当前位置:网站首页>Lex & yacc of Pisa proxy SQL parsing
Lex & yacc of Pisa proxy SQL parsing
2022-07-07 17:19:00 【InfoQ】
One 、 Preface
1.1 The authors introduce
1.2 background
Two 、 Compiler exploration
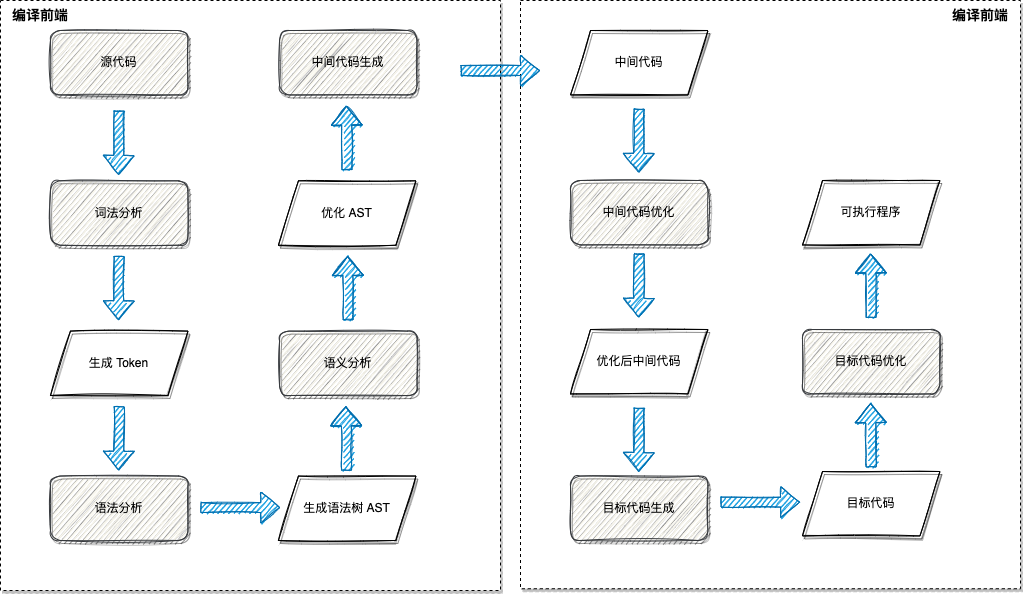
2.1 Compiler workflow
- Scan the source file , Split the character stream of the source file into words (token), This is lexical analysis
- According to the grammar rules, these marks are constructed into a grammar tree , This is syntax analysis
- Check the relationship between the nodes of the syntax tree , Check whether semantic rules are violated , At the same time, the syntax tree is optimized as necessary , This is semantic analysis
- Traverse the nodes of the syntax tree , Convert each node into intermediate code , And put them together in a specific order , This is intermediate code generation
- Optimize the intermediate code
- Convert intermediate code into object code
- Optimize the object code , Generate the final target program
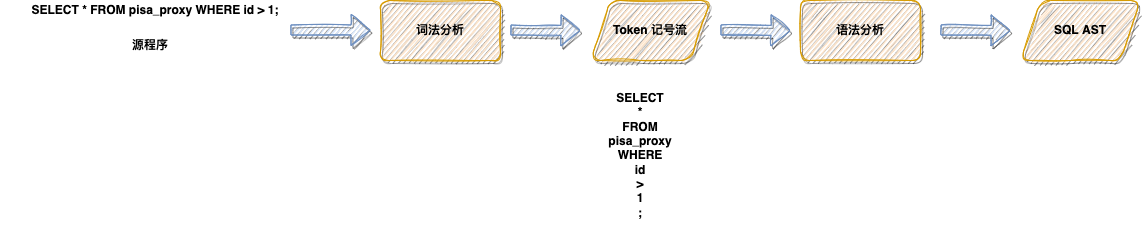
2.2 Lexical analysis
SELECT*FROMpisa_proxySELECTINSERTDELETE2.2.1 Direct scanning method
# -*- coding: utf-8 -*-
single_char_operators_typeA = {
";", ",", "(", ")","/", "+", "-", "*", "%", ".",
}
single_char_operators_typeB = {
"<", ">", "=", "!"
