当前位置:网站首页>深入浅出【机器学习之线性回归】
深入浅出【机器学习之线性回归】
2022-07-07 15:40:00 【SmartBrain】
线性回归:
1. 以银行信贷为例,通俗讲,分类是指根据你的X(工资和年龄等资质),来决定Y(是否给你贷款),回归是决定能贷给你多少钱;
2. 目标:通过贷款数据的各个特征来训练出贷款数据模型,简单举例,就是通过输入X(年龄和工资)来预测Y(是否给您贷款);
3. 方法:建立一个回归方程,Y=W1*X1(工资)+W2*X2(年龄);W是权重或者参数,决定贡献度;
4. 难点:无法用一个平面来满足所有数据点的拟合,只能尽可能找一个最好拟合数据的平面;
5. 数学表达:用数据公司来表达拟合平面如下
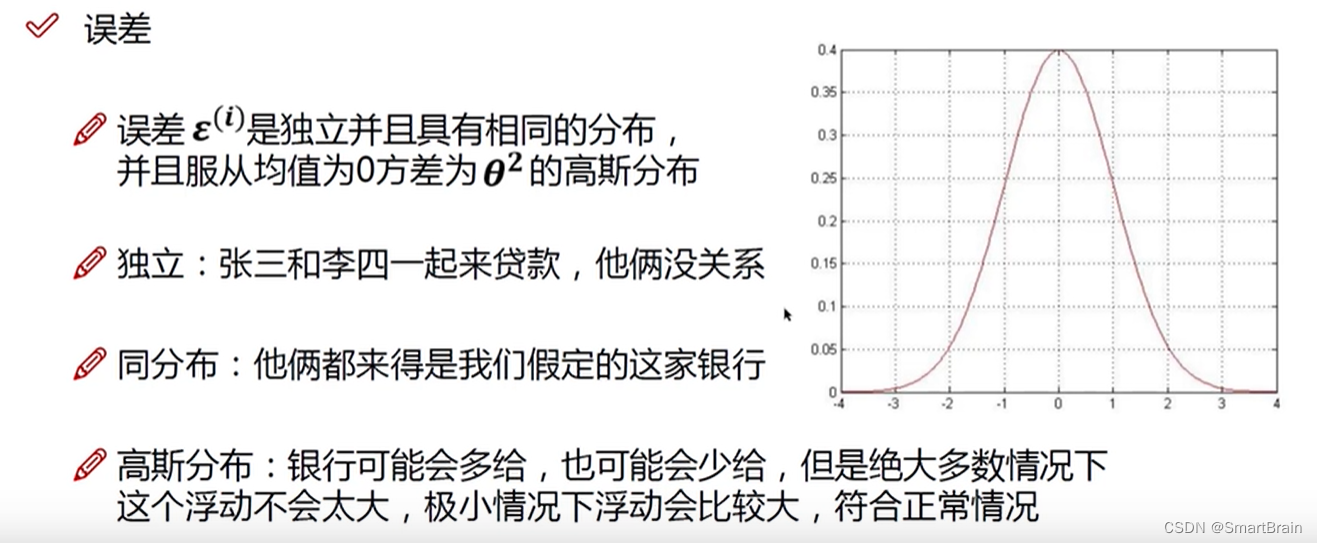
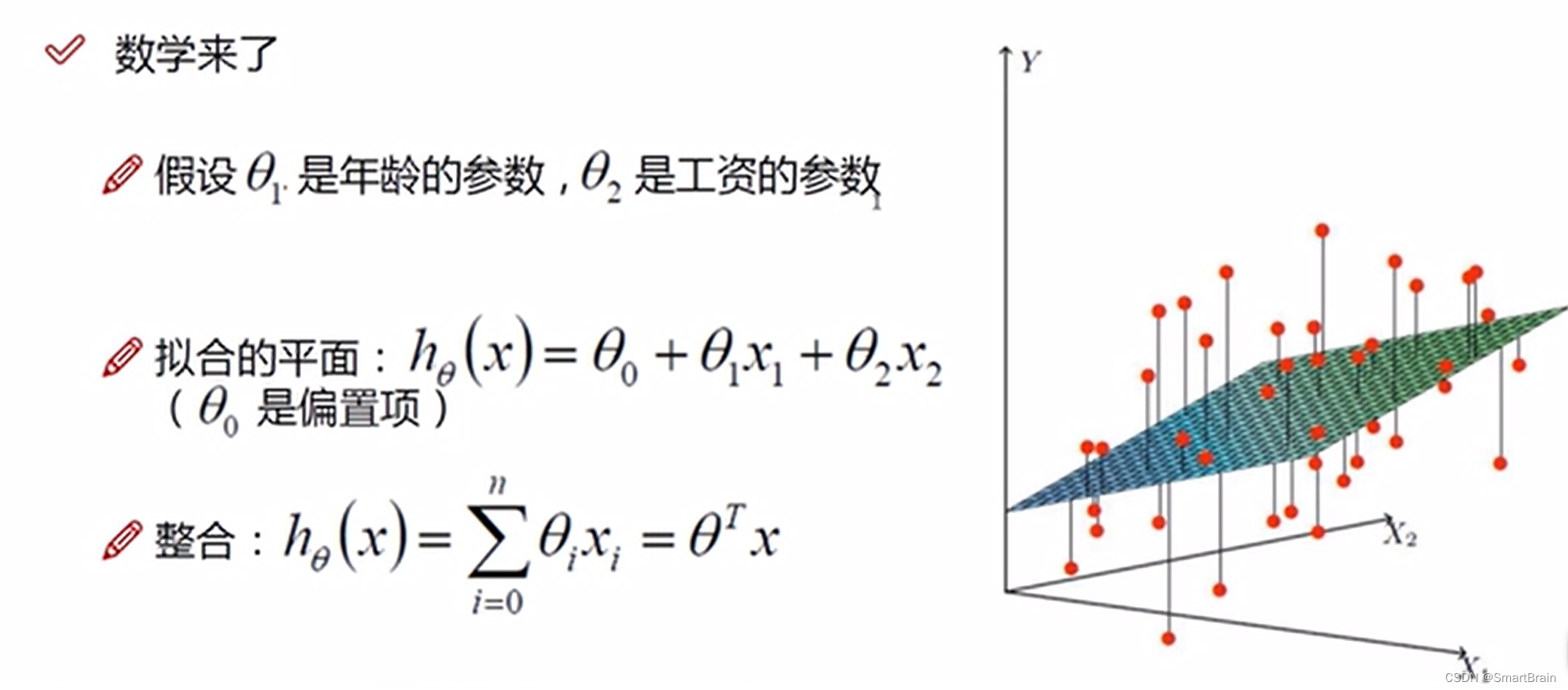 6. 主要是减小误差,而误差必须是针对独立同分布的方程来说的,要服从高斯分布,具体描述如下:
6. 主要是减小误差,而误差必须是针对独立同分布的方程来说的,要服从高斯分布,具体描述如下:
7. 当前,我的参数要如何求解?
