赛训练题:MS15_034漏洞验证与安全加固

Motion capture system for end-positioning control of flexible manipulators

Even if the image is missing in a large area, it can also be repaired realistically. The new model CM-GAN takes into account the global structure and texture details

1小时直播招募令:行业大咖干货分享,企业报名开启丨量子位·视点

技能大赛训练题:ftp 服务攻防与加固
随机推荐
最近很火的国产接口神器Apipost体验
All-round visual monitoring of the Istio microservice governance grid (microservice architecture display, resource monitoring, traffic monitoring, link monitoring)
jvm 一之 类加载器
为什么 wireguard-go 高尚而 boringtun 孬种
LeetCode rotate array
ICML2022 | Fully Granular Self-Semantic Propagation for Self-Supervised Graph Representation Learning
Detailed guide to compare two tables using natural full join in SQL
uniapp微信小程序引用标准版交易组件
Spark Learning: Add Custom Optimization Rules for Spark Sql
Controller层代码这么写,简洁又优雅!
The recently popular domestic interface artifact Apipost experience
Shell脚本经典案例:文件的备份
“听我说谢谢你”还能用古诗来说?清华搞了个“据意查句”神器,一键搜索你想要的名言警句...
使用CompletableFuture进行异步处理业务
新款现代帕里斯帝预售开启,安全、舒适一个不落
【Pytorch】F.softmax()方法说明
ADS communicate with c #
技能大赛训练题:MS15_034漏洞验证与安全加固
leetcode: 485. Maximum number of consecutive 1s
MySQL 23道经典面试吊打面试官