当前位置:网站首页>MRS离线数据分析:通过Flink作业处理OBS数据
MRS离线数据分析:通过Flink作业处理OBS数据
2022-07-07 15:36:00 【InfoQ】

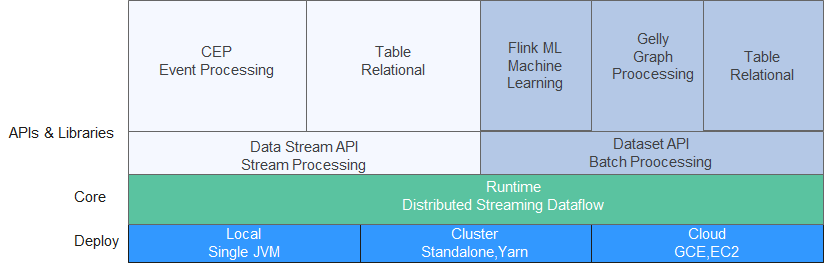
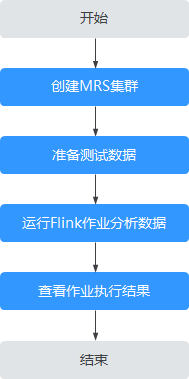
创建MRS集群
准备测试数据
This is a test demo for MRS Flink. Flink is a unified computing framework that supports both batch processing and stream processing. It provides a stream data processing engine that supports data distribution and parallel computing.

创建并运行Flink作业
方式1:在控制台界面在线提交作业。
- 登录MRS管理控制台,单击MRS集群名称,进入集群详情页面。
- 在集群详情页的“概览”页签,单击“IAM用户同步”右侧的“单击同步”进行IAM用户同步。
- 单击“作业管理”,进入“作业管理”页签。
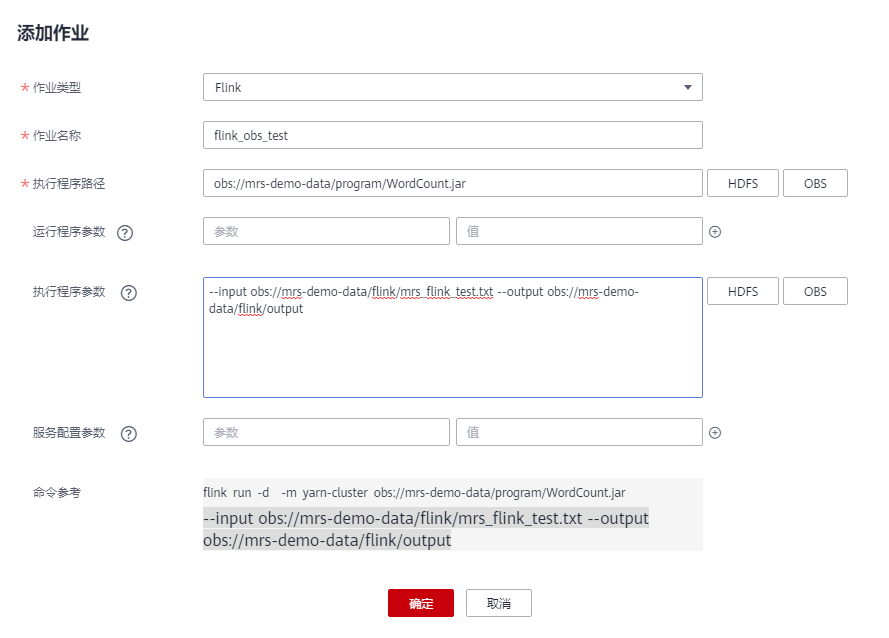
- 单击“添加”,添加一个Flink作业。作业类型:Flink作业名称:自定义,例如flink_obs_test。执行程序路径:本示例使用Flink客户端的WordCount程序为例。运行程序参数:使用默认值。执行程序参数:设置应用程序的输入参数,“input”为待分析的测试数据,“output”为结果输出文件。
- 服务配置参数:使用默认值即可,如需手动配置作业相关参数,可参考运行Flink作业。