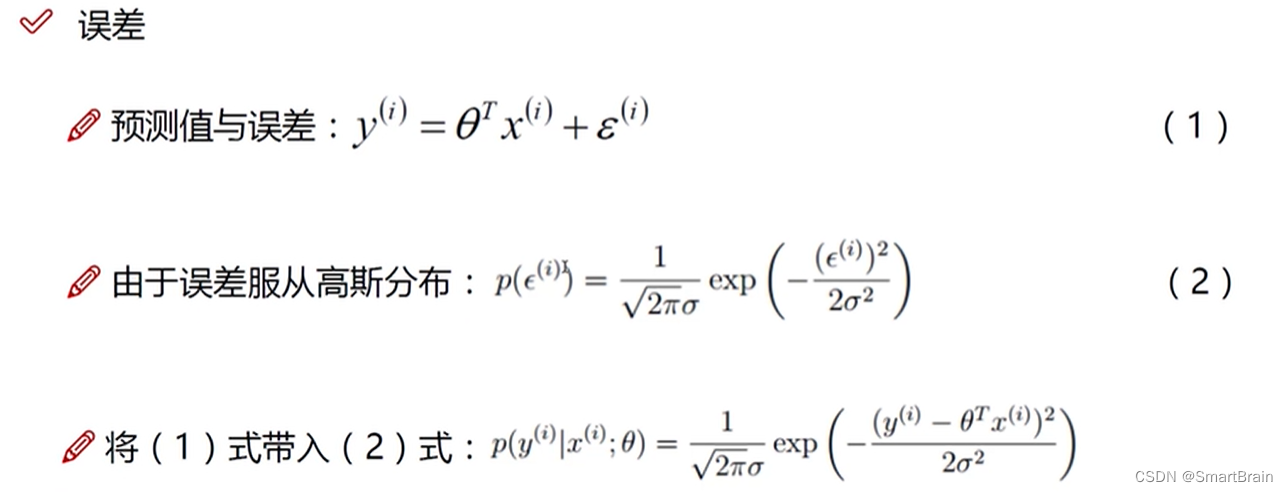 8. 目标:是找到误差为0的方程中,参数最好能是预测值靠近真实值, 因此需要采用大量的数据(这里设置为m)找到合适的参数,因此是累乘的方式,但是乘法问题太复杂,需要用对数转成加法问题。
8. 目标:是找到误差为0的方程中,参数最好能是预测值靠近真实值, 因此需要采用大量的数据(这里设置为m)找到合适的参数,因此是累乘的方式,但是乘法问题太复杂,需要用对数转成加法问题。

9. 转化成求参数的极值点,使得Y最大,也就是求J的最小值,就是最小二乘法
 10 ,求当前的参数,使得J最小,也就是偏导数为0是,就是参数的极值点。
10 ,求当前的参数,使得J最小,也就是偏导数为0是,就是参数的极值点。
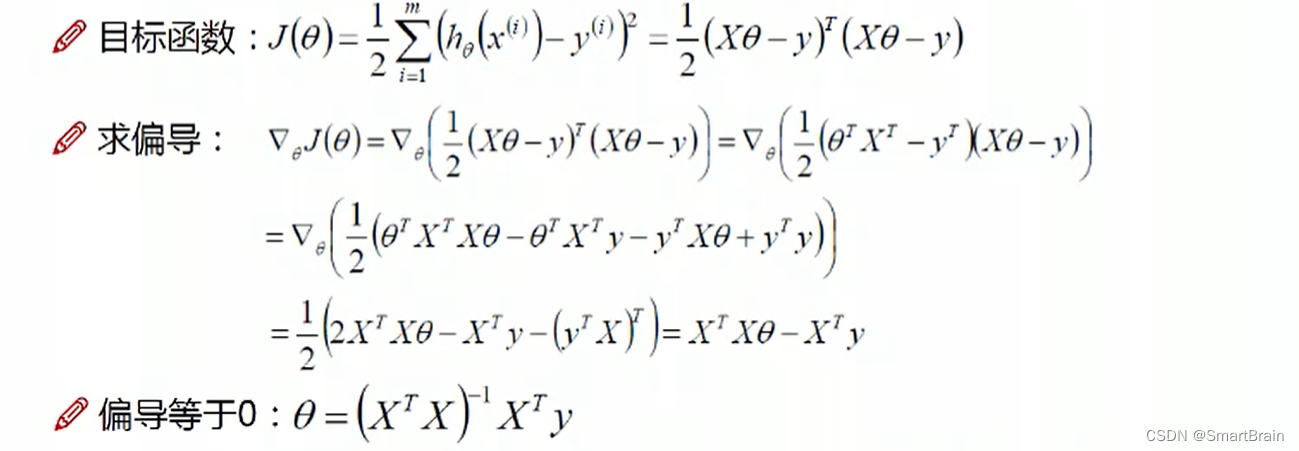
总结如下:
1. 偏差(距离远近):描述的是预测值的期望与真实值之间的差距,偏差越大,越偏离真实数据。 2. 方差(是否聚集):预测值的方差,描述的是预测值的变化范围,离散程度,也就是离预测值期望值的距离,方差越大,数据的分布越分散,概念上理解比较抽象,下面我们通过图解来理解一下偏差和方差。
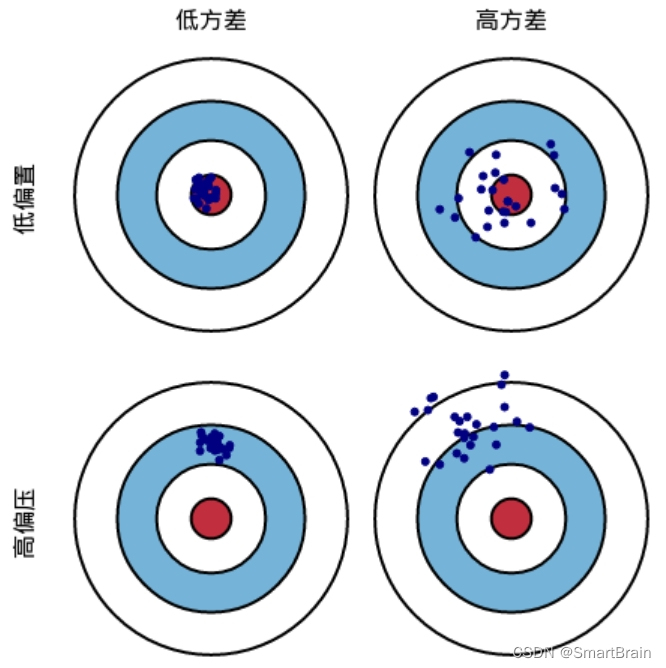
如上图,我们假设一次射击就是一个机器学习模型对一个样本进行预测,射中红色靶心位置代表预测准确,偏离靶心越远代表预测误差越大。偏差则是衡量射击的蓝点离红圈的远近,射击位置即蓝点离红色靶心越近则偏差越小,蓝点离红色靶心越远则偏差越大;方差衡量的是射击时手是否稳即射击的位置蓝点是否聚集,蓝点越集中则方差越小,蓝点越分散则方差越大。
模型的泛化能力(泛化误差)是由偏差、方差与数据噪声之和
偏差度量的是学习算法预测误差和真实误差的偏离程度,即刻画学习算法本身的学习能力,方差度量同样大小的训练数据的变动所导致的学习性能的变化,即刻画数据扰动所造成的影响,噪声则表达了当前任务上任何学习算法所能到达的期望预测误差的下界,即刻画了学习问题本身的难度,因此泛化误差是由学习算法的能力、数据的充分性以及问题本身难度决定 学习算法刚训练时,训练不足欠拟合,此时偏差较大;当训练程度加深之后,训练数据的扰动也被算法学习到了,此时算法过拟合,方差过大,训练数据轻微扰动都会使得学习模型发生显著变化,
因此我们得出结论:模型欠拟合时偏差过大,模型过拟合时方差过大。
1、高偏差(模型欠拟合)时模型优化方法
(1)添加特征数 当特征不足或者选取的特征与标签之间相关性不强时,模型容易出现欠拟合,通过挖掘上下文特征、ID类特征、组合特征等新特征,往往可以达到防止欠拟合的效果,在深度学习中,有很多模型可以帮助完成特征工程,如因子分解机、梯度提升决策树、Deep-crossing等都可以称为丰富特征的方法
