当前位置:网站首页>python_ scrapy_ Fang Tianxia
python_ scrapy_ Fang Tianxia
2020-11-08 08:04:00 【osc_x4ot1joy】
scrapy- Explain
xpath Select node The common tag elements are as follows .
| Mark | describe |
|---|---|
| extract | The extracted content is converted to Unicode character string , The return data type is list |
| / | Select from root node |
| // | Match the selected current node, select the node in the document |
| . | node |
| @ | attribute |
| * | Any element node |
| @* | Any attribute node |
| node() | Any type of node |
Climb to take the house world - Prelude
analysis
1、 website :url:https://sh.newhouse.fang.com/house/s/.
2、 Determine what data to crawl :1) Web address :page.2) Location name :name.3) Price :price.4) Address :address.5) Phone number :tel
2、 Analyze the web page .
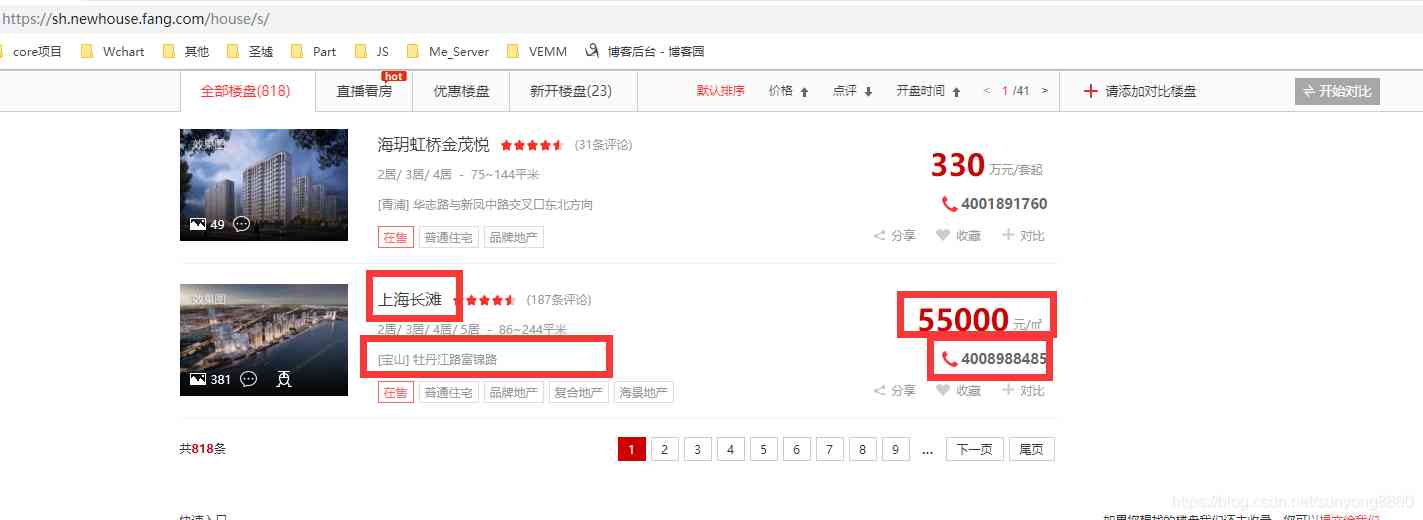
open url after , We can see the data we need , Then you can see that there are still pagination .
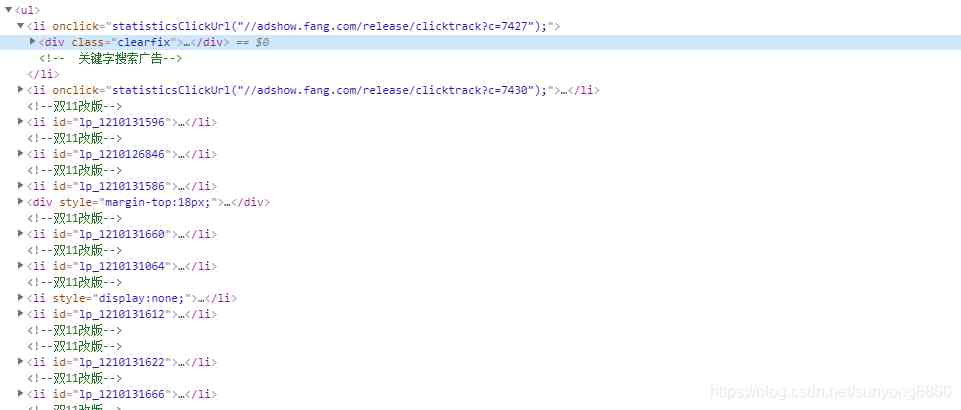
You can see the opening url Then look at the page elements , All the data we need are in a pair of ul tag .
