当前位置:网站首页>Distill knowledge from the interaction model! China University of science and Technology & meituan proposed virt, which combines the efficiency of the two tower model and the performance of the intera
Distill knowledge from the interaction model! China University of science and Technology & meituan proposed virt, which combines the efficiency of the two tower model and the performance of the intera
2022-07-06 18:11:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
This sharing paper 『VIRT: Improving Representation-based Models for Text Matching through Virtual Interaction』, Distill knowledge from interaction model ! China University of science and technology & Meituan put forward VIRT, Both the efficiency of the two tower model and the performance of the interaction model , Achieve a balance between performance and efficiency in text matching !
The details are as follows :

Thesis link :https://arxiv.org/abs/2112.04195
01
Abstract
With pre training Transformer Vigorous development , Based on twins Transformer The representation model of encoder has become the mainstream technology of efficient text matching . However , Compared with the interaction based model , Due to the lack of interaction between text pairs , The performance of these models is seriously degraded . The existing technology attempts to solve this problem through additional interaction with the twin encoded representation , The interaction in the coding process is still ignored .
To solve this problem , The author puts forward a kind of Virtual interaction mechanism (VIRT), The interaction knowledge is transferred from the interaction based model to the twin coder through attention Graph Extraction .VIRT As a component for training runtime only , It can completely maintain the efficiency of twin structure , And it will not bring additional computational costs in the reasoning process . In order to make full use of the learned interactive knowledge , The author further designs an adaptation VIRT Interaction strategy .
Experimental results on multiple text matching datasets show that , The method in this paper is superior to the existing representation based model . Besides ,VIRT It can be easily integrated into existing representation based methods , To achieve further improvements .
02
Motivation
Text matching aims to model the semantic association between a pair of texts , This is a basic problem in the application of natural language understanding . for example , Ask and answer in the community (CQA) In the system , A key component is to find similar problems related to user problems from the database through problem matching . Similarly , Dialog agents need to make logical inference by predicting the implicit relationship between user statements and some predefined assumptions .
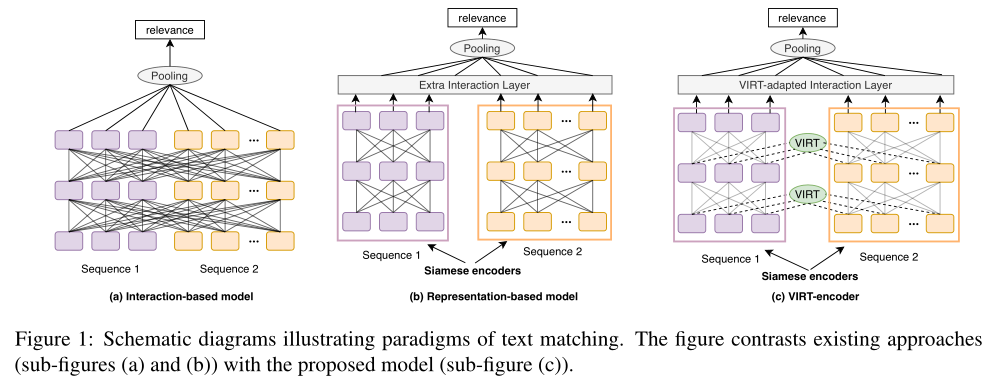
lately , Deep pre training Transformer Has made remarkable progress in text matching tasks . There are usually two based on fine tuning Transformer Example of encoder : Interaction based model ( Cross encoder ) And representation based models ( Double encoder ), Pictured above (a) and (b) Shown . Interaction based model ( for example ,BERT) Align text concat Is a single sequence , And perform complete interaction between text pairs . Although full interaction provides a rich matching signal from the bottom to the top of the model , But it also brings higher calculation cost and reasoning delay , This makes it difficult to deploy in actual scenarios .
for example , In an e-commerce search system , Because there are millions of good query pairs , It takes tens of days to grade these pairs using an interaction based model . contrary , The representation based model encodes text pairs independently by two twin encoders , Without any interaction . therefore , It supports embedded offline computing , This greatly reduces online latency , Thus, this kind of model is very useful in practice . Unfortunately , Independent coding without any interaction may lose the matching signal , This leads to a serious performance degradation .