(2)增加模型复杂度 模型过于简单则学习能力会差,通过增加模型的复杂度可以使得模型拥有更强的你和能力,例如在线性模型中添加高此项,在神经网络模型中增加隐层层数或增加隐层神经元个数
(3)延长训练时间 在决策树、神经网络中,通过增加训练时间可以增强模型的泛化能力,使得模型有足够的时间学习到数据的特征,可达到更好的效果
(4)减小正则化系数 正则化是用来方式过拟合的,但当模型出现欠拟合时则需要有针对的较小正则化系数,如xgboost算法
(5)集成学习方法Boosting Boosting算法是将多个弱分类串联在一起,如Boosting算法训练过程中,我们计算弱分类器的错误和残差,作为下一个分类器的输入,这个过程本身就在不断减小损失函数,减小模型的偏差
(6)选用更合适的模型 有时候欠拟合的原因是因为模型选的不对,如非线性数据使用线性模型,拟合效果肯定不够好,因此有时需要考虑是否是模型使用的不合适
2、高方差(模型过拟合)时模型优化方法
(1)增加数据集 增加数据集是解决过拟合问题最有效的手段,因为更多的数据能够让模型学到更多更有效的特征,减小噪声的影响度。当然数据是很宝贵的,有时候并没有那么多数据可用或者获取代价太高,但我们也可以通过一定的规则来扩充训练数据,比如在图像分类问题上,可以通过图像的平移,旋转,缩放、模糊以及添加噪音等方式扩充数据集,在我的这篇文章中有介绍,更一步,可使用生成式对抗网络来合成大量的新数据
(2)降低模型的复杂度 数据集少时,模型复杂是过拟合的主要因素,适当降低模型复杂度可以避免模型拟合过多的采样噪音,例如在决策树算法中降低树深度、进行剪枝;在深度网络中减少网络层数、神经元个数等
(3)正则化防止过拟合 正则化思想:由于模型过拟合很大可能是因为训练模型过于复杂,因此在训练时,在对损失函数进行最小化的同时,我们要限定模型参数的数量,即加入正则项,即不是以为的去减小损失函数,同时还考虑模型的复杂程度
边栏推荐
- The mail server is listed in the blacklist. How to unblock it quickly?
- 第二十四届中国科协湖南组委会调研课题组一行莅临麒麟信安调研考察
- 99% of users often make mistakes in power Bi cloud reports
- First in China! Todesk integrates RTC technology into remote desktop, with clearer image quality and smoother operation
- Ratingbar的功能和用法
- 从DevOps到MLOps:IT工具怎样向AI工具进化?
- notification是显示在手机状态栏的通知
- User defined view essential knowledge, Android R & D post must ask 30+ advanced interview questions
