当前位置:网站首页>Mrs offline data analysis: process OBS data through Flink job
Mrs offline data analysis: process OBS data through Flink job
2022-07-07 17:06:00 【InfoQ】

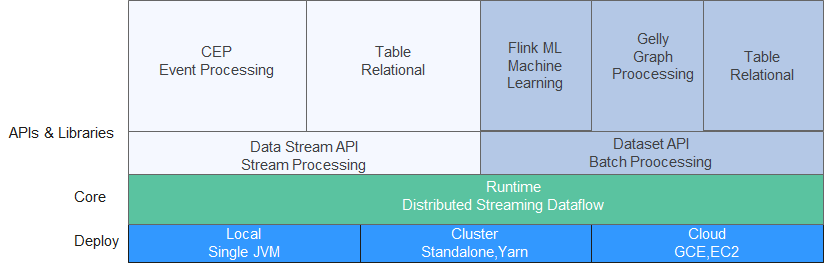
establish MRS colony
Prepare test data
This is a test demo for MRS Flink. Flink is a unified computing framework that supports both batch processing and stream processing. It provides a stream data processing engine that supports data distribution and parallel computing.

Create and run Flink Homework
The way 1: Submit your homework online in the console interface .
- Sign in MRS Administrative console , single click MRS Cluster name , Enter the cluster details page .
- On the cluster details page “ overview ” Tab , single click “IAM User synchronization ” On the right side of the “ Click sync ” Conduct IAM User synchronization .
- single click “ Job management ”, Get into “ Job management ” Tab .
- single click “ add to ”, Add one Flink Homework . The type of assignment :Flink Job name : Customize , for example flink_obs_test. Execution path : This example uses Flink Client's WordCount Program, for example . Run program parameters : Use the default value . Execute program parameters : Set the input parameters of the application ,“input” For the test data to be analyzed ,“output” Output files for results .
- Service configuration parameters : Use the default value , If you need to manually configure parameters related to the job , May refer tofunction Flink Homework.
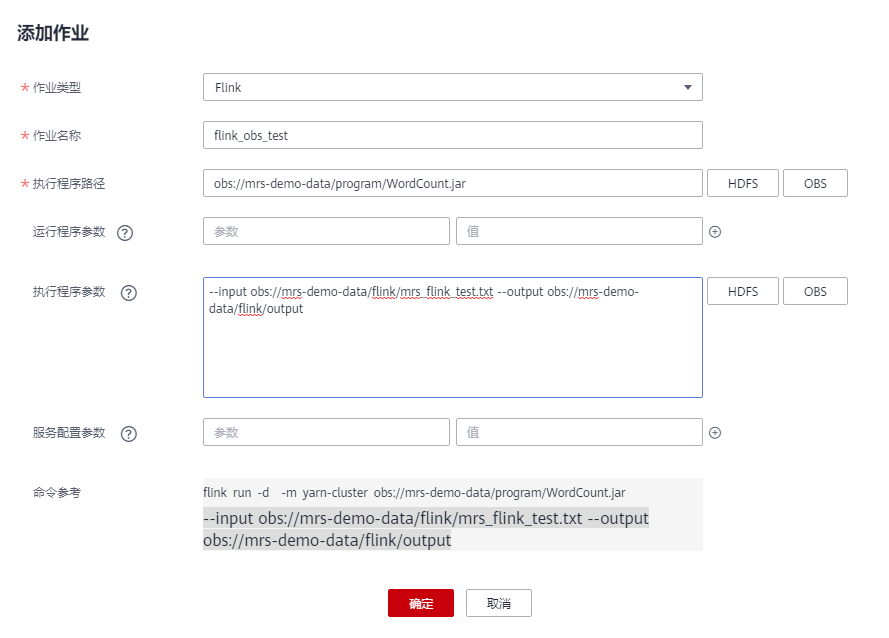

The way 2: Submit jobs through the cluster client .
su - omm
cd /opt/client
source bigdata_envhdfs dfs -ls obs://mrs-demo-data/flinkflink run -m yarn-cluster /opt/client/Flink/flink/examples/batch/WordCount.jar --input obs://mrs-demo-data/flink/mrs_flink_test.txt --output obs://mrs-demo/data/flink/output2...
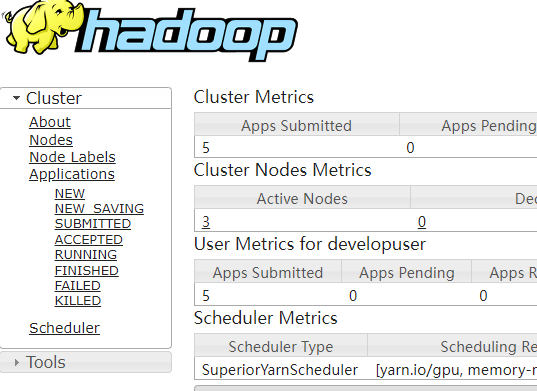
Cluster started: Yarn cluster with application id application_1654672374562_0011
Job has been submitted with JobID a89b561de5d0298cb2ba01fbc30338bc
Program execution finished
Job with JobID a89b561de5d0298cb2ba01fbc30338bc has finished.
Job Runtime: 1200 msView job execution results

