当前位置:网站首页>The k-nearest neighbor method in the notes of Li Hang's "Statistical Learning Methods"
The k-nearest neighbor method in the notes of Li Hang's "Statistical Learning Methods"
2022-08-02 09:32:00 【timerring】

第三章 k近邻法
1.Samples with the same label usually have many similar features,So the same category may get together phenomenon,也就是物以类聚.
2.Every sample comes in,We look at what class the samples around it are,Then it is also very likely to fall into this category.
距离度量Distance measure
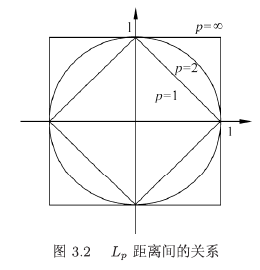
首先令 $ x_{i}=\left(x_{i}^{(1)}, x_{i}^{(2)}, \ldots, x_{i}^{(n)}\right), x_{j}=\left(x_{j}^{(1)}, x_{j}^{(2)}, \ldots, x_{j}^{(n)}\right) $
欧式距离(Also called two-norm):
L 2 ( x i , x j ) = ( ∑ i = 1 n ∣ x i ( l ) − x j ( l ) ∣ 2 ) 1 2 L_{2}\left(x_{i}, x_{j}\right)=\left(\sum_{i=1}^{n}\left|x_{i}^{(l)}-x_{j}^{(l)}\right|^{2}\right)^{\frac{1}{2}} L2(xi,xj)=(∑i=1n∣∣xi(l)−xj(l)∣∣2)21
曼哈顿距离(Also called a norm):
L 1 ( x i , x j ) = ∑ i = 1 n ∣ x i ( l ) − x j ( l ) ∣ L_{1}\left(x_{i}, x_{j}\right)=\sum_{i=1}^{n}\left|x_{i}^{(l)}-x_{j}^{(l)}\right| L1(xi,xj)=∑i=1n∣∣xi(l)−xj(l)∣∣
P范数:
L p ( x i , x j ) = ( ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ p ) 1 p L_{\mathrm{p}}\left(x_{i}, x_{j}\right)=\left(\sum_{l=1}^{n}\left|x_{i}^{(l)}-x_{j}^{(l)}\right|^{p}\right)^{\frac{1}{p}} Lp(xi,xj)=(∑l=1n∣∣xi(l)−xj(l)∣∣p)p1
切比雪夫距离(Similar to the queen of chess)
当 p = ∞ p=\infty p=∞ 时, 它是各个坐标距离的最大值, 即
L ∞ ( x i , x j ) = max l ∣ x i ( l ) − x j ( l ) ∣ L_{\infty}\left(x_{i}, x_{j}\right)=\max _{l}\left|x_{i}^{(l)}-x_{j}^{(l)}\right| L∞(xi,xj)=maxl∣∣xi(l)−xj(l)∣∣

k值的选择
k值的选择会对k近邻法的结果产生重大影响.
如果选择较小的k值,就相当于用较小的邻域中的训练实例进行预测,“学习”的近似误差(approximation error)会减小,只有与输入实例较近的(相似的)训练实例才会对预测结果起作用.但缺点是“学习”的估计误差(estimation error)会增大,预测结果会对近邻的实例点非常敏感.如果邻近的实例点恰巧是噪声,预测就会出错.换句话说,k值的减小就意味着整体模型变得复杂,容易发生过拟合.
如果选择较大的k值,就相当于用较大邻域中的训练实例进行预测.其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大.这时与输入实例较远的(不相似的)训练实例也会对预测起作用,使预测发生错误.k值的增大就意味着整体的模型变得简单.
如果k =N,那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类.这时,模型过于简单,完全忽略训练实例中的大量有用信息,是不可取的.
在应用中,k值一般取一个比较小的数值.通常采用交叉验证法来选取最优的k值.
分类决策规则
k近邻法中的分类决策规则往往是多数表决,即由输入实例的k个邻近的训练实例中的多数类决定输入实例的类.
多数表决规则(majority voting rule)有如下解释:如果分类的损失函数为0-1损失函数.分类函数为:
f : R n → { c 1 , c 2 , ⋯ , c K } f: \mathbf{R}^{n} \rightarrow\left\{c_{1}, c_{2}, \cdots, c_{K}\right\} f:Rn→{ c1,c2,⋯,cK}
那么误分类的概率是
P ( Y ≠ f ( X ) ) = 1 − P ( Y = f ( X ) ) P(Y \neq f(X))=1-P(Y=f(X)) P(Y=f(X))=1−P(Y=f(X))
对给定的实例 $x \in \mathcal{X} $, 其最近邻的 k 个训练实例点构成集合 $ N_{k}(x) $ .如果涵盖 $N_{k}(x) $ 的区域的类别是 c j c_{j} cj , 那么误分类率是
1 k ∑ x i ∈ N k ( x ) I ( y i ≠ c j ) = 1 − 1 k ∑ x i ∈ N k ( x ) I ( y i = c j ) \frac{1}{k} \sum_{x_{i} \in N_{k}(x)} I\left(y_{i} \neq c_{j}\right)=1-\frac{1}{k} \sum_{x_{i} \in N_{k}(x)} I\left(y_{i}=c_{j}\right) k1∑xi∈Nk(x)I(yi=cj)=1−k1∑xi∈Nk(x)I(yi=cj)
要使误分类率最小即经验风险最小, 就要使 $ \sum_{x_{i} \in N_{k}(x)} I\left(y_{i}=c_{j}\right) $ 最大, 所以多数表决规则等价于经验风险最小化.
注意: I ( x ) I\left(x\right) I(x)为指示函数,即x条件为真,则函数值为1,x条件为假,则函数值为0.
总结Summarization
K近邻思想:物以类聚
K近邻没有显式的训练过程(A distance metric is calculated between the new sample and the original sample)
距离度量:
(1)欧式距离:A straight line between two points(2)曼哈顿距离:City block distance
(3)切比雪夫距离:棋盘距离
分类决策规则:多数表决
边栏推荐
猜你喜欢






随机推荐
nacos项目搭建
Pycharm (1) the basic use of tutorial
线程池的使用及ThreadPoolExecutor源码分析
软件exe图标变记事本或浏览器、360压缩打不开的几种应急解决方法
智能网络安全网卡|这是不是你要的安全感
spark:商品热门品类TOP10统计(案例)
HikariCP数据库连接池,太快了!
AutoJs学习-存款计算器
RetinaFace: Single-stage Dense Face Localisation in the Wild
typeinfo类型支持库学习
自定义View实现波浪荡漾效果
边缘计算开源项目概述
Jenkins--基础--6.1--Pipeline--介绍
YugaByte adds Voyager migration service in its 2.15 database update
mysql进阶(二十一)删除表数据与数据库四大特性
在 QT Creator 上配置 opencv 环境的一些认识和注意点
Re23:读论文 How Does NLP Benefit Legal System: A Summary of Legal Artificial Intelligence
Rust from entry to master 03-helloworld
二维数组零碎知识梳理
Scala类型转换