方式2:通过集群客户端提交作业。
su - omm
cd /opt/client
source bigdata_envhdfs dfs -ls obs://mrs-demo-data/flinkflink run -m yarn-cluster /opt/client/Flink/flink/examples/batch/WordCount.jar --input obs://mrs-demo-data/flink/mrs_flink_test.txt --output obs://mrs-demo/data/flink/output2...
Cluster started: Yarn cluster with application id application_1654672374562_0011
Job has been submitted with JobID a89b561de5d0298cb2ba01fbc30338bc
Program execution finished
Job with JobID a89b561de5d0298cb2ba01fbc30338bc has finished.
Job Runtime: 1200 ms查看作业执行结果

a 3
and 2
batch 1
both 1
computing 2
data 2
demo 1
distribution 1
engine 1
flink 2
for 1
framework 1
is 2
it 1
mrs 1
parallel 1
processing 3
provides 1
stream 2
supports 2
test 1
that 2
this 1
unified 1Job with JobID xxx has finished.
Job Runtime: xxx ms
Accumulator Results:
- e6209f96ffa423974f8c7043821814e9 (java.util.ArrayList) [31 elements]
(a,3)
(and,2)
(batch,1)
(both,1)
(computing,2)
(data,2)
(demo,1)
(distribution,1)
(engine,1)
(flink,2)
(for,1)
(framework,1)
(is,2)
(it,1)
(mrs,1)
(parallel,1)
(processing,3)
(provides,1)
(stream,2)
(supports,2)
(test,1)
(that,2)
(this,1)
(unified,1)边栏推荐
- Sqlserver2014+: create indexes while creating tables
- SqlServer2014+: 创建表的同时创建索引
- 【PHP】PHP接口继承及接口多继承原理与实现方法
- LocalStorage和SessionStorage
- DAPP defi NFT LP single and dual currency liquidity mining system development details and source code
- LeetCode 1031. 两个非重叠子数组的最大和 每日一题
- LeetCode 1696. 跳跃游戏 VI 每日一题
- LeetCode 403. Frog crossing the river daily
- LeetCode 300. Daily question of the longest increasing subsequence
- LeetCode 152. 乘积最大子数组 每日一题
猜你喜欢

