当前位置:网站首页>什么是文本挖掘 ?「建议收藏」
什么是文本挖掘 ?「建议收藏」
2022-07-05 18:33:00 【全栈程序员站长】
大家好,又见面了,我是你们的朋友全栈君。
什么是文本挖掘 文本挖掘是抽取有效、新颖、有用、可理解的、散布在文本文件中的有价值知识,并且利用这些知识更好地组织信息的过程。1998年底,国家重点研究发展规划首批实施项目中明确指出,文本挖掘是“图像、语言、自然语言理解与知识挖掘”中的重要内容。 文本挖掘是信息挖掘的一个研究分支,用于基于文本信息的知识发现。文本挖掘利用智能算法,如神经网络、基于案例的推理、可能性推理等,并结合文字处理技术,分析大量的非结构化文本源(如文档、电子表格、客户电子邮件、问题查询、网页等),抽取或标记关键字概念、文字间的关系,并按照内容对文档进行分类,获取有用的知识和信息。 文本挖掘是一个多学科混杂的领域,涵盖了多种技术,包括数据挖掘技术、信息抽取、信息检索,机器学习、自然语言处理、计算语言学、统计数据分析、线性几何、概率理论甚至还有图论。
文本挖掘技术的发展 数据挖掘技术本身就是当前数据技术发展的新领域,文本挖掘则发展历史更短。传统的信息检索技术对于海量数据的处理并不尽如人意,文本挖掘便日益重要起来,可见文本挖掘技术是从信息抽取以及相关技术领域中慢慢演化而成的。 随着网络时代的到来,用户可获得的信息包含了从技术资料、商业信息到新闻报道、娱乐资讯等多种类别和形式的文档,构成了一个异常庞大的具有异构性、开放性特点的分布式数据库,而这个数据库中存放的是非结构化的文本数据。结合人工智能研究领域中的自然语言理解和计算机语言学,从数据挖掘中派生了两类新兴的数据挖掘研究领域:网络挖掘和文本挖掘。 网络挖掘侧重于分析和挖掘网页相关的数据,包括文本、链接结构和访问统计(最终形成用户网络导航)。一个网页中包含了多种不同的数据类型,因此网络挖掘就包含了文本挖掘、数据库中数据挖掘、图像挖掘等。 文本挖掘作为一个新的数据挖掘领域,其目的在于把文本信息转化为人可利用的知识。
文本挖掘预处理 文本挖掘是从数据挖掘发展而来,但并不意味着简单地将数据挖掘技术运用到大量文本的集合上就可以实现文本挖掘,还需要做很多准备工作。文本挖掘的准备工作由文本收集、文本分析和特征修剪三个步骤组成,见图1。 ◆ 文本收集 需要挖掘的文本数据可能具有不同的类型,且分散在很多地方。需要寻找和检索那些所有被认为可能与当前工作相关的文本。一般地,系统用户都可以定义文本集,但是仍需要一个用来过滤相关文本的系统。 ◆ 文本分析 与数据库中的结构化数据相比,文本具有有限的结构,或者根本就没有结构;此外文档的内容是人类所使用的自然语言,计算机很难处理其语义。文本数据源的这些特殊性使得现有的数据挖掘技术无法直接应用于其上,需要对文本进行分析,抽取代表其特征的元数据,这些特征可以用结构化的形式保存,作为文档的中间表示形式。其目的在于从文本中扫描并抽取所需要的事实 ◆ 特征修剪 特征修剪包括横向选择和纵向投影两种方式。横向选择是指剔除噪声文档以改进挖掘精度,或者在文档数量过多时仅选取一部分样本以提高挖掘效率。纵向投影是指按照挖掘目标选取有用的特征,通过特征修剪,就可以得到代表文档集合的有效的、精简的特征子集,在此基础上可以开展各种文档挖掘工作。
文本挖掘的关键技术 经特征修剪之后,可以开展数据文本挖掘工作。文本挖掘工作流程见图2所示。从目前文本挖掘技术的研究和应用状况来看,从语义的角度来实现文本挖掘的还很少,目前研究和应用最多的几种文本挖掘技术有:文档聚类、文档分类和摘要抽取。 ◆ 文档聚类 首先,文档聚类可以发现与某文档相似的一批文档,帮助知识工作者发现相关知识;其次,文档聚类可以将一个文档聚类成若干个类,提供一种组织文档集合的方法;再次,文档聚类还可以生成分类器以对文档进行分类。 文本挖掘中的聚类可用于:提供大规模文档集内容的总括;识别隐藏的文档间的相似度;减轻浏览相关、相似信息的过程。 