当前位置:网站首页>超标量处理器设计 姚永斌 第2章 Cache --2.2 小节摘录
超标量处理器设计 姚永斌 第2章 Cache --2.2 小节摘录
2022-06-11 21:42:00 【岐岇】
2.2 提高Cache的性能
在真实世界的处理器中,会采用更复杂的方法来提高Cache的性能,这些方法包括写缓存write buffer、流水线pipeline cache、多级结构multilevel cache、victim cache和预期prefetch。除此之外,对于乱序执行的超标量处理器来说,根据它的特点,还有一些其他的方法来提高Cache的性能,例如非阻塞non-blocking cache、关键字优先critical word first和提前开始early restart等方法。
2.2.1 写缓存
不管是load或者store指令,当D-Cache发生缺失时,需要从下一级存储器中读取数据,并写到一个选定的Cache line中,如果这个line是dirty,那么首先需要将它写到下级存储器中,考虑一般的饿下级存储器,例如L2 Cache或是物理内存,一般只有一个读写端口,这就要求上面的过程是串行完成的。先将dirty的Cache line的数据写到下级存储器中,然后才能读取下级存储器而得到缺失的数据,由于下级存储器的访问时间都比较长,这种串行的过程导致D-Cache发生缺失的处理时间变得很长,此时就可以采用write buffer写缓存来解决这个问题,dirty的Cache line首先放到写缓存中,等到下级存储器有空闲的时候,才会将写缓存中的数据写到下级存储器中。

对于write back类型的D-Cache来说,当一个dirty的Cache line被替换的时候,这个line中的数据会首先放到写缓存中,然后就可以从下级存储器中读数据了。
对于write through类型的D-Cache来说,采用写缓存之后,每次当数据写到D-Cache的同时,并不会同时写到下级存储器中,而是将其放到写缓存中,这样就减少了write through类型的D-Cache在写操作时需要的时间,从而提高了处理器的性能,以及write through类型的Cache由于便于进行存储器一致性的管理,所以在多核的处理器中,L1 Cache会经常采用这种结构。
加入写缓存之后,会增加系统设计的复杂度,举例来说,当读取D-Cache发生缺失时,不仅需要从下级存储器中查找这个数据,还需要在写缓存中也进行查找。
写缓存就相当于是L1 Cache到下级存储器之间的一个缓冲,通过它,向下级存储器中写数据的动作会被隐藏,从而可以提升处理器的执行效率,尤其是对于write through类型的D-Cache而言。
2.2.2 流水线
对于读取D-Cache来说,由于Tag SRAM和Data SRAM可以在同时进行读取,所以当处理器的周期时间要求不是很严格时,可以在一个周期内完成读取的操作;而对于写D-Cache来说,情况就比较特殊了,读取Tag SRAM和写Data SRAM的操作只能串行地完成。只有通过Tag比较,确认需要写的地址在Cache中之后,才可以写Data SRAM,在主频比较高的处理器中,这些操作很难在一个周期内完成。这就需要对D-Cache的写操作采用流水线的结构。比较典型的方式是将Tag SRAM的读取和比较放在一个周期,写D-Cache放在下一个周期。
需要注意当执行load指令时候,它想要的数据可能正好处于store指令的流水线寄存器中,而不是来自于Data SRAM,因此需要机制能检测到这种情况,将load指令所携带的地址和store指令的流水线寄存器进行比较。
对写D-Cache使用流水线之后,不仅增加了流水线本身的硬件,也带来一些额外的硬件开销。
2.2.3 多级结构
现代处理器很渴望有一种容量大,同时速度又很快的存储器,但在硅工艺条件下,对存储器来说,容量和速度是一对相互制约的因素,容量大必然速度慢。
为了使处理器看起来使用了一个容量大同时速度快的存储器,可以使用多级结构的Cache:
![]()
一般情况下,L1 Cache的容量很小,能够和处理器保持在同样速度等级上,L2 Cache的访问通常需要消耗处理器的几个时钟周期,但是容量要更大一些,L1和L2 Cache都会和处理器放在同一芯片上,现在L3 Cache也放在片上。
一般在处理器中,L2 Cache会使用write back方式,但是L1 Cache更倾向采用wirte through,这样可以简化流水线设计,尤其在多核情况下,管理存储器之间的一致性。
对于多级结构的Multilevel Cache,还需要了解两个概念,Inclusive和Exclusive:
Inclusive:如果L2 Cache包括了L1 Cache的所有内容,则称L2 Cache是Inclusive;
Exclusive:如果L2 Cache与L1 Cache的内容互不相同,则称L2 Cache是Exclusive;
Inclusive类型的Cache是比较浪费硬件资源的,因为它将一份数据保存在两个地方,优点则是可以直接将数据写到L1 Cache中,虽然此时会将Cache line中原来的数据覆盖掉,但是在L2 Cache中存有这个数据的备份,所以这样的覆盖不会引起任何问题(当然,被覆盖的line不能是dirty),以及也简化了一致性coherence的管理。
例如在多核的处理器中,执行store指令改变了存储器中的一个地址的数据时,如果是Inclusive类型的Cache,那么只需检查最低一级的Cache即可(L2 Cache),避免打扰上级Cache(L1 Cache)和处理器流水线的影响;
如果是Exclusive类型的Cache,很显然要检查所有的Cache,而检查L1 Cache也就意味着干扰了处理器的流水线。如果处理器要读取的数据不在L1 Cache中,而在L2 Cache中,那么在将数据从L2 Cache放到L1 Cache的同时,也需要将L1 Cache中被覆盖的数据写到L2 Cache中,这样数据交换很显然会降低处理器的效率,但是Exclusive类型的Cache避免硬件的浪费,可以获得更多可用的容量。
2.2.4 Victim Cache
Cache中被“踢出”的数据可能马上又要被使用,因为Cache中存储的是经常要使用的数据。例如对一个2-way组相连的D-Cache来说,如果个数据频繁使用的3个数据恰好都位于同一个Cache set中,那么就会导致一个way中的数据经常被“踢出”Cache,然后又经常地被写回Cache。

