当前位置:网站首页>Visiontransformer (I) -- embedded patched and word embedded
Visiontransformer (I) -- embedded patched and word embedded
2022-07-03 20:49:00 【lzzzzzzm】
Embedding Patched And Word embedding
1) Why would there be Word Embedding
2)Word Embedding What are you doing?
1) Divide the picture into Patch
2) N(embeded_dim) Dimensional space mapping
Preface
VisionTransformer It can be said that the fire is impossible , And I was actually right before NLP I don't know much about the field , In the study , Think in VIT There are two points worth learning in this paper , One is to preprocess the picture into image token Of Embedding Patched, The other is Transformer Multi head attention module in the module , This time, let's talk about personal Embedding Patched The understanding of the .
zero 、VIT What is it? ?
Before you know anything else , First pair VIT Make one , Personal simple understanding and overview .

Let's simply say VIT In fact, the author wants to be right image Take and context The same way , take image image context Deal with them one by one token, And send it to transform in , Then connect a classification header , You get a result based on transform The classifier of .
So we should understand VIT, I drew a picture , It's actually two parts :
- Part of it is how to image Processing into token The appearance of ——Embedding Patch.
- The other part is transformer, And here it is transformer Compared with NLP Inside transformer It's not Decoder Part of the , So only Encoder. and Encoder Partial network , In addition to the multi head attention module ——Multi-Head Attention The implementation of other parts is very simple , So the other part is to study the mechanism of multiple attention .