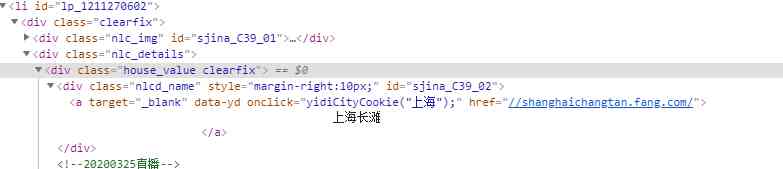
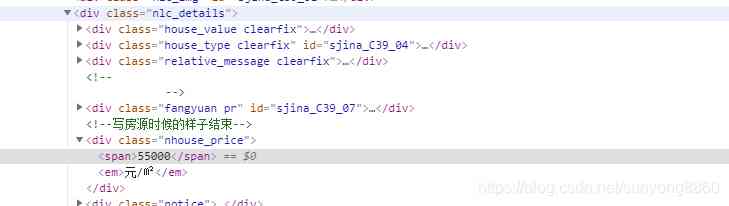
open li A couple of labels , What we need name Is in a Under the label , And there are unclear spaces around the text, such as line feed, need special treatment .
What we need price Is in 55000 Under the label , Be careful , Some houses have been bought without price display , Step on this pit carefully .
We can find the corresponding by analogy address and tel.
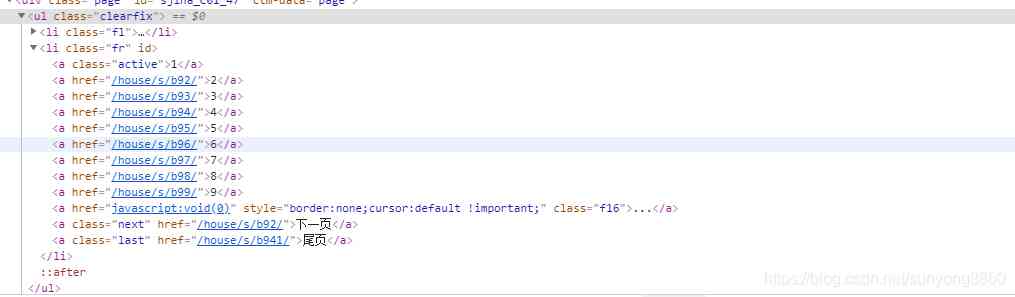
The pagination tag element shows , Of the current page a Of class="active". In opening the home page is a The text of is 1, It means the first page .
Climb to take the house world - Before the specific implementation process
First new scrapy project
1) Switch to the project folder :Terminal Input... On the console scrapy startproject hotel,hotel It's the project name of the demo , You can customize it according to your own needs .
2) On demand items.py Folder configuration parameters . Five parameters are needed in the analysis , Namely :page,name,price,address,tel. The configuration code is as follows :
class HotelItem(scrapy.Item):
# The parameters here should correspond to the specific parameters of the crawler implementation
page = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
address = scrapy.Field()
tel = scrapy.Field()
3) Build our new reptile Branch . Switch to spiders Folder ,Terminal Input... On the console scrapy genspider house sh.newhouse.fang.comhouse Is the crawler name of the project , You can customize ,sh.newhouse.fang.com It's an area selection for crawling .
stay spider Under the folder we created house.py The file .
The code implementation and explanation are as follows
import scrapy
from ..items import *
class HouseSpider(scrapy.Spider):
name = 'house'
# Crawling area restrictions
allowed_domains = ['sh.newhouse.fang.com']
# The main page of crawling
start_urls = ['https://sh.newhouse.fang.com/house/s/',]
def start_requests(self):
for url in self.start_urls:
# Return the module name passed by the function , There are no brackets . It's a convention .
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
items = []
# Get the value displayed on the current page
for p in response.xpath('//a[@class="active"]/text()'):
# extract Convert the extracted content to Unicode character string , The return data type is list
currentpage=p.extract()
# Determine the last page
for last in response.xpath('//a[@class="last"]/text()'):
lastpage=last.extract()
# Switch to the nearest layer of tags .// Select the node in the document from the current node that matches the selection , Regardless of their location / Select from root node
for each in response.xpath('//div[@class="nl_con clearfix"]/ul/li/div[@class="clearfix"]/div[@class="nlc_details"]'):
item=HotelItem()
# name
name=each.xpath('//div[@class="house_value clearfix"]/div[@class="nlcd_name"]/a/text()').extract()
# Price
price=each.xpath('//div[@class="nhouse_price"]/span/text()').extract()
# Address
address=each.xpath('//div[@class="relative_message clearfix"]/div[@class="address"]/a/@title').extract()
# Telephone
tel=each.xpath('//div[@class="relative_message clearfix"]/div[@class="tel"]/p/text()').extract()
# all item The parameters in it have to do with us items The meaning of the parameters in it corresponds to
item['name'] = [n.replace(' ', '').replace("\n", "").replace("\t", "").replace("\r", "") for n in name]
item['price'] = [p for p in price]
item['address'] = [a for a in address]
item['tel'] = [s for s in tel]
item['page'] = ['https://sh.newhouse.fang.com/house/s/b9'+(str)(eval(p.extract())+1)+'/?ctm=1.sh.xf_search.page.2']
items.append(item)
print(item)
# When crawling to the last page , Class label last Automatically switch to the home page
if lastpage==' home page ':
pass
else:
# If it's not the last page , Continue crawling to the next page of data , Know all the data
yield scrapy.Request(url='https://sh.newhouse.fang.com/house/s/b9'+(str)(eval(currentpage)+1)+'/?ctm=1.sh.xf_search.page.2', callback=self.parse)
4) stay spiders Run the crawler under ,Terminal Input... On the console scrapy crawl house.