这会导致Cache始终无法名字需要的数据,显然降低了处理器的执行效率,如果为此增加Cache中的way个数,又会浪费大量的空间。Victim Cache正是要解决这样的问题,它可以保存最近被踢出Cache的数据,因此所有的Cache set都可以利用它来提高way的个数,通常Victim Cache采用全相连的方式,容量都比较小(一般存储4~16个数据)。

Victim Cache本质上相当于增加了Cache中way的个数,能够避免多个数据竞争Cache中有限的位置,从而降低了Cache的缺失率。一般情况下,Cache和Victim Cache存在互斥关系,也就是它们不包含想同样的数据,处理器内核可以同时读取它们。
同样,Victim Cache的数据会被写到Cache中,而Cache中被替换的数据会写到Victim Cache中,这就相当于它们互换了数据。
还有一种更Victim Cache类似的设计思路,称为Filter Cache,只不过使用在Cache之前,而Victim Cache使用在Cache之后,当一个数据第一次使用时,它并不会马上放到Cache中,而是首先会被放到Filter Cache中,等到这个数据再次被使用时,它才会被搬移到Cache中,这样做可以防止那些偶然使用的数据占据Cache。

2.2.5 预取
影响Cache缺失率的3C中一项为Compulsory,当处理器第一次访问一条指令或者一个数据时,这个指令或数据肯定不会在Cache中,这种情况引起的缺失似乎不可避免,但是实际上使用预取prefetch可以缓解这个问题。所谓预取,本质上也是一种预测技术,它猜测处理器在以后可能会使用什么指令或数据,然后提前将其放到Cache中,这个过程可以使用硬件或者软件完成。
1.硬件预取
对于指令来说,猜测后续会执行什么指令相对比较容易,因为程序本身是串行执行的,虽然由于分支指令的存在,这种猜测有时候也会出错,导致不会被使用的指令进入了I-Cache,这一方面降低了I-Cache实际可用的容量,一方面又占用了本来可能有用的指令,这称为“Cache污染”,不仅浪费了时间,还会影响处理器的执行效率,为了避免这种情况,可用将预取的指令放到一个单独的缓存中。
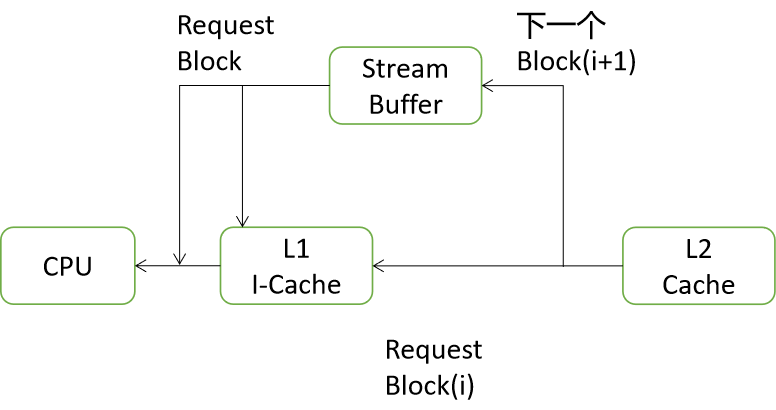
当I-Cache发生缺失时,处理将需要的数据块data block从下级存储器取出并放到I-Cache中,还会降下一个数据块也读取出来,只不过它不会放到I-Cache中,而是放到Stream Buffer的地方。在后续执行时,如果在I-Cache中发生了缺失,但是在Stream Buffer找到了想要的指令,那么除了使用Stream Buffer中读取的指令之外,还会将其中对应的数据块搬移到I-Cache中,同时继续从下一级存储器中读取下一个数据块放到Stream Buffer,当程序中没有遇到分支指令时,这种方法会一直正确地工作,从而使I-Cache的缺失率得到降低。但是分支指令会导致Stream Buffer的指令编的无效,此时的预取相当于做了无用功,浪费了总线带宽和功耗。预取是一把双刃剑,它可能会减少Cache的缺失率,也可能由于错误的预取而浪费了功耗和性能。
不同于指令的预取,对于数据的预取来说,它的规律更难以进行捕捉。一般情况下,当访问D-Cache发生缺失时,除了将所需要的数据块从下级存储器中取出来之外,还会将下一个数据块也读取出来。Intel Pentium 4和IBM Power5处理器中,采用了一种称为Strided Prefetch方法,它能够使用硬件来观测程序中使用数据的规律。
2. 软件预取
使用硬件进行数据的预取,很难得到满意的结果,其实在程序的编译阶段,编译器complier就可以对程序进行分析,进而知道哪些数据是需要进行预取的,如果在指令集中有预取指令prefetch instruction,那么编译器就可以可以直接控制程序进行预取。
应用软件预取方法有一种前提,就是预取的时机。如果预取数据的时间太晚,那么当真正需要使用数据时,有可能还没有被预取出来,这样预取就失去的意义;如果预取的时间太早,那么就有可能踢掉D-Cache中一些本来有用的数据,造成Cache污染。
还需要注意,使用软件预取的方法,当执行预取指令的时候,处理器需要能够继续执行,也就是能继续从D-Cache中读取数据,而不能让预取指令阻碍了后面指令的执行,这要求D-Cache是non-blocking结构。
在实现虚拟存储器Virtual memory系统中,预取指令有可能会引起一些异常exception发生,例如Page fault、虚拟地址错误virtual address fault或者保护违例Protection Violation。此时若对异常进行处理,就称其为处理错误的预取指令Faulting Prefetch Instruction,反之,称为不处理错误的预取指令nonfaulting prefetch instruction。
边栏推荐