}
double_char_operators = {
">=", "<=", "==", "~="
}
reservedWords = {
"select", "insert", "update", "delete", "show",
"create", "set", "grant", "from", "where"
}
class Token:
def __init__(self, _type, _val = None):
if _val is None:
self.type = "T_" + _type;
self.val = _type;
else:
self.type, self.val = _type, _val
def __str__(self):
return "%-20s%s" % (self.type, self.val)
class NoneTerminateQuoteError(Exception):
pass
def isWhiteSpace(ch):
return ch in " \t\r\a\n"
def isDigit(ch):
return ch in "0123456789"
def isLetter(ch):
return ch in "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
def scan(s):
n, i = len(s), 0
while i < n:
ch, i = s[i], i + 1
if isWhiteSpace(ch):
continue
if ch == "#":
return
if ch in single_char_operators_typeA:
yield Token(ch)
elif ch in single_char_operators_typeB:
if i < n and s[i] == "=":
yield Token(ch + "=")
else:
yield Token(ch)
elif isLetter(ch) or ch == "_":
begin = i - 1
while i < n and (isLetter(s[i]) or isDigit(s[i]) or s[i] == "_"):
i += 1
word = s[begin:i]
if word in reservedWords:
yield Token(word)
else:
yield Token("T_identifier", word)
elif isDigit(ch):
begin = i - 1
aDot = False
while i < n:
if s[i] == ".":
if aDot:
raise Exception("Too many dot in a number!\n\tline:"+line)
aDot = True
elif not isDigit(s[i]):
break
i += 1
yield Token("T_double" if aDot else "T_integer", s[begin:i])
elif ord(ch) == 34: # 34 means '"'
begin = i
while i < n and ord(s[i]) != 34:
i += 1
if i == n:
raise Exception("Non-terminated string quote!\n\tline:"+line)
yield Token("T_string", chr(34) + s[begin:i] + chr(34))
i += 1
else:
raise Exception("Unknown symbol!\n\tline:"+line+"\n\tchar:"+ch)
if __name__ == "__main__":
print "%-20s%s" % ("TOKEN TYPE", "TOKEN VALUE")
print "-" * 50
sql = "select * from pisa_proxy where id = 1;"
for token in scan(sql):
print token
TOKEN TYPE TOKEN VALUE
--------------------------------------------------
T_select select
T_* *
T_from from
T_identifier pisa_proxy
T_where where
T_identifier id
T_= =
T_integer 1
T_; ;
reservedWordssingle_char_operators_typeA2.2.2 Regular expression scanning
2.3 Syntax analysis
you I He Love RustPisanix sentence -> The subject Predicate The object
The subject -> I
The subject -> you
The subject -> He
Predicate -> Love
The object -> Rust
The object -> Pisanix
Generative formula non-terminal Terminator Start symbol sentence -> The subject Predicate The object
The subject -> you | I | He
Predicate -> Love
The object -> Rust | Pisanix
Expr => Expr Expr + Expr => SELECT Expr + Expr => SELECT number + Expr => SELECT number + number => SELECT 1 + 2
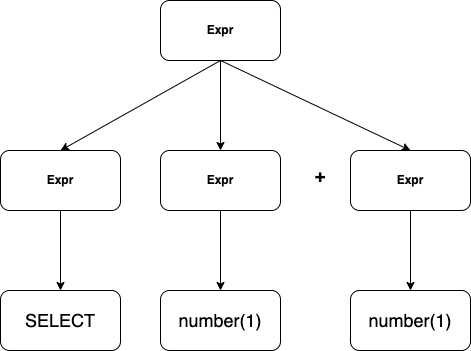
2.3.1 Two analytical methods
- Top down analysis : Top down analysis starts with the starting symbol , Keep picking out the right production , Expand the non terminator in the middle sentence , Finally, expand to the given sentence .