To balance efficiency and effectiveness , Some work attempts to equip the twin structure with interaction modules . Various interaction strategies have been proposed , For example, attention level and Transformer layer . However , For efficiency , These interaction modules are added after the twin encoder , In order to preserve the twin character , The interaction in the coding process of twin encoder is still ignored . therefore , Rich interactive signals are lost , The existing representation based model still lags far behind the interaction based model in the following aspects .
In this work , The author tries to break the dilemma between interaction based model and representation based model . The key idea is in the representation based model , Without destroying the twin structure , Integrate the interaction in the twin coding process . So , The author proposes virtual interaction (VIRT), This is a new mechanism to transfer the knowledge in text pair interaction to the twin encoder based on the representation model .
say concretely , The twin coder learns the interactive information between the two texts by imitating the complete interaction , And guided by the knowledge transferred by the interaction based model . Knowledge transfer is realized as an attention graph extraction task in the training process , In the process of reasoning, the task can be deleted to maintain the twin characteristics . So it's called “ Virtual interaction ”. Besides , In order to further utilize the interactive knowledge learned after twin coding , The author designs an interactive strategy of virtual adaptation . In a program called VIRT The representation based model of the encoder jointly realizes VIRT and VIRT Adaptive interaction strategies , Pictured above (c) Shown .
In this paper, the contribution It can be summarized as follows :
The author proposes a new virtual interaction mechanism VIRT, By extracting attention maps from interaction based models , It is integrated into the twin encoder based on the representation model , Without additional reasoning costs .
A lot of experiments show that , What this article puts forward VIRT The encoder is better than that based on SOTA The model of representation , At the same time, the reasoning efficiency is maintained .
VIRT It can be easily integrated into other representation based text matching models , To further improve its performance .
03
Method
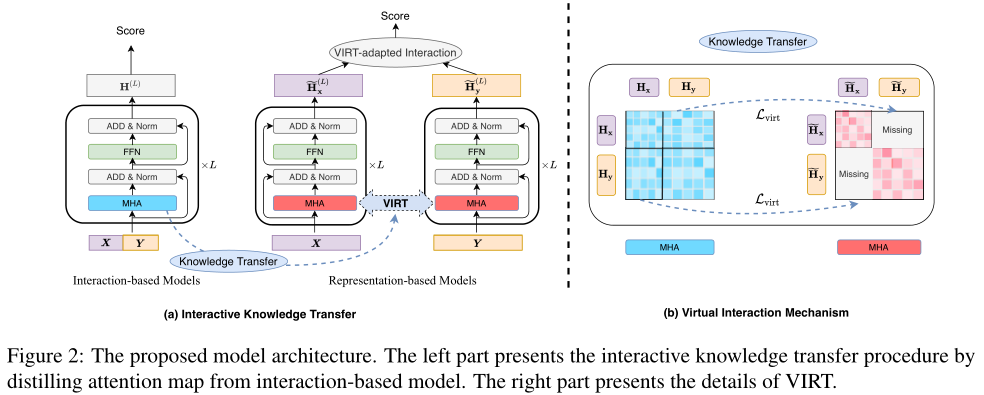
In this section , The author will first describe the interaction based model and the representation based model . then , Introduce the virtual interaction mechanism (VIRT), It extracts interaction knowledge from interaction based models to twin coders . Besides , adopt VIRT Adaptive interaction strategies , You can make full use of the interactive knowledge learned .VIRT The architecture of is shown in the figure above .
3.1 Interaction-based Models
Given two text sequences and as input , Interaction based models will X and Y concat by , And use L layer Transformer Encode :.Transformer Each layer of consists of two residual sublayers : A multi head attention operation (MHA) And a feedforward network (FFN):
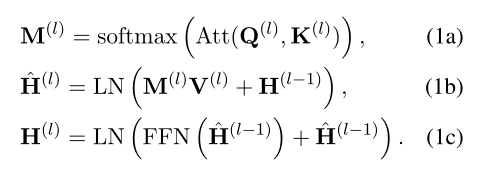
, among d Is the dimension of the hidden state . here , For the sake of description , omitted batch Dimensions of size and attention head .
402 Payment Required
It's No (l-1) The middle of the layer represents , It's right X and Y Code the interactive information between . and It's No l Attention parameter of layer , from From mapping . Express LayerNorm operation .You can see , The interaction based model can encode the interaction information into X and Y In the expression of . In particular , Combine representations to generate attention maps M, It represents the weight of different interaction signals . These expressions are based on M To choose and integrate .
