当前位置:网站首页>[medical segmentation] u2net
[medical segmentation] u2net
2022-07-01 05:38:00 【Coke Daniel】
summary
u2net Is in unet Based on , It is a very effective saliency target detection model .
Significance target detection : Segment the main body of the image .
The model proposed Main background It's two parts :
1、 Split tasks backbone Mainly some pre training models . Because of some segmentation backbone The effect of is not as good as that of the pre training model , So we all use the pre training model . problem : They are not designed for segmentation , Insufficient attention has been paid to the key local details and global comparison information in the segmentation task , So if you want to better adapt to segmentation, you need to add some special structures on this basis , Achieve better use of the extracted features , This brings computational complexity .
2、 The model is generally deep , Considering the overhead of video memory and Computing , We will first do some down sampling operations on the pictures in the top layers , Reduce resolution . problem : In fact, for split tasks , The rich spatial information in high-resolution images needs to be made good use of .
u2net Successfully solved these two problems , A two-level nested u Shape structure , The network can be trained from scratch without relying on the pre training model , The effect of feature extraction is as good as the pre training model , And no additional structure is needed to deal with these features . In addition, after the network deepens , It can also maintain high resolution ( because RSU A large number of pooling operations in ), And the overhead of video memory and computation is also very friendly .
details
Network structure
The following is u2net Network structure , In general, it's still unet Of u Shape structure , But every layer or every stage from unet The simple convolution structure in becomes RUS(Residual U-blocks), Then each decoder The side outputs of all receive gt Supervision of , All side outputs do concat after , The convolution operation is the final network output .
Previous studies have also included stacking or cascading unet obtain u ∗ n − n e t u*n-net u∗n−net, But the author is nested or exponential unuet Went to the , Obviously, the number of nesting can be very large , namely u n n e t u^n net unnet, But considering the actual situation , Or nest one layer to get u 2 n e t u^2 net u2net
Then each RSU The number of layers of encoder With the increase of the number of layers , namely En_1、En_2、En_3、En_4 The used are RSU-7、RSU-6、RSU-5、RSU-4, Because we attach importance to the feature extraction of high-resolution feature map , Pool operation will be performed at the same time , Reduce size . and En_5、En_6 What we use is RSU-4F 了 ,F It means that the size will not change , That is, only feature extraction .
RSU(Residual U-blocks)
RUS To replace the unet Simple convolution block in , It can better capture the overall and local information , And in the past 1x1,3x3 Convolution due to receptive field , Often good at capturing local information , The capture of global information is not so good , And the global information is often needed for segmentation .RUS Through this u The shape structure realizes the mixing of characteristic maps of different scales and different receptive fields , It can capture global information from more different scales .
And he also used the idea of residuals .resnet You need at least two levels in order to do identity mapping , Or we'll do a linear transformation , and n The linear change effect of degree is equivalent to 1 Linear transformation of degree . And in this article , Because of this u-block It contains several layers , So cross one block That's it .
Then there is the calculation quantity , The author compares some mainstream block structures , Discover though RSU The amount of calculation is linear with the increase of depth , But the coefficient is very small , Therefore, the amount of calculation is not very large , It can be stacked very deep .
Loss
There are mainly two parts , One part is the loss of side output characteristic graph , The other part is the loss of the final output feature map formed after the fusion of these side outputs .

边栏推荐
- Flutter 实现每次进来界面都刷新数据
- Redis数据库的部署及常用命令
- CentOS 7使用yum安装PHP7.0
- 【医学分割】u2net
- Basic electrician knowledge 100 questions
- Is it safe for a novice to open a securities account?
- Deeply understand the underlying implementation principle of countdownlatch in concurrent programming
- 2/15 (awk, awk conditions, awk processing design can perform additional tasks, and use awk array +for loop to realize advanced search)
- Trust guessing numbers game
- College community management system based on boot+jsp (with source code download link)
猜你喜欢