a 3
and 2
batch 1
both 1
computing 2
data 2
demo 1
distribution 1
engine 1
flink 2
for 1
framework 1
is 2
it 1
mrs 1
parallel 1
processing 3
provides 1
stream 2
supports 2
test 1
that 2
this 1
unified 1Job with JobID xxx has finished.
Job Runtime: xxx ms
Accumulator Results:
- e6209f96ffa423974f8c7043821814e9 (java.util.ArrayList) [31 elements]
(a,3)
(and,2)
(batch,1)
(both,1)
(computing,2)
(data,2)
(demo,1)
(distribution,1)
(engine,1)
(flink,2)
(for,1)
(framework,1)
(is,2)
(it,1)
(mrs,1)
(parallel,1)
(processing,3)
(provides,1)
(stream,2)
(supports,2)
(test,1)
(that,2)
(this,1)
(unified,1)边栏推荐
- os、sys、random标准库主要功能
- Lie cow count (spring daily question 53)
- Reflections on "product managers must read: five classic innovative thinking models"
- 字节跳动Android金三银四解析,android面试题app
- Ray and OBB intersection detection
- LeetCode 1626. 无矛盾的最佳球队 每日一题
- Arduino 控制的双足机器人
- NeRF:DeepFake的最终替代者?
- Flask搭建api服务
- skimage学习(2)——RGB转灰度、RGB 转 HSV、直方图匹配
猜你喜欢
Direct dry goods, 100% praise
整理几个重要的Android知识,高级Android开发面试题

Introduction and use of gateway

SIGGRAPH 2022最佳技术论文奖重磅出炉!北大陈宝权团队获荣誉提名
QT中自定义控件的创建到封装到工具栏过程(一):自定义控件的创建
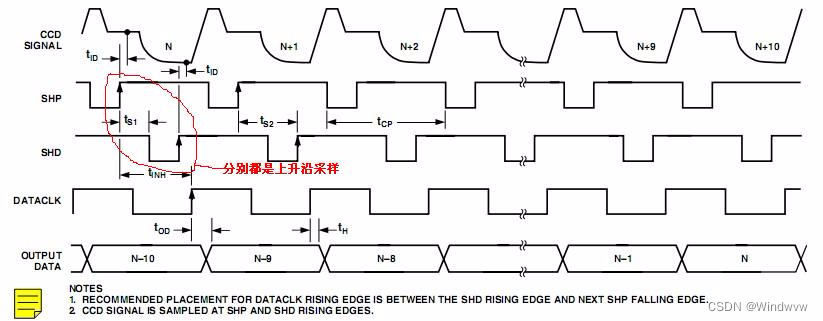
【图像传感器】相关双采样CDS
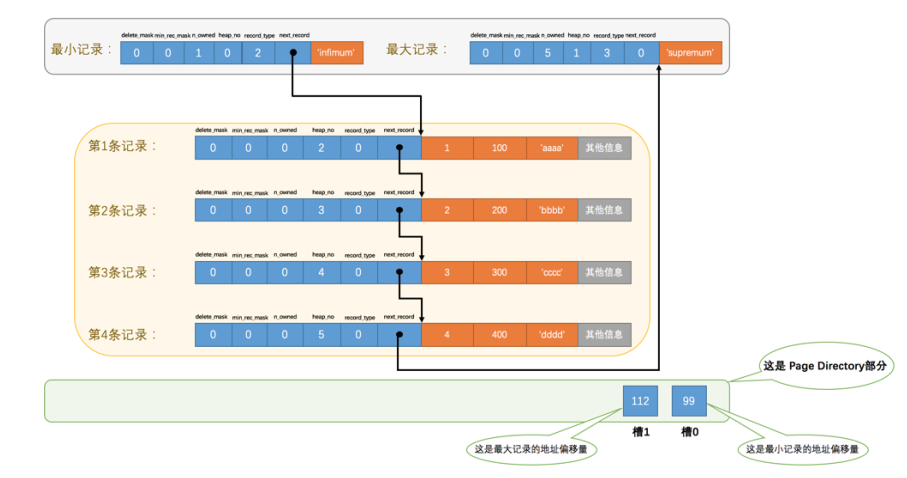
【MySql进阶】索引详解(一):索引数据页结构

Skimage learning (3) -- adapt the gray filter to RGB images, separate colors by immunohistochemical staining, and filter the maximum value of the region

Skimage learning (3) -- gamma and log contrast adjustment, histogram equalization, coloring gray images

浅浅理解.net core的路由
随机推荐
os、sys、random标准库主要功能
最新高频Android面试题目分享,带你一起探究Android事件分发机制
智慧物流平台:让海外仓更聪明
邮件服务器被列入黑名单,如何快速解封?
[designmode] proxy pattern
两类更新丢失及解决办法
Advanced C language -- function pointer
QT视频传输
最新2022年Android大厂面试经验,安卓View+Handler+Binder
Seaborn data visualization
QML初学
Sqlserver2014+: create indexes while creating tables
字节跳动Android面试,知识点总结+面试题解析
LeetCode 1986. 完成任务的最少工作时间段 每日一题
LeetCode 1774. The dessert cost closest to the target price is one question per day
Pychart ide Download
Pycharm IDE下载
[Seaborn] combination chart: pairplot and jointplot
防火墙系统崩溃、文件丢失的修复方法,材料成本0元
mysql实现两个字段合并成一个字段查询