3.2 Representation-based Models
Compared with the interaction based model , The representation based model first passes through two independent twins Transformer Encoders are respectively aligned X and Y Encoding ( It is assumed that each encoder has L individual Transformer layer ):,. then , They have additional interactions with twin encoded and .transformer The structure of is the same as the interaction based model , Just pay attention to the picture ( or ) Just use X( or Y) Calculated separately :
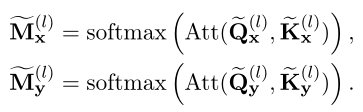
Compared with the interaction based model , In the coding process X and Y No interaction between . In a representation based model ,X and Y The fine-grained interaction information between them will be lost , This can lead to performance degradation .
3.3 Virtual Interaction
As mentioned earlier , The main disadvantage of the representation based model is the lack of interaction when encoding two input sequences separately . Intuitively speaking , The interaction based model passes MHA Mechanism performs interaction . By corresponding to X and Y To calculate . Compared with the interaction based model , The representation based model only passes X( or Y) Calculated separately ( or ). In the next section , We will first explain in detail the two models in MHA Operational differences . Next , It introduces VIRT Mechanism , It can improve the representation based model without adding additional reasoning cost .
First, decompose the... Based on the interaction model MHA operation , Pictured above (b) Note the blue color in the figure . To be specific , In the interaction based model l The input representation of the layer , namely , Decomposable into X Part and Y part . therefore ,, among ,
402 Payment Required
. Based on this , The attention parameter can also be rewritten as X part ( Expressed as and ) and Y part ( Expressed as and ) The combination of .Softmax(·) Final attention score before operation ( Expressed as ) It can be decomposed into the following partition matrix :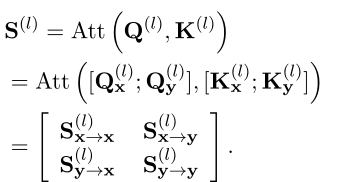
Therefore, it can be divided into four parts :
402 Payment Required
, namely :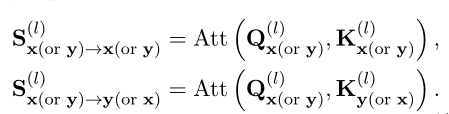
It's only in X or Y Implemented in MHA operation , It corresponds to MHA operation . And refers to interaction based models x and Y Interaction between , These models are responsible for rich representation of interactive information . However , They are missing from the representation based model , This leads to the performance gap between the two models .
Through the above analysis , Missing interactions based on representation models can be extracted as X and Y Between MHA operation . To restore this missing interaction , Let the representation based model simulate the interaction in the interaction based model , As shown below :
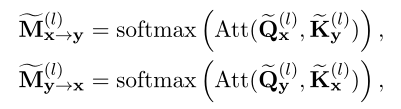
Where means by attend To the generated attention map , By attend To the generated attention map . These two additional attention maps represent the missing interaction signals in the representation based model .
Because we hope to improve the performance of representation based model to interaction based model , Therefore, the author proposes to align the missing attention graph with its existing correspondence in the interaction based model . The attention graph in the interaction based model can guide the representation ( Namely and ) Towards the direction of rich interaction , It's like interaction in the coding process . In this way , Extract knowledge during interaction , And transmit it to the dual encoder , Without any additional computing overhead . This is why this mechanism is called “ Virtual interaction ”.
In order to achieve VIRT, The author adopts knowledge distillation technology , One of the trained interaction based models is considered a teacher , A representation based model that requires training is considered a student . And corresponding interaction based models X and Y Interaction between . They can go directly from softmax(·) From the previous attention score : Yes, before m OK and last n Column section , Corresponding to the last n Line and front m Column . except softmax Out of operation , The author also directly selects these two slices , To form a guided attention graph from an interaction based model :
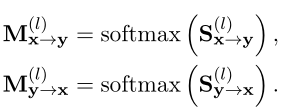
As a supervised interaction, knowledge is further transferred , To guide VIRT. say concretely , The goal is to minimize and L2 distance :
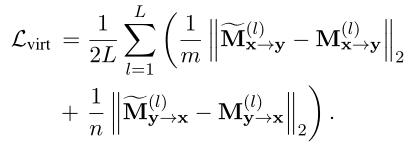
Take the above formula as the optimization goal only in the training stage , And delete it during reasoning . This preserves the twin properties of the representation based model , At the same time, it will not bring additional reasoning costs .