And this article , Mainly explain personal right Embedding Patch The understanding of the .
One 、Word Embedding
Want to Embedding Patch Have a better understanding of , Personally, I think it is necessary to briefly introduce in NLP In the field Word Embedding technology , Comparative learning , There will be a deeper understanding of .
1) Why would there be Word Embedding
Word Embedding To put it simply , It's kind of token( word ) Mapping code to vector .
Why do you need to do this , Here is an example to illustrate this .
There is a sentence : it's a nice day today , I will go to see the movies . If we want a machine, we can recognize this sentence , Then we can segment each part of the sentence first , Then code each word that comes out of the word segmentation , So the next time you encounter the corresponding word , You can check this code , To get the meaning of this sentence .
it's a nice day today , I will go to see the movies . It can be divided into , today / The weather / Pretty good /,/ I / Want to go / see / The movie this 8 Word , Then let's analyze these eight words one-hot code , such as today You can get the code as [1,0,0,0,0,0,0,0], and I Is encoded as [0,0,0,0,1,0,0,0].
Then next time I come across a sentence : Go to the movies today , The machine only needs to segment this sentence first , Then find the corresponding code in your code table , Then the machine can recognize this sentence .
But now we have two problems to consider :
- There are too many words in Chinese , If you follow this method one-hot code , Then this code table , At least it's also a 5000*5000 The sparse matrix of , If you want to use this matrix to learn for machines , It is a waste of memory and time .
- Use one-hot code , Words lose relevance . For example, for Chinese , I and you It should belong to synonyms , In English cat and cats It should be a similar word , But if you use one-hot code , The similarity between words is discarded , It is also not conducive to machine learning .
So it introduces word embedding How to do it .
2)Word Embedding What are you doing?
Now? , Every token Not only stay in the single hot coding , It's about putting each token The only hot code of is remapped as N dimension (embedded_dim) Points in space . such as today It can be encoded as [0.1,0.2,0.3], I The code is [0.5,0.6,0.6].
So the whole word embedding( In a broad sense ) What exactly are you doing , I use two steps to summarize :
- Yes context Do word segmentation .
- Divide the divided words one-hot code , According to the corresponding weight of learning one-hot Code for N(embedded_dim) The mapping of dimensional space .
Here is the second point , Take our example above , it's a nice day today , I will go to see the movies This sentence , adopt one-hot code , The whole sentence can be expressed as a 8X8 Matrix , We learn a weight matrix , Its size is 8X(embedded_dim), Then multiply it , Compared with doing a to (embedded_dim) The mapping of dimensions , obtain 8X(embedded_dim) Matrix .
And if we are right about this N Reduce the dimension of points in dimensional space , You will find words with similar meanings , Close to each other
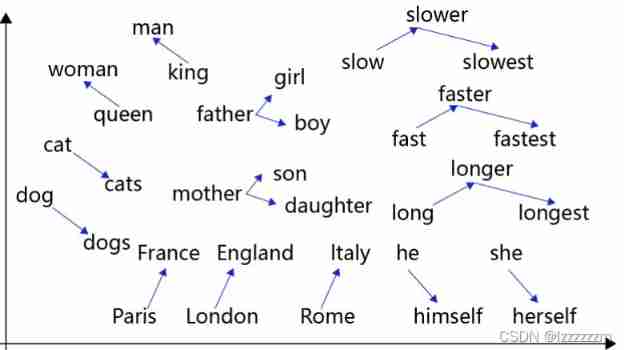
For example, the picture above ,man and king The points of are more similar ,cat and cats Also more similar . therefore word embedding That's the solution one-hot The problem of coding sparse matrix , And make the encoded vector have semantic information .
Two 、Embedding Patch
word embedding Is aimed at context Encoding , A method convenient for the machine to learn , and Embedding patch It's for image Encoding , Methods convenient for machine learning . As the author said , The author's original meaning is actually thinking , take image As a context Deal with the same .
therefore Embedding patch I'm actually doing two steps :
- Divide the picture like a word segmentation
- The divided pictures ( We call it here Patch) Conduct N(embedded_dim) The mapping of dimensional space .
1) Divide the picture into Patch
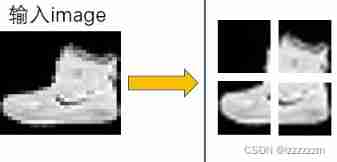
Yes context Word segmentation is actually relatively simple , For example, sentences in English , Basically, it is divided by spaces , There's no problem with this . But there is no obvious separation in the picture , But the most intuitive idea is to pull the two-dimensional image directly into a one-dimensional vector , Such as 28X28 Pictures of the , Pull into 1X784 Vector of length , take 784 The vector of dimension is taken as context, And then do word embedding. But the problem with this method is that it consumes too much ,NLP The domain deals with a 14X14=196 The length of sentences is already a time-consuming thing , Not to mention just 28*28 Pictures of the , As it is now CV Field processing pictures are basically 224X224 Upward , Obviously not .
Then let's change our thinking , Let's divide the pictures one by one (PXP) Small pieces , So let's set P by 7, So one 28X28 Pictures of the , Can be divided into 16 individual 7X7 Pictures. , If we draw even again , about transformer It becomes manageable .
2) N(embeded_dim) Dimensional space mapping
We now divide the picture into Patch And flatten the picture , Relative to the completion of context Sentence segmentation in and one-hot Coded work , We use 28X28 For example , What we have now is a 16X49 Matrix . Next we can look like context equally , To construct a learning 49(PXP) X (embedded_dim) The weight matrix of , that 16X49 The matrix of is multiplied by , Get one 16Xembedded_dim Vector , It is relative to its embedded_dim dimension It's a mapping of .

The official picture is what I mean .
3) Realization Embedding Patch
But really realize Embedding Patch It doesn't need to be so troublesome , Because for pictures , We can directly complete the segmentation of pictures and embedded_dim The relationship of dimensional mapping .