聚类方法通常有:层次聚类法、平面划分法、简单贝叶斯聚类法、K-最近邻参照聚类法、分级聚类法、基于概念的文本聚类等。 ◆ 文档分类 分类和聚类的区别在于:分类是基于已有的分类体系表的,而聚类则没有分类表,只是基于文档之间的相似度。 由于分类体系表一般比较准确、科学地反映了某一个领域的划分情况,所以在信息系统中使用分类的方法,能够让用户手工遍历一个等级分类体系来找到自己需要的信息,达到发现知识的目的,这对于用户刚开始接触一个领域想了解其中的情况,或者用户不能够准确地表达自己的信息需求时特别有用。传统搜索引擎中目录式搜索引擎属于分类的范畴,但是许多目录式搜索引擎都采用人工分类的方法,不仅工作量巨大,而且准确度不高,大大限制了起作用的发挥。 另外,用户在检索时往往能得到成千上万篇文档,这让他们在决定哪些是与自己需求相关时会遇到麻烦,如果系统能够将检索结果分门别类地呈现给用户,则显然会减少用户分析检索结果的工作量,这是自动分类的另一个重要应用。 文档自动分类一般采用统计方法或机器学习来实现。常用的方法有:简单贝叶斯分类法,矩阵变换法、K-最近邻参照分类算法以及支持向量机分类方法等。 ◆ 自动文摘 互联网上的文本信息、机构内部的文档及数据库的内容都在成指数级的速度增长,用户在检索信息的时候,可以得到成千上万篇的返回结果,其中许多是与其信息需求无关或关系不大的,如果要剔除这些文档,则必须阅读完全文,这要求用户付出很多劳动,而且效果不好。 自动文摘能够生成简短的关于文档内容的指示性信息,将文档的主要内容呈现给用户,以决定是否要阅读文档的原文,这样能够节省大量的浏览时间。简单地说自动文摘就是利用计算机自动地从原始文档中提取全面准确地反映该文档中心内容的简单连贯的短文。 自动文摘具有以下特点:(1)自动文摘应能将原文的主题思想或中心内容自动提取出来。(2)文摘应具有概况性、客观性、可理解性和可读性。(3)可适用于任意领域。 按照生成文摘的句子来源,自动文摘方法可以分成两类,一类是完全使用原文中的句子来生成文摘,另一类是可以自动生成句子来表达文档的内容。后者的功能更强大,但在实现的时候,自动生成句子是一个比较复杂的问题,经常出现产生的新句子不能被理解的情况,因此目前大多用的是抽取生成法。
文本挖掘应用前景 利用文本挖掘技术处理大量的文本数据,无疑将给企业带来巨大的商业价值。因此,目前对于文本挖掘的需求非常强烈,文本挖掘技术应用前景广阔。
知识链接 文本挖掘系统的评估办法 评估文本挖掘系统是至关重要的,目前已有许多方法来衡量在这一领域的进展状况,几种比较公认的评估办法和标准如下: ◆ 分类正确率:通过计算文本样本与待分类文本的概率来得出分类正确率。 ◆ 查准率:查准率是指正确分类的对象所占对象集的大小, ◆ 查全率:查全率是指集合中所含指定类别的对象数占实际目标类中对象数的比例。 ◆ 支持度:支持度表示规则的频度。 ◆ 置信度:置信度表示规则的强度。
———————————————————————————————————————————————-
案例:文本挖掘在互连网关键词分析中的应用
沈浩老师以新浪体育国际足球新闻标题为例,生动的讲述了文本挖掘在互联网关键词分析中的应用。
在数据分析技术中,文本分析的使用一直是一个较少被涉及的领域,特别是有关中文文字的文本挖掘。
文本挖掘大致可由三部分组成:底层是文本数据挖掘的基础领域,包括机器学习、数理统计、自然语言处理;在此基础上是文本数据挖掘的基本技术,有五大类,包括文本信息抽取、文本分类、文本聚类、文本数据压缩、文本数据处理;在基本技术之上是两个主要应用领域,包括信息访问和知识发现,信息访问包括信息检索、信息浏览、信息过滤、信息报告,知识发现包括数据分析、数据预测。其中需要付出大量人力物力的是文本信息的提取及内容分类,尤其对于中文来说不同领域不同行业的关键词术语各不相同,因此,构建一个适用于不同行业的关键词库显得尤为重要。