3.4 VIRT-Adapted Interaction
adopt VIRT, Interaction knowledge can be penetrated into every coding layer of the representation based model . However , After twin coding , The representation of the last layer , Namely and , Still can't see each other , Therefore, there is a lack of clear interaction . In order to make full use of the learned interactive knowledge , The author further designs an adaptation VIRT Interaction strategy , The strategy is VIRT Under the guidance of the attention map of learning, and .
To be specific , The author performs the... Between and in the following process VIRT Adapt to interaction . The formula of the generated attention graph is as follows :
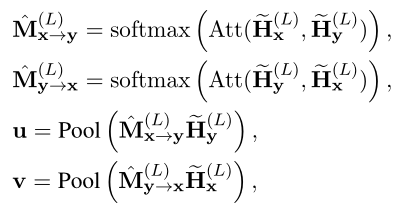
among Pool(·) Indicates the average pool operation . Last , Using simple fusion prediction to match tags y:
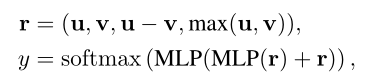
Where is concat operation ,MLP Represents a multi-layer perceptron . The overall training goal is to lose the supervision of specific tasks ( That's cross entropy loss ) The combination of and is minimized :
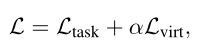
among α It is a super parameter to measure the impact of virtual interaction .
It is worth noting that ,VIRT Is a general strategy , It can be used to enhance any representation based matching model .
04
experiment
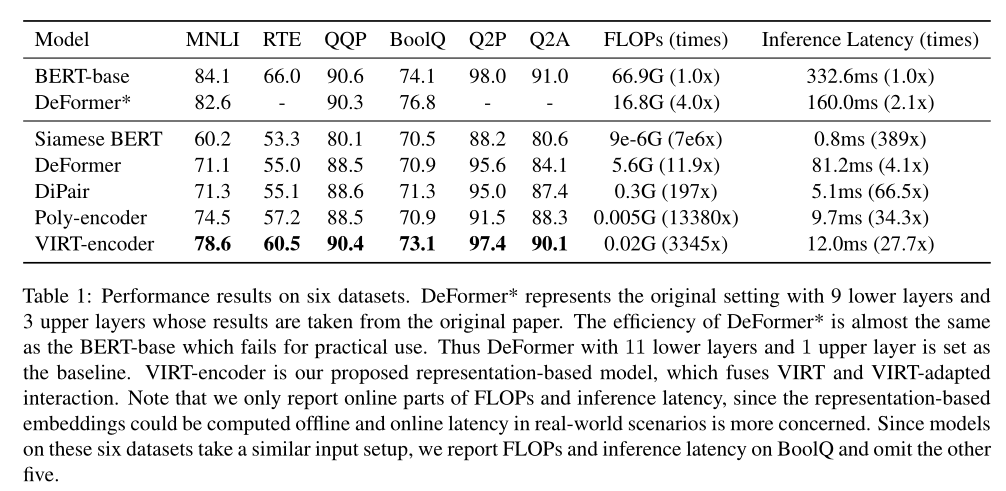
The performance of different methods is shown in the table above .BERT-base As a powerful interaction based model , It shows its effectiveness . And BERT comparison ,Siamese BERT The performance of . What this article puts forward VIRT Encoder achieves the best performance , Better than all presentation based baseline, Even with interaction based BERT The model is competitive . This proof VIRT Be able to approximate the deep interaction modeling ability of interaction based models .
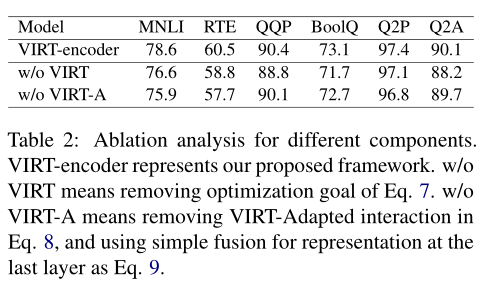
The above table shows the VIRT as well as VIRT The contribution of adaptive interaction . Don't use VIRT or VIRT The performance degradation of adapting to interaction shows the effectiveness of these two architectures . about MNLI and RTE, Due to removal VIRT The performance degradation caused by adaptive interaction is more serious .