- Bottom up analysis : The order of bottom-up analysis is just the opposite to that of top-down analysis , Start with the given sentence , Keep picking out the right production , Fold the substring in the middle sentence into a non terminator , Finally collapse to the starting symbol
2.4 Summary
3、 ... and 、 know Lex and Yacc
3.1 know Lex
3.1.1 Lex It's made up of three parts
- Definition section : The definition segment includes text blocks 、 Definition 、 Internal table declaration 、 Starting conditions and transitions .
- The rules section : The rule segment is a series of matching patterns and actions , Patterns are usually written in regular expressions , The action part is C Code .
- User subroutine segment : Here for C Code , Will be copied to c In file , Generally, some auxiliary functions are defined here , Such as the auxiliary function used in the action code .
%{
#include <stdio.h>
%}
%%
select printf("KW-SELECT : %s\n", yytext);
from printf("KW-FROM : %s\n", yytext);
where printf("KW-WHERE : %s\n", yytext);
and printf("KW-AND : %s\n", yytext);
or printf("KW-OR : %s\n", yytext);
[*] printf("IDENTIFIED : %s\n", yytext);
[,] printf("IDENTIFIED : %s\n", yytext);
[=] printf("OP-EQ : %s\n", yytext);
[<] printf("KW-LT : %s\n", yytext);
[>] printf("KW-GT : %s\n", yytext);
[a-zA-Z][a-zA-Z0-9]* printf("IDENTIFIED: : %s\n", yytext);
[0-9]+ printf("NUM: : %s\n", yytext);
[ \t]+ printf(" ");
. printf("Unknown : %c\n",yytext[0]);
%%
int main(int argc, char* argv[]) {
yylex();
return 0;
}
int yywrap() {
return 1;
}
# flex sql.l # use flex compile .l File generation c Code
# ls
lex.yy.c sql.l
# gcc -o sql lex.yy.c # Compile and generate executable binaries
# ./sql # Execute binary
select * from pisaproxy where id > 1 and sid < 2 # Input test sql
KW-SELECT : select
IDENTIFIED : *
KW-FROM : from
IDENTIFIED: : pisaproxy
KW-WHERE : where
IDENTIFIED: : id
KW-GT : >
NUM: : 1
KW-AND : and
IDENTIFIED: : sid
KW-LT : <
NUM: : 2
3.2 know Yacc
- Define segments and predefined tag sections :
%left%right- The rules section : Rule segments consist of grammatical rules and include C The action composition of the code . In the rule, the target or non terminal character is placed on the left , Followed by a colon (:), Then there is the right side of production , Then there is the corresponding action ( use {} contain )
- Code section : This part is the function part . When Yacc When parsing error , Would call
yyerror(), Users can customize the implementation of functions .