CockroachDB: The Resilient Geo-Distributed SQL Database 论文阅读笔记

【QT】qt加减乘除之后,保留小数点后两位

Summary of spanner's paper
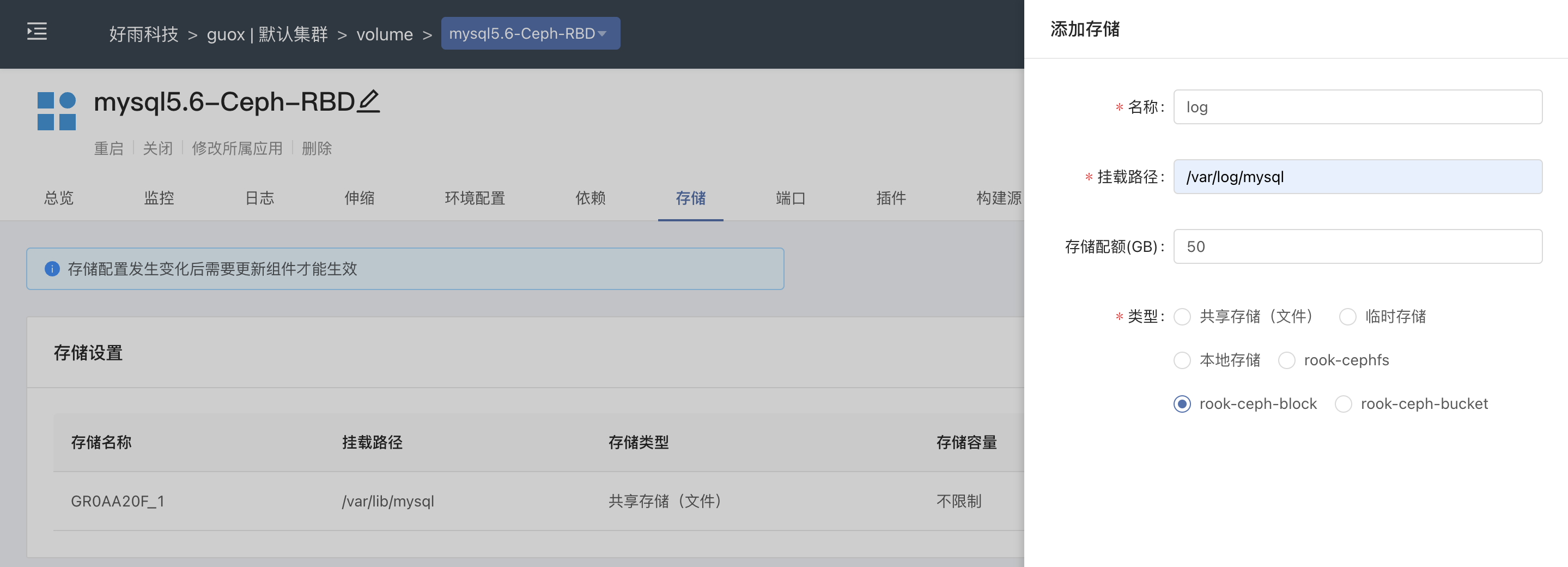
Practice of combining rook CEPH and rainbow, a cloud native storage solution

What is the at instruction set often used in the development of IOT devices?
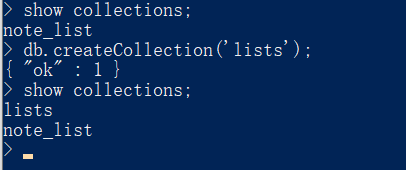
Mongodb學習篇:安裝後的入門第一課

LevelDB源码分析之LRU Cache
【医学分割】u2net

Day 05 - file operation function

Unity项目心得总结
随机推荐
Lock free concurrency of JUC (leguan lock)
Unity uses SQLite
Design and application of immutable classes
QT等待框制作
Use and principle of AQS related implementation classes
Data governance: data governance framework (Part I)
[RootersCTF2019]babyWeb
第05天-文件操作函数
[ffmpeg] [reprint] image mosaic: picture in picture with wheat
【问题思考总结】为什么寄存器清零是在用户态进行的?
Is it safe for a novice to open a securities account?
Usage and principle of synchronized
多表操作-外键级联操作
云原生存储解决方案Rook-Ceph与Rainbond结合的实践
Trust guessing numbers game
如何创建一个根据进度改变颜色的进度条
Actual combat: basic use of Redux
HDU - 1024 Max Sum Plus Plus(DP)
In depth understanding of condition source code interpretation and analysis of concurrent programming
tar命令