SIGGRAPH 2022最佳技术论文奖重磅出炉!北大陈宝权团队获荣誉提名

Skimage learning (3) -- gamma and log contrast adjustment, histogram equalization, coloring gray images
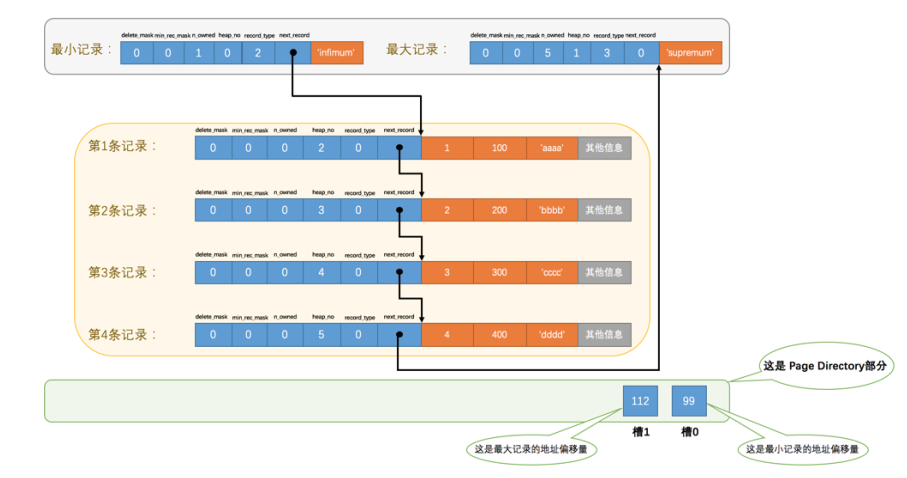
【MySql进阶】索引详解(一):索引数据页结构
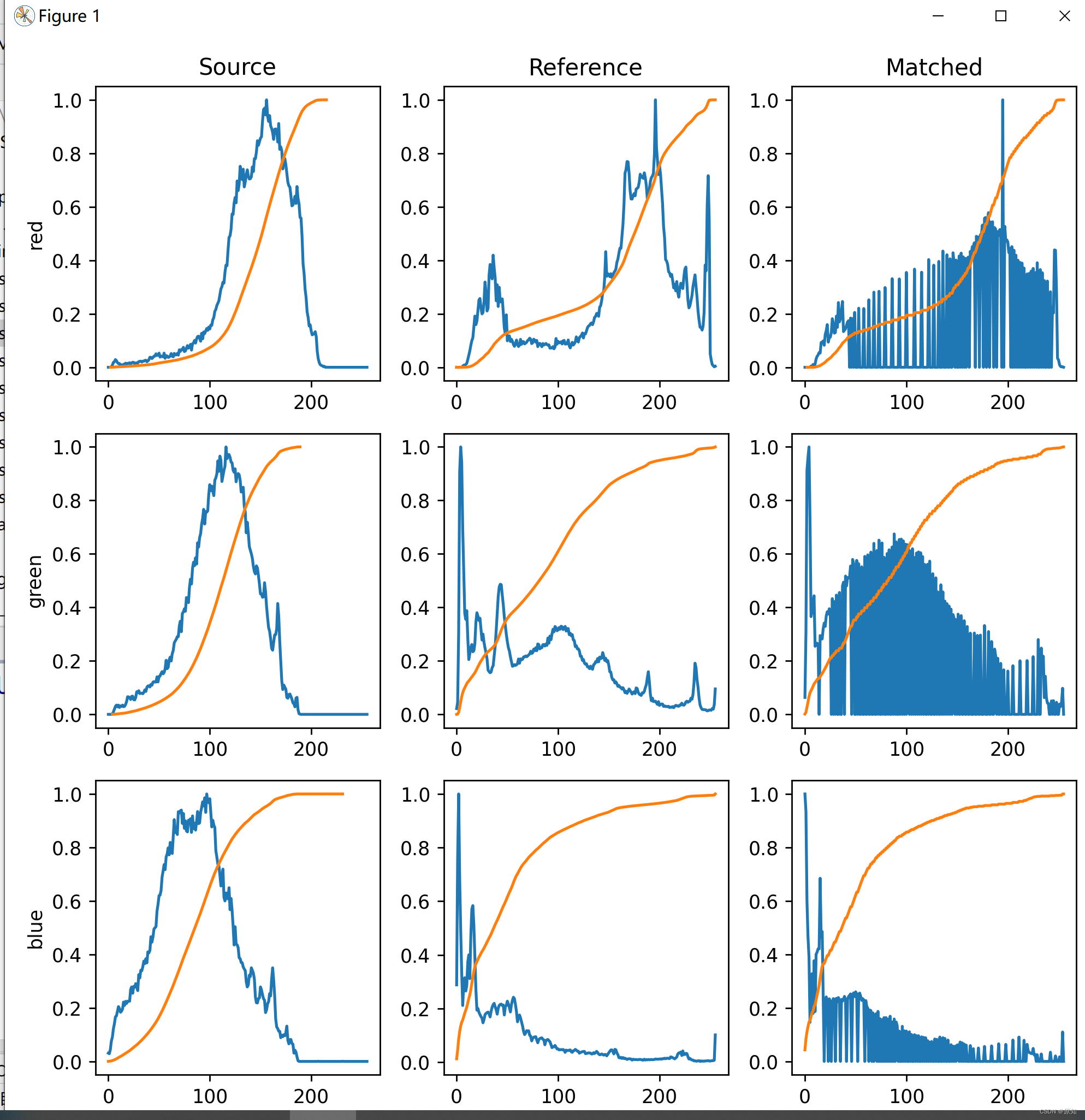
skimage学习(2)——RGB转灰度、RGB 转 HSV、直方图匹配
ByteDance Android gold, silver and four analysis, Android interview question app
Skimage learning (2) -- RGB to grayscale, RGB to HSV, histogram matching
Binary search tree (features)
正在准备面试,分享面经

浅浅理解.net core的路由
NeRF:DeepFake的最终替代者?
随机推荐
Temperature sensor chip used in temperature detector
The process of creating custom controls in QT to encapsulating them into toolbars (II): encapsulating custom controls into toolbars
蓝桥杯 决赛 异或变换 100分
LocalStorage和SessionStorage
【医学分割】attention-unet
最新2022年Android大厂面试经验,安卓View+Handler+Binder
time标准库
预售17.9万,恒驰5能不能火?产品力在线,就看怎么卖
LeetCode 403. 青蛙过河 每日一题
深度监听 数组深度监听 watch
SlashData开发者工具榜首等你而定!!!
Vs2019 configuration matrix library eigen
第九届 蓝桥杯 决赛 交换次数
null == undefined
SIGGRAPH 2022最佳技术论文奖重磅出炉!北大陈宝权团队获荣誉提名
LeetCode 300. 最长递增子序列 每日一题
LeetCode 1981. 最小化目标值与所选元素的差 每日一题
LeetCode 152. Product maximum subarray daily question
最新高频Android面试题目分享,带你一起探究Android事件分发机制
Opencv personal notes