- Leetcode-43- string multiplication
- R语言书籍学习03 《深入浅出R语言数据分析》-第八章 逻辑回归模型 第九章 聚类模型
- 快速排序的优化
- Cdr2022 serial number coreldraw2022 green key
- Rexroth overflow valve zdb6vp2-42/315v
- Matlab: 文件夹锁定问题的解决
- [today in history] June 11: the co inventor of Monte Carlo method was born; Google launched Google Earth; Google acquires waze
- R language book learning 03 "in simple terms R language data analysis" - Chapter 10 association rules Chapter 11 random forest
- Leetcode-322- change exchange
- Carry and walk with you. Have you ever seen a "palm sized" weather station?
猜你喜欢
![BZOJ3189 : [Coci2011] Slika](/img/46/c3aa54b7b3e7dfba75a7413dfd5b68.png)
BZOJ3189 : [Coci2011] Slika

Classes and objects (3)
Huawei equipment configuration hovpn

网络连接正常但百度网页打不开显示无法访问此网站解决方案

EndnoteX9简介及基本教程使用说明

The shortcomings of the "big model" and the strengths of the "knowledge map"

How to use the transaction code sat to find the name of the background storage database table corresponding to a sapgui screen field

揭秘爆款的小程序,为何一黑到底
![[niuke.com] dp31 [template] complete Backpack](/img/81/5f35a58c48f05a5b4b6bdc106f5da0.jpg)
[niuke.com] dp31 [template] complete Backpack

Popular science | what are the types of NFT (Part 1)
随机推荐
Leetcode - 第2天
Customer information management software
Uncover the secret of the popular app. Why is it so black
「大模型」之所短,「知识图谱」之所长
Classes and objects (2)
Codeworks round 739 (Div. 3) problem solving Report
JVM | virtual machine stack (local variable table; operand stack; dynamic link; method binding mechanism; method call; method return address)
D. Game With Array
类和对象(2)
How does the chief financial officer of RPA find the "super entrance" of digital transformation?
AC automata
实验10 Bezier曲线生成-实验提高-控制点生成B样条曲线
学习位段(1)
[today in history] June 11: the co inventor of Monte Carlo method was born; Google launched Google Earth; Google acquires waze
Why microservices are needed
Rexroth overflow valve zdb6vp2-42/315v
Bipartite King
快速排序的三种方法
Leetcode-32- longest valid bracket
The upcoming launch of the industry's first retail digital innovation white paper unlocks the secret of full link digital success