%{
#include <stdio.h>
#include <string.h>
#include "struct.h"
#include "sql.tab.h"
int numerorighe=0;
%}
%option noyywrap
%%
select return SELECT;
from return FROM;
where return WHERE;
and return AND;
or return OR;
[*] return *yytext;
[,] return *yytext;
[=] return *yytext;
[<] return *yytext;
[>] return *yytext;
[a-zA-Z][a-zA-Z0-9]* {yylval.Mystr=strdup(yytext);return IDENTIFIER;}
[0-9]+ return CONST;
\n {++yylval.numerorighe; return NL;}
[ \t]+ /* ignore whitespace */
%%
%{
%}
%token <numerorighe> NL
%token <Mystr> IDENTIFIER CONST '<' '>' '=' '*'
%token SELECT FROM WHERE AND OR
%type <Mystr> identifiers cond compare op
%%
lines:
line
| lines line
| lines error
;
line:
select identifiers FROM identifiers WHERE cond NL
{
ptr=putsymb($2,$4,$7);
}
;
identifiers:
'*' {$="ALL";}
| IDENTIFIER {$=$1;}
| IDENTIFIER','identifiers
{
char* s = malloc(sizeof(char)*(strlen($1)+strlen($3)+1));
strcpy(s,$1);
strcat(s," ");
strcat(s,$3); $=s;
}
;
select:
SELECT
;
cond:
IDENTIFIER op compare
| IDENTIFIER op compare conn cond;
compare:
IDENTIFIER
| CONST
;
op:
'<'
|'='
|'>'
;
conn:
AND
| OR
;
%%
# Here, because the compilation process is cumbersome , Here are just the key results
# ./parser "select id,name,age from pisaproxy1,pisaproxy2,pisaproxy3 where id > 1 and name = 'dasheng'"
''Row #1 is correct
columns: id name age
tables: pisaproxy1 pisaproxy2 pisaproxy3
columntablesFour 、Pisa-Proxy SQL Analysis and implementation
lex.rsgrammar.y5、 ... and 、 summary
6、 ... and . Related links :
6.1 Pisanix:
6.2 Community
7、 ... and 、 Reference material
- 《 Compiler principle 》
- 《 Principles of modern compilation 》
- https://github.com/mysql/mysql-server/blob/8.0/sql/sql_yacc.yy
- http://web.stanford.edu/class/archive/cs/cs143/cs143.1128/
边栏推荐
- Notes on installing MySQL in centos7
- QML beginner
- Flask搭建api服务-SQL配置文件
- PLC: automatically correct the data set noise, wash the data set | ICLR 2021 spotlight
- SIGGRAPH 2022最佳技术论文奖重磅出炉!北大陈宝权团队获荣誉提名
- LeetCode 1477. Find two subarrays with sum as the target value and no overlap
- [source code interpretation] | source code interpretation of livelistenerbus
- Blue Bridge Cup final XOR conversion 100 points
- LeetCode 1049. Weight of the last stone II daily question
- 电脑无法加域,ping域名显示为公网IP,这是什么问题?怎么解决?
猜你喜欢
Sort out several important Android knowledge and advanced Android development interview questions
Skimage learning (1)

Sator推出Web3遊戲“Satorspace” ,並上線Huobi
How to add aplayer music player in blog
Direct dry goods, 100% praise

The top of slashdata developer tool is up to you!!!

Module VI

麒麟信安携异构融合云金融信创解决方案亮相第十五届湖南地区金融科技交流会

DevOps 的运营和商业利益指南
skimage学习(1)
随机推荐
Skimage learning (1)
Sator推出Web3游戏“Satorspace” ,并上线Huobi
[source code interpretation] | source code interpretation of livelistenerbus
自定义View必备知识,Android研发岗必问30+道高级面试题
Is AI more fair than people in the distribution of wealth? Research on multiplayer game from deepmind
LeetCode 1696. 跳跃游戏 VI 每日一题
【饭谈】那些看似为公司着想,实际却很自私的故事 (一:造轮子)
Number of exchanges in the 9th Blue Bridge Cup finals
Leetcode brush questions day49
Pycharm IDE下载
DNS 系列(一):为什么更新了 DNS 记录不生效?
【Seaborn】组合图表:FacetGrid、JointGrid、PairGrid
First in China! Todesk integrates RTC technology into remote desktop, with clearer image quality and smoother operation
测试用例管理工具推荐
【饭谈】Web3.0到来后,测试人员该何去何从?(十条预言和建议)
Mrs offline data analysis: process OBS data through Flink job
LeetCode 1049. 最后一块石头的重量 II 每日一题
LeetCode 300. Daily question of the longest increasing subsequence
How to choose the appropriate automated testing tools?
User defined view essential knowledge, Android R & D post must ask 30+ advanced interview questions