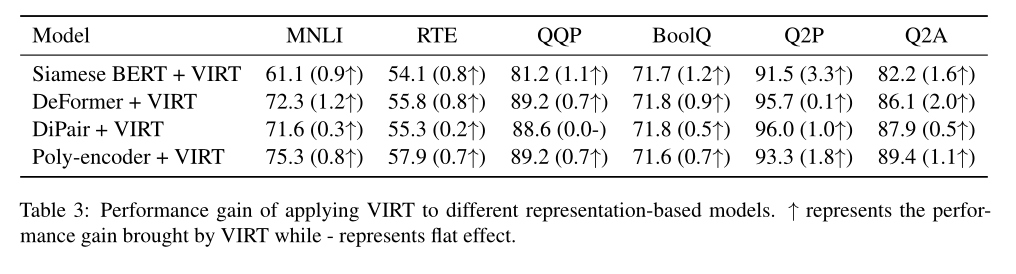
In order to verify the proposed VIRT The generality of , The author further imports it into the above representation based model . The results are shown in the table above . Based on the results , Can be observed VIRT It can be easily integrated into other representation based text matching models , To further improve performance .
05
summary
Representation based models are widely used in text matching tasks because of their high efficiency , The interaction based model has poor performance due to the lack of interaction . Previous work often introduced additional interaction layers , The interaction in the twin encoder is still missing .
In this paper , The author proposes a virtual interaction (VIRT) Mechanism , This mechanism can approximate the ability of interaction modeling by extracting attention graph from interaction based model to twin encoder based on representation model , Without additional reasoning costs .
The proposed VIRT The encoder adopts VIRT and VIRT Adapt to interaction strategies , The latest performance of the existing representation based model is implemented in multiple text matching tasks . Besides ,VIRT The existing representation based model is further improved .
Reference material
[1]https://arxiv.org/abs/2112.04195

END
Join in 「 Computer vision 」 Exchange group notes :CV

边栏推荐
- 二分(整数二分、实数二分)
- MarkDown语法——更好地写博客
- Pytest learning ----- pytest confitest of interface automation test Py file details
- Jerry's access to additional information on the dial [article]
- C language exchanges two numbers through pointers
- Interview shock 62: what are the precautions for group by?
- Appium automated test scroll and drag_ and_ Drop slides according to element position
- Kill -9 system call used by PID to kill process
- kivy教程之在 Kivy 中支持中文以构建跨平台应用程序(教程含源码)
- 78 岁华科教授逐梦 40 载,国产数据库达梦冲刺 IPO
猜你喜欢
kivy教程之在 Kivy 中支持中文以构建跨平台应用程序(教程含源码)

Smart street lamp based on stm32+ Huawei cloud IOT design
【Android】Kotlin代码编写规范化文档
30 分钟看懂 PCA 主成分分析

递归的方式
node の SQLite

偷窃他人漏洞报告变卖成副业,漏洞赏金平台出“内鬼”
Implementation of queue

Heavy! Ant open source trusted privacy computing framework "argot", flexible assembly of mainstream technologies, developer friendly layered design

RB157-ASEMI整流桥RB157
随机推荐
Unity tips - draw aiming Center
RB157-ASEMI整流桥RB157
UDP协议:因性善而简单,难免碰到“城会玩”
[introduction to MySQL] the first sentence · first time in the "database" Mainland
Pytest learning ----- pytest confitest of interface automation test Py file details
Is it meaningful for 8-bit MCU to run RTOS?
scratch疫情隔离和核酸检测模拟 电子学会图形化编程scratch等级考试三级真题和答案解析2022年6月
Shell input a string of numbers to determine whether it is a mobile phone number
The easycvr platform reports an error "ID cannot be empty" through the interface editing channel. What is the reason?
【Swoole系列2.1】先把Swoole跑起来
78 岁华科教授逐梦 40 载,国产数据库达梦冲刺 IPO
酷雷曼多种AI数字人形象,打造科技感VR虚拟展厅
一体化实时 HTAP 数据库 StoneDB,如何替换 MySQL 并实现近百倍性能提升
Markdown grammar - better blogging
C language exchanges two numbers through pointers
MSF horizontal MSF port forwarding + routing table +socks5+proxychains
Open source and safe "song of ice and fire"
The integrated real-time HTAP database stonedb, how to replace MySQL and achieve nearly a hundredfold performance improvement
It doesn't make sense without a distributed gateway
IP, subnet mask, gateway, default gateway