不过基于中文的文本挖掘也有非常多的使用,比如各大媒体的2011十大关键词盘点。比如前段时间零点E-lab研究室所绘制的中国唐诗及宋词的关键词构成,非常的有趣,将古人诗歌的高频或者说比较潮的词汇都捕捉到了。并且采用网络分析图的方法将各个关键词之间的联系清楚的展现出来,甚至部分读者能够根据该网络图自己推敲出一些经典的诗句。怎么样?能够分辨出那张图是分析唐诗的,哪张是宋词么?
言归正传,笔者也在处理有关文本分析的内容,正好借此分享一下文本分析的方法。
正如前文所述,中文的文本挖掘集中在关键词库的建立,在没有专门软件的帮助下,使用“人工智能”倒是一个权宜之计。而人为建立关键词库的要点就在于编码,要求编码人员对关键词有相当的经验及足够的敏感度,如是多人编码还需考虑到团队的个性差异及分工协作等要素。
笔者选择将新浪体育网站中国际足球版面的新闻标题作为研究对象(不选国内足球的原因你懂……),希望通过文本挖掘的方法以小见大的分析发现新闻编辑的个人特点及标题撰写的“潜规则”。
首先,笔者选择了2011年7月1日至2011年12月20日的新闻标题作为研究对象,在这个时间段中包括了大型杯赛(美洲杯)、转会期、日常联赛等内容,应该说涵盖了足球活动中可能出现的大多数新闻报导,共有25,598条新闻标题。
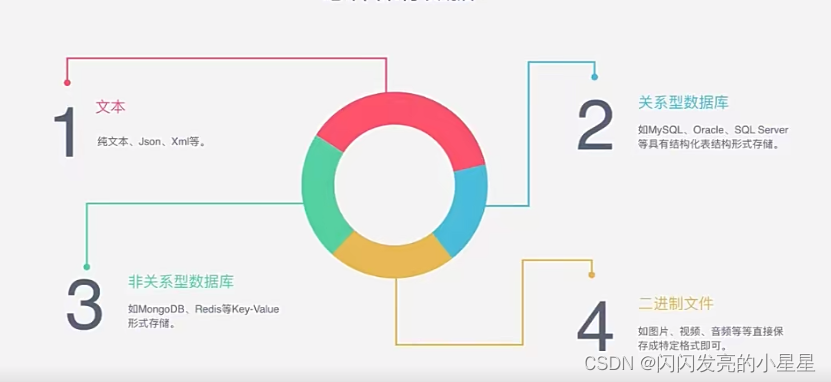
新闻大致分为三大类,即:图片、文字、视频。
经过整理,笔者共筛选了500多个关键词,如:转会、队长、传奇、名单、大将、赞、新星、对手、训练、国脚、锋霸、点球、VS、主场、天王等等。这些关键词的筛选,笔者筛选关键词的依据主要有以下几点:
l 与体育活动相关,可是场外或者场内
l 属于日常用语,不能造词
l 需要是通过词汇,即具有普适性,比如像“贝克汉姆带儿子逛街”就不作为关键词,因为其他球员出现类似情况的概率很低。
l 尽可能多的找,然后整理。比如“小小罗”和”C罗”是同一个人,但是笔者将其作为两个关键词。
废话少说,下面就晒一下对这些词的分析结果:
概述篇下面列出三大类新闻标题的关键词排名,图片类以“庆祝“、”训练”、”进球”为代表;视频类新闻以“进球”、”破门”、”梅西”为代表,主要和球场活动有关,而与前两类有较大不同的是文字类新闻,排名靠前的分别是”梅西”、”宣布”、”首发”、”C罗”、”官方”等,包含内容较多,并且纵观整个文字新闻页面,使用的高频形容词是最多的。
人物篇在排名前20的词汇中共出现三个人物名称:”梅西”、”C罗”、”穆帅”。作为球员前两人在图片及视频中占了较大比重,而穆里尼奥是唯一跻身新闻关键词前20的教练员。
技术篇在排名前20的词汇中,涉及足球比赛描述的词汇主要集中在视频中,其次是图片,而文字新闻中场外内容占了较大篇幅。
写作篇那么,怎么写好新闻标题,或者怎样写出新浪体育的标题?为了解决这一问题,笔者将所有标题涉及的前100个新闻标题进行相关性的网络分析:
经过整理后如下,怎么样,可以汇总一条新闻标题么?
发布者:全栈程序员栈长,转载请注明出处:https://javaforall.cn/149822.html原文链接:https://javaforall.cn
边栏推荐
- 如何写出好代码 - 防御式编程
- Whether to take a duplicate subset with duplicate elements [how to take a subset? How to remove duplicates?]
- JDBC reads a large amount of data, resulting in memory overflow
- rust统计文件中单词出现的次数
- sample_rate(采样率),sample(采样),duration(时长)是什么关系
- node_exporter内存使用率不显示
- Writing writing writing