- Lex & yacc of Pisa proxy SQL parsing
- 使用popupwindow創建对话框风格的窗口
猜你喜欢

Several best practices for managing VDI
mysql官网下载:Linux的mysql8.x版本(图文详解)
第3章业务功能开发(用户登录)

What is cloud computing?
简单的loading动画
Share the latest high-frequency Android interview questions, and take you to explore the Android event distribution mechanism

How to choose the appropriate automated testing tools?
【TPM2.0原理及应用指南】 1-3章

【OKR目标管理】案例分析

Devops' operational and commercial benefits Guide
随机推荐
Mysql 索引命中级别分析
Function and usage of textswitch text switcher
LeetCode 890(C#)
Flash build API service
toast会在程序界面上显示一个简单的提示信息
Sator推出Web3游戏“Satorspace” ,并上线Huobi
本周小贴士131:特殊成员函数和`= default`
【分布式理论】(一)分布式事务
Problems encountered in Jenkins' release of H5 developed by uniapp
Linux 安装mysql8.X超详细图文教程
专精特新软件开发类企业实力指数发布,麒麟信安荣誉登榜
The top of slashdata developer tool is up to you!!!
Siggraph 2022 best technical paper award comes out! Chen Baoquan team of Peking University was nominated for honorary nomination
The mail server is listed in the blacklist. How to unblock it quickly?
Sator launched Web3 game "satorspace" and launched hoobi
【TPM2.0原理及应用指南】 9、10、11章
DevOps 的运营和商业利益指南
Jenkins发布uniapp开发的H5遇到的问题
L1-019 谁先倒(Lua)
Sator推出Web3遊戲“Satorspace” ,並上線Huobi