What we need to do is different from this dynamic graph , Each of us Patch It's not repeated ( Of course, some people will divide it into repetition ), each stride The length of is P. One 28X28 Pictures of the , Through one 7X7Xembedded_dim Of kernel, And stride yes 4, Re flatten , I get one embedded_dimX16 Vector of , After transposition, it is 16Xembedded_dim Matrix , Is it the same as the result above .
Then we only need a convolution operation to complete our Embedding Patch.
The specific code is as follows
class PatchEmbedding(nn.Module):
def __init__(self,
patch_size,
in_channels,
embedded_dim,
dropout=0.):
super().__init__()
self.patch_embedded = nn.Conv2d(in_channels=in_channels,
out_channels=embedded_dim,
kernel_size=patch_size,
stride=patch_size,
bias=False)
# It's added here dropout The operation of
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# X = [batchsize, 1, 28, 28]
x = self.patch_embedded(x)
# X = [batchsize, embedded_dim, h, w]
x = x.flatten(2)
# X = [batchsize, embedded_dim, h*w]
x = x.transpose(2, 1)
# X = [batchisize, h*w, embedded_dim]
x = self.dropout(x)
return xafter Embedding Patch after , In fact, the picture is relatively so token 了 , The back is transformer Thing .
therefore VIT The title of the paper is also called AN IMAGE IS WORTH 16X16 WORDS.
Of course, except Embedding Patch, There's actually another one Position embedded and cls token Things that are , Let's talk about this next time .
summary
The whole writing is more colloquial , And they are all personal learning and understanding , If something goes wrong , Please point out... In the comment area , Welcome to discuss .
边栏推荐
- Task of gradle learning
- 2.6 formula calculation
- "Designer universe" APEC safety and health +: environmental protection Panda "xiaobaobao" Happy Valentine's Day 2022 | ChinaBrand | Asia Pacific Economic media
- 11-grom-v2-04-advanced query
- 18、 MySQL -- index
- Cesiumjs 2022 ^ source code interpretation [7] - Analysis of the request and loading process of 3dfiles
- Is flush account opening and registration safe and reliable? Is there any risk?
- Battle drag method 1: moderately optimistic, build self-confidence (1)
- 同花顺开户注册安全靠谱吗?有没有风险的?
- Cannot load driver class: com. mysql. cj. jdbc. Driver
猜你喜欢

LabVIEW training

TLS environment construction and plaintext analysis

In 2021, the global revenue of thick film resistors was about $1537.3 million, and it is expected to reach $2118.7 million in 2028
2022 safety officer-c certificate examination and safety officer-c certificate registration examination

Camera calibration (I): robot hand eye calibration

APEC industry +: father of the king of the ox mill, industrial Internet "king of the ox mill anti-wear faction" Valentine's Day greetings | Asia Pacific Economic media | ChinaBrand

Xai+ network security? Brandon University and others' latest "interpretable artificial intelligence in network security applications" overview, 33 page PDF describes its current situation, challenges,

鹏城杯 WEB_WP
![C 10 new feature [caller parameter expression] solves my confusion seven years ago](/img/32/2d81237d4f1165f710a27a7c4eb1e1.jpg)
C 10 new feature [caller parameter expression] solves my confusion seven years ago
Apprentissage intensif - notes d'apprentissage 1 | concepts de base
随机推荐
2.1 use of variables
From the behind the scenes arena of the ice and snow event, see how digital builders can ensure large-scale events
C 10 new feature [caller parameter expression] solves my confusion seven years ago
Apprentissage intensif - notes d'apprentissage 1 | concepts de base
1.4 learn more about functions
Use nodejs+express+mongodb to complete the data persistence project (with modified source code)
1.5 learn to find mistakes first
浅析 Ref-NeRF
MySQL master-slave synchronization principle
你真的知道自己多大了吗?
Global and Chinese market of rubidium standard 2022-2028: Research Report on technology, participants, trends, market size and share
Test access criteria
强化學習-學習筆記1 | 基礎概念
Refer to some books for the distinction between blocking, non blocking and synchronous asynchronous
[postgresql]postgresql custom function returns an instance of table type
全网都在疯传的《老板管理手册》(转)
Deep search DFS + wide search BFS + traversal of trees and graphs + topological sequence (template article acwing)
thrift go
Set, weakset, map, weakmap in ES6
Viewing Chinese science and technology from the Winter Olympics (II): when snowmaking breakthrough is in progress