- How to write good code defensive programming
- 《ClickHouse原理解析与应用实践》读书笔记(5)
- Rse2020/ cloud detection: accurate cloud detection of high-resolution remote sensing images based on weak supervision and deep learning
猜你喜欢

ICML2022 | 长尾识别中分布外检测的部分和非对称对比学习

第十届全球云计算大会 | 华云数据荣获“2013-2022十周年特别贡献奖”

A2L file parsing based on CAN bus (3)
Tupu software digital twin | visual management system based on BIM Technology
buuctf-pwn write-ups (9)
pytorch yolov5 训练自定义数据

Let more young people from Hong Kong and Macao know about Nansha's characteristic cultural and creative products! "Nansha kylin" officially appeared
Reptile 01 basic principles of reptile

Introduction to the development function of Hanlin Youshang system of Hansheng Youpin app
分享:中兴 远航 30 pro root 解锁BL magisk ZTE 7532N 8040N 9041N 刷机 刷面具原厂刷机包 root方法下载
随机推荐
Memory management chapter of Kobayashi coding
Use of print function in MATLAB
7-1 链表也简单fina
The 2022 China Xinchuang Ecological Market Research and model selection evaluation report released that Huayun data was selected as the mainstream manufacturer of Xinchuang IT infrastructure!
ClickHouse(03)ClickHouse怎么安装和部署
Introduction to Resampling
C final review
Trust counts the number of occurrences of words in the file
Image classification, just look at me!
技术分享 | 接口测试价值与体系
RPC协议详解
Is it safe to open an account and register stocks for stock speculation? Is there any risk? Is it reliable?
Insufficient picture data? I made a free image enhancement software
音视频包的pts,dts,duration的由来.
pytorch yolov5 训练自定义数据
MySQL优化六个点的总结
[QNX Hypervisor 2.2用户手册]6.3.2 配置VM
Solutions contents have differences only in line separators
写作写作写作写作
小程序 修改样式 ( placeholder、checkbox的样式)