The results are shown in the following figure
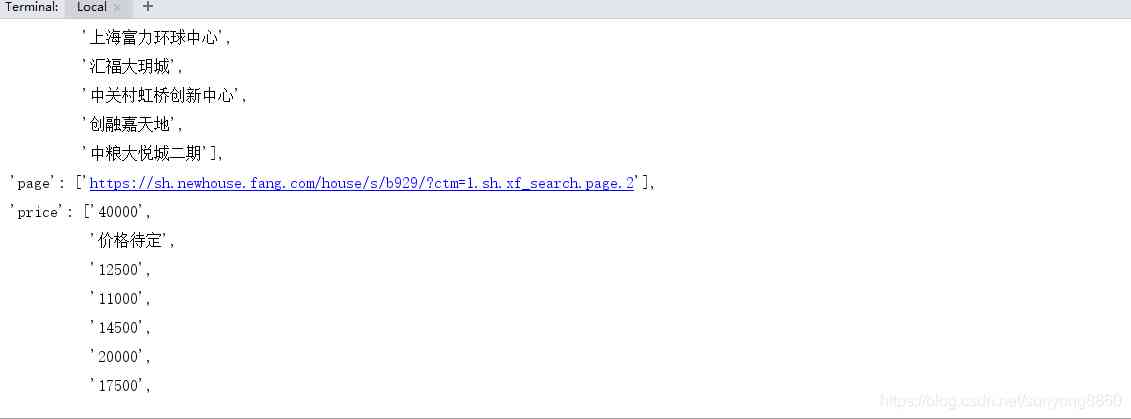
The overall project structure is shown on the right tts The folder is used to store data on my side txt file . There is no need for this project .

If you find any errors, please contact wechat :sunyong8860
python Crawling along the road
版权声明
本文为[osc_x4ot1joy]所创,转载请带上原文链接,感谢
边栏推荐
- Bili Bili common API
- Adobe Prelude / PL 2020 software installation package (with installation tutorial)
- 【总结系列】互联网服务端技术体系:高性能之数据库索引
- 归纳一些比较好用的函数
- Application of bidirectional LSTM in outlier detection of time series
- The software in your host has terminated an established connection. resolvent
- SQL Server 2008R2 18456 error resolution
- IOS upload app store error: this action cannot be completed - 22421 solution
- Everything is 2020, LINQ query you are still using expression tree
- Privacy violation and null dereference of fortify vulnerability
猜你喜欢

洞察——风格注意力网络(SANet)在任意风格迁移中的应用
【原创】关于高版本poi autoSizeColumn方法异常的情况
wanxin金融
sed之查找替换
Data structure and sorting algorithm
Privacy violation and null dereference of fortify vulnerability
数据科学面试应关注的6个要点
Search and replace of sed
Face recognition: attack types and anti spoofing techniques
Do you really understand the high concurrency?
随机推荐
[original] about the abnormal situation of high version poi autosizecolumn method
CPP (1) installation of cmake
5g + Ar out of the circle, China Mobile Migu becomes the whole process strategic partner of the 33rd China Film Golden Rooster Award
Astra: the future of Apache Cassandra is cloud native
Go sending pin and email
麦格理银行借助DataStax Enterprise (DSE) 驱动数字化转型
在Ubuntu上体验最新版本EROFS
Six key points of data science interview
Simple use of future in Scala
C language I blog assignment 03
Problems of Android 9.0/p WebView multi process usage
【原创】关于高版本poi autoSizeColumn方法异常的情况
Goland 编写含有template的程序
Game mathematical derivation AC code (high precision and low precision multiplication and division comparison) + 60 code (long long) + 20 point code (Full Permutation + deep search DFS)
Download, installation and configuration of Sogou input method in Ubuntu
京淘项目知识点总结
学习Scala IF…ELSE 语句
Experience the latest version of erofs on Ubuntu
1. In depth istio: how is sidecar auto injection realized?
洞察——风格注意力网络(SANet)在任意风格迁移中的应用